В этой статье описывается альтернативный подход к проектам хранилища данных, который называется разведочным анализом данных (EDA). Такой подход может снизить сложность операций извлечения, преобразования и загрузки (ETL). В первую очередь он позволяет фокусироваться на формировании бизнес-аналитики, а затем перейти к решению задач моделирования и ETL.
Архитектура

Скачайте файл Visio для этой архитектуры.
Для EDA важна только правая сторона схемы. Бессерверная служба Azure Synapse SQL используется в качестве подсистемы вычислений для файлов озера данных.
Для выполнения EDA:
- Запросы T-SQL выполняются непосредственно в бессерверной службе Azure Synapse SQL или в Azure Synapse Spark.
- Запросы выполняются из инструмента создания запросов с графическим интерфейсом, например Power BI или Azure Data Studio.
Рекомендуется сохранять все данные lakehouse с помощью Parquet или Delta.
Вы можете реализовать левую часть схемы (прием данных) с помощью любого инструмента для извлечения, загрузки и преобразования (ELT). Она не влияет на EDA.
Компоненты
Azure Synapse Analytics сочетает интеграцию данных, хранение корпоративных данных и аналитику больших данных для данных lakehouse. В этом решении:
- Рабочая область Azure Synapse обеспечивает совместную работу инженеров данных, специалистов по обработке и анализу данных, аналитиков данных и специалистов по бизнес-аналитике (BI) над задачами EDA.
- Бессерверные пулы SQL в Azure Synapse анализируют неструктурированные и частично структурированные данные в Azure Data Lake Storage с помощью стандартного языка T-SQL.
- Бессерверные пулы Apache Spark в Azure Synapse выполняют анализ code-first в Data Lake Storage с помощью таких языков Spark, как Spark SQL, PySpark и Scala.
Azure Data Lake служба хранилища предоставляет хранилище для данных, которые затем анализируются бессерверными пулами SQL Azure Synapse.
Машинное обучение Azure предоставляет данные для Azure Synapse Spark.
Power BI используется в этом решении для запроса данных, необходимых для выполнения EDA.
Альтернативные варианты
Вы можете заменить или дополнить бессерверные пулы SQL Synapse посредством Azure Databricks.
Вместо использования модели lakehouse с бессерверными пулами Synapse SQL можно применять выделенные пулы SQL в Azure Synapse для хранения корпоративных данных. Ознакомьтесь с вариантами использования и рекомендациями, приведенными в этой статье, а также со связанными ресурсами, чтобы решить, какую технологию использовать.
Подробности сценария
Это решение показывает реализацию подхода EDA к проектам хранилища данных. Этот подход может снизить проблемы операций ETL. Сначала он фокусируется на создании бизнес-аналитики, а затем превращается в решение задач моделирования и ETL.
Потенциальные варианты использования
Другие сценарии, которые могут использовать преимущества этого шаблона аналитики:
Предписывающая аналитика. Задавайте вопросы о данных, например о следующем лучшем действии или о том, что делать дальше. Используйте данные, чтобы больше действовать на их основании, чем наугад. Данные могут быть неструктурированными, а также могут происходить из множества внешних источников разного качества. Вы можете максимально быстро использовать данные, чтобы оценивать бизнес-стратегию, без фактической загрузки информации в хранилище данных. Вы можете удалить данные после получения ответов на вопросы.
Самостоятельные операции ETL. Выполняйте операции ETL и ELT при выполнении действий изолирования данных (EDA). Преобразуйте данные и сделайте их ценными. Это может увеличить масштаб работы ваших разработчиков ETL.
О разведочном анализе данных
Прежде чем мы подробнее рассмотрим, как работает EDA, стоит кратко изложить традиционный подход к проектированию хранилищ данных. Традиционный подход выглядит следующим образом:
Сбор требований. Документирование действий с данными.
Моделирование данных. Определение того, как моделировать числовые данные и данные атрибутов в таблицах фактов и таблицах измерения. Традиционно этот шаг выполняется перед получением новых данных.
Извлечение, преобразование и загрузка (ETL). Запрос данных и их преобразование в соответствии с моделью данных хранилища данных.
Эти этапы могут длиться недели или даже месяцы. Только после этого можно будет начать запрашивать данные и решать бизнес-задачу. Пользователь видит значение только после создания отчетов. Архитектура решения обычно выглядит следующим образом.
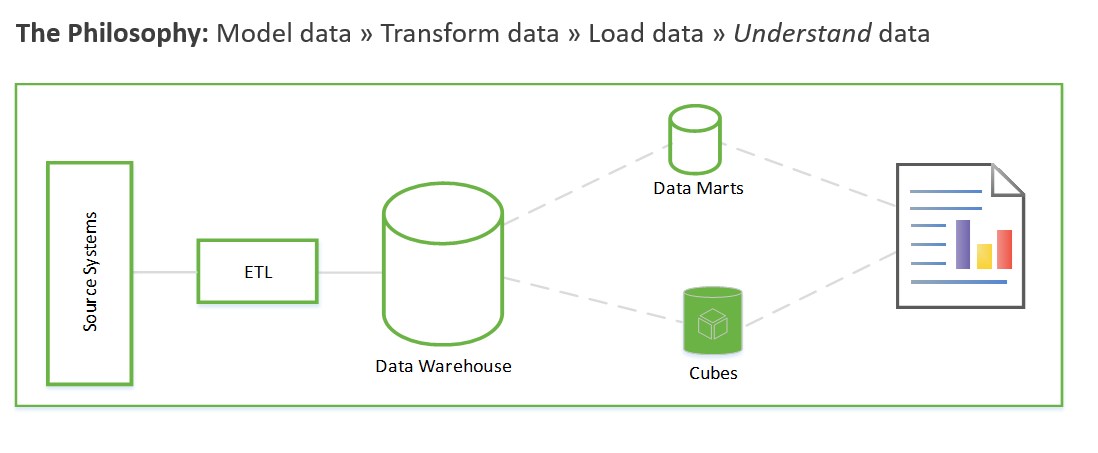
Решение можно построить иначе: в первую очередь сфокусироваться на формировании бизнес-аналитики, а затем перейти к решению задач моделирования и ETL. Этот процесс аналогичен процессам обработки и анализа данных. Она имеет следующий вид.
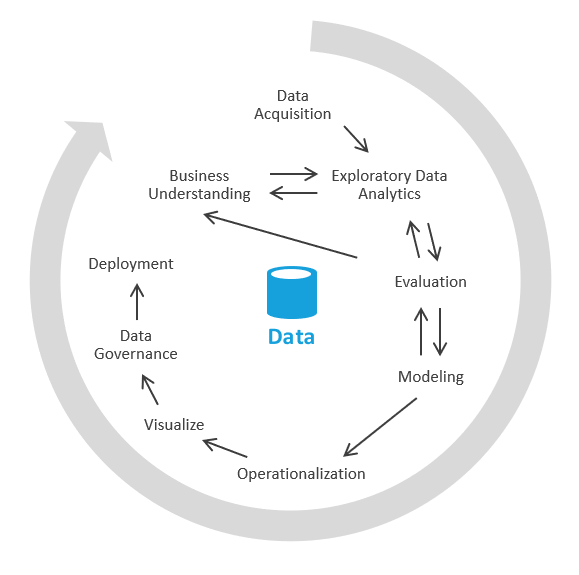
В отрасли этот процесс называется EDA, или разведочным анализом данных.
Ниже приведены шаги.
Сбор данных. Во-первых, необходимо определить, какие источники данных необходимо использовать для приема информации в озеро данных или песочницу. Затем необходимо перенести эти данные в целевую область озера. Azure предоставляет такие инструменты, как Фабрика данных Azure и Azure Logic Apps, которые обеспечивают быстрый прием данных.
Изолирование данных. Изначально специалист по бизнес-аналитике и инженер, обладающий навыками разведочного анализа данных посредством бессерверных или стандартных пулов SQL в Azure Synapse Analytics, работают вместе. На этом этапе они пытаются выявить бизнес-аналитику с помощью новых данных. EDA — это итеративный процесс. Может потребоваться принять дополнительные данные, поговорить с профильными специалистами, задать дополнительные вопросы или создать визуализации.
Вычисление. После нахождения бизнес-аналитики необходимо оценить, что делать с данными. Может потребоваться сохранить их в хранилище данных (так вы перейдете к этапу моделирования). Или же может потребоваться сохранить данные в озере данных или хранилище lakehouse и использовать их для прогнозной аналитики (алгоритмы машинного обучения). Кроме того, может потребоваться задним числом внести изменения в регистрируемые системы, используя новые аналитические сведения. Основываясь на этих решениях, вы сможете получить более полное представление о том, что нужно делать дальше. Вам могут не потребоваться операции ETL.
Эти методы являются основой полноценной самостоятельной аналитики. Используя озеро данных и инструмент создания запросов, такой как бессерверная служба Azure Synapse, которая распознает шаблоны запросов к озеру данных, вы сможете предоставить свои ресурсы данных бизнесменам, которые хотя бы немного разбираются в SQL. Используя этот метод, можно радикально сократить срок окупаемости и частично устранить риск, связанный с инициативами по корпоративным данным.
Рекомендации
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая является набором руководящих принципов, которые можно использовать для улучшения качества рабочей нагрузки. Дополнительные сведения см. в статье Microsoft Azure Well-Architected Framework.
Доступность
Бессерверные пулы SQL в Azure Synapse — это функция платформы как услуги (PaaS), которая может выполнить ваши требования к высокому уровню доступности (HA) и аварийному восстановлению (DR).
Бессерверные пулы доступны по запросу. Для них не требуется какое-либо масштабирование или администрирование. В них используется модель с оплатой по запросу, поэтому в любой момент используется вся запрошенная емкость. Бессерверные пулы идеально подходят для:
- автоматизированного исследования данных с помощью T-SQL;
- раннего создания прототипов для сущностей хранилища данных;
- определения представлений, которые могут использоваться объектами-получателями, например в Power BI, для сценариев, допускающих временное падение производительности;
- разведочного анализа данных.
Operations
Бессерверная служба Synapse SQL использует стандартный язык T-SQL для запросов и операций. В качестве инструмента T-SQL можно использовать пользовательский интерфейс рабочей области Synapse, Azure Data Studio или SQL Server Management Studio.
Оптимизация затрат
Оптимизация затрат заключается в поиске способов уменьшения ненужных расходов и повышения эффективности работы. Дополнительные сведения см. в разделе Обзор критерия "Оптимизация затрат".
Цены на Data Lake Storage зависят от объема хранящихся данных и частоты использования этих данных. Пример цены включает в себя 1 ТБ хранимых данных и предполагаемые дальнейшие транзакции. 1 ТБ относится к размеру озера данных, а не к размеру исходной устаревшей базы данных.
Цена пула Spark в Azure Synapse основана на стоимости размера узла, количестве экземпляров и времени доступности. В примере предполагается, что один небольшой вычислительный узел используется до 5 часов в неделю и до 40 часов в месяц.
Цена на бессерверный пул SQL в Azure Synapse основана на стоимости терабайтов обработанных данных. В примере предполагается, что в месяц обрабатывалось 50 ТБ. На этом рисунке показа размер озера данных, а не исходной устаревшей базы данных.
Соавторы
Эта статья обновляется и поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Основные авторы:
- Дэйв Уенцель | Главный технический архитектор MTC
Следующие шаги
- Инженер данных схемы обучения
- Руководство. Начало работы с Azure Synapse Analytics
- Создание отдельной базы данных в Базе данных SQL Azure
- Архитектура Azure Synapse SQL
- Создание учетной записи хранения для Azure Data Lake Storage
- Краткое руководство по Центрам событий Azure. Создание концентратора событий с помощью портала Azure
- Краткое руководство. Создание задания Stream Analytics с помощью портал Azure
- Краткое руководство. Начало работы с Машинное обучение Azure