Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к:![]() База данных SQL Azure
База данных SQL Azure![]() базе данных SQL в Fabric
базе данных SQL в Fabric
Динамические административные представления можно запрашивать с помощью T-SQL для мониторинга производительности рабочей нагрузки и диагностики проблем с производительностью, которые могут быть вызваны заблокированными или длительными запросами, узкими местами ресурсов, неоптимальными планами запросов и т. д.
Для графического мониторинга ресурсов запросов используйте хранилище запросов.
Подсказка
Рассмотрите возможность автоматической настройки базы данных для автоматического повышения производительности запросов.
Отслеживание использования ресурсов
Вы можете отслеживать использование ресурсов на уровне базы данных с помощью следующих динамических административных представлений.
sys.dm_db_resource_stats
Так как это представление предоставляет подробные данные об использовании ресурсов, сначала используйте sys.dm_db_resource_stats для любого анализа текущего состояния или устранения неполадок. Например, этот запрос показывает среднее и максимальное использование ресурсов для текущей базы данных за последний час:
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
В sys.dm_db_resource_stats представлении показаны последние данные об использовании ресурсов относительно ограничений размера вычислительных ресурсов. Проценты ЦП, операций ввода-вывода данных, записи журналов, рабочих потоков и использования памяти в сторону ограничения записываются каждые 15-секундный интервал и сохраняются примерно в течение одного часа.
Другие примеры запросов см. в sys.dm_db_resource_stats.
sys.resource_stats
Представление sys.resource_stats в master базе данных содержит дополнительные сведения, которые помогут отслеживать производительность базы данных на определенном уровне служб и размере вычислительных ресурсов. Данные собираются каждые 5 минут и хранятся приблизительно 14 дней. Это представление полезно для анализа использования ресурсов Базы данных за более долгий период.
На следующей диаграмме показано почасовое использование ресурсов процессора для базы данных уровня служб "Премиум" с объемом вычислительных ресурсов P2 в течение недели. Этот график начинается в понедельник, показывает пять рабочих дней, а затем показывает выходные дни, когда гораздо меньше происходит в приложении.
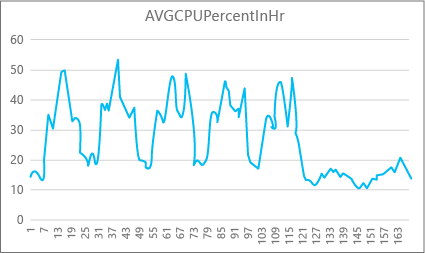
Судя по этим данным, пиковая нагрузка на процессор составляет чуть более 50 % от максимальной нагрузки для объема вычислительных ресурсов P2 (полдень вторника). Если мощность процессора является главным фактором в ресурсном профиле приложения, то вы можете решить, что P2 — это правильный размер вычислительных ресурсов, который гарантирует, что рабочая нагрузка всегда подходила. Если ожидается рост нагрузки на приложение с течением времени, рекомендуется увеличить запас ресурсов, чтобы приложения не достигло предела производительности. Увеличив объем вычислительных ресурсов, можно избежать заметных пользователю ошибок, которые могут возникнуть из-за нехватки в базе данных мощности для эффективной обработки запросов, особенно в средах, чувствительных к задержкам.
Для других типов приложений можно интерпретировать тот же график по-разному. Например, если приложение обрабатывало данные по зарплате каждый день и получало ту же диаграмму, то выполнение таких "пакетных заданий" будет эффективным и для объема вычислительных ресурсов P1. Размер вычислительных ресурсов P1 имеет 100 DTU по сравнению с 200 DTU у размера P2. Таким образом, объем вычислительных ресурсов P1 предоставляет половину объема вычислительных ресурсов P2. Таким образом, 50 процентов использования ЦП на уровне P2 равняется 100 процентам использования ЦП на уровне P1. Если в работе приложения не возникает пауз, возможно, не имеет значения, сколько времени выполняется задание — 2 или 2,5 часа, а важно только, чтобы оно было завершено сегодня. Приложение такой категории может использовать объем вычислительных ресурсов Р1. Вы можете воспользоваться тем, что в определенные периоды дня использование ресурсов ниже, так что любая "высокая нагрузка" может перейти на один из более поздних периодов снижения нагрузок в течение дня. Объем вычислительных ресурсов Р1 может отлично подойти для такого приложения (и сэкономить деньги), если задания будут завершаться вовремя в течение одного дня.
Ядро СУБД предоставляет сведения о потребляемых ресурсах для каждой активной базы данных в sys.resource_stats представлении master базы данных на каждом логическом сервере. Данные в представлении агрегируются с интервалами в 5 минут. Это может занять несколько минут, чтобы эти данные отображались в таблице, поэтому sys.resource_stats более полезно для анализа исторических данных, а не для анализа в режиме реального времени. Запросите представление sys.resource_stats, чтобы увидеть последние изменения базы данных и убедиться, что выбранный вами размер вычислительных ресурсов обеспечивал необходимую производительность.
Примечание.
Необходимо подключиться к master базе данных для запроса sys.resource_stats в следующих примерах.
В этом примере показаны данные в sys.resource_stats:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
В следующем примере показаны различные способы использования представления каталога для получения сведений о том sys.resource_stats , как база данных использует ресурсы:
Чтобы просмотреть использование ресурса прошлой недели для пользовательской базы данных
userdb1, можно выполнить этот запрос, подставив собственное имя базы данных:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Чтобы оценить, насколько хорошо ваша рабочая нагрузка соответствует размеру вычислительных ресурсов, необходимо детализировать каждый аспект метрик ресурсов: ЦП, данные ввода-вывода, запись журналов, количество рабочих ролей и количество сеансов. Ниже приведен измененный запрос, который используется
sys.resource_statsдля отчета о средних и максимальных значениях этих метрик ресурсов для каждого размера вычислительных ресурсов, для которых подготовлена база данных:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;С помощью средних и максимальных значений по каждому ресурсу можно оценить, насколько выбранный объем вычислительных ресурсов подходит для вашей рабочей нагрузки. Обычно средние значения из
sys.resource_statsпредоставляют хорошую основу для сравнения с целевым размером.Для баз данных по модели приобретения DTU:
Например, вы можете использовать уровень служб "Стандартный" с объемом вычислительных ресурсов S2. При этом средняя нагрузка на процессор и число операций чтения и записи ввода-вывода составляют меньше 40 %, среднее число рабочих ролей — меньше 50, а среднее количество сеансов — меньше 200. Под вашу рабочую нагрузку может подойти размер вычислительных ресурсов S1. Вы легко можете увидеть, соответствует ли ваша база данных ограничениям для рабочих и сеансов. Чтобы узнать, соответствует ли база данных более низкому размеру вычислений, разделите число DTU меньшего размера вычислений на число DTU текущего размера вычислений, а затем умножьте результат на 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Результатом будет относительная разница производительности между двумя объемами вычислительных ресурсов в процентах. Если использование ресурса не превышает этот процент, рабочая нагрузка может соответствовать более низкому размеру вычислительных ресурсов. Однако необходимо рассмотреть все диапазоны значений использования ресурсов и определить, в процентах, как часто рабочая нагрузка базы данных будет вписываться в рамки меньшего размера вычислительных ресурсов. Следующий запрос выводит процент соответствия для каждого измерения ресурса на основе 40-процентного порога, который мы рассчитали в этом примере.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;В зависимости от уровня служб базы данных вы можете определить, подходит ли более низкий объем вычислительных ресурсов для вашей рабочей нагрузки. Если целевой показатель рабочей нагрузки составляет 99,9 % и указанный выше запрос возвращает значение больше 99,9 % для всех трех измерений ресурсов, весьма вероятно, что рабочую нагрузку можно выполнять с более низким объемов вычислительных ресурсов.
Просмотр процента соответствия также поможет вам понять, нужно ли перейти на следующий более высокий объем вычислительных ресурсов для достижения вашей цели. Например, использование ЦП для образца базы данных за прошлую неделю:
Средняя нагрузка ЦП, % Максимальная нагрузка ЦП, % 24,5 100.00 Средняя нагрузка ЦП равна приблизительно одной четвертой ограничения объема вычислительных ресурсов, что вполне соответствует объему вычислительных ресурсов базы данных.
Для баз данных, использующих модель приобретения DTU и модель приобретения виртуальных ядер:
Максимальное значение показывает, что база данных достигает предела размера вычислительных ресурсов. Требуется ли перейти на более высокий объем вычислительных ресурсов? Определите, сколько раз рабочая нагрузка достигает 100 %, и сравните это значение с целевым показателем рабочей нагрузки базы данных.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Эти проценты — это количество примеров рабочей нагрузки, подходящих для текущего размера вычислительных ресурсов. Если этот запрос возвращает значение менее 99,9 процента для любого из трех измерений ресурсов, выборка средней рабочей нагрузки превысила ограничения. Рассмотрите возможность перехода к следующему более высокому размеру вычислительных ресурсов или используйте методы настройки приложений, чтобы уменьшить нагрузку на базу данных.
sys.dm_elastic_pool_resource_stats
Применимо только к:![]() База данных SQL Azure только
База данных SQL Azure только
sys.dm_db_resource_stats
Аналогичным образом sys.dm_elastic_pool_resource_stats предоставляет последние и детализированные данные об использовании ресурсов для эластичного пула База данных SQL Azure. Представление можно запрашивать в любой базе данных в эластичном пуле, чтобы предоставить данные об использовании ресурсов для всего пула, а не для какой-либо конкретной базы данных. Процентные значения, предоставляемые этим DMV, соответствуют ограничениям эластичного пула, которые могут быть выше ограничений для базы данных в этом пуле.
В этом примере показаны суммированные данные об использовании ресурсов для текущего эластичного пула за последние 15 минут:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
Если вы обнаружите, что любое использование ресурсов приближается к 100 % в течение значительного периода времени, может потребоваться проверить использование ресурсов для отдельных баз данных в одном эластичном пуле, чтобы определить, сколько каждая база данных способствует использованию ресурсов на уровне пула.
sys.elastic_pool_resource_stats
Применимо только к:![]() База данных SQL Azure только
База данных SQL Azure только
sys.resource_stats
Аналогичным образом sys.elastic_pool_resource_stats в master базе данных предоставляют данные об использовании ресурсов для всех эластичных пулов на логическом сервере. Вы можете использовать sys.elastic_pool_resource_stats для исторического мониторинга за последние 14 дней, включая анализ тенденций использования.
В этом примере показаны суммированные данные об использовании ресурсов за последние семь дней для всех эластичных пулов на текущем логическом сервере. Выполните запрос в master базе данных.
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
Одновременные запросы
Чтобы просмотреть текущее количество одновременных запросов, выполните этот запрос в пользовательской базе данных:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
Это только моментальный снимок в один момент времени. Для лучшего понимания рабочей нагрузки и требований к параллельным запросам потребуется собрать большое количество примеров с течением времени.
Средняя скорость запроса
В этом примере показано, как найти среднюю частоту запросов для базы данных или базы данных в эластичном пуле с течением времени. В этом примере период времени имеет значение 30 секунд. Его можно изменить, изменив инструкцию WAITFOR DELAY . Выполните этот запрос в пользовательской базе данных. Если база данных находится в эластичном пуле и имеется достаточно разрешений, результаты включают другие базы данных в эластичном пуле.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
Текущие сеансы
Чтобы просмотреть количество текущих активных сеансов, выполните этот запрос в базе данных:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
Этот запрос возвращает количество точек во времени. Сбор нескольких образцов за определенный период времени обеспечивает лучшее понимание использования сеансов.
Недавняя история запросов, сеансов и работников
В этом примере возвращается недавнее историческое использование запросов, сеансов и потоков выполнения для базы данных или баз данных в эластичном пуле. Каждая строка представляет моментальный снимок использования ресурсов в определенный момент времени для базы данных. Столбец requests_per_second — это средняя скорость запроса в течение интервала времени, который заканчивается в snapshot_time. Если база данных находится в эластичном пуле и имеется достаточно разрешений, результаты включают другие базы данных в эластичном пуле.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
Вычисление размеров базы данных и объектов
Следующий запрос возвращает размер данных в базе данных (в мегабайтах):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Следующий запрос возвращает размер отдельных объектов базы данных в мегабайтах:
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Выявление проблем производительности ЦП
В этом разделе описаны отдельные запросы, которые являются главными потребителями ЦП.
Если потребление ЦП превышает 80 % в течение длительного периода времени, рассмотрите следующие действия по устранению неполадок, возникающих в настоящее время или произошедших в прошлом. Вы также можете выполнить действия, описанные в этом разделе, чтобы заранее определить основные запросы на использование ЦП и настроить их. В некоторых случаях снижение потребления ЦП может привести к уменьшению масштаба баз данных и эластичных пулов и экономии затрат.
Действия по устранению неполадок одинаковы для автономных баз данных и баз данных в эластичном пуле. Выполните все запросы в пользовательской базе данных.
Проблема с ЦП происходит сейчас
Если проблема происходит прямо сейчас, существует два возможных сценария:
Множество отдельных запросов, которые в совокупности потребляют много ресурсов ЦП
Используйте следующий запрос, чтобы определить топ-запросы по хэшу запросов:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
Длительные запросы, использующие ЦП, все еще выполняются
Используйте следующий запрос для идентификации этих запросов:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
Проблема с ЦП была в прошлом
Если проблема возникла в прошлом и вы хотите найти первопричину, используйте хранилище запросов. Пользователи с доступом к базе данных могут использовать T-SQL для запроса данных из хранилища запросов. По умолчанию хранилище запросов записывает статистические статистические данные запросов за один час.
Используйте следующий запрос для анализа активности запросов с высоким использованием ЦП. Этот запрос возвращает 15 самых ресурсоемких запросов. Не забудьте изменить
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE(), чтобы просматривать период времени, отличный от последних двух часов.-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Когда вы найдете проблемные запросы, настройте их для снижения нагрузки на ЦП. Кроме того, можно увеличить объем вычислительных ресурсов базы данных или эластичного пула, чтобы обойти проблему.
Дополнительные сведения об обработке проблем с производительностью ЦП в База данных SQL Azure см. в статье "Диагностика и устранение неполадок с высоким уровнем ЦП в База данных SQL Azure".
Поиск проблем производительности операций ввода-вывода
При выявлении проблем с производительностью ввода-вывода данных хранилища основные типы ожиданий:
PAGEIOLATCH_*Проблемы с вводом и выводом данных (включая
PAGEIOLATCH_SH,PAGEIOLATCH_EX,PAGEIOLATCH_UP). Если в имени типа ожидания есть IO, это указывает на проблему ввода-вывода. Если в названии ожидания блокировки страницы отсутствует IO, это указывает на другой тип проблемы, не связанной с производительностью хранения данных (например,tempdbконфликт).WRITE_LOGПроблемы с вводом-выводом журнала транзакций.
Если проблема ввода-вывода возникает прямо сейчас
Используйте sys.dm_exec_requests или sys.dm_os_waiting_tasks, чтобы посмотреть wait_type и wait_time.
Определение использования данных и журнального ввода-вывода
Используйте следующий запрос для определения данных и журнального ввода-вывода.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Дополнительные примеры использования sys.dm_db_resource_statsсм. в разделе "Мониторинг использования ресурсов" в следующей части этой статьи.
Если достигнуто ограничение ввода-вывода, у вас есть два варианта:
- повышение объема вычислительных ресурсов или уровня служб.
- Определите и настройте запросы, потребляющие большинство операций ввода-вывода.
Просмотр операций ввода-вывода, связанных с буфером, с помощью хранилища запросов
Чтобы определить основные запросы из-за ожидания ввода-вывода, можно использовать следующий запрос из Хранилища запросов для просмотра активности за последние два часа.
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
Вы также можете использовать представление sys.query_store_runtime_stats, сосредоточив внимание на запросах с большими значениями в столбцах avg_physical_io_reads и avg_num_physical_io_reads.
Просмотр общего журнала операций ввода-вывода для ожиданий WRITELOG
Если тип ожидания имеет значение WRITELOG, используйте следующий запрос, чтобы просмотреть общий объем операций ввода-вывода журнала по инструкции:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Определение проблем с производительностью tempdb
Распространенные типы ожидания, связанные с tempdb проблемами, — PAGELATCH_* (не PAGEIOLATCH_*). Однако PAGELATCH_* ожидания не всегда означают tempdb конфликт. Это ожидание также может означать, что у вас есть конфликт на странице данных пользовательского объекта из-за параллельных запросов, направленных на ту же страницу данных. Чтобы подтвердить конкуренцию, используйте sys.dm_exec_requests для подтверждения того, что значение tempdb начинается с 2:x:y, где 2 является идентификатором базы данных tempdb, x является идентификатором файла и y является идентификатором страницы.
Для устранения tempdb распространенный метод заключается в сокращении или перезаписи кода приложения, в котором используется tempdb. Распространенные области использования tempdb:
- Временные таблицы
- Табличные переменные
- Параметры табличного типа
- Запросы с планами запросов, которые используют сортировку, хэш-соединения и буферы
Для получения дополнительной информации см. tempdb в Azure SQL.
Все базы данных в эластичном пуле используют одну и ту же tempdb базу данных. Высокая tempdb загрузка пространства одной базой данных может повлиять на другие базы данных в одном эластичном пуле.
Основные запросы, использующие табличные переменные и временные таблицы
Используйте следующий запрос для идентификации основных запросов, использующих табличные переменные и временные таблицы:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Определите длительные транзакции
Используйте следующий запрос, чтобы определить длительные транзакции. Длительные транзакции предотвращают очистку постоянного хранилища версий (PVS). Дополнительные сведения см. в статье Устранение неполадок ускоренного восстановления баз данных.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Определение проблем с производительностью при ожидании выделения памяти
Если среди ваших типов ожидания на первом месте RESOURCE_SEMAPHORE, может возникнуть проблема с предоставлением памяти, из-за которой запросы не могут запускаться, пока они не получат достаточно большой объем памяти.
Определить, является ли ожидание RESOURCE_SEMAPHORE наиболее часто используемым
Используйте следующий запрос, чтобы определить, является ли RESOURCE_SEMAPHORE ожидание наибольшим ожиданием. Кроме того, свидетельством этому может служить повышение рейтинга времени ожидания RESOURCE_SEMAPHORE в последнее время. Дополнительные сведения об устранении неполадок с ожиданием предоставления памяти см. в статье "Устранение проблем с медленной производительностью или низкой памятью, вызванных предоставлением памяти в SQL Server".
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Определение операторов, потребляющих большой объем памяти
При возникновении в Базе данных SQL Azure ошибок, связанных с нехваткой памяти, см. сведения в статье о sys.dm_os_out_of_memory_events. Дополнительные сведения см. в статье "Устранение ошибок с памятью с помощью База данных SQL Azure".
Сначала измените следующий скрипт, чтобы обновить соответствующие значения start_time и end_time. Затем выполните следующий запрос, чтобы определить операторы с высоким потреблением памяти.
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Определение десяти основных временно предоставляемых буферов памяти
Используйте следующий запрос для определения десяти самых активных предоставлений памяти.
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Мониторинг подключений
Представление sys.dm_exec_connections можно использовать для получения сведений о подключениях к определенной базе данных и о деталях каждого подключения. Если база данных находится в эластичном пуле и у вас есть достаточные разрешения, представление возвращает набор подключений для всех баз данных в эластичном пуле. Кроме того, представление sys.dm_exec_sessions позволяет получить сведения обо всех активных подключениях пользователя и внутренних задачах.
Просмотр текущих сеансов
Следующий запрос получает сведения о текущем подключении и сеансе. Чтобы просмотреть все подключения и сеансы, удалите WHERE предложение.
Все выполняемые сеансы в базе данных видны только в том случае, если у вас есть VIEW DATABASE STATE разрешение на базу данных при использовании представлений sys.dm_exec_requests и sys.dm_exec_sessions. В противном случае отображается только текущий сеанс.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Мониторинг производительности запросов
Медленные или длительные запросы могут потреблять значительные системные ресурсы. В этом разделе показано, как использовать динамические административные представления для обнаружения нескольких распространенных проблем с производительностью запросов с помощью динамического представления управления sys.dm_exec_query_stats . Представление содержит одну строку для каждой инструкции запроса в закэшированном плане, а время жизни строк зависит от самого плана. Когда план удаляется из кэша, соответствующие строки исключаются из представления. Если запрос не имеет кэшированного плана, например, потому что используется OPTION (RECOMPILE), он отсутствует в результатах этого представления.
Поиск основных запросов по времени ЦП
В следующем примере возвращаются сведения о 15 лучших запросах, ранжированных по среднему времени ЦП на выполнение. В этом примере выполняется сбор запросов по хэшу запроса, то есть логически схожие запросы группируются по общему потреблению ресурсов.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
Следите за планами запросов для общего накопленного времени работы ЦП
Неэффективный план запросов также может увеличить потребление ЦП. В следующем примере определяется, какой из запросов использует наибольшее общее время использования ЦП в недавней истории.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Мониторинг заблокированных запросов
Медленные или длительные запросы могут вызывать избыточное потребление ресурсов, что приводит к блокировке запросов. Причиной блокировки может быть неэффективная структура приложений, неудачные планы запросов, отсутствие полезных индексов и т. д.
Вы можете использовать представление sys.dm_tran_locks для получения сведений о текущей активности блокировки в базе данных. Примеры кода см. в sys.dm_tran_locks. Дополнительные сведения об устранении неполадок с блокировкой см. в статье Изучение и устранение проблем с блокировкой SQL Azure.
Наблюдайте за взаимоблокировками
В некоторых случаях два или более запросов могут блокировать друг друга, что приводит к взаимоблокировке.
Вы можете создать трассировку расширенных событий для записи событий взаимоблокировки, а затем найти связанные запросы и планы их выполнения в хранилище запросов. Дополнительные сведения см. в разделе "Анализ и предотвращение взаимоблокировок" в базе данных SQL Azure, включая лабораторную работу по вызову взаимоблокировки в AdventureWorksLT. Узнайте больше о типах ресурсов, которые могут приводить к взаимоблокировке.
Разрешения
В базе данных Azure SQL, в зависимости от размера вычислений, параметра развертывания и данных в динамическом административном представлении (DMV), могут потребоваться разрешения либо VIEW DATABASE STATE, либо VIEW SERVER PERFORMANCE STATE, либо VIEW SERVER SECURITY STATE. Последние два разрешения включены в VIEW SERVER STATE разрешение. Просмотр разрешений состояния сервера предоставляется через членство в соответствующих ролях сервера. Чтобы определить, какие разрешения требуются для запроса определенного динамического административного представления (DMV), ознакомьтесь с разделом Динамические административные представления и найдите статью, описывающую это представление.
Чтобы предоставить VIEW DATABASE STATE разрешение пользователю базы данных, выполните следующий запрос, заменив database_user на имя пользователя в базе данных.
GRANT VIEW DATABASE STATE TO [database_user];
Чтобы предоставить членству в серверной роли ##MS_ServerStateReader## логин с именем login_name на логическом сервере, подключитесь к базе данных master, а затем выполните следующий запрос в качестве примера:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
Для принятия в силу разрешения может потребоваться несколько минут. Дополнительные сведения см. в разделе "Ограничения ролей уровня сервера".
Связанный контент
- Диагностика и устранение неполадок с высокой загрузкой ЦП в Базе данных SQL Azure
- Настройка приложений и баз данных для повышения производительности в Базе данных SQL Azure
- Изучение и устранение проблем с блокировкой Базы данных SQL Azure
- Анализ и предотвращение взаимоблокировок в Базе данных SQL Azure
- Анализ производительности запросов
- sys.dm_db_resource_stats
- sys.resource_stats
- sys.dm_elastic_pool_resource_stats
- sys.elastic_pool_resource_stats