Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве описывается, как создать и запустить конвейер в Фабрика данных Azure, который выполняет рабочую нагрузку в пакетная служба Azure. Скрипт Python запускается на узлах пакетной обработки, чтобы получить входные данные, разделенные запятыми (CSV), из контейнера Blob-хранилища Azure, обрабатывать данные и записать выходные данные в другой контейнер хранилища. Пакетный обозреватель Batch Explorer используется для создания пула и узлов пакетной службы, а Обозреватель службы хранилища Azure — для работы с контейнерами и файлами хранилища.
В этом руководстве описано следующее:
- Используйте Batch Explorer для создания пула и узлов в Azure Batch.
- Используйте Обозреватель службы хранилища для создания контейнеров хранилища и отправки входных файлов.
- Разработка скрипта Python для обработки входных данных и создания выходных данных.
- Создайте конвейер "Data Factory", который запускает пакетную рабочую нагрузку.
- Используйте Batch Explorer для просмотра выходных файлов журнала.
Требования
- Учетная запись Azure с активной подпиской. Если ее нет, создайте бесплатную учетную запись.
- Учетная запись службы Batch со связанной учетной записью служба хранилища Azure. Учетные записи можно создать с помощью любого из следующих методов: Azure портал | Azure CLI | Bicep | ARM template | Terraform.
- Экземпляр фабрики данных. Чтобы создать фабрику данных, следуйте инструкциям в статье "Создание фабрики данных".
- Batch Explorer скачан и установлен.
- Обозреватель службы хранилища загружен и установлен.
-
Python 3.8 или более поздней версии с пакетом azure-storage-blob , установленным с помощью
pip. - Набор данных iris.csv, загруженный с GitHub.
Используйте Batch Explorer для создания пула и узлов пакетной обработки
Используйте Batch Explorer для создания пула вычислительных узлов для выполнения рабочей нагрузки.
Войдите в Batch Explorer с помощью учетных данных Azure.
Выберите учетную запись Batch.
Выберите пулы на левой боковой панели и щелкните + значок, чтобы добавить пул.
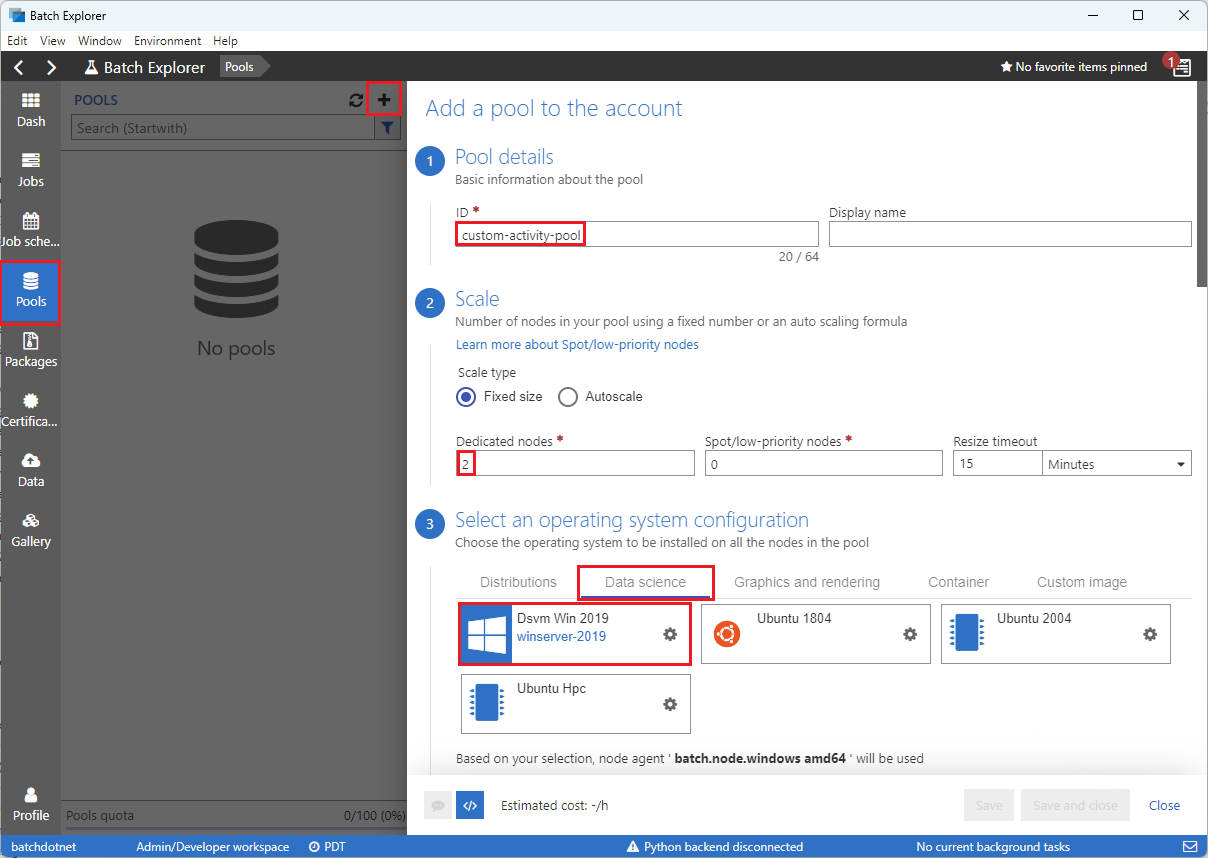
Заполните форму добавления пула в форму учетной записи следующим образом:
- В поле "Идентификатор" введите custom-activity-pool.
- В разделе "Выделенные узлы" введите 2.
- Чтобы выбрать конфигурацию операционной системы, перейдите на вкладку "Обработка и анализ данных", а затем выберите Dsvm Win 2019.
- Для выбора размера виртуальной машины выберите Standard_F2s_v2.
- Для задачи 'Начать' выберите Добавить задачу начала.
На начальном экране задачи в командной строке введите
cmd /c "pip install azure-storage-blob pandas"и нажмите кнопку "Выбрать". Эта команда устанавливаетazure-storage-blobпакет на каждом узле по мере запуска.
Выберите Сохранить и закрыть.

Создайте контейнеры blob с помощью обозревателя службы хранилища
Используйте Обозреватель службы хранилища для создания контейнеров BLOB для хранения входных и выходных файлов, а затем загрузите ваши входные файлы.
- Войдите в Обозреватель службы хранилища с помощью учетных данных Azure.
- На левой панели найдите и разверните учетную запись хранилища, связанную с вашим Batch-аккаунтом.
- Щелкните правой кнопкой мыши контейнеры BLOB-объектов и выберите «Создать контейнер BLOB-объектов», или выберите «Создать контейнер BLOB-объектов» в разделе Действия в нижней части боковой панели.
- Введите текст в поле ввода.
- Создайте другой контейнер объектов с именем output.
- Выберите входнойконтейнер и нажмите кнопку >" в правой области.
- На экране "Отправить файлы" в разделе "Выбранные файлы" выберите многоточие ... рядом с полем записи.
- Перейдите к расположению скачаемого файла iris.csv , выберите "Открыть" и нажмите кнопку "Отправить".

Разработка скрипта Python
Следующий скрипт Python загружает файл набора данных iris.csv из контейнера ввода в Обозревателе хранилища, обрабатывает данные и сохраняет результаты в контейнере выхода.
Сценарий должен использовать строку подключения для учетной записи службы хранилища Azure, которая связана с вашей пакетной учетной записью. Чтобы получить строку подключения, выполните следующие действия.
- В портале Azure найдите и выберите имя учетной записи хранения, связанной с вашей учетной записью Batch.
- На странице учетной записи хранения выберите ключи доступа в левой области навигации в разделе "Безопасность и сеть".
- В разделе key1 выберите "Показать рядом со строкой подключения", а затем щелкните значок "Копировать", чтобы скопировать строка подключения.
Вставьте строку подключения в следующий скрипт, заменив этот <storage-account-connection-string> заполнитель. Сохраните скрипт в виде файла с именем main.py.
Внимание
Экспонирование ключей учетной записи в исходном коде приложения не рекомендуется для использования в продуктивной среде. Необходимо ограничить доступ к учетным данным и ссылаться на них в коде с помощью переменных или файла конфигурации. Оптимальным вариантом является хранение ключей учетной записи Batch и Storage в Azure Key Vault.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Ознакомьтесь с документацией по хранилищу blob-объектов Azure для получения дополнительной информации о его использовании.
Запустите скрипт локально для тестирования и проверки функциональности.
python main.py
Скрипт должен создать выходной файл с именем iris_setosa.csv , который содержит только записи данных с типом = setosa. Убедившись, что он работает правильно, загрузите файл скрипта main.py в входной контейнер Обозревателя службы хранилища.
Настройка конвейера в Data Factory
Создайте и проверьте конвейер фабрики данных, использующий скрипт Python.
Получение данных об учетной записи
Конвейер Фабрики данных использует имена учетных записей Batch и хранения, значения ключей учетной записи и конечную точку учетной записи Batch. Чтобы получить эти сведения из портал Azure, выполните указанные ниже действия.
На панели поиска Azure найдите и выберите имя учетной записи Batch.
На странице учетной записи Batch выберите Ключи в области навигации слева.
На странице "Ключи" скопируйте следующие значения:
- Учетная запись пакетной обработки
- Конечная точка учетной записи
- Первичный ключ доступа
- Имя учетной записи хранения
- Key1
Создание и запуск конвейера
Если Фабрика данных Azure Studio еще не запущена, выберите Запустить студию на странице фабрики данных в портале Azure.
В Студии фабрики данных щелкните значок карандаша "Автор " в области навигации слева.
В разделе Ресурсы фабрики щелкните значок +, а затем выберите Конвейер.
В области свойств справа измените имя конвейера на Запуск Python.
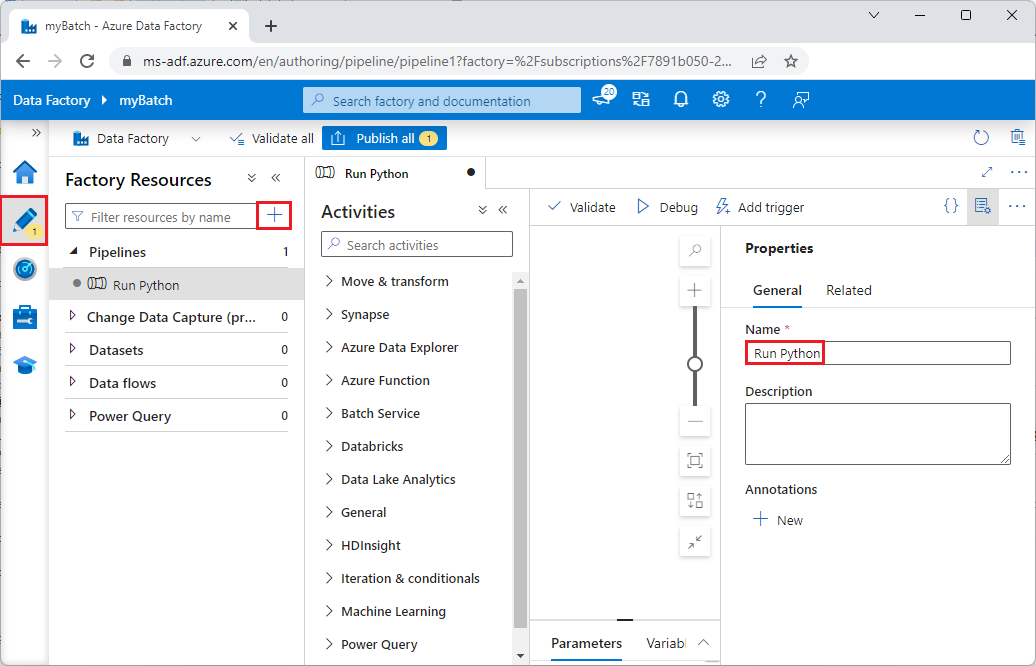
В панели действий разверните Пакетную службу и перетащите пользовательскую деятельность в область конструктора конвейеров.
Под холстом конструктора на вкладке "Общие " введите testPipeline в разделе "Имя".
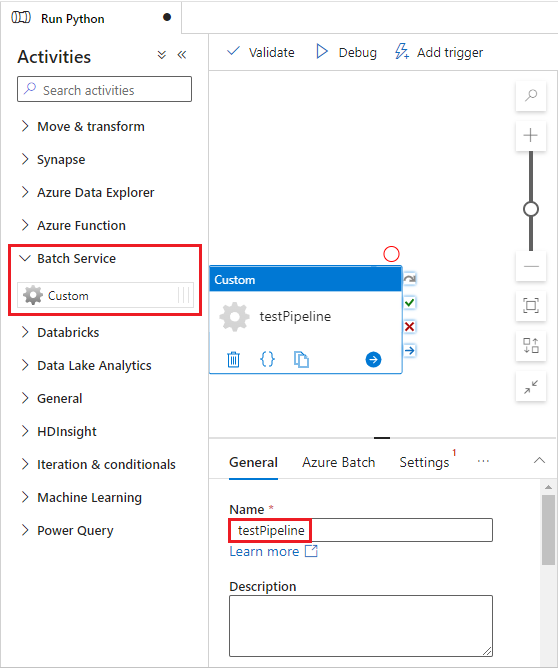
Выберите вкладку пакетная служба Azure и затем выберите Создать.
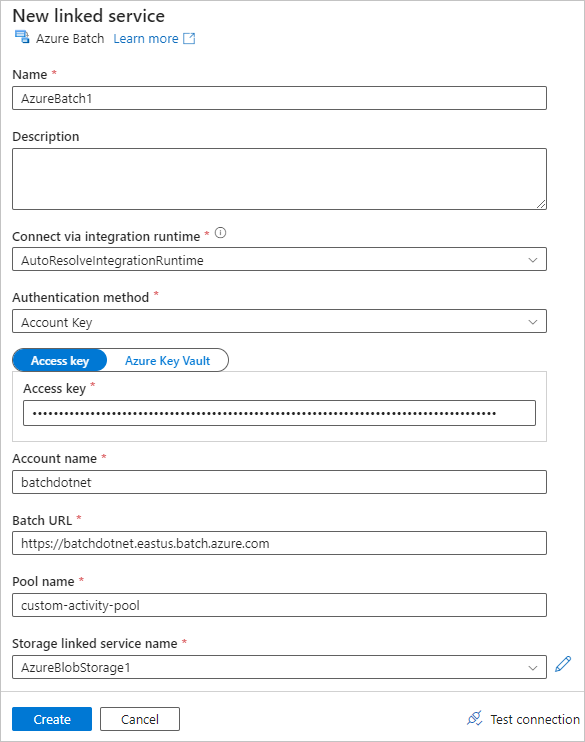
Заполните форму новой связанной службы следующим образом:
- Имя: введите имя связанной службы, например AzureBatch1.
- Ключ доступа: введите основной ключ доступа, скопированный из вашей учетной записи службы Batch.
- Имя учетной записи: введите имя учетной записи Batch.
-
URL пакетной службы: введите адрес конечной точки, скопированный из вашей учетной записи пакетной службы, например
https://batchdotnet.eastus.batch.azure.com. - Имя пула: введите custom-activity-pool, пул, который вы создали в Пакетном обозревателе.
- Имя службы, связанной с учетной записью хранения: выберите Создать. На следующем экране введите имя связанной службы хранилища, например AzureBlobStorage1, выберите подписку Azure и связанную учетную запись хранения, а затем нажмите кнопку "Создать".
В нижней части экрана Создание новой связанной службы, выберите Проверить подключение. Когда подключение выполнено успешно, нажмите кнопку "Создать".
Выберите вкладку "Параметры" и введите или выберите следующие параметры:
-
Команда: Нажмите ВВОД
cmd /C python main.py. - Связанная служба ресурсов: выберите созданную службу связанного хранилища, например AzureBlobStorage1, и проверьте подключение, чтобы убедиться, что оно выполнено успешно.
- Путь к папке: щелкните значок папки, а затем выберите входной контейнер и нажмите кнопку "ОК". Файлы из этой папки скачиваются из контейнера на узлы пула перед запуском скрипта Python.
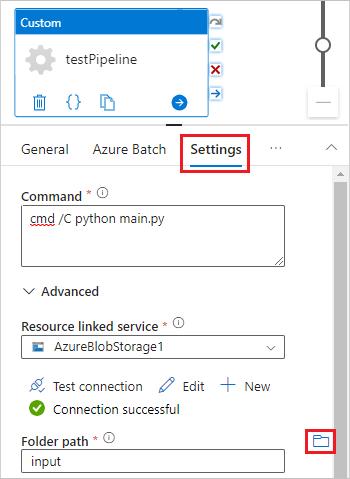
-
Команда: Нажмите ВВОД
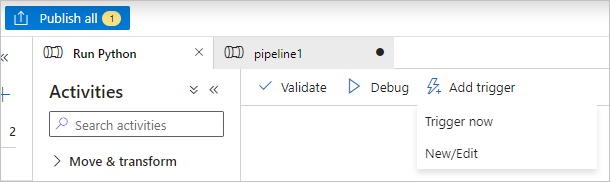
Выберите «Проверить» на панели инструментов конвейера, чтобы выполнить валидацию конвейера.
Выберите "Отладка", чтобы проверить конвейер и убедиться, что он работает правильно.
Выберите "Опубликовать все ", чтобы опубликовать конвейер.
Выберите " Добавить триггер", а затем нажмите кнопку "Триггер" , чтобы запустить конвейер или создать или изменить , чтобы запланировать его.

Просмотр файлов журналов с помощью Batch Explorer
Если при запуске конвейера возникают предупреждения или ошибки, можно использовать Batch Explorer для просмотра stdout.txt и stderr.txt выходных файлов для получения дополнительных сведений.
- В пакетном обозревателе выберите задания на левой боковой панели.
- Выберите задание adfv2-custom-activity-pool.
- Выберите задачу, у которой был код выхода из строя.
- Просмотрите stdout.txt и stderr.txt файлы для изучения и диагностики проблемы.
Очистка ресурсов
Учетные записи пакетов, задания и задачи бесплатны, но вычислительные узлы несут расходы, даже когда они не работают. Рекомендуется выделить пулы узлов только по мере необходимости и удалить пулы, когда вы закончите работу с ними. Удаление пулов приводит к удалению всех выходных данных задач на узлах, а также самих узлов.
Входные и выходные файлы остаются в учетной записи хранения, за что могут взиматься дополнительные сборы. Если файлы больше не нужны, можно удалить файлы или контейнеры. Если вам больше не нужна учетная запись пакетной службы или связанная учетная запись хранения, их можно удалить.
Следующие шаги
В этом руководстве вы узнали, как использовать скрипт Python с Batch Explorer, Обозреватель службы хранилища и Data Factory для запуска рабочей нагрузки в пакетной обработке. Дополнительные сведения о фабрике данных см. в статье "Что такое Фабрика данных Azure?"