Руководство. Синхронизация данных из SQL Edge в хранилище BLOB-объектов Azure с помощью Фабрика данных Azure
Важно!
Azure SQL Edge больше не поддерживает платформу ARM64.
В этом руководстве показано, как использовать Фабрика данных Azure для добавочной синхронизации данных с хранилищем BLOB-объектов Azure из таблицы в экземпляре SQL Azure Edge.
Подготовка к работе
Если вы еще не создали базу данных или таблицу в SQL Azure для пограничных вычислений, создайте ее одним из приведенных ниже способов.
Подключитесь к SQL Azure для пограничных вычислений с помощью SQL Server Management Studio или Azure Data Studio. Запустите скрипт SQL, чтобы создать базу данных и таблицу.
Создайте базу данных и таблицу с помощью sqlcmd путем прямого подключения к модулю SQL Edge. Дополнительные сведения см. в статье о подключении к ядру СУБД с помощью sqlcmd.
С помощью программы SQLPackage.exe разверните файл пакета приложения уровня данных в контейнере SQL Azure для пограничных вычислений. Вы можете автоматизировать этот процесс, указав URI файла SqlPackage в качестве части необходимой конфигурации свойств модуля. Вы также можете использовать клиентское средство SqlPackage.exe напрямую для развертывания пакета приложения уровня данных в SQL Azure для пограничных вычислений.
Сведения о скачивании и установке средства SqlPackage.exe см. в этой статье. Ниже приведены некоторые примеры команд для SqlPackage.exe. Дополнительные сведения см. в документации по SqlPackage.exe.
Создание пакета приложения уровня данных
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>Применение пакета приложения уровня данных
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
Создание таблицы SQL и процедуры для хранения и обновления водяных знаков
Таблица водяных знаков используется для хранения последней метки времени, данные до которой уже синхронизированы со службой хранилища Azure. Таблица водяных знаков обновляется после каждой синхронизации с помощью хранимой процедуры Transact-SQL (T-SQL).
Выполните приведенные ниже команды в экземпляре SQL Azure для пограничных вычислений.
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Создание конвейера Фабрики данных
В этом разделе вы создадите конвейер Фабрики данных Azure для синхронизации данных из таблицы в SQL Azure для пограничных вычислений с хранилищем BLOB-объектов Azure.
Создание Фабрики данных с помощью пользовательского интерфейса Фабрики данных
Создайте Фабрику данных, следуя инструкциям в этом учебнике.
Создание конвейера Фабрики данных
На странице Начало работы в пользовательском интерфейсе Фабрики данных выберите Создать конвейер.

На странице Общие в окне Свойства для конвейера введите имя PeriodicSync.
Добавьте первое действие поиска, которое получает старое значение водяного знака. На панели Действия разверните элемент Общие и перетащите действие Поиск в область конструктора конвейера. Измените имя действия на OldWatermark.
Перейдите на вкладку Параметры и щелкните Создать в области Source Dataset (Исходный набор данных). Вы создадите набор данных для представления данных в таблице водяных знаков. В этой таблице содержится старый нижний предел, который использовался в предыдущей операции копирования.
В окне Новый набор данных выберите Azure SQL Server, а затем нажмите кнопку Продолжить.
В окне Установка свойств для набора данных введите WatermarkDataset в поле Имя.
В поле Связанная служба, выберитеСоздать, а затем выполните следующие действия:
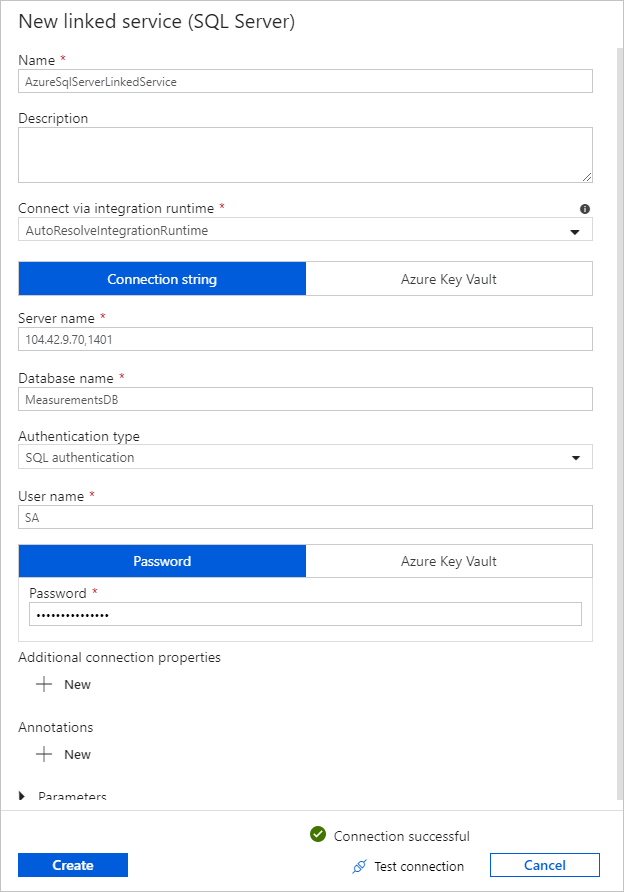
В поле Имя введите SQLDBEdgeLinkedService.
В поле Имя сервера введите сведения о сервере SQL Azure для пограничных вычислений.
Выберите имя базы данных из списка.
Введите имя пользователя и пароль.
Чтобы проверить подключение к экземпляру SQL Azure для пограничных вычислений, нажмите кнопку Проверить подключение.
Нажмите кнопку создания.
Нажмите ОК.
На вкладке Параметры щелкните Изменить.
На вкладке Подключение ion выберите
[dbo].[watermarktable]для таблицы. Если вы хотите просмотреть данные в таблице, нажмите кнопку Просмотр данных.Перейдите в редактор конвейеров, выбрав вкладку конвейера вверху или имя конвейера в представлении в виде дерева слева. В окне свойств для действия "Поиск" убедитесь в том, что в списке Source dataset (Исходный набор данных) выбран вариант WatermarkDataset.
На панели Действия разверните элемент Общие и перетащите другое действие Поиск в область конструктора конвейера. На вкладке Общие в окне свойств задайте имя NewWatermark. Это действие поиска получает новое значение водяного знака из таблицы, где содержатся исходные данные для копирования в место назначения.
В окне свойств второго действия "Поиск" перейдите на вкладку Параметры и нажмите кнопку Создать, чтобы создать набор данных, который будет указывать на исходную таблицу с новым значением водяного знака.
В окне Новый набор данных выберите SQL Edge instance (Экземпляр SQL Azure для пограничных вычислений) и нажмите кнопку Продолжить.
В окне Установка свойств в поле Имя введите SourceDataset. В поле Связанная служба выберите SQLDBEdgeLinkedService.
В поле Таблица выберите таблицу, которую нужно синхронизировать. Вы можете также указать запрос для этого набора данных, как будет описано далее в этом учебнике. Этот запрос будет более приоритетным, чем указанная на этом шаге таблица.
Нажмите ОК.
Перейдите в редактор конвейеров, выбрав вкладку конвейера вверху или имя конвейера в представлении в виде дерева слева. В окне свойств для действия "Поиск", убедитесь, что в списке Source dataset (Исходный набор данных) выбран вариант SourceDataset.
Выберите Запрос в поле Использовать запрос. Обновите имя таблицы в следующем запросе, а затем введите запрос. Вы выбираете только максимальное значение
timestampиз таблицы. Обязательно установите флажок First row only (Только первая строка).SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];
В области Действия разверните узел Move & Transform (Переместить и преобразовать) и перетащите действие Копирование из области Действия в область конструктора. Присвойте этому действию имя IncrementalCopy.
Соедините оба действия поиска с действием копирования, перетащив зеленую кнопку от действий поиска к действию копирования. Когда цвет границы для действия копирования изменится на синий, отпустите кнопку мыши.
Выберите действие "Копирование" и проверьте его свойства в окне Свойства.
Откройте вкладку Источник в окне Свойства и выполните здесь следующие действия.
Выберите SourceDataset в поле Source dataset (Исходный набор данных).
Выберите Запрос в поле Использовать запрос.
Введите SQL-запрос в поле Запрос. Вот пример запроса:
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';На вкладке Приемник выберите Новый в поле Sink Dataset (Набор данных приемника).
В этом учебнике в качестве хранилища данных, применяемого как приемник, используется хранилище BLOB-объектов Azure. Выберите Хранилище BLOB-объектов Azure, а затем нажмите кнопку Продолжить в окне Новый набор данных.
В окне Выбор формата выберите формат данных, а затем нажмите кнопку Продолжить.
В окне Set Properties (Установка свойств) в поле Имя введите SinkDataset. В разделе Связанная служба выберите Создать. Вы создадите подключение (связанную службу) для хранилища BLOB-объектов Azure.
В окне New Linked Service (Azure Blob storage) (Новая связанная служба (хранилище BLOB-объектов Azure)) выполните указанные ниже действия.
Введите AzureStorageLinkedService в поле Имя.
В поле Имя учетной записи хранения выберите учетную запись хранения Azure с вашей подпиской Azure.
Проверьте подключение и нажмите кнопку Готово.
Убедитесь, что в окне Set Properties (Установка свойств) в списке Связанная служба выбрано AzureStorageLinkedService. Щелкните Создать и нажмите кнопку ОК.
На вкладке Приемник выберите Изменить.
Перейдите на вкладку Подключение в SinkDataset и выполните указанные ниже действия.
В разделе "Путь к файлу" введите
asdedatasync/incrementalcopyимяasdedatasyncконтейнера BLOB-объектов иincrementalcopyимя папки. Создайте контейнер (если его еще нет) или присвойте ему имя имеющегося контейнера. Фабрика данных Azure автоматически создает выходную папкуincrementalcopy, если она не существует. Можно также нажать кнопку Обзор рядом с полем Путь к файлу, чтобы перейти к нужной папке в контейнере больших двоичных объектов.Для части файла в пути к файлу выберите "Добавить динамическое содержимое " [ALT+P], а затем введите
@CONCAT('Incremental-', pipeline().RunId, '.txt')в открывающееся окно. Выберите Готово. Это выражение динамически создает имя файла. Каждый запуск конвейера имеет уникальный идентификатор. Действие копирования использует этот идентификатор запуска при создании имени файла.
Перейдите в редактор конвейеров, выбрав вкладку конвейера вверху или имя конвейера в представлении в виде дерева слева.
На панели Действия разверните элемент Общие, а затем перетащите действие Хранимая процедура с панели Действия в область конструктора конвейера. Соедините результаты действия "Копирование", обозначенные зеленым цветом, с действием "Хранимая процедура".
Выберите действие хранимой процедуры в конструкторе конвейеров и измените его имя
SPtoUpdateWatermarkActivityна .Перейдите на вкладку Учетная запись SQL и выберите *QLDBEdgeLinkedService в разделе Связанная служба.
Перейдите на вкладку Хранимая процедура и выполните здесь следующие действия:
В разделе "Имя хранимой процедуры" выберите
[dbo].[usp_write_watermark].Чтобы указать значения для параметров хранимой процедуры, выберите Import parameter (Импорт параметров) и введите следующие значения.
Имя. Тип значение LastModifiedTime Дата/время @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName Строка @{activity('OldWaterMark').output.firstRow.TableName}Чтобы проверить настройки конвейера, нажмите кнопку Проверить на панели инструментов. Убедитесь, что проверка завершается без ошибок. Чтобы закрыть окно Pipeline Validation Report (Отчет о проверке конвейера), нажмите кнопку >>.
Опубликуйте сущности (связанные службы, наборы данных и конвейеры) в службе "Фабрика данных Azure", щелкнув Опубликовать все. Подождите, пока появится сообщение, подтверждающее, что операция публикации прошла успешно.
Активация конвейера на основе расписания
На панели инструментов конвейера выберите Добавить триггер, щелкните New/Edit (Создать или изменить), а затем выберите Создать.
Присвойте триггеру имя HourlySync. В поле Тип выберите Расписание. Установите для параметра Повторение значение "Каждый час".
Нажмите ОК.
Выберите Опубликовать все.
Выберите Запустить сейчас.
Перейдите на вкладку Мониторинг слева. Здесь вы увидите, что конвейер запущен вручную. Щелкните Обновить, чтобы обновить список.
Следующие шаги
- Конвейер Фабрики данных Azure в этом учебнике копирует данные из таблицы в экземпляре SQL Azure для пограничных вычислений в расположение в хранилище BLOB-объектов Azure раз в час. Перейдите к этим учебникам, чтобы узнать об использовании Фабрики данных в других сценариях.