Эта эталонная архитектура демонстрирует набор проверенных рекомендаций по работе с n-уровневыми приложениями в нескольких регионах Azure, благодаря которым можно обеспечить высокую доступность и получить надежную архитектуру аварийного восстановления.
Архитектура
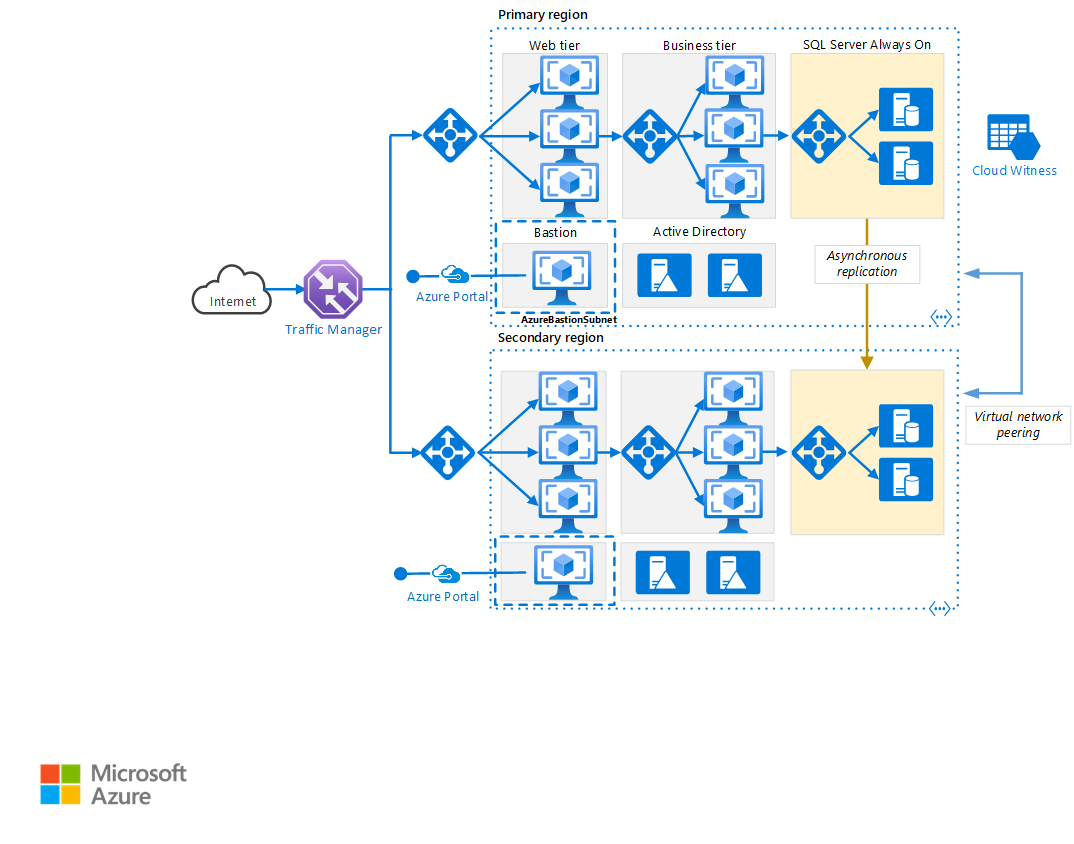
Скачайте файл Visio для этой архитектуры.
Рабочий процесс
Основной и дополнительный регионы. Чтобы достичь более высокого уровня доступности, используйте два региона Azure, один из которых является основным, а второй предназначен для отработки отказа.
Диспетчер трафика Azure. Диспетчер трафика направляет входящие запросы в один из регионов. При обычной работе он направляет запросы в основной регион. Если этот регион становится недоступным, диспетчер трафика выполняет отработку отказа в дополнительный регион. Дополнительные сведения см. в разделе Конфигурация диспетчера трафика.
Группы ресурсов. Создайте отдельные группы ресурсов для основного и вторичного регионов, а также для диспетчера трафика. Этот метод обеспечивает гибкость управления каждым регионом в виде единой коллекции ресурсов. Например, можно повторно развернуть один регион, не отключая другой. Свяжите группы ресурсов, чтобы запустить запрос на перечисление всех ресурсов приложения.
Виртуальные сети. Создайте отдельные виртуальные сети для каждого региона. Убедитесь, что адресные пространства не перекрываются.
Группа доступности AlwaysOn SQL Server. Если вы используете SQL Server, мы рекомендуем группы доступности SQL AlwaysOn для обеспечения высокой доступности. Создайте одну группу доступности, которая включает экземпляры SQL Server в обоих регионах.
Примечание.
Кроме того, учитывайте Базу данных SQL Azure, которая предоставляет реляционную базу данных в качестве облачной службы. В базе данных SQL не нужно настраивать группу доступности или управлять отработкой отказа.
Пиринг между виртуальными сетями. Пиринг между двумя виртуальными сетями, чтобы разрешить репликацию данных из основного региона в дополнительный регион. Дополнительные сведения см. в статье Пиринг между виртуальными сетями.
Компоненты
- Группы доступности распределяют развернутые в Azure виртуальные машины между несколькими изолированными аппаратными узлами в кластере. Если в Azure возникает сбой оборудования или программного обеспечения, затрагивается только подмножество виртуальных машин, и все решение остается доступным и операционным.
- Зоны доступности защищают приложения и данные от сбоев на уровне центра обработки данных. Зоны доступности — это отдельные физические расположения в пределах одного региона Azure. Каждая зона состоит из одного или нескольких центров обработки данных, оснащенных независимыми системами электроснабжения, охлаждения и сетевого взаимодействия.
- Диспетчер трафика Azure — это подсистема балансировки нагрузки на основе DNS, которая оптимально распределяет трафик. Она предоставляет службы в глобальных регионах Azure с высокой доступностью и скоростью реагирования.
- Azure Load Balancer распределяет входящий трафик в соответствии с определенными правилами и пробами работоспособности. Подсистема балансировки нагрузки обеспечивает низкую задержку и высокую пропускную способность, а также позволяет выполнять масштабирование до миллионов потоков для всех приложений, которые используют протоколы TCP и UDP. В этом сценарии используется общедоступная подсистема балансировки нагрузки для распределения входящего трафика клиента на веб-уровне. В этом сценарии используется внутренняя подсистема балансировки нагрузки для распределения трафика из бизнес-уровня в серверный кластер SQL Server.
- Бастион Azure обеспечивает безопасное подключение RDP и SSH ко всем виртуальным машинам в виртуальной сети, в которой она подготовлена. Используйте Бастион Azure для защиты виртуальных машин от предоставления портов RDP/SSH во внешнем мире, обеспечивая безопасный доступ с помощью RDP/SSH.
Рекомендации
Архитектура с несколькими регионами может обеспечить более высокий уровень доступности, чем развертывание в одном регионе. Если региональный сбой влияет на основной регион, можно использовать диспетчер трафика для выполнения отработки отказа в дополнительный регион. Эта архитектура также помогает при сбое отдельной подсистемы или приложения.
Есть несколько общих подходов к достижению высокого уровня доступности в регионах:
- Шаблон "активный — пассивный" с "горячим" резервом. Трафик отправляется в один регион, в то время как другой ожидает в режиме "горячего" резерва. Горячий резервный режим означает, что виртуальные машины в дополнительном регионе выделяются и всегда выполняются.
- Шаблон "активный — пассивный" с "холодным" резервом. Трафик отправляется в один регион, в то время как другой ожидает в режиме "холодного" резерва. Холодный резервный режим означает, что виртуальные машины в дополнительном регионе не выделяются до тех пор, пока не потребуется для отработки отказа. Этот подход экономичнее, однако при сбое для выхода в динамический режим требуется больше времени.
- Активный — активный. Оба региона активны, нагрузка запросов балансируется между ними. Если один регион становится недоступным, он выходит из поворота.
В этой эталонной архитектуре уделяется внимание режиму "активный — пассивный" с "горячим" резервом, а также использованию диспетчера трафика для отработки отказа. Вы можете развернуть несколько виртуальных машин для горячего резервного режима, а затем масштабировать по мере необходимости.
Региональные пары
Каждый регион Azure образует пару с другим регионом в пределах одной географической территории. В общем случае выбирайте регионы из одной региональной пары (например, восточная часть США 2, центральная часть США). Преимущества:
- Если есть широкий сбой, восстановление по крайней мере одного региона из каждой пары является приоритетным.
- запланированные обновления системы Azure распространяются в парах регионов последовательно во избежание возможных простоев;
- пары находятся в пределах одной географической территории в соответствии с требованиями к местонахождению данных.
Убедитесь, что оба региона поддерживают все службы Azure, необходимые приложению (см. статью Доступность продуктов по регионам). Дополнительные сведения о парах регионов см. в статье Непрерывность бизнес-процессов и аварийное восстановление в службах BizTalk: пары регионов Azure.
Конфигурация диспетчера трафика
При настройке диспетчера трафика необходимо учитывать следующее:
- Маршрутизация. Диспетчер трафика поддерживает несколько алгоритмов маршрутизации. Для сценария, описанного в этой статье, используется маршрутизация по приоритету (ранее называлась маршрутизацией отработки отказа). С помощью этой функции диспетчер трафика отправляет все запросы в основной регион, если дополнительный регион не станет недоступным. В этот момент он автоматически выполняет отработку отказа в дополнительный регион. Дополнительные сведения см. в статье о настройке метода маршрутизации с отработкой отказа.
- Проверка работоспособности. Диспетчер трафика использует проверку HTTP (или HTTPS) для мониторинга доступности каждого региона. При этом проверяется код ответа HTTP 200 в заданном пути URL-адреса. Рекомендуется создать конечную точку, которая сообщает о работоспособности приложения, и использовать ее для проверки работоспособности. В противном случае при проверке может быть сообщено о работоспособной конечной точке, тогда как критические части приложения фактически не будут работать. См. дополнительные сведения о шаблоне мониторинга конечных точек работоспособности.
Когда Диспетчер трафика отработки отказа, существует период времени, когда клиенты не могут добраться до приложения. Этот период зависит от следующих факторов:
- При проверке работоспособности определяется, что с основным регионом невозможно связаться.
- DNS-серверы должны обновить кэшированные записи DNS для IP-адресов, которые зависят от срока существования DNS. Срок существования по умолчанию — 300 секунд (5 минут), однако это значение можно настроить при создании профиля диспетчера трафика.
Дополнительные сведения см. в статье о мониторинге в диспетчере трафика.
При отработке отказа диспетчера трафика ее рекомендуется выполнять вручную, а не внедрять автоматическую отработку отказа. В противном случае могут возникнуть ситуации, в которых приложение будет переходить между регионами. Убедитесь, что все подсистемы приложения полностью работоспособны, и лишь затем выполните восстановление размещения.
Диспетчер трафика автоматически завершается сбоем по умолчанию. Чтобы предотвратить эту проблему, вручную уменьшите приоритет основного региона после события отработки отказа. Например, предположим, что основной регион имеет приоритет 1, а дополнительные — приоритет 2. После отработки отказа задайте основному региону приоритет 3, чтобы избежать автоматического восстановления размещения. Когда вы будете готовы вернуться, обновите приоритет до 1.
Следующая команда Azure CLI обновляет приоритет:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
Другой подход — временно отключить конечную точку до тех пор, пока вы не будете готовы выполнить отработку отказа:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
В зависимости от причины отработки отказа может потребоваться повторное развертывание ресурсов в пределах региона. До восстановления размещения выполните тест готовности к работе. При этом проверяется следующее:
- правильная настройка виртуальных машин (все необходимое программное обеспечение установлено, IIS выполняются и т. д.);
- работоспособность подсистем приложения;
- функциональное тестирование (например, доступен ли уровень базы данных с веб-уровня).
Настройка группы доступности AlwaysOn SQL Server
До Windows Server 2016 для групп доступности SQL Server Always On требовался контроллер домена, а все узлы в группе доступности должны были находиться в одном домене Active Directory (AD).
Чтобы настроить группу доступности, сделайте следующее:
Поместите как минимум два контроллера домена в каждом регионе.
Предоставьте каждому контроллеру домена статический IP-адрес.
Пиринг двух виртуальных сетей для включения связи между ними.
Для каждой виртуальной сети добавьте IP-адреса контроллеров доменов (из обоих регионов) в список DNS-серверов. Вы можете использовать следующую команду интерфейса командной строки. Дополнительные сведения см. в разделе Изменение DNS-серверов.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Создайте отказоустойчивый кластер Windows Server (WSFC), включающий экземпляры SQL Server в обоих регионах.
Создайте группу доступности Always On SQL Server, в которую включены экземпляры SQL Server в основном и дополнительном регионах. Дополнительные сведения о шагах см. в статье Extending AlwaysOn Availability Group to Remote Azure Datacenter (PowerShell) (Расширение групп доступности Always On на удаленный центр обработки данных Azure (PowerShell)).
Поместите первичную реплику в основной регион.
Поместите одну или несколько вторичных реплик в основной регион. Настройте эти реплики для использования синхронной фиксации с автоматической отработкой отказа.
Поместите одну или несколько вторичных реплик в дополнительный регион. Настройте эти реплики для использования асинхронной фиксации по соображениям производительности. (иначе все транзакции T-SQL должны ожидать кругового перехода по сети до дополнительного региона).
Примечание.
Реплики асинхронной фиксации не поддерживают автоматический переход на другой ресурс.
Рекомендации
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая является набором руководящих принципов, которые можно использовать для улучшения качества рабочей нагрузки. Дополнительные сведения см. в статье Microsoft Azure Well-Architected Framework.
Availability
С помощью сложного n-уровневого приложения можно не реплицировать все приложение в дополнительном регионе. Вместо этого вы можете просто реплицировать критическую подсистему, необходимую для обеспечения непрерывной работы бизнеса.
Диспетчер трафика — это точка возможного сбоя в системе. Если служба Диспетчер трафика завершается ошибкой, клиенты не могут получить доступ к приложению во время простоя. Просмотрите соглашение об уровне обслуживания диспетчера трафика и подумайте, достаточно ли диспетчера трафика в соответствии с требованиями к высокой доступности в вашей организации. Если это не так, добавьте резервное решение для управления трафиком. Если в службе диспетчера трафика Azure произошел сбой, измените записи CNAME в службе доменных имен, чтобы они указывали на резервную службу управления трафиком. (Этот шаг нужно выполнить вручную, приложение будет отключено, пока изменения DNS не распространятся.)
В кластере SQL Server необходимо учитывать два сценария отработки отказа:
Происходит сбой всех реплик базы данных SQL Server в основном регионе. Например, этот сбой может произойти во время регионального сбоя. В этом случае необходимо вручную переключить группу доступности, несмотря на то, что диспетчер трафика автоматически переключается на внешнем интерфейсе. Выполните шаги в статье Perform a Forced Manual Failover of a SQL Server Availability Group (Выполнение принудительного перехода на другой ресурс вручную для группы доступности (SQL Server)), в которой описано, как выполнять принудительный переход на другой ресурс с помощью SQL Server Management Studio, Transact-SQL или PowerShell в SQL Server 2016.
Предупреждение
При принудительной отработки отказа существует риск потери данных. Когда основной регион будет восстановлен, сделайте моментальный снимок базы данных и используйте tablediff, чтобы найти отличия.
Диспетчер трафика выполняет отработку отказа в дополнительный регион, однако основная реплика базы данных SQL Server все еще доступна. Например, сбой внешнего уровня может не затронуть виртуальные машины SQL Server. В этом случае интернет-трафик направляется в дополнительный регион, а этот регион может все еще подключиться к основной реплике. Тем не менее будет увеличена задержка, так как подключения SQL Server пересекают регионы. В этом случае следует выполнить отработку отказа вручную следующим образом:
- Временно переключите базу данных SQL Server в дополнительный регион для синхронной фиксации. Этот шаг гарантирует, что во время отработки отказа не будет потери данных.
- Выполните отработку отказа с переходом к этой реплике.
- При восстановлении размещения в основном регионе восстановите параметр асинхронной фиксации.
Управляемость
При обновлении развертывания обновляйте один регион за раз, чтобы уменьшить вероятность глобального сбоя из-за неправильной конфигурации или ошибки в приложении.
Проверьте устойчивость системы к сбоям. Ниже приведены некоторые распространенные сценарии сбоев для тестирования:
- завершение работы экземпляров виртуальной машины;
- нехватка ресурсов, таких как ЦП и память;
- отключение или задержка сети;
- прекращение работы процессов;
- завершение срока действия сертификатов;
- моделирование сбоев оборудования;
- завершение работы службы DNS на контроллерах домена.
Измерьте время восстановления и убедитесь, что оно соответствует вашим бизнес-требованиям. Следует также протестировать комбинации режимов отказа.
Оптимизация затрат
Оптимизация затрат заключается в поиске способов уменьшения ненужных расходов и повышения эффективности работы. Дополнительные сведения см. в разделе Обзор критерия "Оптимизация затрат".
Используйте калькулятор цен Azure для оценки затрат. Ниже приведены некоторые другие соображения.
Масштабируемые наборы виртуальных машин
Масштабируемые наборы виртуальных машин доступны во всех размерах виртуальных машин Windows. Плата взимается только за развернутые виртуальные машины Azure и все добавленные базовые ресурсы инфраструктуры, которые используются, такие как хранилище и сеть. Для службы Масштабируемые наборы виртуальных машин плата не взимается.
Сведения о ценах на отдельные виртуальные машины см. в разделе о ценах на виртуальные машины Windows.
Сервер SQL Server
Если выбрать DBaas SQL Azure, вы можете сэкономить на затратах, так как не нужно настраивать группу доступности AlwaysOn и компьютеры контроллера домена. Существует несколько вариантов развертывания, начиная с одной базы данных до управляемого экземпляра или эластичных пулов. Дополнительные сведения см. в ценах на SQL Azure.
Цены на виртуальные машины SQL Server см. в разделе о ценах на виртуальные машины SQL.
Подсистемы балансировки нагрузки
Плата взимается только за количество настроенных правил балансировки нагрузки и исходящего трафика. За правила преобразования сетевых адресов (NAT) плата не взимается. Почасовая плата за Load Balancer (цен. категория не взимается, если правила не настроены.
Цены на диспетчер трафика
Тарификация за использование диспетчера трафика основана на количестве получаемых запросов DNS, при этом предоставляется дополнительная скидка для служб, которые получают свыше 1 миллиарда запросов в месяц. Кроме того, взимается плата за каждую отслеживаемую конечную точку.
См. сведения о затратах на платформу Microsoft Azure с продуманной архитектурой.
Цены на пиринг между виртуальными сетями
Развертывание с высоким уровнем доступности, использующее несколько регионов Azure, будет использовать пиринг виртуальной сети. Существуют различные расходы на пиринг между виртуальными сетями в одном регионе и для глобальной одноранговой виртуальной сети.
Дополнительные сведения см. в разделе о ценах на виртуальная сеть.
DevOps
Используйте один шаблон Azure Resource Manager для подготовки ресурсов Azure и его зависимостей. Используйте один и тот же шаблон для развертывания ресурсов как в первичных, так и в дополнительных регионах. Включите все ресурсы в одну виртуальную сеть, чтобы они изолированы в одной базовой рабочей нагрузке. Включив все ресурсы, вы упрощаете связывание конкретных ресурсов рабочей нагрузки с командой DevOps, чтобы команда могли самостоятельно управлять всеми аспектами этих ресурсов. Эта изоляция позволяет DevOps Team и Services выполнять непрерывную интеграцию и непрерывную доставку (CI/CD).
Кроме того, вы можете использовать различные шаблоны Azure Resource Manager и интегрировать их с Azure DevOps Services для подготовки различных сред в минутах, например для репликации рабочих сред, таких как сценарии или среды нагрузочного тестирования только при необходимости, экономия затрат.
Мы рекомендуем использовать Azure Monitor для анализа и оптимизации производительности инфраструктуры, отслеживания и диагностики проблем с сетью без входа на виртуальные машины. Фактически Application Insights — это один из компонентов платформы Azure Monitor, которая предоставляет разнообразные метрики и журналы, отображающие состояние всего ландшафта Azure. Azure Monitor поможет вам следовать состоянию инфраструктуры.
Не только отслеживайте вычислительные элементы, поддерживающие код приложения, но и платформу данных, в частности базы данных, так как низкая производительность уровня данных приложения может иметь серьезные последствия.
Чтобы протестировать среду Azure, в которой выполняются приложения, она должна управлять версиями и развертываться с помощью тех же механизмов, что и код приложения, а затем его можно протестировать и проверить с помощью парадигм тестирования DevOps.
Дополнительные сведения см. в разделе "Эффективность работы" в Microsoft Azure Well-Architected Framework.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участниками.
Автор субъекта:
- Донни Трамповер | Старший архитектор облачных решений
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.
Следующие шаги
Связанные ресурсы
В следующей архитектуре используются одни и те же технологии: