Возможности при использовании нескольких моделей
Область применения:![]() База данных SQL Azure
База данных SQL Azure![]() Управляемый экземпляр SQL Azure
Управляемый экземпляр SQL Azure ![]() базе данных SQL в Fabric
базе данных SQL в Fabric
Многомодельные базы данных позволяют хранить данные в нескольких форматах, например реляционные данные, графы, JSON- или XML-документы, пространственные данные и пары "ключ — значение", и работать с ними.
Семейство продуктов Azure SQL использует реляционную модель, обеспечивающую наилучшую производительность для различных приложений общего назначения. Однако продукты Azure SQL, такие как База данных SQL Azure и Управляемый экземпляр SQL, не ограничиваются реляционными данными. Они позволяют использовать нереляционные форматы, которые тесно интегрируются в реляционную модель.
Поддержка нескольких моделей в Azure SQL подходит для следующих ситуаций:
- У вас есть информация или структуры, которые лучше подходят для моделей NoSQL и вы не хотите использовать отдельную базу данных NoSQL.
- Большая часть данных подходит для реляционной модели, но некоторые части данных необходимо оформить в стиле NoSQL.
- Вы хотите использовать язык Transact-SQL для запроса и анализа реляционных и NoSQL данных, а затем интегрировать эти данные с инструментами и приложениями, которые могут использовать язык SQL.
- Вы хотите применить такие функции базы данных, как технологии в памяти, чтобы повысить производительность аналитики или обработки структур данных NoSQL. Вы можете использовать репликацию транзакций или читаемые реплики, чтобы создавать копии данных и переносить некоторые рабочие нагрузки аналитики из базы данных — источника.
В следующих разделах описаны наиболее важные возможности поддержки нескольких моделей в Azure SQL.
Примечание.
Вы можете использовать выражение JSONPath, выражения XQuery/XPath, пространственные функции и выражения запроса по графам в одном запросе Transact-SQL для доступа к любым данным, хранящимся в базе данных. Любое средство или язык, поддерживающие выполнение запросов Transact-SQL, также могут использовать этот интерфейс запросов для доступа к данным нескольких моделей. Это ключевое отличие от многомодельных баз данных, таких как Azure Cosmos DB, которое предоставляет специальный API для моделей данных.
Функции графа
Продукты Azure SQL предоставляет возможности графовой базы данных, чтобы моделировать связь "многие ко многим" в базе данных. Граф состоит из узлов (или вершин) и ребер (или связей). Узел представляет сущность (например, пользователя или организацию). Ребро представляет связь между двумя узлами, которые оно связывает (например, отметки "нравится" или друзья).
Ниже приведены некоторые функции, благодаря которым графовая база данных является уникальной.
- Ребра являются сущностями первого класса в графовой базе данных. У них могут быть связанные атрибуты или свойства.
- Одно ребро может гибко соединить несколько узлов в графовой базе данных.
- Вы можете легко выразить запросы на сопоставление шаблонов и навигацию со множеством переходов.
- Вы можно легко выразить транзитивное замыкание и полиморфные запросы.
Связи графа и возможности запроса графа интегрированы в Transact-SQL и получают преимущества использования ядра СУБД SQL Server в качестве основополагающей системы управления базами данных. Функции графа используют стандартные запросы Transact-SQL, улучшенные с помощью оператора графа MATCH, для запроса данных графа.
Реляционная база данных может делать все то же, что и графовая база данных. Тем не менее графовая база данных может упростить выражение определенных запросов. Графовую базу данных следует использовать при наличии следующих условий.
- Необходимо моделировать иерархические данные, в которых один узел может иметь несколько родительских элементов, поэтому нельзя использовать тип данных hierarchyid.
- Приложение имеет сложные связи "многие ко многим". По мере развития приложения добавляются новые связи.
- Вам необходимо анализировать взаимосвязанные данные и связи.
- Вы хотите использовать характерные для графа условия поиска T-SQL, такие как SHORTEST_PATH.
Возможности JSON
Продукты Azure SQL позволяет анализировать и запрашивать данные, представленные в формате JSON (нотация объектов JavaScript), и экспортировать реляционные данные в виде текста JSON. JSON — это основная функция ядра СУБД SQL Server.
Функции JSON позволяют размещать документы JSON в таблицах, преобразовывать реляционные данные в документы JSON и преобразовывать документы JSON в реляционные данные. Для анализа документов можно использовать стандартный язык Transact-SQL, расширенный с помощью функций JSON. Для оптимизации запросов можно также использовать некластеризованные индексы, индексы columnstore или таблицы, оптимизированные для памяти.
JSON — это распространенный формат данных, который используется для обмена данными в современных мобильных и веб-приложениях. Кроме того, формат JSON используется для хранения частично структурированных данных в файлах журнала или базах данных NoSQL. Многие веб-службы REST возвращают результаты в формате текста JSON или принимают данные в формате JSON.
У большинства служб Azure есть конечные точки REST, которые возвращают или используют JSON. Среди этих служб Когнитивный поиск Azure, служба хранилища Azure и Azure Cosmos DB.
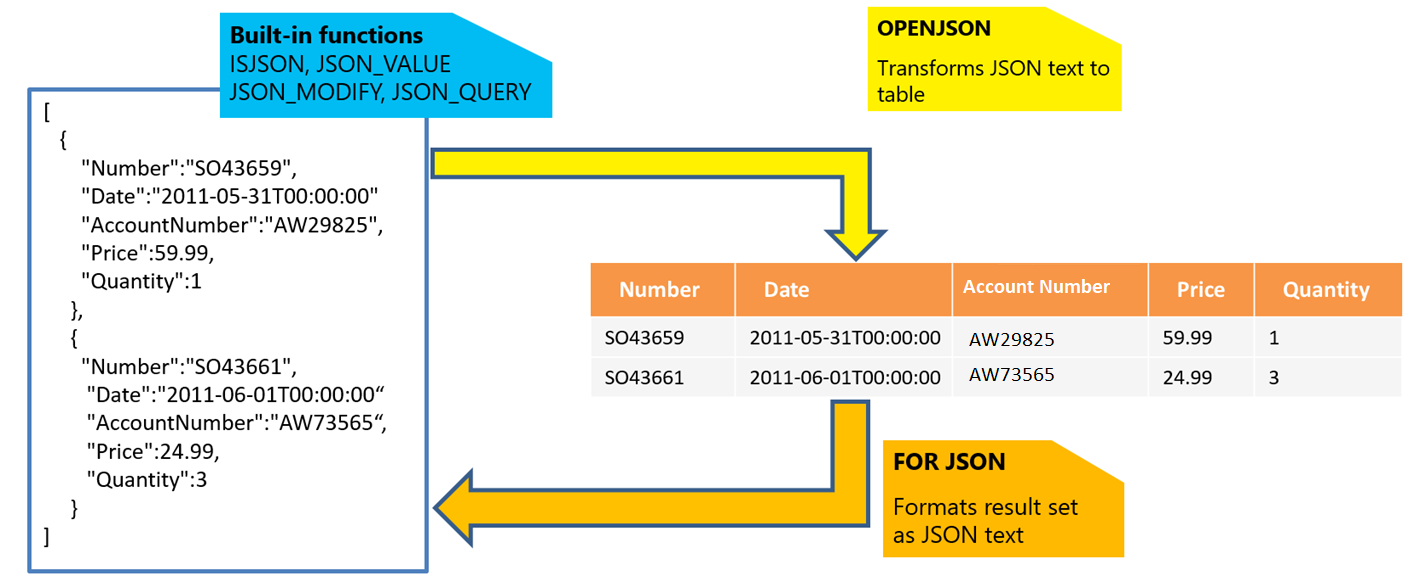
Если имеется текст JSON, то можно извлечь данные из JSON или проверить правильность его форматирования с помощью встроенных функций JSON_VALUE, JSON_QUERY и ISJSON. Другие функции:
- Функция JSON_MODIFY позволяет обновлять значения внутри текста JSON.
- Функция OPENJSON позволяет преобразовать массив объектов JSON в набор строк для более сложных запросов и анализа. С возвращенным результирующим набором можно выполнить любой SQL-запрос.
- Функция FOR JSON позволяет форматировать данные, хранящиеся в реляционных таблицах, в виде текста JSON.
Дополнительные сведения см. в разделе Как работать с данными JSON.
Модели документов могут использоваться вместо реляционных моделей в некоторых сценариях:
- Высокая нормализация схемы не дает значительных преимуществ, так как вы одновременно получаете доступ ко всем полям объектов или никогда не обновляете нормализованные части объектов. Тем не менее нормализованная модель увеличивает сложность запросов из-за большего количества таблиц, которые необходимо соединить для получения данных.
- Вы работаете с приложениями, которые изначально используют JSON-документы и в которых применяются модели обмена данными или модели данных, и вы не хотите вводить дополнительные уровни, преобразующие реляционные данные в формат JSON и наоборот.
- Необходимо упростить модель данных путем отмены нормализации дочерних таблиц или шаблонов "сущность — объект — значение".
- Вам нужно загрузить или экспортировать данные, хранящиеся в формате JSON, без использования дополнительного средства, анализирующего данные.
Функции XML
Возможности XML позволяют хранить, индексировать XML-данные в базе данных и использовать собственные операции XQuery и XPath для работы с XML-данными. У продуктов Azure SQL есть специализированный встроенный тип данных XML и функции запросов, обрабатывающие данные XML.
Ядро СУБД SQL Server предоставляет мощную платформу для разработки приложений для управления частично структурированными данными. Поддержка XML интегрирована во все компоненты ядра СУБД и включает следующие возможности.
- Возможность хранить значения XML в столбце типа XML-данных, который можно типизировать в соответствии с коллекцией схем XML или оставить нетипизированным. XML-столбец можно индексировать.
- Возможность указывать запросы XQuery к XML-данным, хранящимся в столбцах и переменных типа XML. Функции XQuery можно использовать в любом запросе Transact-SQL, который получает доступ к любой модели данных, используемой в базе данных.
- Автоматическое индексирование всех элементов в XML-документах с помощью первичного XML-индекса. Или можно указать точные пути, которые должны индексироваться с помощью вторичного XML-индекса.
OPENROWSET, который позволяет выполнять массовую загрузку XML-данных.- Возможность преобразования реляционных данных в формат XML.
Модели документов могут использоваться вместо реляционных моделей в некоторых сценариях:
- Высокая нормализация схемы не дает значительных преимуществ, так как вы одновременно получаете доступ ко всем полям объектов или никогда не обновляете нормализованные части объектов. Тем не менее нормализованная модель увеличивает сложность запросов из-за большего количества таблиц, которые необходимо соединить для получения данных.
- Вы работаете с приложениями, которые изначально используют XML-документы и в которых применяются модели обмена данными или модели данных, и вы не хотите вводить дополнительные уровни, преобразующие реляционные данные в формат JSON, и наоборот.
- Необходимо упростить модель данных путем отмены нормализации дочерних таблиц или шаблонов "сущность — объект — значение".
- Вам нужно загрузить или экспортировать данные, хранящиеся в формате XML, без использования какого-либо дополнительного средства, анализирующего данные.
Пространственные функции
Пространственные данные представляют сведения о физическом расположении и форме объектов. Этими объектами могут быть точки расположения или более сложные объекты, такие как страны/регионы, дороги или озера.
Azure SQL поддерживает два пространственных типа данных:
- Геометрический тип данных представляет данные в евклидовой (плоской) системе координат.
- а географический — в сферической.
Пространственные функции в Azure SQL позволяют хранить геометрические и географические данные. Пространственные объекты в Azure SQL можно использовать для анализа и запроса данных, представленных в формате JSON, и экспорта реляционных данных в виде текста JSON. Пространственные объекты включают Point, LineString и Polygon. Azure SQL также предоставляет специализированные пространственные индексы, которые можно использовать для повышения производительности пространственных запросов.
Поддержка пространственных объектов — это основная функция ядра СУБД SQL Server.
Пары "ключ-значение"
В продуктах Azure SQL нет специализированных типов или структур, поддерживающих пары "ключ — значение", так как их структуры изначально представляются в виде стандартных реляционных таблиц:
CREATE TABLE Collection (
Id int identity primary key,
Data nvarchar(max)
)
Вы можете настраивать эту структуру пар "ключ — значение" в соответствии со своими потребностями без каких-либо ограничений. Например, значением может быть XML-документ, а не тип nvarchar(max). Если значение является документом JSON, можно использовать ограничение CHECK, проверяющее допустимость содержимого JSON. В дополнительные столбцы можно разместить любое количество значений, связанных с одним ключом. Например:
- Добавьте вычисленные столбцы и индексы, чтобы упростить и оптимизировать доступ к данным.
- Определите таблицу как оптимизированную для памяти и предназначенную только для схемы, чтобы получить лучшую производительность.
Реальный пример эффективного использования реляционной модели в качестве решения для пар "ключ — значение" см. в статье Как bwin использует выполняющуюся в памяти OLTP SQL Server 2016 для достижения беспрецедентной производительности и масштабирования. В этом примере bwin использовал реляционную модель для решения кэширования ASP.NET, чтобы достичь скорости 1,2 млн пакетов в секунду.
Следующие шаги
Поддержка нескольких моделей — это основная функция ядра СУБД SQL Server, которая представлена во всех продуктах Azure. Дополнительные сведения об этих функциях см. в следующих статьях: