Как моделировать и секционировать данные в Azure Cosmos DB на примере реальной задачи
ОБЛАСТЬ ПРИМЕНЕНИЯ: ![]() NoSQL
NoSQL
В этой статье применяется ряд ключевых понятий Azure Cosmos DB, таких как моделирование данных, секционирование и подготовленная пропускная способность, чтобы продемонстрировать решение реальной практической задачи по подготовке данных.
Если вы регулярно работаете с реляционными базами данных, у вас уже есть представление о моделях данных и определенный набор приемов по их созданию. Azure Cosmos DB имеет ряд уникальных преимуществ и специфичных ограничений. Поэтому многие традиционные рекомендации в этой среде плохо применимы и приводят к созданию неоптимальных решений. В этой статье наглядно демонстрируется полный процесс моделирования данных в Azure Cosmos DB на примере реального использования — от моделирования элементов до размещения сущностей и секционирования контейнеров.
Скачайте или просмотрите созданный сообществом исходный код, иллюстрирующий основные понятия из этой статьи.
Внимание
Участник сообщества внес свой вклад в этот пример кода, и команда Azure Cosmos DB не поддерживает его обслуживание.
Сценарий
В этом упражнении мы рассмотрим домен платформы блогов, где пользователи могут создавать записи. Также они могут добавлять к этим записям отметки "Нравится" и текстовые комментарии.
Совет
Несколько слов, которые здесь выделены курсивом, определяют характер сущностей и концепций, с которыми будет работать наша модель.
Давайте добавим к спецификации несколько конкретных требований:
- на титульной странице должен отображаться веб-канал недавно созданных записей;
- нужна возможность получить все записи определенного пользователя, все комментарии и (или) отметки "Нравится" по определенной записи;
- вместе с записью должны возвращаться имя пользователя автора этой записи, а также количество комментариев и отметок "Нравится";
- вместе с комментариями и отметками "Нравится" должны возвращаться имена пользователей, которые их создали;
- при отображении списков записей должна демонстрироваться только усеченная версия содержимого.
Описание основных схем доступа
Сначала определим структуру для начальной спецификации, обозначив шаблоны доступа для нашего решения. При разработке модели данных для Azure Cosmos DB важно понимать, какие запросы нашей модели должны служить, чтобы убедиться, что модель эффективно обслуживает эти запросы.
Чтобы упростить общий процесс, мы классифицируем эти различные запросы как команды или запросы, заимствование некоторых словарей из CQRS. В CQRS команды — это запросы на запись (то есть намерения обновить систему), а запросы — запросы только для чтения.
Ниже приведен список запросов, предоставляемых нашей платформой:
- [C1] — создание или изменение пользователя;
- [Q1] — получение сведений о пользователе;
- [C2] — создание или изменение записи;
- [Q2] — получение записи;
- [Q3] — список записей пользователя в краткой форме;
- [C3] — создание комментария;
- [Q4] — список комментариев к записи;
- [C4] — добавление к записи отметки "Нравится";
- [Q5] — список отметок "Нравится" для записи;
- [Q6] — список x самых свежих записей в краткой форме (веб-канал).
На этом этапе мы не думали о том, что содержит каждая сущность (пользователь, запись и т. д.). Этот шаг обычно является одним из первых, которые необходимо решить при проектировании для реляционного хранилища. Начнем с этого шага, так как мы должны выяснить, как эти сущности переводятся с точки зрения таблиц, столбцов, внешних ключей и т. д. Это гораздо меньше проблем с базой данных документов, которая не применяет ни одну схему при записи.
Основная причина, по которой важно определить наши шаблоны доступа с самого начала, заключается в том, что этот список запросов будет нашим набором тестов. Каждый раз, когда мы итерируем модель данных, мы просматриваем каждый из запросов и проверяем его производительность и масштабируемость. Мы вычисляем единицы запросов, потребляемые в каждой модели, и оптимизируем их. Все эти модели используют политику индексирования по умолчанию. Ее можно переопределить путем индексирования конкретных свойств, что может дополнительно уменьшить потребление единиц запросов и задержку.
Версия 1: первая версия
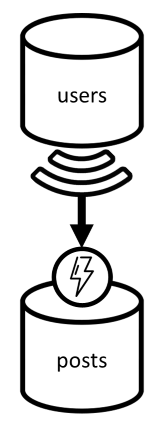
Первыми объектами у нас будут два контейнера: users и posts.
Контейнер users
В этом контейнере хранятся только элементы с данными о пользователях:
{
"id": "<user-id>",
"username": "<username>"
}
Мы секционируем этот контейнер, что означает, что каждая логическая секция в этом контейнере idсодержит только один элемент.
Контейнер posts
В этом контейнере размещаются такие сущности, как записи, комментарии и нравится:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Мы секционируем этот контейнер, что означает, что каждая логическая секция в этом контейнере postIdсодержит одну запись, все комментарии для этой записи и все нравится для этой записи.
Мы представили type свойство в элементах, хранящихся в этом контейнере, чтобы различать три типа сущностей, на которых размещается этот контейнер.
Кроме того, мы решили использовать ссылки на связанные данные вместо внедрения данных (сравнение этих концепций вы найдете в этом разделе), руководствуясь следующими факторами:
- верхний предел для количества созданных пользователем записей е предусмотрен;
- записи могут иметь произвольную длину;
- верхний предел для количества комментариев и (или) отметок "Нравится" для одной записи не предусмотрен;
- требуется возможность добавить к записи комментарий или отметку "Нравится", не обновляя саму запись.
Насколько хорошо работает эта модель?
Пришло время оценить производительность и масштабируемость нашей первой версии. Для каждой из ранее определенных операций мы оценим задержку и количество потребляемых единиц запроса. Это измерение выполняется по фиктивному набору данных 100 000 пользователей, содержащему от 5 до 50 записей от каждого пользователя, а также не более 25 комментариев и 100 отметок "Нравится" для каждой записи.
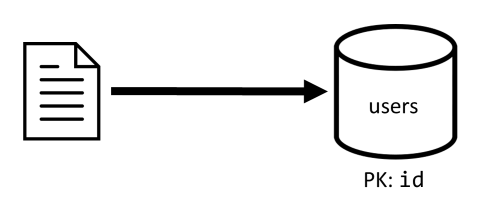
[C1] — создание или изменение пользователя
Этот запрос реализуется довольно просто: достаточно создать или обновить элемент в контейнере users. Запросы хорошо распределялись по всем секциям благодаря ключу id секции.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
7 госпожа |
5.71 ЕЗ |
✅ |
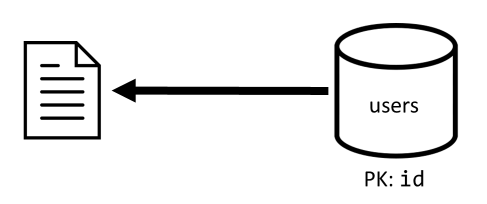
[Q1] — получение сведений о пользователе
Получение сведений о пользователе выполняется путем чтения соответствующего элемента из контейнера users.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
2 госпожа |
1 ЕЗ |
✅ |
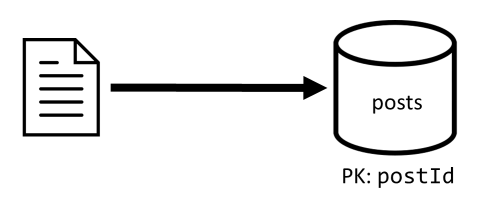
[C2] — создание или изменение записи
Аналогично операции [C1], выполняется путем записи в контейнер posts.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
9 госпожа |
8.76 ЕЗ |
✅ |
[Q2] — получение записи
Сначала нужно извлечь соответствующий документ из контейнера posts. Но это недостаточно, как по нашей спецификации, мы также должны агрегировать имя пользователя автора публикации, количество комментариев и количество нравится для публикации. Для агрегирования, перечисленных в списке, требуется еще 3 запроса SQL.
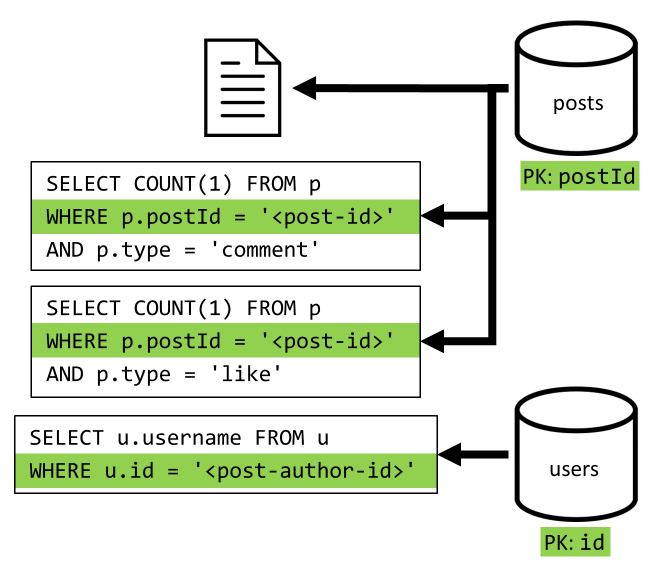
Каждый из дополнительных запросов фильтрует ключ секции соответствующего контейнера, что именно то, что мы хотим повысить производительность и масштабируемость. Но в итоге мы выполняем четыре операции для возврата одной записи. Это поведение мы улучшим в следующей итерации.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
9 госпожа |
19.54 ЕЗ |
⚠ |
[Q3] — список записей пользователя в краткой форме
Сначала нам нужно извлечь требуемые записи с помощью запроса SQL, который возвращает записи по определенному пользователю. Но мы также должны выдавать дополнительные запросы, чтобы агрегировать имя пользователя автора и количество комментариев и нравится.
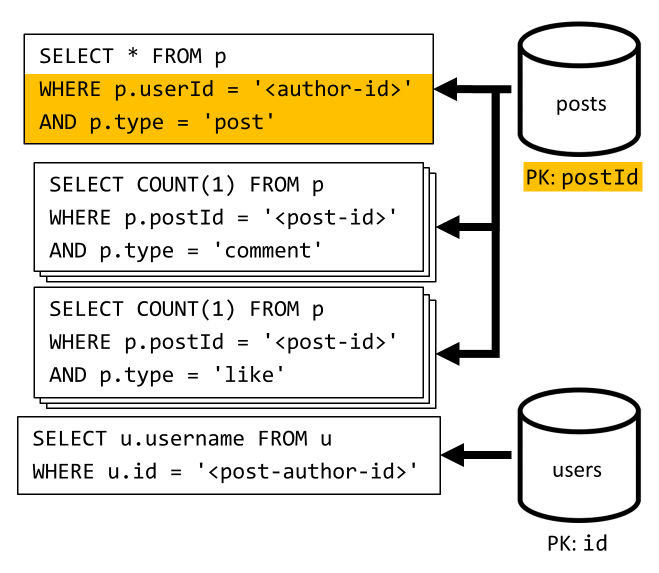
Представленная реализация имеет несколько недостатков:
- сбор данных о количестве комментариев и отметок "Нравится" выполняется отдельно для каждой записи, которая получена в результатах первого запроса;
- Основной запрос не фильтрует ключ секции
postsконтейнера, что приводит к раздуву и сканированию секций по контейнеру.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
130 госпожа |
619.41 ЕЗ |
⚠ |
[C3] — создание комментария
Комментарий создается путем сохранения соответствующего элемента в контейнер posts.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
7 госпожа |
8.57 ЕЗ |
✅ |
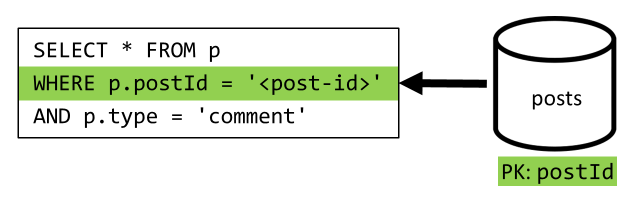
[Q4] — список комментариев к записи
Мы начинаем обработку с запроса, который позволяет извлечь все комментарии к нужной записи. Затем снова нужно получить имена пользователей отдельно для каждого комментария.
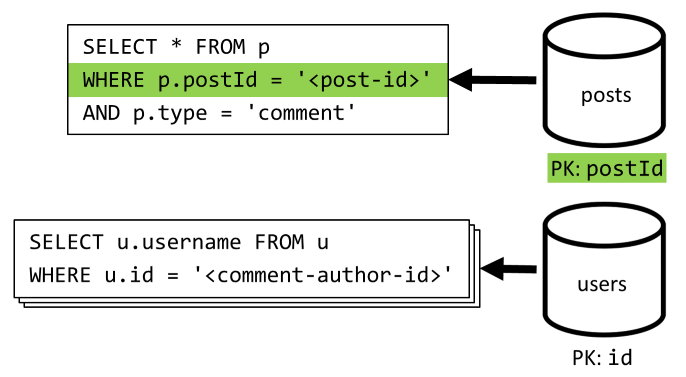
Основной запрос позволяет отфильтровать данные контейнера по ключу секции, но раздельный сбор имен пользователей снижает общую производительность. Мы улучшили это позже.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
23 госпожа |
27.72 ЕЗ |
⚠ |
[C4] — добавление к записи отметки "Нравится"
Так же, как и при выполнении операции [C3], мы создаем нужные элемент в контейнере posts.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
6 госпожа |
7.05 ЕЗ |
✅ |
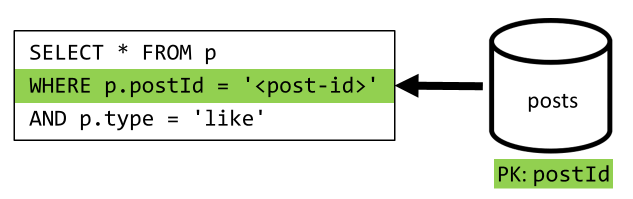
[Q5] — список отметок "Нравится" для записи
Так же, как и при выполнении операции [Q4], мы запрашиваем отметки "Нравится" для нужной записи, а затем получаем для них имена пользователей.
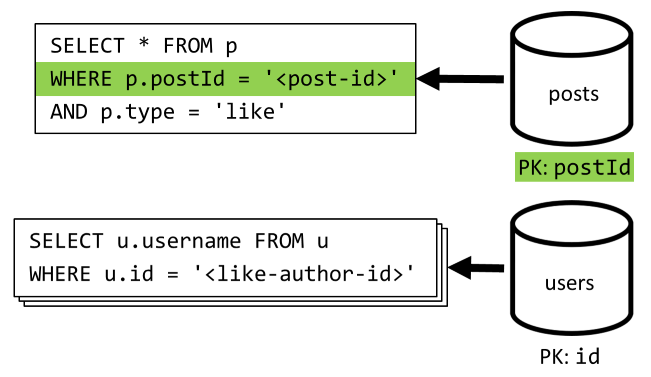
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
59 госпожа |
58.92 ЕЗ |
⚠ |
[Q6] — список "x" самых свежих записей в краткой форме (веб-канал)
Мы запрашиваем последние записи из контейнера posts, отсортировав его по убыванию даты создания, а затем собираем имена пользователей и количество комментариев и отметок "Нравится" для каждой из записей.
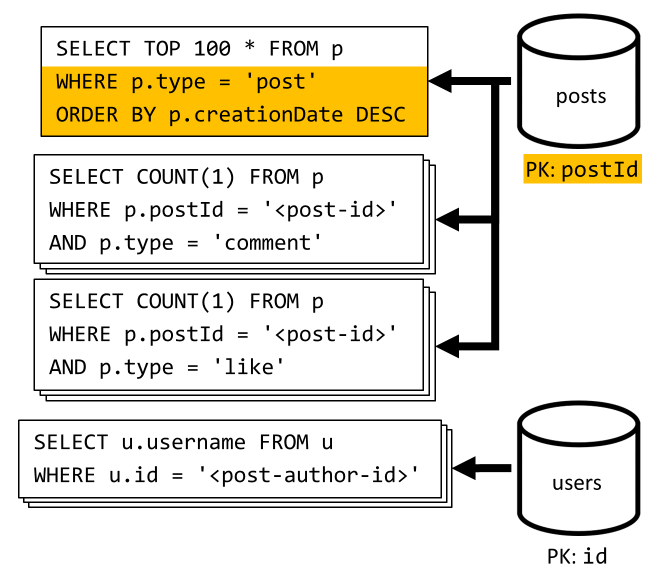
Снова наш первоначальный запрос не фильтрует ключ секции posts контейнера, который активирует дорогостоящий раздумка. Это еще хуже, так как мы нацелены на более крупный результирующий набор и сортируем результаты с ORDER BY предложением, что делает его более дорогим с точки зрения единиц запроса.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
306 госпожа |
2063.54 ЕЗ |
⚠ |
Факторы, влияющие на производительность версии 1
Изучая проблемы с производительностью, которые мы обнаружили в предыдущем разделе, можно выделить два основных класса проблем:
- некоторые операции требуют выполнить несколько запросов для сбора всех нужных данных;
- некоторые запросы не используют ключ секции для фильтрации контейнеров, в результате чего создаются размноженные запросы с плохой масштабируемостью.
Давайте займемся устранением каждой из этих проблем, начиная с первой из них.
Версия 2: введение денормализации для оптимизации запросов на чтение
Причина, по которой мы должны выдавать больше запросов в некоторых случаях, заключается в том, что результаты первоначального запроса не содержат все данные, которые нам нужно вернуть. Денормализация данных решает эту проблему в нашем наборе данных при работе с нереляционным хранилищем данных, таким как Azure Cosmos DB.
В нашем примере мы изменим элементы записей, чтобы они содержали имя пользователя, число комментариев и отметок "Нравится":
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Мы также изменим элементы комментариев и отметок "Нравится",чтобы они содержали имя пользователя, создавшего их:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Денормализация счетчиков комментариев и отметок "Нравится"
Теперь нам нужно, чтобы при каждом добавлении комментария или отметки "Нравится" увеличивались значения commentCount или likeCount для соответствующей записи. Как postId секционирует наш posts контейнер, новый элемент (комментарий или подобное) и соответствующая запись сидят в той же логической секции. Это позволяет нам использовать хранимую процедуру для выполнения нужной операции.
При создании комментария ([C3]) вместо простого добавления нового элемента в контейнер мы вызываем следующую хранимую процедуру в posts этом контейнере:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Эта хранимая процедура принимает в качестве параметров идентификатор записи и текст нового комментария. Она предназначена для выполнения следующих действий:
- извлечение записи;
- увеличение значения
commentCount; - сохранение новых данных записи;
- добавление нового комментария.
Так как хранимые процедуры выполняются как атомарные транзакции, значение commentCount и фактическое количество комментариев всегда остается в синхронизации.
Разумеется, мы применим аналогичную хранимую процедуру и для добавления новых отметок "Нравится", чтобы увеличивать значение likeCount.
Денормализация имен пользователей
Для имен пользователей нужен другой подход, так как они располагаются не только в разных секциях, но и в другом контейнере. Для денормализации данных в нескольких секциях и контейнерах можно использовать веб-канал изменений исходного контейнера.
В нашем примере мы настроим канал изменений контейнера users таким образом, чтобы он реагировал на каждое изменение имен пользователей. Все эти изменения мы будем распространять с помощью другой хранимой процедуры из контейнера posts:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Эта хранимая процедура принимает в качестве параметров идентификатор пользователя и его новое имя пользователя. Она предназначена для выполнения следующих задач:
- Извлечение всех элементов, соответствующих условию
userId(это могут быть записи, комментарии и отметки "Нравится"). - для каждого из этих элементов
- заменяется параметр
userUsername; - сохраняются новые данные элемента.
- заменяется параметр
Внимание
Эта операция сопряжена со значительными затратами, так как хранимую процедуру придется выполнить в каждом разделе контейнера posts. Но мы полагаем, что большинство пользователей выбирают подходящее имя пользователя сразу при регистрации и никогда не изменяют его, а значит, такое обновление будет выполняться очень редко.
Какие преимущества для производительности обеспечила версия 2?
Давайте поговорим о некоторых достижениях производительности версии 2.
[Q2] — получение записи
Теперь, когда мы настроили денормализацию, для обработки этого запроса достаточно получить один элемент.
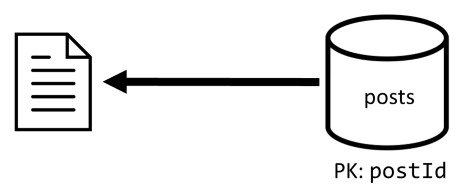
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
2 госпожа |
1 ЕЗ |
✅ |
[Q4] — список комментариев к записи
Здесь мы также избавились от затрат на дополнительные запросы имен пользователей и оставили лишь один запрос с фильтрацией по ключу секции.
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
4 госпожа |
7.72 ЕЗ |
✅ |
[Q5] — список отметок "Нравится" для записи
Аналогичный результат достигнут и для перечисления отметок "Нравится".
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
4 госпожа |
8.92 ЕЗ |
✅ |
Версия 3: обеспечение масштабируемости для всех операций
Существует еще два запроса, которые мы не полностью оптимизированы при просмотре наших общих улучшений производительности. Эти запросы : [Q3] и [Q6]. Они являются запросами, включающими запросы, которые не фильтруют ключ секции целевых контейнеров.
[Q3] — список записей пользователя в краткой форме
Этот запрос уже имеет преимущества от улучшений, представленных в версии 2, что экономит больше запросов.

Но сохранившийся запрос по-прежнему не выполняет фильтрацию контейнера posts по ключу раздела.
Способ думать об этой ситуации прост:
- Этот запрос должен отфильтровать данные из-за
userIdтого, что мы хотим получить все записи для конкретного пользователя. - Он не работает хорошо, так как он выполняется в
postsконтейнере, который не имеетuserIdсекционирования. - Заявив, что очевидно, мы бы решить нашу проблему производительности, выполнив этот запрос в отношении контейнера, секционированного с
userId. - И он у нас есть: это контейнер
users!
Поэтому мы добавим второй уровень денормализации, дублируя все записи в контейнере users. Таким образом, мы фактически получаем копию наших записей, секционированную только по другому измерению, что делает их более эффективным для получения их userId.
Теперь users контейнер содержит два типа элементов:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
В этом примере:
- Мы ввели
typeполе в элементе пользователя, чтобы отличить пользователей от записей, - Мы также добавили
userIdполе в элемент пользователя, который является избыточным сidполем, но требуется, так какusersконтейнер теперь секционирован (userIdи неidтак, как ранее)
Чтобы выполнить эту денормализацию, мы снова применяем канал изменений. Теперь мы настроим реагирование по каналу изменений в контейнере posts, чтобы переносить в контейнер users все новые или измененные записи. И так как перечисление записей не требует возврата полного содержимого, мы можем усечь их в процессе.
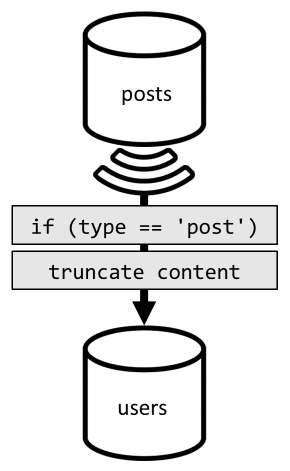
Теперь наш запрос можно направить к контейнеру users и использовать фильтрацию по ключу секции этого контейнера.

| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
4 госпожа |
6.46 ЕЗ |
✅ |
[Q6] — список "x" самых свежих записей в краткой форме (веб-канал)
Мы должны иметь дело с аналогичной ситуацией здесь: даже после того, как больше запросов осталось ненужным при денормализации, введенной в версии 2, оставшийся запрос не фильтрует ключ секции контейнера:
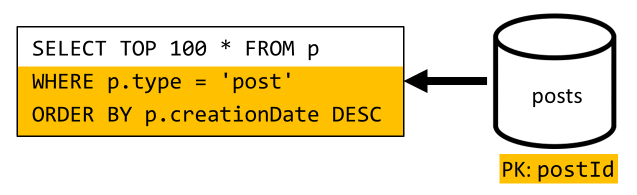
Применяя тот же подход, производительность и масштабируемость этого запроса можно увеличить, ограничив область его действия одной секцией. Только нажатие одной секции возможно, потому что нам нужно вернуть только ограниченное количество элементов. Чтобы заполнить домашнюю страницу платформы блогов, нам просто нужно получить 100 последних записей без необходимости разбиения на страницы по всему набору данных.
Чтобы оптимизировать этот последний запрос, мы добавляем в архитектуру третий контейнер, полностью посвященный обслуживанию этого запроса. Добавим также денормализацию запросов в этот новый контейнер feed:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Поле type секционирует этот контейнер, который всегда post находится в наших элементах. Это гарантирует, что все элементы в контейнере будут размещаться в одной секции.
Для достижения такой денормализации нужно лишь подключить конвейер канала изменений, который мы создали ранее, для передачи записей в новый контейнер. Здесь важно помнить один важный момент — нам нужно хранить только 100 самых последних записей, иначе размер контейнера может превысить максимальный размер секции. Это ограничение можно реализовать путем вызова после триггера при каждом добавлении документа в контейнер:
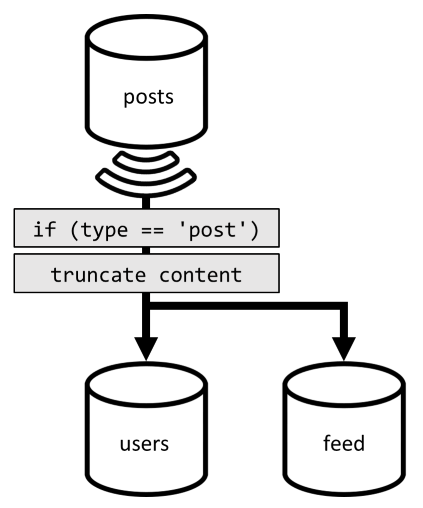
Усечь коллекцию можно с помощью такого запроса:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
И, наконец, мы переадресуем существующий запрос в новый контейнер feed:
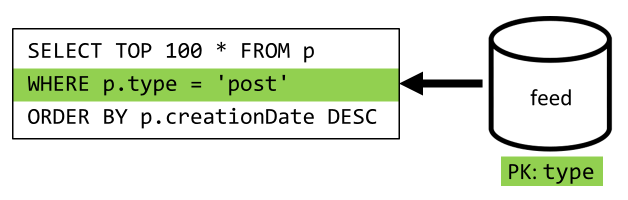
| Задержка | Стоимость в ЕЗ | Производительность |
|---|---|---|
9 госпожа |
16.97 ЕЗ |
✅ |
Заключение
Давайте рассмотрим общие улучшения производительности и масштабируемости, которые мы представили в различных версиях нашего дизайна.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
Мы оптимизированы для чтения тяжелый сценарий
Возможно, вы заметили, что мы сосредоточили наши усилия на повышении производительности запросов на чтение (запросы) за счет запросов на запись (команды). При операциях записи теперь часто запускаются действия денормализации через каналы изменений, что повышает затраты на их вычисление и длительность выполнения.
Мы оправдываем это внимание на производительность чтения тем фактом, что платформа блога (как и большинство социальных приложений) является тяжелой для чтения. Рабочая нагрузка с большим объемом чтения указывает, что объем запросов на чтение, которые он должен обслуживать, обычно является порядком больше, чем количество запросов на запись. Увеличение ресурсоемкости для операций записи позволяет снизить стоимость и повысить эффективность операций чтения.
Если мы рассмотрим самую крайнюю оптимизацию, мы сделали, [Q6] пошел с 2000+ ЕЗ до всего 17 ЕЗ; мы достигли этого путем денормализации постов стоимостью около 10 ЕЗ на каждый элемент. Так как запросы канала обновлений обслуживаются многократно чаще, чем создание или обновление записей, затраты на денормализацию можно считать несущественными по сравнению с увеличением эффективности.
Денормализацию можно применять последовательно
Улучшения масштабируемости, которые мы рассматривали в этой статье, включают денормализацию и дублирование данных по всему набору данных. Важно отметить, что вы не обязаны применить все приемы оптимизации к первому дню работы. Запросы, которые фильтруют ключи секций, выполняются лучше в масштабе, но запросы между секциями могут быть приемлемыми, если они вызываются редко или в ограниченном наборе данных. Если вы просто создаете прототип или запускаете продукт с небольшой и контролируемой пользовательской базой, вы можете, вероятно, поэкономить эти улучшения для дальнейшего использования. Важно следить за производительностью вашей модели, чтобы решить, следует ли и когда пришло время их привлечь.
В канале изменений, который мы используем для распространения обновлений в другие контейнеры, постоянно сохраняются все обновления. Это сохраняемость позволяет запрашивать все обновления после создания контейнера и денормализованных представлений начальной загрузки в качестве однократной операции перехвата, даже если у вашей системы уже есть много данных.
Следующие шаги
После этого вводные сведения о практическом моделировании и секционирования данных можно проверить следующие статьи, чтобы ознакомиться с основными понятиями, которые мы рассмотрели:
- Work with databases, containers, and items (Работа с базами данных, контейнерами и элементами)
- Секционирование в Azure Cosmos DB
- Change feed in Azure Cosmos DB (Канал изменений в Azure Cosmos DB)
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по