Копирование данных из Хранилища BLOB-объектов Azure в базу данных в службе "База данных SQL Azure" с помощью Фабрики данных Azure
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этом руководстве вы создадите фабрику данных с помощью пользовательского интерфейса фабрики данных Azure. Конвейер этой фабрики данных копирует данные из Хранилища BLOB-объектов Azure в базу данных в службе "База данных SQL Azure". Шаблон конфигурации в этом руководстве применяется к копированию из файлового в реляционное хранилище данных. Список хранилищ данных, которые поддерживаются в качестве источников и приемников, см. в таблице Поддерживаемые хранилища данных и форматы.
Примечание.
Если вы еще не работали с фабрикой данных, ознакомьтесь со статьей Введение в фабрику данных Azure.
Вот какие шаги выполняются в этом учебнике:
- Создали фабрику данных.
- создание конвейера с действием копирования;
- тестовый запуск конвейера;
- активация конвейера вручную;
- запуск конвейера по расписанию;
- Мониторинг конвейера и выполнения действий.
Необходимые компоненты
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure, прежде чем начинать работу.
- Учетная запись хранения Azure. В этом руководстве в качестве источника будет использоваться хранилище BLOB-объектов. Если у вас нет учетной записи хранения, создайте ее, следуя действиям в этом разделе.
- База данных SQL Azure. Используйте базу данных как хранилище данных-приемник. Если у вас нет базы данных в службе "База данных SQL Azure", вы можете создать ее, выполнив инструкции из краткого руководства Создание отдельной базы данных в Базе данных SQL Azure.
Создание большого двоичного объекта и таблицы SQL
Теперь подготовьте хранилище больших двоичных объектов и базу данных SQL к изучению этого руководства, выполнив следующие действия.
Создание исходного большого двоичного объекта
Запустите Блокнот. Скопируйте следующий текст и сохраните его в файл emp.txt на диске.
FirstName,LastName John,Doe Jane,DoeСоздайте контейнер с именем adftutorial в хранилище BLOB-объектов. Создайте папку input в этом контейнере. Затем отправьте файл emp.txt в папку input. Эти задачи можно выполнить с помощью портала Azure или специальных средств, таких как Обозреватель службы хранилища Azure.
Создание таблицы-приемника SQL
Чтобы создать в своей базе данных таблицу dbo.emp, используйте следующий скрипт SQL:
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);Предоставьте службам Azure доступ к серверу SQL Server. Убедитесь, что параметр Разрешить доступ к службам Azure имеет состояние Вкл. для вашего сервера SQL Server, чтобы фабрика данных могла записывать данные на него. Чтобы проверить и при необходимости включить этот параметр, перейдите к логическому серверу SQL Server, выберите >Обзор > Настройка брандмауэра для сервера>, а затем задайте для параметра Разрешить доступ к службам Azure значение Вкл.
Создание фабрики данных
На этом этапе вы создадите фабрику данных и запустите пользовательский интерфейс службы "Фабрика данных" для создания конвейера в фабрике данных.
Откройте Microsoft Edge или Google Chrome. Сейчас только эти браузеры поддерживают пользовательский интерфейс фабрики данных.
В меню слева последовательно выберите элементы Создать ресурс>Интеграция>Фабрика данных.
На странице Создание фабрики данных на вкладке Основные сведения выберите подписку Azure, в рамках которой вы хотите создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий:
a. Выберите существующую группу ресурсов из раскрывающегося списка.
b. Выберите Создать новую и укажите имя новой группы ресурсов.
Сведения о группах ресурсов см. в статье Общие сведения об Azure Resource Manager.
В поле Регион выберите расположение фабрики данных. В раскрывающемся списке отображаются только поддерживаемые расположения. Хранилища данных (например, служба хранилища Azure и база данных SQL) и вычислительные ресурсы (например, Azure HDInsight), используемые фабрикой данных, могут располагаться в других регионах.
В поле Имя введите ADFTutorialDataFactory.
Имя фабрики данных Azure должно быть глобально уникальным. Если вы увидите следующую ошибку касательно значения имени, введите другое имя фабрики данных. (Например, используйте yournameADFTutorialDataFactory.) Дополнительные сведения о правилах именования артефактов фабрики данных см. в статье Фабрика данных Azure — правила именования.
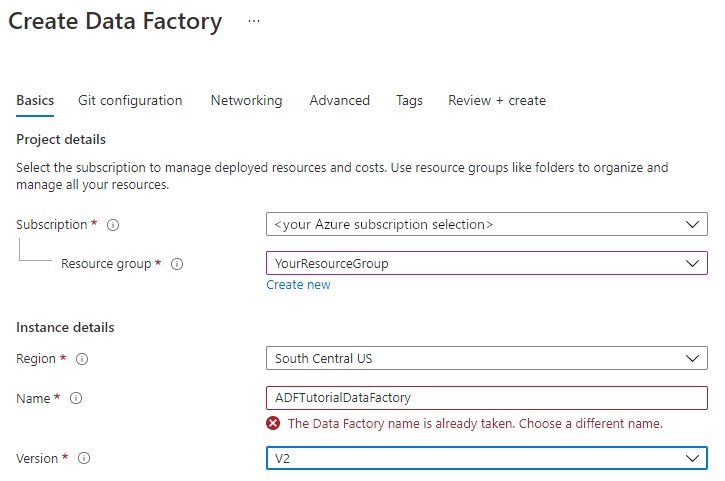
В качестве версии выберите V2.
Выберите вкладку Git configuration (Конфигурация Git) в верхней части экрана и установите флажок Configure Git later (Настроить Git позже).
Щелкните Просмотр и создание и выберите Создать после прохождения проверки.
После завершения создания вы увидите уведомление в центре уведомлений. Нажмите кнопку Перейти к ресурсу, чтобы открыть страницу фабрики данных.
Выберите Открыть на плитке Open Azure Data Factory Studio (Открыть студию Фабрики данных Azure), чтобы запустить пользовательский интерфейс Фабрики данных на отдельной вкладке.
Создание конвейера
На этом шаге вы создадите в фабрике данных конвейер с действием копирования. Это действие копирования копирует данные из хранилища BLOB-объектов в базу данных SQL. В предыдущем руководстве вы создали конвейер, выполнив следующие действия:
- Создание связанной службы.
- Создание входных и выходных наборов данных.
- Создание конвейера.
В этом руководстве вы сразу приступите к созданию конвейера, а связанные службы и наборы данных будете создавать по мере необходимости для настройки конвейера.
На домашней странице выберите Orchestrate (Оркестрация).
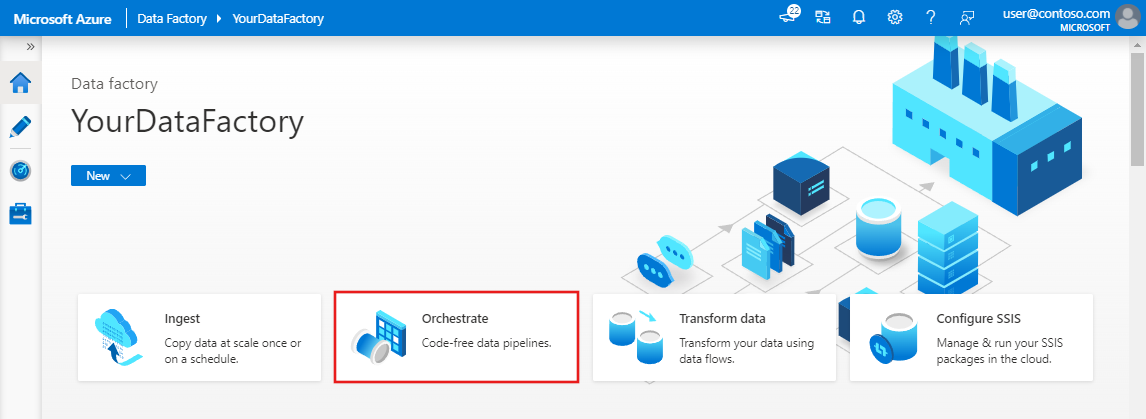
В разделе Свойства на панели "Общие сведения" укажите для параметра Имя значение CopyPipeline. Затем сверните панель, щелкнув значок Свойства в правом верхнем углу.
На панели элементов Действия разверните категорию Move and Transform (Переместить и преобразовать) и перетащите действие Копирование данных из панели элементов в область конструктора конвейера. Введите CopyFromBlobToSql в поле Имя.
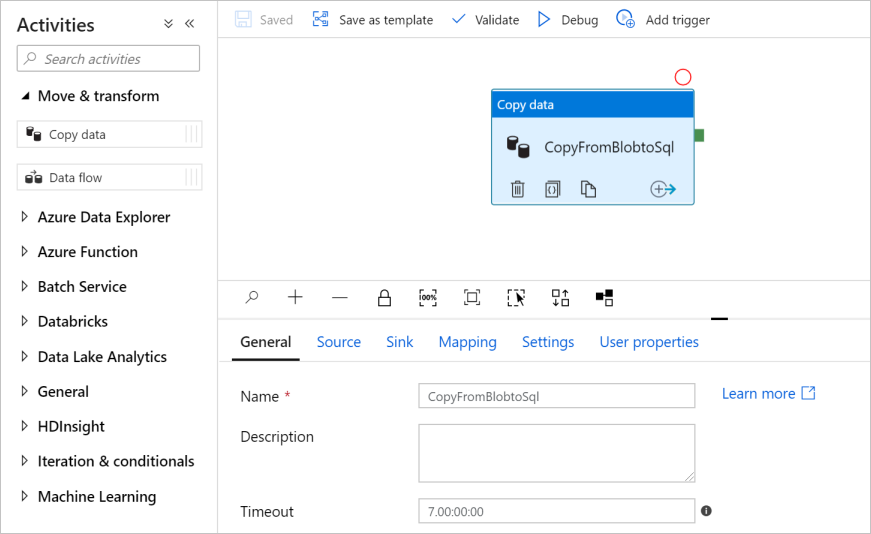
Настройка источника
Совет
В этом руководстве вы используете ключ учетной записи в качестве типа проверки подлинности для исходного хранилища данных, но при необходимости можно выбрать другие поддерживаемые методы проверки подлинности: URI SAS, субъект-служба и управляемое удостоверение . Дополнительные сведения см. в соответствующих разделах этой статьи. Чтобы безопасно хранить секреты для хранилищ данных, также рекомендуется использовать Azure Key Vault. Дополнительные сведения см. в этой статье.
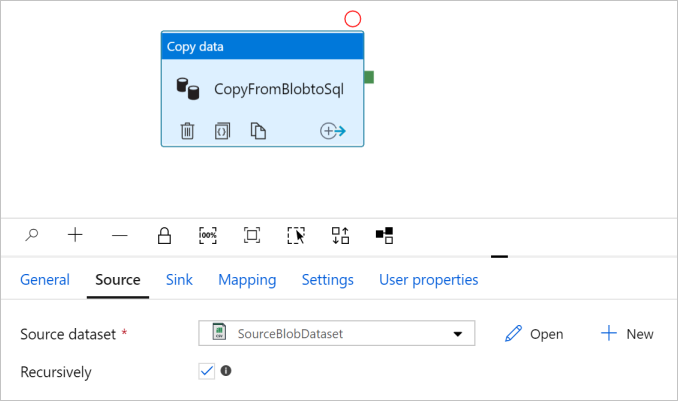
Перейдите на вкладку "Источник ". Нажмите +Создать , чтобы создать исходный набор данных.
В диалоговом окне Новый набор данных выберите Хранилище BLOB-объектов Azure и щелкните Продолжить. Выберите Хранилище BLOB-объектов для исходного набора данных, потому что именно там находится источник данных.
В диалоговом окне Выбор формата выберите тип формата ваших данных, а затем нажмите кнопку Продолжить.
В диалоговом окне Установка свойств введите SourceBlobDataset в качестве имени. Установите флажок Использовать первую строку в качестве заголовка. В текстовом поле Связанная служба выберите + Создать.
В окне New Linked Service (Azure Blob Storage) (Новая связанная служба (хранилище BLOB-объектов Azure)) в качестве имени введите AzureStorageLinkedService и выберите учетную запись хранения в списке Имя учетной записи хранения. Проверьте подключение и нажмите кнопку Создать, чтобы развернуть связанную службу.
После создания связанной службы откроется страница Установка свойств. Рядом с полем Путь к файлу выберите Обзор.
Перейдите к папке adftutorial/input, выберите файл emp.txt и нажмите кнопку ОК.
Нажмите ОК. Автоматически откроется страница конвейера. Убедитесь, что на вкладке Источник выбрано значение SourceBlobDataset. Чтобы просмотреть данные на этой странице, выберите Просмотр данных.
Настройка приемника
Совет
В этом руководстве вы используете проверку подлинности SQL в качестве типа проверки подлинности для хранилища данных приемника, но при необходимости можно выбрать другие поддерживаемые методы проверки подлинности: субъект-служба и управляемое удостоверение . Дополнительные сведения см. в соответствующих разделах этой статьи. Чтобы безопасно хранить секреты для хранилищ данных, также рекомендуется использовать Azure Key Vault. Дополнительные сведения см. в этой статье.
Перейдите на вкладку Приемник и выберите + Создать, чтобы создать целевой набор данных.
В диалоговом окне Новый набор данных введите SQL в окне поиска, чтобы отфильтровать соединители, а затем выберите База данных SQL Azure и нажмите кнопку Продолжить. В этом руководстве вы будете копировать данные в базу данных SQL.
В диалоговом окне Установка свойств введите OutputSqlDataset в качестве имени. В раскрывающемся списке Связанная служба выберите + Создать. Связанную службу нужно сопоставить с набором данных. Связанная служба содержит строку подключения, которая потребуется фабрике данных для подключения к Базе данных SQL во время выполнения. Набор данных определяет контейнер, папку и (необязательно) файл, куда копируются данные.
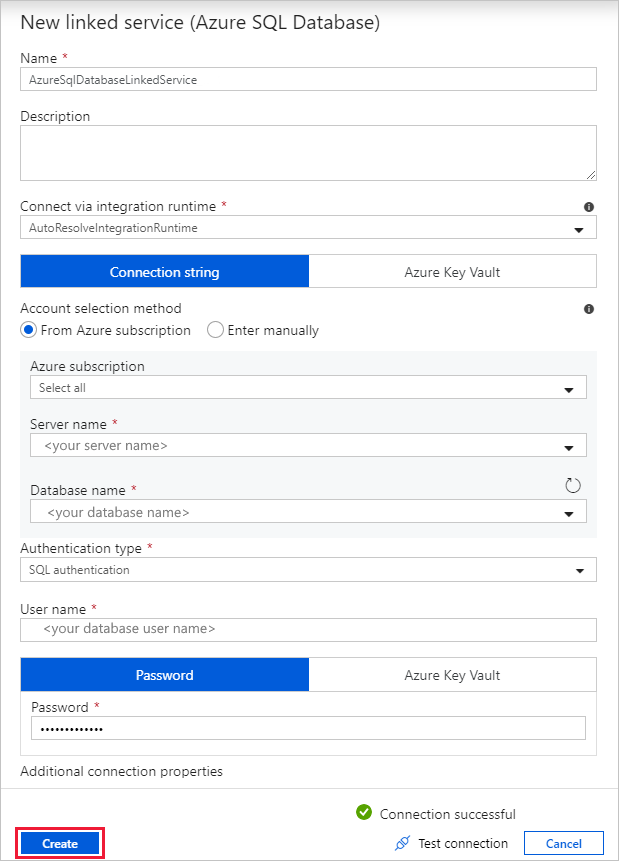
В диалоговом окне New Linked Service (Azure SQL Database) (Новая связанная служба (База данных SQL Azure)) сделайте следующее:
a. В поле Имя введите AzureSqlDatabaseLinkedService.
b. В списке Имя сервера выберите необходимый экземпляр SQL Server.
c. В списке Имя базы данных выберите нужную базу данных.
d. В поле Имя пользователя введите имя пользователя.
д) В поле Пароль введите пароль для этого пользователя.
е) Выберите Проверить подключение, чтобы проверить подключение.
ж. Выберите Создать, чтобы развернуть связанную службу.
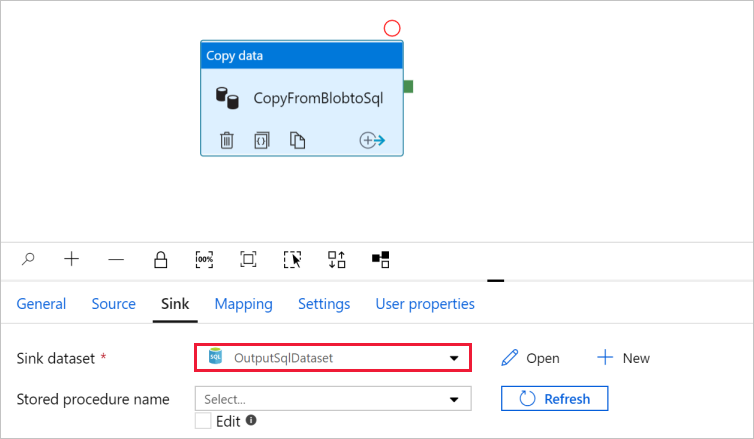
Автоматически откроется диалоговое окно Установка свойств. В поле Таблица выберите [dbo].[emp]. Затем выберите OK.
Перейдите на вкладку с конвейером и убедитесь, что в поле Sink Dataset (Целевой набор данных) выбрано значение OutputSqlDataset.
При необходимости вы можете сопоставить схему источника с соответствующей схемой назначения, выполнив действия в статье Сопоставление схемы в действии копирования.
Проверка конвейера
Чтобы проверить параметры конвейера, на панели инструментов выберите Проверить.
Чтобы отобразить код JSON, соответствующий конвейеру, щелкните Код в правом верхнем углу.
Отладка и публикация конвейера
Вы можете отладить работу конвейера, прежде чем публиковать артефакты (связанные службы, наборы данных и конвейер) в фабрике данных или вашем собственном репозитории Git Azure Repos.
Чтобы выполнить отладку конвейера, на панели инструментов щелкните Отладка. Состояние выполнения конвейера вы можете найти на вкладке Выходные данные в нижней части окна.
После успешного запуска конвейера в верхней панели инструментов выберите Опубликовать все. Это действие опубликует созданные сущности (наборы данных и конвейеры) в фабрике данных.
Дождитесь сообщения Опубликовано. Чтобы отобразить уведомления, щелкните Показать уведомления в правом верхнем углу (кнопка в виде колокольчика).
Aктивация конвейера вручную
На этом шаге вы вручную запустите конвейер, опубликованный ранее.
Выберите Trigger (Запустить) на панели инструментов, а затем Trigger Now (Запустить сейчас). На странице Запуск конвейера щелкните ОК.
Перейдите на вкладку Мониторинг слева. Вы увидите выполнение конвейера, которое вы только что активировали вручную. Ссылки в столбце Имя конвейера позволят вам просмотреть подробные сведения о действиях и повторно выполнить конвейер.

Чтобы просмотреть выполнение действий, связанных с выполнением конвейера, выберите ссылку CopyPipeline в столбце Имя конвейера. В нашем примере определено только одно действие, поэтому в списке вы увидите только одну запись. Чтобы увидеть сведения об операции копирования, щелкните ссылку Сведения (значок очков) в столбце Название действия. Выберите Все запуски конвейеров в верхней части окна, чтобы вернуться к представлению "Выполнения конвейеров". Чтобы обновить список, нажмите кнопку Обновить.

Убедитесь, что в таблицу emp в базе данных добавлены две новые строки.

запуск конвейера по расписанию;
В этом разделе вы создадите триггер планировщика для выполнения конвейера. Этот триггер запускает конвейер по определенному расписанию (каждый час или каждый день). В этом разделе вы настроите триггер, который выполняется каждую минуту до указанного времени окончания.
Перейдите на вкладку Автор слева над вкладкой монитора.
Перейдите в конвейер, щелкните Триггер на панели инструментов и выберите Создать/изменить.
В диалоговом окне Add Trigger (Добавление триггеров) выберите + Создать в области Выберите триггер.
В окне New Trigger (Создание триггера) выполните следующие действия.
a. В поле Имя введите RunEveryMinute.
b. Обновите дату начала для своего триггера. Если дата предшествует текущему значению даты и времени, триггер начнет действовать после публикации изменения.
c. Разверните раскрывающийся список в поле Часовой пояс.
d. Установите для параметра Повторение значение Каждые 1 мин.
д) Установите флажок для параметра Укажите дату окончания и обновите элемент Окончание в, задав значение на несколько минут позднее текущего значения даты и времени. Триггер начнет работу только после публикации изменений. Если вы настроите разницу всего в одну-две минуты и не успеете за это время опубликовать триггер, он не будет выполнен.
е) Для параметра Активировать выберите Да.
ж. Нажмите ОК.
Важно!
Каждое выполнение конвейера оплачивается. Поэтому здесь важно правильно указать дату окончания.
Прочитайте предупреждение на странице Изменение триггера и выберите Готово. Конвейер в этом примере не принимает параметры.
Щелкните Опубликовать все, чтобы опубликовать изменения.
Перейдите на вкладку Мониторинг слева, чтобы увидеть активированные выполнения конвейера.

Чтобы перейти от представления запусков конвейера к представлению запусков триггера, выберите Trigger Runs (Запуски триггера) в левой области окна.
Вы увидите в списке выполнения своего триггера.
Проследите, как в таблицу emp добавляются по две строки в минуту (для каждого выполнения конвейера) вплоть до указанного времени окончания.
Связанный контент
В этом примере конвейер копирует данные из одного расположения в другое в хранилище BLOB-объектов. Вы научились выполнять следующие задачи:
- Создали фабрику данных.
- создание конвейера с действием копирования;
- тестовый запуск конвейера;
- активация конвейера вручную;
- запуск конвейера по расписанию;
- Мониторинг конвейера и выполнения действий.
Перейдите к следующему руководству, чтобы узнать о копировании данных из локальной среды в облако: