Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
В мире больших данных в реляционных, нереляционных и других системах хранения часто хранятся необработанные и неорганизованные данные. Но необработанные данные сами по себе не содержат нужного контекста или значения, чтобы быть полезными для аналитиков, специалистов по анализу данных и руководителей компаний.
Для работы с большими данными нужна служба, которая поддерживает процессы организации и подготовки к использованию, для анализа этих огромных объемов необработанных данных и преобразования их в полезные данные. Azure Data Factory — это управляемая облачная служба, созданная для этих сложных проектов интеграции с гибридным извлечением и преобразованием (ETL), извлечением и преобразованием нагрузки (ELT) и проектами интеграции данных.
Функции Azure Data Factory
Сжатие данных: Во время операции копирования данных можно сжать данные и записать сжатые данные в целевой источник данных. Эта функция помогает оптимизировать использование пропускной способности при копировании данных.
Расширенная поддержка подключения для разных источников данных: Azure Data Factory обеспечивает широкую поддержку подключения к разным источникам данных. Это полезно, если требуется извлекать или записывать данные из разных источников данных.
Пользовательские триггеры событий: Azure Data Factory позволяет автоматизировать обработку данных с помощью пользовательских триггеров событий. Эта функция позволяет автоматически выполнять определенное действие при возникновении определенного события.
Предварительный просмотр и проверка данных: Во время деятельности по копированию данных предоставляются средства для предварительного просмотра и проверки данных. Эта функция помогает убедиться, что данные копируются правильно и записываются в целевой источник данных.
Настраиваемые потоки данных: Azure Data Factory позволяет создавать настраиваемые потоки данных. Эта функция позволяет добавлять пользовательские действия или шаги для обработки данных.
Встроенная безопасность: Azure Data Factory предлагает интегрированные функции безопасности, такие как интеграция Entra ID и управление доступом на основе ролей для управления доступом к потокам данных. Эта функция повышает безопасность обработки данных и защищает данные.
Сценарии использования
В качестве примера рассмотрим компанию, которая создает облачные игры и собирает петабайты информации в виде журналов этих игр. Компания хочет проанализировать эти журналы, чтобы получить сведения о предпочтениях клиентов, демографических параметрах и особенностях использования. Эти сведения помогут понять, как можно увеличить дополнительные и перекрестные продажи, разработать новые интересные функции, стимулировать развитие компании и улучшить качество обслуживания клиентов.
Чтобы проанализировать эти журналы, компании необходимо использовать справочные сведения, например информацию о клиентах, игре и маркетинговых действиях, которые хранятся в локальном хранилище данных. Компании нужно объединить эти данные из локального хранилища данных с дополнительными данными журналов, собранными в облачном хранилище данных.
Чтобы извлечь аналитические сведения, он надеется обработать присоединенные данные с помощью кластера Spark в облаке (Azure HDInsight) и опубликовать преобразованные данные в облачное хранилище данных, например Azure Synapse Analytics, чтобы легко создать отчет на его основе. Они хотят автоматизировать этот рабочий процесс, а также следить за ним и управлять им по ежедневному графику. Они также хотят выполнить его, когда файлы помещаются в контейнер хранилища BLOB-объектов.
Azure Data Factory — это платформа, которая решает такие сценарии данных. Это облачная служба ETL и интеграции данных, которая позволяет создавать управляемые данными рабочие процессы для оркестрации перемещения данных и преобразования данных в масштабе. С помощью Azure Data Factory можно создавать и планировать управляемые данными рабочие процессы (называемые конвейерами), которые могут получать данные из разных хранилищ данных. Вы можете создавать сложные процессы ETL, которые визуально преобразуют данные с потоками данных или с помощью вычислительных служб, таких как Azure HDInsight Hadoop, Azure Databricks и Azure SQL Database.
Кроме того, можно опубликовать преобразованные данные в хранилищах данных, таких как Azure Synapse Analytics для приложений бизнес-аналитики (BI). В конечном счете с помощью Azure Data Factory необработанные данные можно упорядочить в значимые хранилища данных и озера данных для лучшего бизнес-решения.
Как это работает?
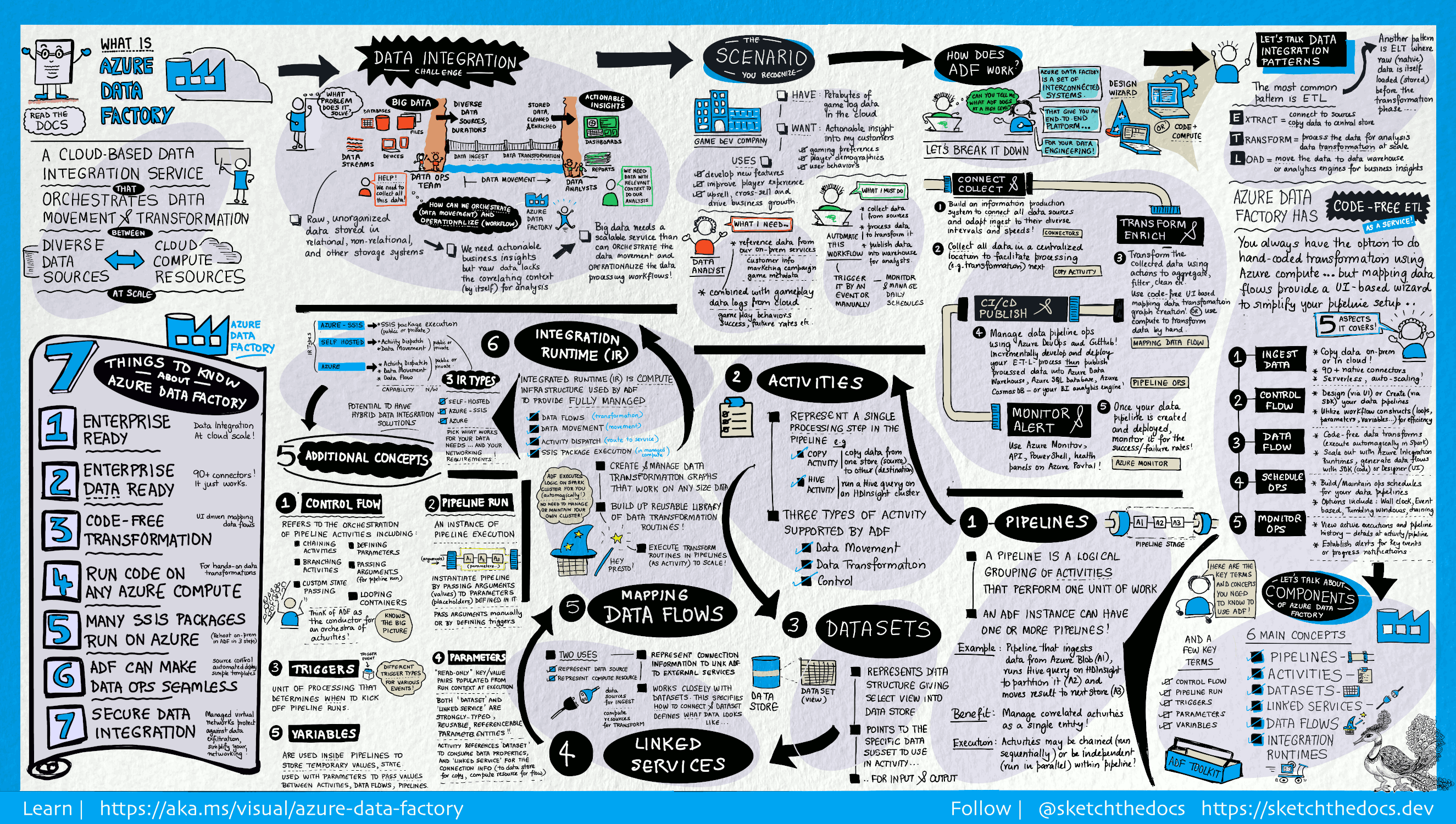
Фабрика данных содержит набор взаимосвязанных систем, предоставляющих комплексную платформу для специалистов по обработке данных.

Данное наглядное руководство обеспечивает подробный обзор всей архитектуры Фабрики данных:

Чтобы увидеть более подробную информацию, выберите предыдущее изображение, чтобы увеличить, или перейдите к изображению с высоким разрешением. Узнайте о разработке этого визуального руководства и эскизе проекта документации здесь.
{kind=link}
Подключение и сбор данных
Предприятия собирают данные различных типов в разнородных локальных и облачных источниках данных. Структурированные, неструктурированные или частично структурированные данные поступают с разными интервалами и с разной скоростью.
Первым этапом в создании системы производства информации является подключение ко всем необходимым источникам данных и службам обработки, таким как службы SaaS (программное обеспечение как услуга), базы данных, файловые ресурсы с общим доступом, FTP и веб-службы, Следующим шагом является перемещение данных в централизованное место для последующей обработки.
Не имея фабрики данных предприятия вынуждены создавать компоненты для перемещения пользовательских данных или писать пользовательские службы для интеграции этих источников данных и обработки. Такие системы дорого стоят, их сложно интегрировать и обслуживать. Кроме того, они часто не включают функции мониторинга и оповещений корпоративного уровня, а также элементы управления, которые может предложить полностью управляемая служба.
В фабрике данных вы можете использовать действие копирования в конвейере данных для перемещения данных из локальных и облачных исходных хранилищ данных в централизованное хранилище данных в облаке для последующего анализа. Например, можно собирать данные в Azure Data Lake Storage и преобразовывать их позже с помощью службы вычислений Azure Data Lake Analytics. Вы также можете собирать данные в хранилище BLOB-объектов Azure и преобразовать их позже с помощью кластера Azure HDInsight Hadoop.
Трансформируй и обогащай
После того как данные размещены в централизованном облачном хранилище, обрабатывайте или преобразовывайте их с помощью потоков сопоставления данных ADF. Потоки данных позволяют специалистам по обработке данных создавать и обслуживать схемы преобразования данных, которые выполняются в Spark, даже без знаний о кластерах Spark и программировании Spark.
Если вы предпочитаете преобразования кода вручную, ADF поддерживает внешние действия для выполнения преобразований в вычислительных службах, таких как HDInsight Hadoop, Spark, Data Lake Analytics и Machine Learning.
CI/CD и публикация
Data Factory обеспечивает полную поддержку CI/CD конвейеров данных с помощью Azure DevOps и GitHub. Это позволяет постепенно разрабатывать и предоставлять ETL-процессы перед публикацией готового продукта. После того как необработанные данные были преобразованы в готовый для использования бизнесом вид, загрузите их в Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB или любую аналитическую систему, которую бизнес-пользователи могут использовать через свои инструменты бизнес-аналитики.
Монитор
После создания и развертывания конвейера интеграции данных, который извлекает полезные данные из обработанных данных, вам понадобится отслеживать успешное выполнение и сбои запланированных операций и конвейеров. Azure Data Factory имеет встроенную поддержку мониторинга конвейера с помощью Azure Monitor, API, PowerShell, журналов Azure Monitor и панелей работоспособности на портале Azure.
Концепции высшего уровня
Подписка Azure может включать один или несколько экземпляров Azure Data Factory (фабрики данных). Azure Data Factory состоит из следующих ключевых компонентов:
- Pipelines
- Активности
- Наборы данных
- Связанные службы
- Потоки данных
- Среды выполнения интеграции
Они образуют платформу, на которой можно создавать управляемые данными рабочие процессы, предусматривающие перемещение и преобразование данных.
Pipeline
В фабрике данных можно использовать один или несколько конвейеров. Конвейер — это логическая группа действий, которые выполняют определенный блок задач. Действия в конвейере совместно выполняют задачу. Например, конвейер может содержать группу операций, которые поглощают данные из хранилища Azure Blob, а затем выполняют запрос Hive в кластере HDInsight для разбиения данных на разделы.
Преимущество конвейера в том, что он позволяет управлять группами действий, а не каждым отдельным действием. Действия в конвейере можно связывать друг с другом последовательно или выполнять параллельно и независимо друг от друга.
Сопоставление потоков данных
Создавайте и администрируйте графов логики преобразования данных, с помощью которых можно преобразовывать данные любого размера. Вы можете создать многоразовую библиотеку процедур преобразования данных и выполнять их с помощью конвейеров ADF в условиях горизонтального масштабирования. Фабрика данных будет выполнять логику в кластере Spark, который увеличивается и уменьшается по мере необходимости. Вам не придется ни управлять кластерами, ни обслуживать их.
Действие (Activity)
Действия представляют отдельные этапы обработки в конвейере. Например, действие копирования может использоваться для копирования данных из одного хранилища данных в другое. Аналогичным образом можно использовать действие Hive, которое выполняет запрос Hive в кластере Azure HDInsight, чтобы преобразовать или проанализировать данные. Фабрика данных поддерживает три типа действий: действия перемещения данных, действия преобразования данных и действия управления.
Наборы данных
Наборы данных представляют структуры данных в хранилищах, которые просто указывают на или ссылаются на данные, которые вы хотите использовать в своих действиях в качестве входных или выходных данных.
Связанные службы
Связанные службы напоминают строки подключения, определяющие сведения о подключении, необходимые для подключения фабрики данных к внешним ресурсам. Таким образом, набор данных представляет структуру данных, а связанная служба определяет подключение к источнику данных. Например, связанная с Azure Storage служба указывает connection string для подключения к учетной записи Azure Storage. Кроме того, набор данных Azure Blob указывает контейнер блобов и папку, содержащую данные.
Связанные службы используются в фабрике данных для двух целей:
Для представления хранилища данных, которое включает, но не ограничивается SQL Server базой данных, базой данных Oracle, общей папкой или учетной записью хранения BLOB Azure. Список поддерживаемых хранилищ данных можно найти в статье о действии копирования.
Для представления вычислительного ресурса, в котором можно выполнить действие. Например, действие HDInsightHive выполняется в кластере Hadoop в HDInsight. Список поддерживаемых действий преобразования и вычислительных сред см. в статье о преобразовании данных.
Среда выполнения интеграции
В "Фабрике данных" активность определяет действие, которое необходимо выполнить. Связанная служба обозначает целевое хранилище данных или службу вычислений. Среда выполнения интеграции служит мостом между действием и связанными службами. На нее ссылаются связанные с ней службы или действия, а кроме того она предоставляет вычислительную среду, в которой действие выполняется или из которой оно диспетчеризируется. Такая схема позволяет выполнять действия в регионе, который максимально близко расположен к целевому хранилищу данных или службе вычислений, обеспечивает высокую производительность и соблюдение требований по безопасности и соответствию.
Триггеры
Триггеры представляют собой элемент процесса, который определяет момент, когда необходимо запустить выполнение конвейера. Существует несколько типов триггеров для разных событий.
Запуски конвейера
Запуск конвейера — это экземпляр выполнения конвейера. Запуски конвейера обычно создаются путем передачи аргументов в параметры, определенные в конвейерах. Аргументы можно передавать вручную или в определении триггера.
Параметры
Параметры представляют собой пары "ключ — значение" в конфигурации, которая доступна только для чтения. Параметры определяются в конвейере, Аргументы для определённых параметров передаются во время выполнения из контекста запуска, который был создан триггером, или из конвейера, выполняемого вручную. Действия в конвейере используют значения параметров.
Набор данных — это строго типизированный параметр и сущность, доступная для ссылок и повторного использования. Действие может ссылаться на наборы данных и может использовать параметры, определенные в определении набора данных.
Связанная служба также является строго типизированным параметром, который содержит сведения о подключении к хранилищу данных или среде вычислений. Это также повторно используемый/ссылочный объект.
Управление потоком
Поток управления — это оркестрация действий в конвейере, которая включает связывание действий в последовательности, ветвление, определение параметров на уровне конвейера и передачу аргументов во время вызова конвейера по запросу или из триггера. Он также включает в себя контейнеры с возможностью передачи и перебора, т. е. итераторы 'For-each'.
Переменные
Переменные можно использовать внутри конвейеров для хранения временных значений, а также в сочетании с параметрами для передачи значений между конвейерами, потоками данных и другими действиями.
Связанный контент
Вот несколько важных документов, которые следует изучить на следующем этапе:
- Datasets and linked services in Azure Data Factory (Наборы данных и связанные службы в фабрике данных Azure)
- Конвейеры и действия
- Среда выполнения интеграции
- Сопоставление потоков данных
- Пользовательский интерфейс Фабрики данных на портале Azure
- инструмент Copy Data на портале Azure
- PowerShell
- .NET
- Python
- REST
- шаблон Azure Resource Manager