Целевые зоны данных
Целевые зоны данных подключены к целевой зоне управления данными по пирингу виртуальной сети. Каждая целевая зона данных считается целевой зоной, связанной с архитектурой целевой зоны Azure.
Внимание
Перед подготовкой целевой зоны данных убедитесь, что операционная модель DevOps и CI/CD развернута, а целевая зона управления данными развернута.
Каждая целевая зона данных содержит несколько уровней, которые обеспечивают гибкость интеграции данных службы и продуктов данных, содержащихся в ней. Вы можете развернуть новую целевую зону данных со стандартным набором служб, которые позволяют целевой зоне данных начать прием и анализ данных.
Ваша подписка Azure, связанная с целевой зоной данных, имеет следующую структуру:
| Уровень | Обязательное поле | Группы ресурсов |
|---|---|---|
| Основные службы | Да |
|
| Приложение данных | Необязательно |
|
| Визуализация | Необязательно |
Примечание.
Приложение данных создает один или несколько продуктов данных.
Архитектура целевой зоны данных
Архитектура целевой зоны данных иллюстрирует слои, их группы ресурсов и службы, содержащие каждую группу ресурсов. Архитектура также содержит обзор всех групп и ролей, связанных с целевой зоной данных, а также степень их доступа к плоскостям управления и данных.

Совет
Перед развертыванием целевой зоны данных необходимо учитывать количество начальных целевых зон данных, которые необходимо развернуть.
Используйте эту архитектуру в качестве отправной точки. Скачайте файл Visio и измените его в соответствии с конкретными бизнес-требованиями и техническими требованиями при планировании реализации целевой зоны данных.
Слой основных служб
Основной уровень служб включает все службы, необходимые для включения целевой зоны данных в контексте облачной аналитики. В следующей таблице перечислены группы ресурсов, которые предоставляют стандартный набор доступных служб в каждой развернутой целевой зоне данных.
| Группа ресурсов | Обязательное поле | Описание: |
|---|---|---|
network-rg |
Да | Сеть |
databricks-monitoring-rg |
Необязательно | Мониторинг рабочих областей Azure Databricks |
hive-rg |
Необязательно | Хранилище метаданных Hive для Azure Databricks |
storage-rg |
Да | Службы озера данных |
external-data-rg |
Да | Хранилище принимаемых данных при загрузке |
runtimes-rg |
Да | Общие среды выполнения интеграции |
mgmt-rg |
Да | Агенты CI/CD |
metadata-ingestion-rg |
Необязательно | Не зависят от приема данных |
databricks-monitoring-rg |
Необязательно | Рабочая область Log Analytics для рабочих областей Databricks в целевой зоне |
shared-synapse-rg |
Необязательно | Общий доступ к Azure Synapse |
shared-databricks-rg |
Необязательно | Общая рабочая область Azure Databricks |
Сеть
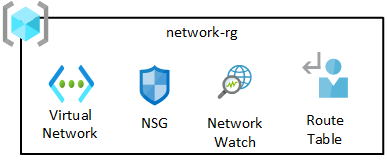
Группа сетевых ресурсов содержит основные компоненты, включая azure Наблюдатель за сетями, группы безопасности сети (NSG) и виртуальную сеть. Все эти службы развертываются в одной группе ресурсов.
Виртуальная сеть целевой зоны данных автоматически выполняет пиринг с виртуальной сетью целевой зоны управления данными и виртуальной сетью подписки на подключение.
Мониторинг рабочих областей Azure Databricks
Эта группа ресурсов является необязательной и развертывается только с помощью Azure Databricks.
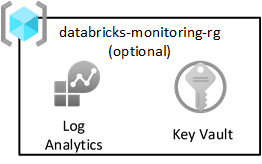
Шаблон целевой зоны Azure рекомендует отправлять все журналы в центральную рабочую область Log Analytics. Однако каждая целевая зона данных также включает группу ресурсов мониторинга для записи журналов Spark из Databricks. Каждая группа ресурсов содержит общую рабочую область Log Analytics и Azure Key Vault для хранения ключей Log Analytics.
Внимание
Используйте только рабочую область Log Analytics в группе ресурсов мониторинга Databricks для записи журналов Azure Databricks Spark.
Дополнительные сведения см. в статье Мониторинг в Azure Databricks.
Хранилище метаданных Hive для Azure Databricks
Эта группа ресурсов является необязательной и должна быть развернута только с помощью Azure Databricks.
Хранилище метаданных Hive для Azure Databricks подготавливает базу данных База данных Azure для MySQL и хранилище ключей. Все рабочие области Azure Databricks в целевой зоне данных используют это хранилище метаданных в качестве внешнего хранилища метаданных Apache Hive.
Дополнительные сведения см. в разделе "Внешнее хранилище метаданных Apache Hive".
Службы Data Lake
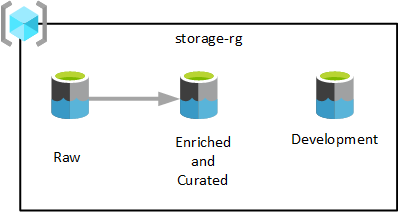
Как показано на предыдущей схеме, три учетные записи Azure Data Lake Storage 2-го поколения подготавливаются в одной группе ресурсов служб озера данных. Данные, преобразованные на разных этапах, сохраняются в одном из озер данных целевой зоны данных. Данные доступны для использования командами аналитики, обработки и анализа данных и визуализации.
Слои озера данных используют различные терминологии в зависимости от технологии и поставщика. В этой таблице приведены рекомендации по применению терминов для облачной аналитики:
| Аналитика в масштабах облака | Delta Lake | Другие термины | Description |
|---|---|---|---|
| Необработанные | Бронзовая | Посадка и соответствие | Таблицы приема данных |
| Обогащенные | Серебряная | Зона стандартизации | Уточненные таблицы. Хранимые полные сущности, наборы записей, готовые к использованию, из систем записей. |
| Отобрано | Золотая | Зона продукта | Функции или агрегированные таблицы. Основная зона для приложений, команд и пользователей для использования продуктов данных. |
| Разработка | -- | Зона разработки | Расположение инженеров и специалистов по обработке и анализу данных, включая песочницу аналитики и зону разработки продуктов. |
Примечание.
На предыдущей схеме каждая целевая зона данных имеет три озера данных. Однако в зависимости от ваших требований может потребоваться объединить необработанные, обогащенные и курированные слои в одну учетную запись хранения, а также сохранить другую учетную запись хранения под названием "разработка" для потребителей данных, которые будут применять другие полезные продукты данных.
Дополнительные сведения см. в разделе:
- Обзор Azure Data Lake Storage для облачной аналитики
- Стандартизация данных
- Подготовка учетных записей Azure Data Lake Storage 2-го поколения для каждой целевой зоны данных
- Основные рекомендации для Azure Data Lake Storage
- Управление доступом и конфигурации озера данных в Azure Data Lake Storage
Хранилище принимаемых данных при загрузке
Сторонние издатели данных должны помещать данные на платформу, чтобы команды приложений данных могли извлечь их в свои озера данных. Как показано на следующей схеме, группа ресурсов отправки позволяет подготавливать хранилища BLOB-объектов для сторонних разработчиков.
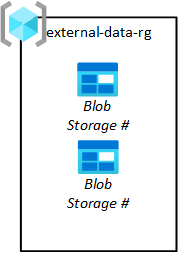
Команды приложений данных запрашивают эти большие двоичные объекты хранилища. Затем их запросы утверждены группой операций целевой зоны данных. Данные должны быть удалены из исходного BLOB-объекта хранилища после извлечения из большого двоичного объекта хранилища в необработанный.
Внимание
Так как служба хранилища Azure большие двоичные объекты подготавливаются по мере необходимости, сначала следует развернуть пустую группу ресурсов служб хранилища в каждой целевой зоне данных.
Общие среды выполнения интеграции
Разверните виртуальную машину с локальными средами выполнения интеграции в целевой зоне данных. Разместите его в группе ресурсов общей интеграции. Это развертывание позволяет быстро подключить продукты данных к целевой зоне данных.
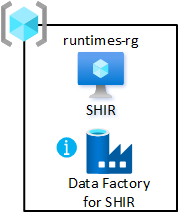
Чтобы включить группу ресурсов, выполните следующие действия.
- Создайте хотя бы одну Фабрика данных Azure в общей группе ресурсов интеграции целевой зоны данных. Используйте его только для связывания общей локальной среды выполнения интеграции, а не для конвейеров данных.
- Создайте и настройте локальную среду выполнения интеграции на виртуальной машине.
- Свяжите локальную среду выполнения интеграции с фабриками данных Azure в целевой зоне данных.
- Настройте служба автоматизации Azure для периодического обновления локальной среды выполнения интеграции.
Примечание.
Приведенное выше развертывание обеспечивает развертывание одной виртуальной машины с локальными средами выполнения интеграции. Можно связать локальную среду выполнения интеграции с несколькими локальными компьютерами или виртуальными машинами в Azure. Такие компьютеры называются узлами. Для локальной среды выполнения интеграции можно использовать до четырех узлов. Ниже перечислены преимущества использования для логического шлюза нескольких узлов на локальных компьютерах с установленным шлюзом.
- Более высокий уровень доступности локальной среды выполнения интеграции в силу устранения единой точки отказа в решении больших данных или интеграции облачных данных. Такой уровень доступности позволяет обеспечить непрерывность работы при использовании не более четырех узлов.
- Повышение производительности и пропускной способности при перемещении данных между локальными и облачными хранилищами данных. Узнайте больше о сравнении производительности.
Можно связать несколько узлов, установив программное обеспечение локальной среды выполнения интеграции из Центра загрузки. Затем следует зарегистрировать его с помощью одного из ключей проверки подлинности, полученных в результате выполнения командлета New-AzDataFactoryV2IntegrationRuntimeKey, как описано в этом руководстве.
Сведения о футере подробно описаны в Azure Datafactory High availability и масштабируемости.
Внимание
Развертывание общих сред выполнения интеграции как можно ближе к источнику данных. Их развертывание не ограничивает развертывание сред выполнения интеграции в целевой зоне данных или в сторонние облака. Вместо этого он предоставляет резервный вариант для собственных облачных источников данных в регионе.
Агенты CI/CD
Агенты CI/CD помогают развертывать приложения данных и изменять целевую зону данных.
Дополнительные сведения см. в статье об агентах Azure Pipeline.
Не зависят от приема данных
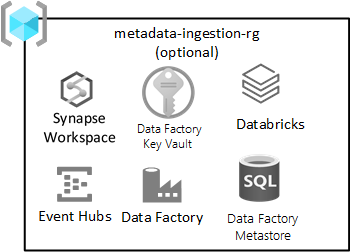
Эта группа ресурсов является необязательной и не запрещает развертывание целевой зоны.
Эта группа ресурсов применяется, если у вас есть (или разрабатывается) подсистема приема данных, предназначенная для автоматического приема данных на основе регистрации метаданных (включая строка подключения, путь к копированию данных из и в, а также расписание приема данных. Группа ресурсов приема и обработки имеет ключевые службы для такой платформы.
Разверните экземпляр База данных SQL Azure для хранения метаданных, используемых Фабрика данных Azure. Подготовьте Azure Key Vault для хранения секретов, связанных со службами автоматического приема данных. Эти секреты могут включать:
- Учетные данные хранилища метаданных Фабрики данных Azure
- Учетные данные субъекта-службы для процесса автоматического приема
Дополнительные сведения см. в статье О том, как автоматизированные платформы приема поддерживают облачную аналитику в Azure.
Службы, включенные в эту группу ресурсов, включают:
| Service | Обязательное поле | Рекомендации |
|---|---|---|
| Azure Data Factory | Да | Фабрика данных Azure — это обработчик оркестрации для приема данных, не зависящих от данных. |
| Базой данных SQL Azure | Да | База данных SQL Azure — это хранилище метаданных для Фабрика данных Azure. |
| Центры событий или центр Интернета вещей | Необязательно | Центры событий или Центр Интернета вещей могут предоставлять потоковую передачу в центры событий в режиме реального времени, а также пакетную и потоковую обработку с помощью рабочей области проектирования Databricks. |
| Azure Databricks | Необязательно | Вы можете развернуть Azure Databricks или Azure Synapse Spark для использования с подсистемой приема данных. |
| Azure Synapse | Необязательно | Вы можете развернуть Azure Databricks или Azure Synapse Spark для использования с механизмом приема данных. |
Общие данные Databricks
Эта группа ресурсов является необязательной и развертывается только с помощью Azure Databricks. Каждый пользователь в целевой зоне данных может использовать рабочую область Databricks.
Azure Databricks является ключевым потребителем службы Azure Data Lake Storage. Атомарные операции с файлами оптимизированы для обработчиков аналитики Spark. Эта оптимизация ускоряет выполнение заданий Spark, связанных с проблемами службы Azure Databricks.
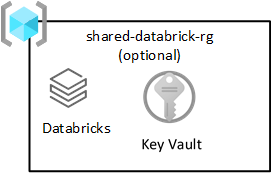
Внимание
Рабочая область Azure Databricks, называемая рабочей областью Azure Databricks (аналитика), подготовлена для всех специалистов по обработке и анализу данных и DataOps, как показано в группе ресурсов общих продуктов.
Эту рабочую область можно настроить для подключения к Azure Data Lake с помощью сквозного руководства Microsoft Entra или управления доступом к таблицам. В зависимости от варианта использования можно настроить условный доступ в качестве другой меры безопасности.
Чтобы интегрировать Azure Databricks, следуйте рекомендациям по анализу облачных технологий.
- Безопасный доступ к Azure Data Lake 2-го поколения из Azure Databricks
- Рекомендации по Azure Databricks
Шаблон целевой зоны Azure рекомендует отправлять все журналы в центральную рабочую область Log Analytics. Однако каждая целевая зона данных также содержит группу ресурсов мониторинга для записи журналов Spark из Databricks.
Общий доступ к Azure Synapse Analytics
Эта группа ресурсов является необязательной.
Во время начальной настройки целевой зоны данных развертывается одна рабочая область Azure Synapse Analytics для использования всеми аналитиками данных и учеными в группе ресурсов общих продуктов.
Вы можете настроить дополнительные рабочие области synapse для продуктов данных, если требуется управление затратами и перезагрузка. Команды приложений данных могут использовать выделенные рабочие области Azure Synapse Analytics для создания выделенных пулов База данных SQL Azure в качестве хранилища данных для чтения, используемого уровнем визуализации.
Внимание
Запретить использование общей рабочей области Azure Synapse для создания продукта данных, заблокируя рабочую область, чтобы разрешить только запросы SQL по запросу. Это только для эксплойтивных целей.
Приложение данных
Каждая целевая зона данных может иметь несколько продуктов данных. Эти продукты данных можно создать, используя данные из источника. Вы также можете создавать продукты данных из других продуктов данных в той же целевой зоне данных или из других целевых зон данных. Создание продукта данных продуктов данных подлежит утверждению в отношении данных.
Группа ресурсов продукта данных
Продукт группы ресурсов данных содержит все службы, необходимые для создания этого продукта данных. Например, для MySQL требуется база данных Azure, которая используется средством визуализации. Данные должны быть приема и преобразования перед тем, как они приземлились в базу данных MySQL. В этом случае можно развернуть База данных Azure для MySQL и Фабрика данных Azure в группе ресурсов продукта данных.
Совет
Если вы решили не реализовать подсистему агностик данных для приема одного раза из операционных источников или если сложные подключения не упрощаются в подсистеме агностик данных, создайте приложение для выравнивания источника данных. Дополнительные сведения см. в статьях "Приложения данных" (с выравниванием по источнику)
Дополнительные сведения о том, как подключить продукты данных, см. в статье "Облачный масштабируемый анализ данных" в Azure.
Визуализация
Для каждой целевой зоны данных создается пустая группа ресурсов визуализации. Заполните эту группу ресурсов службами, которые необходимо реализовать решение визуализации. Использование существующей виртуальной сети позволяет решению подключаться к продуктам данных.
Эта группа ресурсов может размещать виртуальные машины для сторонних служб визуализации.
Совет
Из-за затрат на лицензирование может оказаться более экономичным развертывание сторонних продуктов визуализации в целевой зоне управления данными, а также для подключения между целевыми зонами данных для извлечения данных.
Следующие шаги
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по