В этой статье описано дерево принятия решений и приведены примеры использования высокой доступности (HA) и аварийного восстановления (DR) при развертывании многоуровневых приложений инфраструктуры как услуги (IaaS) в Azure.
Архитектура
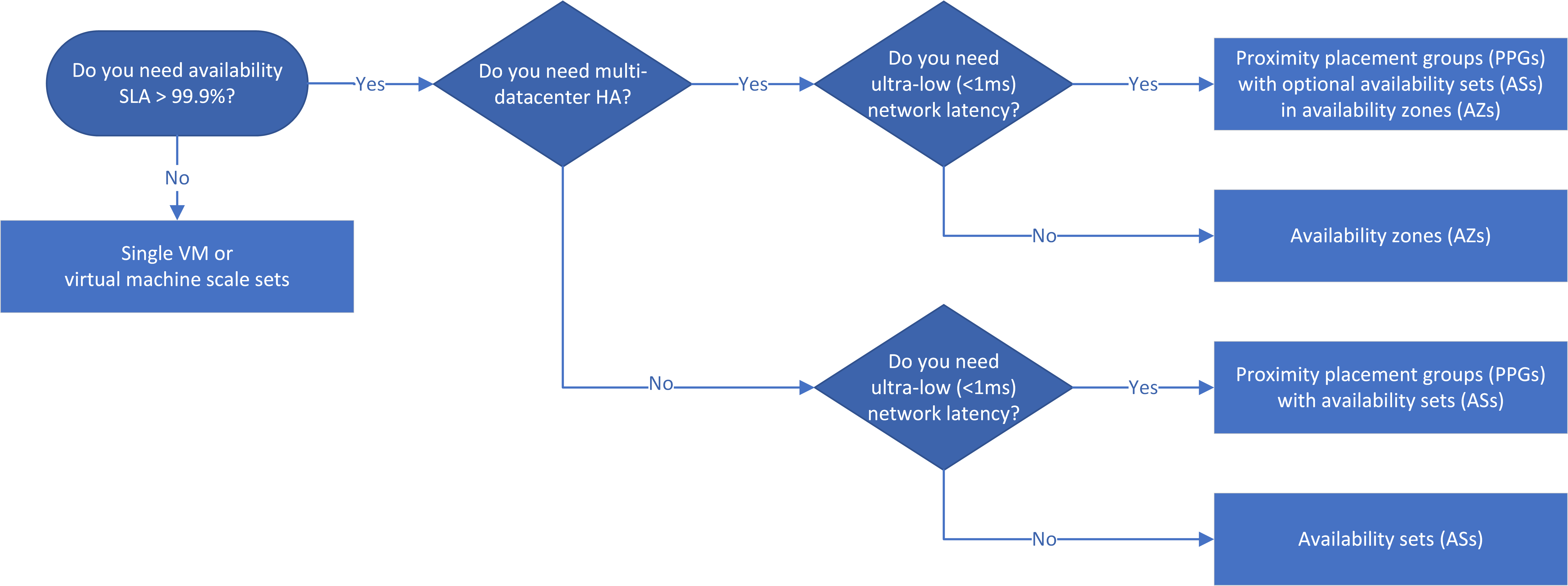
Рабочий процесс
Группы доступности обеспечивают избыточность виртуальных машин и доступность в центре обработки данных путем распределения виртуальных машин между несколькими изолированными аппаратными узлами. Подмножество виртуальных машин продолжает работу во время запланированного или неожиданного простоя, поэтому приложение остается доступным и продолжает функционировать.
Зоны доступности — это уникальные физические расположения, охватывающие центры обработки данных в регионе Azure. Каждая зона доступности обращается к одному или нескольким центрам обработки данных с независимым питанием, охлаждением и сетью, и каждый регион доступности с поддержкой зоны доступности Azure имеет не менее трех отдельных зон доступности. Физическое разделение зон доступности в регионе защищает развернутые виртуальные машины от сбоя центра обработки данных.
Блок-схема принятия решений отражает принцип, который приложения высокого уровня доступности должны использовать зоны доступности, если это возможно. Высокая доступность между зонами, а следовательно, и между центрами обработки данных обеспечивает > 99,99 % соблюдения соглашения об уровне обслуживания благодаря устойчивости к сбоям.
Группы доступности и зоны доступности для разных уровней приложений не гарантируются в одном центре обработки данных. Если задержка приложений является основной проблемой, необходимо выделить службы в одном центре обработки данных с помощью групп размещения близкого взаимодействия (PPG) с зонами доступности и группами доступности.
Компоненты
Альтернативные варианты
Если приложение может самостоятельно реплицировать данные, в качестве альтернативы региональному DR с Azure Site Recovery можно реализовать аварийное восстановление в нескольких регионах с помощью серверов горячей замены или холодного резервирования, например растянутого кластера для DR. Этот вариант не описан подробно в примерах, но его можно добавить в любое решение. Обратите внимание, что репликация между регионами выполняется асинхронно и возможна потеря определенных данных.
Кроме того, если у вас есть собственная технология репликации данных, ее можно использовать для создания дополнительной зоны в регионе для DR. В зависимости от региона рабочих нагрузок также можно использовать Azure Site Recovery для реплика элементов в альтернативной зоне, вы можете проверка региональной доступности и узнать больше об этой функции в статье "Включение аварийного восстановления зоны в зоне" для виртуальных машин Azure.
Возможна HA для нескольких регионов, но это требует подключения глобальной подсистемы балансировки нагрузки, такой как Front Door или Диспетчер трафика. Дополнительные сведения см. в статье Запуск N-уровневого приложения в нескольких регионах Azure для высокой доступности.
Подробности сценария
В обычных локальных приложениях часто используются многоуровневые или n-уровневые архитектуры, поэтому они являются очевидным выбором при переносе локальных приложений в облако или разработке приложений для локальной и облачной сред. N-уровневые архитектуры обычно реализуются как приложения IaaS, разделенные на логические и физические уровни, где верхний уровень — это веб-уровень или уровень представления, посередине находится бизнес-уровень, а затем идет уровень данных.
В n-уровневом приложении IaaS каждый уровень выполняется в отдельном наборе виртуальных машин. Для веб-уровня и бизнес-уровня состояние не отслеживается, то есть любая виртуальная машина этого уровня может обработать любой запрос на нем. Уровень данных представляет собой реплицированную базу данных, хранилище объектов или файлов. Использование нескольких виртуальных машин на каждом уровне обеспечивает устойчивость при сбое одной из них, так как подсистемы балансировки нагрузки распределяют запросы между работоспособными виртуальными машинами.
Можно выполнить горизонтальное увеличение масштаба уровней, добавив дополнительные виртуальные машины в пулы и воспользовавшись масштабируемыми наборами виртуальных машин для автомасштабирования одинаковых виртуальных машин. Так как используются подсистемы балансировки нагрузки, можно горизонтально масштабировать уровни, не влияя на время работы приложения.
Если в соглашении об уровне обслуживания для приложения IaaS требуется > 99 % доступности, для ее настройки можно поместить виртуальные машины в группы доступности, зоны доступности и группы размещения близкого взаимодействия. Решения HA и DR зависят от требований соглашения об уровне обслуживания, критериев задержки и региональных требований к аварийному восстановлению.
Потенциальные варианты использования
- Перенос n-уровневого приложения из локальной среды в облако.
- Развертывание n-уровневого приложения как в локальной среде, так и в облаке.
- Настройка высокой доступности и аварийного восстановления для приложения IaaS.
Это решение можно использовать для любой отрасли, включая следующие сценарии:
- Приложения для государственных секторов
- Банковское дело (финансовая отрасль)
- Здравоохранение
Рекомендации
Зоны доступности недоступны во всех регионах Azure.
Перед созданием решения определите, какой вариант развертывания хотите использовать. Можно изменить конфигурацию после развертывания, однако сделать это непросто. Придется удалить виртуальные машины и заново их создать из базовых управляемых дисков, что является связанным процессом.
Убедитесь, что ваше приложение можно сопоставить с выбранным решением. Для этого дерева принятия решений недоступны многие шаблоны и разработки устойчивости уровней приложения.
Перезагрузку виртуальных машин Azure могут вызвать три сценария: непредвиденное обслуживание оборудования, непредвиденный простой и запланированное обслуживание. Дополнительные сведения об этих событиях и рекомендациях по обеспечению высокого уровня доступности для снижения их воздействия см. в статье Общие сведения о перезагрузке виртуальных машин. Обслуживание и простой.
Отдельные виртуальные машины
Если для приложения не требуется > 99,9 % доступности, его необязательно настраивать для HA, и можно развернуть отдельные виртуальные машины. С помощью масштабируемых наборов виртуальных машин можно автоматически горизонтально увеличить масштаб одинаковых виртуальных машин. Разворачивайте отдельные виртуальные машины без указания зоны, чтобы они распределялись по региону. При использовании дисков SSD Azure (цен. категория "Премиум") для таких приложений достигается 99,9 % соблюдения соглашения об уровне обслуживания.
Отдельные виртуальные машины используют функцию восстановления служб по умолчанию, встроенную во все центры обработки данных Azure. Для прогнозируемых сбоев эта функция обычно использует динамическую миграцию, но во время непредсказуемых событий виртуальные машины могут быть перезагружены или недоступны.
Высокая доступность
Если для приложения требуется > 99,9 % соблюдения соглашения об уровне обслуживания, спроектируйте приложение для HA. По возможности используйте зоны доступности, так как они обеспечивают отказоустойчивость центра обработки данных. Вы можете использовать группы доступности вместо зон доступности, но использование групп доступности сокращает доступность с 99,99% до 99,95%, так как группы доступности не могут допускать сбоя центра обработки данных.
Зоны доступности подходят для многих кластеризованных сценариев приложений, включая кластеры SQL AlwaysOn, использование активных, активных и пассивных или сочетание обоих уровней высокой доступности на каждом уровне с быстрой отработкой отказа. Между любыми узлами системы управления базами данных (СУБД) возможна синхронная репликация благодаря низкой задержке в сети между зонами. Также между зонами можно запустить конфигурацию растянутого кластера, которая обладает большей задержкой и поддерживает асинхронную репликацию.
Если вы хотите использовать arbiter кластера на основе виртуальной машины, например следящий файловый ресурс, поместите его в третью зону доступности, чтобы убедиться, что кворум не будет потерян, если одна зона завершается ошибкой. Кроме того, можно использовать облачного свидетеля в другом регионе.
Все виртуальные машины в зоне доступности находятся в одном домене сбоя (FD) и домене обновления (UD), что означает, что они совместно используют общий сетевой коммутатор и источник питания и могут одновременно перезагружаться. Если вы создаете виртуальные машины в разных зонах доступности, виртуальные машины эффективно распределяются по разным FD и UD, поэтому они не будут выполняться сбоем или перезагрузкой одновременно. Если вы хотите иметь избыточные виртуальные машины в зоне, а также межзонные виртуальные машины, следует разместить виртуальные машины в группах доступности в группах доступности в PPG, чтобы убедиться, что они не будут перезагружены одновременно. Даже для рабочих нагрузок виртуальных машин с одним экземпляром, которые не являются избыточными сегодня, можно по-прежнему использовать наборы доступности в PPG, чтобы обеспечить будущий рост и гибкость.
Для развертывания масштабируемых наборов виртуальных машин в зонах доступности рекомендуется использовать режим оркестрации в настоящее время в общедоступной предварительной версии, что позволяет объединять FD и зоны доступности.
Зоны доступности с ppG в зоне позволяют обеспечить одну из самых низких задержек сети в Azure и соглашение об уровне обслуживания не менее 99,99 % из-за устойчивости нескольких центров обработки данных. По возможности используйте ускорение сети на виртуальных машинах.
Это решение может представлять сценарий, в котором служба, запущенная на виртуальной машине в одной зоне, должна взаимодействовать со службой в другой зоне. Например, в зонах может быть веб-уровень "активный— активный" и уровень базы данных "активный- пассивный". Некоторые запросы используют несколько зон, что приводит к задержкам. Хотя задержка между зонами очень низкая, если вам необходимо обеспечить минимальную задержку, настройте все сетевые взаимодействия между уровнями приложения в пределах одной зоны.
Рекомендации по задержкам
Сетевая задержка зависит, помимо прочего, от физического расстояния между развернутыми виртуальными машинами. Если приложению требуется очень низкая задержка между уровнями, его можно развернуть в одном центре обработки данных, используя PPG с группами доступности для каждого уровня. По возможности используйте ускорение сети на виртуальных машинах. Такой сценарий обеспечивает одну из наименьших сетевых задержек в Azure, а также соблюдение соглашения об уровне обслуживания на 99,95 %.
Можно воспользоваться следующими инструментами, чтобы получить более подробные сведения об условиях задержки для различных сценариев:
- Чтобы проверить задержку между виртуальными машинами, см. статью Проверка сетевой задержки виртуальных машин.
- Чтобы проверить задержку между зонами, перейдите по ссылке проверка задержки между зонами доступности. Эта проверка поможет определить, у какой логической зоны наименьшая задержка в вашей подписке.
- Чтобы проверить задержку между регионами Azure, перейдите по ссылке http://www.azurespeed.com/. Этот регулярно обновляемый инструмент может пригодиться для асинхронной репликации между регионами.
Аварийное восстановление
Рекомендации по аварийному восстановлению включают доступность, то есть возможность приложения находиться в работоспособном состоянии, и устойчивость данных, то есть сохранение данных в случае аварии.
Отработка отказа HA должна быть быстрой, без потери данных и с ограниченным воздействием на службу. В отличие от этого, традиционная отработка отказа аварийного восстановления может иметь более длинную связанную цель времени восстановления (RTO) и целевую точку восстановления (RPO) и асинхронную с потенциальной потерей данных.
Вы можете воспользоваться преимуществами зон доступности для обеспечения высокой доступности и аварийного восстановления с помощью другой зоны доступности для решения аварийного восстановления. Зоны доступности достаточно близки, чтобы иметь подключения с низкой задержкой к другим зонам доступности (задержка кругового пути меньше 2 мс). Однако они достаточно далеко друг от друга, чтобы снизить вероятность того, что местные сбои или погода может повлиять на несколько зон доступности. Для критически важных рабочих нагрузок следует рассмотреть решение, которое использует несколько регионов в дополнение к нескольким зонам доступности.
Azure Site Recovery позволяет реплицировать виртуальные машины в другой регион Azure для регионального аварийного восстановления и обеспечения непрерывности бизнес-процессов. Вы можете использовать Azure Site Recovery для восстановления приложений в случае сбоя исходного региона или для проведения периодических детализаций аварийного восстановления, чтобы обеспечить соответствие требованиям.
Если приложение поддерживает Azure Site Recovery, можно обеспечить региональное решение DR для повышенной защиты, если этого требует критичность приложения. Тем не менее, кросс-зона, кросс-центр обработки данных может быть достаточной защиты, так как если приложение полностью устойчиво к сбою центра обработки данных, не должно быть простоя или потери данных.
Оптимизация затрат
Дополнительные затраты на виртуальные машины, развернутые в зонах доступности, отсутствуют. Может потребоваться дополнительная плата за передачу данных между зонами доступности между виртуальными машинами. Дополнительные сведения см. на странице Стоимость пропускной способности.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Автор субъекта:
- Шон Краучер | Старший консультант
Следующие шаги
- Группы доступности
- Зоны доступности
- Масштабируемые наборы виртуальных машин
- Включение аварийного восстановления между зонами для виртуальных машин Azure
Связанные ресурсы
- Стиль архитектуры N-уровней
- Создание многоуровневых веб-приложений для обеспечения высокой доступности и аварийного восстановления в Azure
- Запуск веб-приложения, избыточного между зонами, для обеспечения высокой доступности
- Запуск веб-приложения в нескольких регионах Azure для обеспечения высокой доступности
- Запуск n-уровневого приложения в нескольких регионах Azure для обеспечения высокой доступности