Ускорение анализа больших данных в реальном времени с помощью соединителя Spark
Применимо к:![]() База данных SQL Azure Управляемый экземпляр SQL Azure
База данных SQL Azure Управляемый экземпляр SQL Azure ![]()
Примечание.
По состоянию на сентябрь 2020 г. этот соединитель уже не поддерживается на должном уровне. Однако теперь доступен соединитель Apache Spark для SQL Server и SQL Azure с поддержкой привязок Python и R, простым в использовании интерфейсом для выполнения операций массовой вставки данных и многими другими улучшениями. Настоятельно рекомендуется оценить новый соединитель и использовать его вместо прежнего. Сведения о старом соединителе (эта страница) поддерживаются только в целях архивации.
Соединитель Spark позволяет базам данных в Базе данных SQL Azure, Управляемом экземпляре SQL Azure и SQL Server действовать в качестве источника входных данных или приемника выходных данных для заданий Spark. Это позволяет использовать данные о транзакциях в реальном времени при анализе больших данных и сохранять результаты для нерегламентированных запросов или отчетов. По сравнению со встроенным соединителем JDBC этот соединитель обеспечивает возможность массовой вставки данных в базу данных. Он может в 10–20 раз превосходить по производительности вставку по строкам. Соединитель Spark поддерживает проверку подлинности с помощью идентификатора Microsoft Entra (ранее Azure Active Directory) для подключения к База данных SQL Azure и Управляемый экземпляр SQL Azure, что позволяет подключать базу данных из Azure Databricks с помощью учетной записи Microsoft Entra. Она предоставляет аналогичные интерфейсы со встроенным соединителем JDBC. Имеющиеся задания Spark можно легко перенести, чтобы использовать этот соединитель.
Примечание.
Идентификатор Microsoft Entra ранее был известен как Azure Active Directory (Azure AD).
Скачивание и создание соединителя Spark
Репозиторий GitHub для старого соединителя, ранее связанного с этой страницей, уже не поддерживается на должном уровне. Настоятельно рекомендуется оценить новый соединитель и использовать его вместо прежнего.
Официальные поддерживаемые версии
| Компонент | Версия |
|---|---|
| Apache Spark | 2.0.2 или более поздние версии |
| Scala | 2.10 или более поздние версии |
| Драйвер Microsoft JDBC для SQL Server | 6.2 или более поздние версии |
| Microsoft SQL Server | SQL Server 2008 или более поздняя версия |
| База данных SQL Azure | Поддерживается |
| Управляемый экземпляр SQL Azure | Поддерживается |
Соединитель Spark использует Microsoft JDBC Driver для SQL Server, чтобы перемещать данные между рабочими узлами Spark и базами данных.
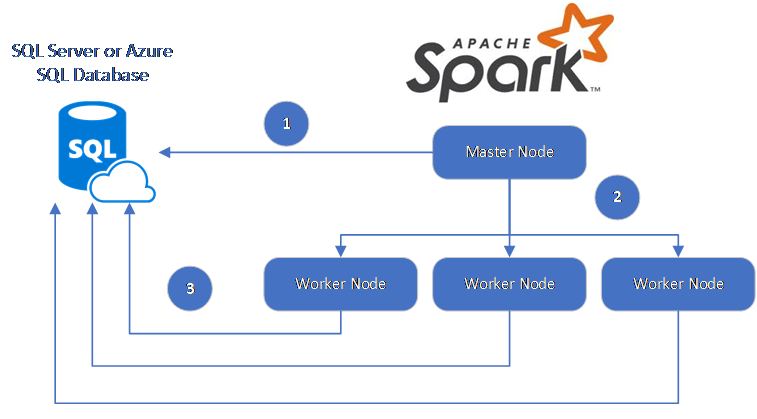
Поток данных выглядит следующим образом:
- Главный узел Spark подключается к базам данных в Базе данных SQL или SQL Server и загружает данные из определенной таблицы или использует специальный SQL-запрос.
- Главный узел Spark распределяет данные в рабочие узлы для преобразования.
- Рабочий узел подключается к базам данных, которые подключаются к Базе данных SQL и SQL Server и записывает данные в базу данных. Пользователь может использовать вставку по строкам или массовую вставку.
На схеме ниже показан поток данных.
Создание соединителя Spark
Сейчас в проекте соединителя используется maven. Чтобы создать соединитель без зависимостей, выполните следующую команду:
- mvn clean package;
- скачать последние версии JAR-файла из папки release;
- включить JAR-файл Базы данных SQL Spark.
Подключение и чтение данных с помощью соединителя Spark
Для чтения или записи данных можно подключаться к базам данных в Базе данных SQL и SQL Server из задания Spark. Кроме того, можно выполнить запрос DML или DDL в базах данных в Базе данных SQL и SQL Server.
Чтение данных из Azure SQL и SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Чтение данных из Azure SQL и SQL Server с помощью указанного SQL-запроса
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Запись данных в Azure SQL или SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Выполнение запроса DML или DDL в Azure SQL и SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Подключение из Spark с помощью проверки подлинности Microsoft Entra
Вы можете подключиться к База данных SQL и Управляемый экземпляр SQL с помощью проверки подлинности Microsoft Entra. Используйте проверку подлинности Microsoft Entra для централизованного управления удостоверениями пользователей базы данных и в качестве альтернативы проверке подлинности SQL.
Подключение с использованием режима аутентификации ActiveDirectoryPassword
Требования к настройке
Если вы используете режим проверки подлинности ActiveDirectoryPassword, необходимо скачать microsoft-authentication-library-for-java и его зависимости и включить их в путь сборки Java.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Подключение с помощью маркера доступа
Требования к настройке
Если вы используете режим проверки подлинности на основе маркеров доступа, необходимо скачать microsoft-authentication-library-for-java и его зависимости и включить их в путь сборки Java.
Ознакомьтесь с проверкой подлинности Microsoft Entra, чтобы узнать, как получить маркер доступа к базе данных в База данных SQL Azure или Управляемый экземпляр SQL Azure.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Запись данных с помощью массовой вставки
Традиционный соединитель JDBC записывает данные в базу данных путем построчной вставки. Соединитель Spark можно использовать для записи данных в Azure SQL и SQL Server с помощью массовой вставки. Это значительно повышает производительность записи при загрузке больших наборов данных или загрузке данных в таблицы, где используется индекс columnstore.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Следующие шаги
Если это еще не сделано, скачайте соединитель Spark из репозитория GitHub azure-sqldb-spark и изучите дополнительные ресурсы в репозитории.
Дополнительные сведения см. также в руководстве по SQL, таблицам и наборам данных Apache Spark и в документации по Azure Databricks.