Моделирование данных в Azure Cosmos DB
ОБЛАСТЬ ПРИМЕНЕНИЯ: ![]() NoSQL
NoSQL
В то время как бессхемные базы данных, такие как Azure Cosmos DB, позволяют очень легко хранить и запрашивать неструктурированные и полуструктурированные данные, вам следует потратить некоторое время на обдумывание модели данных, чтобы получить максимальную отдачу от службы с точки зрения производительности и масштабируемости, а также с точки зрения уменьшения затрат.
Как данные будут храниться? Как приложение будет получать данные и выполнять запросы по ним? Ориентировано ли ваше приложение на запись или на чтение?
Ознакомившись с данной статьей, вы сможете ответить на следующие вопросы.
- Что такое моделирование данных и почему оно так важно?
- Чем различается моделирование данных в Azure Cosmos DB и в реляционной базе данных?
- Как выразить связи данных в нереляционной базе данных?
- Когда следует внедрять данные, а когда — связывать?
Числа в JSON
Azure Cosmos DB сохраняет документы в ФОРМАТЕ JSON. Это означает, что необходимо точно определить, нужно ли преобразовывать числа в строки перед их сохранением в JSON. Лучше, чтобы все числа преобразовывались в String, если есть вероятность того, что они находятся вне границ двойной точности чисел в соответствии со стандартом IEEE 754 binary64. В спецификации JSON указаны причины, по которым использование чисел за пределами этих границ в целом не рекомендуется в JSON из-за вероятных проблем со взаимодействием. Эти проблемы особенно важны для ключевого столбца секции, так как они неизменяемы и требуют, чтобы переноса данных позже их изменил.
Внедрение данных
Начиная моделировать данные в Microsoft Azure Cosmos DB, попробуйте обработать сущности как собственные элементы, представленные как JSON-документы.
Для сравнения, давайте сначала посмотрим, как моделировать данные в реляционной базе данных. В следующем примере показано, как можно сохранить в реляционной базе данных человека.
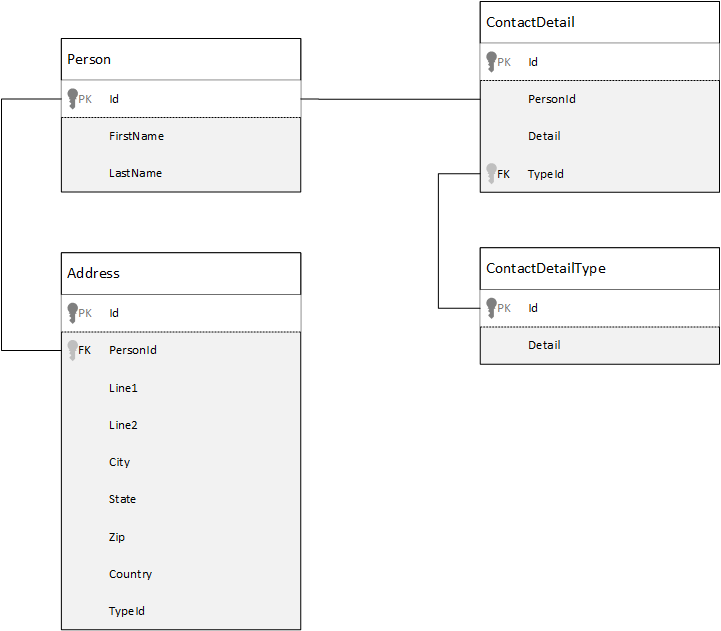
При работе с реляционными базами данных стратегия заключается в нормализации всех ваших данных. Нормализация данных обычно заключается в том, чтобы взять сущность, например определенного человека, и разбить его на отдельные компоненты. В приведенном выше примере у пользователя может быть несколько записей с контактными данными, а также несколько записей с адресом. Контактные данные можно дополнительно разделить, извлекая общие поля, такие как тип. То же самое относится и к адресу, поскольку каждая запись адреса может иметь тип Home или Business.
Руководящий принцип при нормализации данных заключается в том, чтобы избегать хранения избыточных данных в каждой записи и использовать только ссылки на эти данные. Для считывания данных о человеке со всеми его сведениями о контактах и адресами в этом примере необходимо использовать операторы JOIN, чтобы эффективно возвращать (или денормализировать) данные во время выполнения.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Операции записи во многих отдельных таблицах необходимы для обновления контактных данных и адресов одного человека.
А сейчас давайте рассмотрим, как смоделировать аналогичные данные в виде автономной сущности в Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Согласно описанному выше подходу мы выполнили денормализацию записи пользователя, внедрив всю относящуюся к нему информацию, такую как контактные данные и адреса, в отдельный документ JSON. Кроме того, отсутствие привязки к фиксированной схеме повышает гибкость работы, например, мы можем использовать сведения о контактах в самых разных формах.
Получение всей записи пользователя из базы данных теперь обеспечивается отдельной операцией чтения, выполняемой для отдельного контейнера и отдельного элемента. Обновление сведений о контактах и адресов в записи человека также обеспечивается одной операцией записи, выполняемой для одного элемента.
Благодаря денормализации данных ваше приложение может использовать меньше запросов и обновлений для выполнения распространенных операций.
Когда следует использовать внедрение
В общем случае модели внедренных данных следует использовать в следующих ситуациях:
- между сущностями существуют содержащиеся связи;
- между сущностями существуют связи один к нескольким ;
- есть редко изменяющиеся внедренные данные;
- есть внедренные данные, которые не будут увеличиваться неограниченно;
- есть внедренные данные, которые часто запрашиваются вместе.
Примечание.
Обычно модели денормализованных данных обеспечивают повышенную производительность при чтении .
Когда внедрение использовать не следует
Хотя основной подход для Microsoft Azure Cosmos DB заключается в том, чтобы выполнить денормализацию всех элементов и внедрить все данные в один элемент, это может привести к некоторым нежелательным ситуациям.
Рассмотрим этот фрагмент кода JSON.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Так могла бы выглядеть сущность публикации с внедренными комментариями, если бы мы моделировали обычный блог или систему CMS. Проблема с этим примером заключается в том, что массив комментариев является неограниченным, то есть предела для количества комментариев к отдельной публикации (практически) не существует. Это может стать проблемой, так как размер элемента может расти бесконечно, поэтому такого подхода следует избегать.
По мере увеличения элемента пропорционально ухудшается возможность передачи данных, а также чтения и обновления элемента.
В этом случае лучше рассмотреть следующую модель данных.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Эта модель содержит документ для каждого комментария со свойством, содержащим идентификатор публикации. Она позволяет публикациям содержать любое количество комментариев и может эффективно расширяться. Пользователи, желающие увидеть не только последние комментарии, будут запрашивать этот контейнер для передачи postId, который должен быть ключом секции для контейнера комментариев.
Кроме того, внедрение данных нельзя назвать удачным решением в ситуациях, когда эти данные часто используются в разных элементах и постоянно изменяются.
Рассмотрим этот фрагмент кода JSON.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Этот код может представлять биржевой портфель человека. Мы решили внедрить информацию об акциях в каждый документ портфеля. В среде, где связанные данные часто изменяются, например в приложении для торговли акциями, внедрение часто изменяемых данных означает, что всякий раз при совершении сделки с акцией вы постоянно обновляете каждый документ портфеля.
В течение дня акции zbzb могут покупать и продавать сотни раз, и zbzb могут входить в портфели тысяч пользователей. В случае использования описанной выше модели данных нам пришлось бы обновлять многие тысячи документов портфелей каждый день, что затруднило бы масштабирование системы.
Эталонные данные
Внедрение данных отлично подходит для многих ситуаций, однако существуют сценарии, в которых денормализация данных вызовет больше проблем, чем принесет пользы. Что же нам делать теперь?
Связи между сущностями можно задавать не только в реляционных базах данных. В базе данных документов можно поместить в один документ сведения, которые связаны с данными в других документах. Мы не рекомендуем создавать системы, для реализации которых лучше подходит реляционная база данных, в Azure Cosmos DB или любой другой базе данных документов, однако простые связи между данными не составляют проблемы и могут быть полезны.
В приведенном ниже коде JSON мы решили использовать использованный ранее пример биржевого портфеля, однако здесь мы не внедряем элемент акции в портфеле, а ссылаемся на него. Если элемент акции часто изменяется в течение дня, то обновлять требуется единственный документ акции.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Недостаток такого подхода проявляется, когда приложению нужно отобразить информацию о каждой имеющейся акции в портфеле человека; в этом случае потребуется выполнить множество обращений к базе данных, чтобы загрузить информацию для каждого документа акции. Здесь мы приняли решение повысить эффективность операций записи, которые часто выполняются в течение дня, однако это затруднило выполнение операций чтения, которые оказывают меньшее влияние на производительность всей данной системы.
Примечание.
Модели нормализованных данных могут потребовать больше круговых путей к серверу.
Сведения о внешнем ключе
Поскольку сейчас концепция ограничения, основанная на внешнем ключе или чем-либо другом, отсутствует, все отношения между документами представляют собой "слабые связи" и не проверяются самой СУБД. Если вы хотите убедиться, что данные, на которые ссылается документ, действительно существуют, это нужно сделать в приложении, с помощью триггеров на стороне сервера или хранимых процедур в Azure Cosmos DB.
Когда следует использовать ссылки
В общем случае модели нормализованных данных следует использовать в следующих ситуациях:
- Осуществляется представление связей один ко многим .
- Осуществляется представление связей многие ко многим .
- Связанные данные часто изменяются.
- Данные, на которые указывает ссылка, могут быть неограниченными.
Примечание.
Обычно нормализация обеспечивает повышенную производительность при записи .
Куда следует поместить связь
Рост связи поможет определить, в каком документе следует сохранить ссылку.
Давайте рассмотрим следующий код JSON, моделирующий издателей и книги.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Если на издателя приходится небольшое число книг, а рост ограничен, то может оказаться удобным хранить ссылку на книгу в документе издателя. Однако если число книг на издателя не имеет ограничений, эта модель данных приведет к изменяемым и разрастающимся массивам, как в приведенном выше примере с документом издателя.
Небольшая доработка помогает получить модель, которая все еще представляет те же данные, однако избавляется от крупных изменяемых коллекций.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
В приведенном выше примере мы поместили неограниченную коллекцию в документ издателя. Вместо этого мы просто воспользуемся ссылкой на издателя в каждом документе книги.
Как моделировать связи "многие ко многим"?
В реляционной базе данных связи многие ко многим часто моделируются с помощью таблиц JOIN, которые просто соединяют вместе записи из других таблиц.
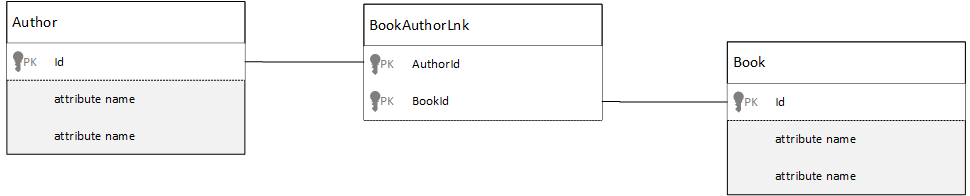
У вас может возникнуть желание реплицировать это с помощью документов и создать модель данных, аналогичную приведенной ниже.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Такой подход будет работать. Однако при загрузке автора вместе с его книгами или книги вместе с ее автором всегда потребуется отправлять два дополнительных запроса в базу данных. Один запрос отправляется в документ присоединения, а другой — для получения самого присоединяемого документа.
Если эта таблица присоединения всего лишь соединяет два элемента данных, почему бы просто не отказаться от нее? Рассмотрим следующий пример.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Если у меня есть автор, я сразу же узнаю, какие книги он написал, и наоборот, если у меня загружен документ книги, я получу сведения о ее авторах. Это позволяет отказаться от промежуточного запроса к таблице JOIN и сократить количество круговых путей для вашего приложения.
Гибридные модели данных
Мы рассмотрели внедрение (или денормализацию) данных и создание ссылок для данных (или нормализацию). Каждый подход имеет свои достоинства и недостатки.
Однако далеко не всегда следует придерживаться лишь одного из подходов — можно попробовать совместить их.
Учитывая применяемые в приложении схемы использования и рабочие нагрузки, в некоторых случаях совмещение внедрения и ссылок может иметь смысл и позволяет упростить логическую схему приложения, сократить число круговых путей к серверу и при этом сохранить высокий уровень производительности.
Давайте рассмотрим следующий код JSON.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Здесь мы в большей степени придерживались модели внедрения, где данные из других сущностей внедряются в документ верхнего уровня, однако для остальных данных используются ссылки.
Если взглянуть на документ книги, можно заметить несколько интересных полей в массиве авторов. Существует поле id, которое используется для обратной ссылки на документ автора, что является стандартным решением в модели нормализации, однако также присутствуют поля name и thumbnailUrl. Мы могли бы ограничиться полем id и заставить приложение получать всю необходимую информацию из соответствующего документа автора с использованием "ссылки", но поскольку наше приложение выводит имя автора и эскиз для каждой отображаемой книги, мы можем сэкономить по одному круговому пути к серверу на каждую книгу в списке, выполнив денормализацию некоторых данных об авторе.
Естественно, в случае изменения имени автора или обновления его фотографии нам пришлось бы обновить каждую опубликованную им книгу, но в нашем приложении такое решение вполне уместно, так как авторы довольно редко меняют свои имена.
В примере используются значения предварительно вычисленных статистических выражений, чтобы сэкономить вычислительные ресурсы на операции чтения. В данном примере некоторые данные, внедренные в документ автора, вычисляются во время выполнения. Каждый раз при публикации новой книги создается документ книги, и для поля countOfBooks задается вычисленное значение, зависящее от числа существующих для данного автора документов книги. Такая оптимизация хорошо подходит для систем с большим количеством операций чтения, где можно выполнять вычисления в операциях записи для повышения производительности операций чтения.
Использование модели с предварительно вычисленными значениями в полях стало возможным благодаря тому, что Azure Cosmos DB поддерживает транзакции с несколькими документами. Многие хранилища NoSQL не позволяют выполнять транзакции между документами, подталкивая при проектировании к связанным с этим ограничением решениям, таким как "Всегда внедряйте все, что можно". В Azure Cosmos DB вы можете использовать триггеры на стороне сервера или хранимые процедуры, которые вставляют книги и обновляют авторов в рамках транзакции ACID. Теперь вам не обязательно внедрять все в один документ просто для того, чтобы обеспечить согласованность данных.
Различия между типами документов
В некоторых случаях может потребоваться смешать различные типы документов в одной коллекции. Обычно это происходит, когда требуется, чтобы несколько связанных документов находились в одном разделе. Например, можно разместить книги и обзоры книг в одной и той же коллекции и секционировать их по bookId. В такой ситуации для различения в документы обычно требуется добавить поле, определяющее их тип.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Моделирование данных для Azure Synapse Link и аналитическое хранилище Azure Cosmos DB
Azure Synapse Link для Azure Cosmos DB — это облачная гибридная транзакционно-аналитическая возможность обработки (HTAP), которая позволяет вам выполнять аналитику операционных данных в Azure Cosmos DB почти в реальном времени. Azure Synapse Link обеспечивает тесную эффективную интеграцию между Azure Cosmos DB и Azure Synapse Analytics.
Эта интеграция происходит через аналитическое хранилище Azure Cosmos DB — столбцовое представление данных о ваших транзакциях, которое позволяет использовать масштабную аналитику без влияния на транзакционные рабочие нагрузки. Это аналитическое хранилище подходит для быстрого и экономичного выполнения запросов к большим наборам операционных данных без копирования данных и влияния на производительность транзакционных рабочих нагрузок. Когда вы создаете контейнер с включенным аналитическим хранилищем или включаете аналитическое хранилище в существующем контейнере, все транзакционные вставки, обновления и удаления синхронизируются с аналитическим хранилищем почти в реальном времени, и вам не нужно использовать канал изменений или задания извлечения, преобразования и загрузки (ETL).
С помощью Azure Synapse Link теперь можно непосредственно подключаться к контейнерам Azure Cosmos DB из Azure Synapse Analytics и обращаться к аналитическому хранилищу, не тратя при этом единицы запросов (ЕЗ). Сейчас Azure Synapse Analytics поддерживает Azure Synapse Link с Synapse Apache Spark и бессерверные пулы SQL. Если вы используете глобально распределенную учетную запись Azure Cosmos DB, после включения аналитического хранилища для контейнера он будет доступен во всех регионах для этой учетной записи.
Автоматический вывод схемы аналитического хранилища
В то время как транзакционное хранилище Azure Cosmos DB считается полуструктурированными данными с построчным форматированием, аналитическое хранилище имеет столбцовый и структурированный формат. Это преобразование выполняется для клиентов автоматически с использованием правил вывода схемы для аналитического хранилища. В процессе преобразования есть ограничения: максимальное количество уровней вложенности, максимальное количество свойств, неподдерживаемые типы данных и другие.
Примечание.
В контексте аналитического хранилища мы рассматриваем следующие структуры как свойство:
- "Элементы" JSON или "пары строка-значение с разделителем
:". - Объекты JSON с разделителями
{и}. - Массивы JSON с разделителями
[и].
Вы можете свести к минимуму влияние преобразований при выводе схемы и максимально расширить аналитические возможности, используя следующие методы.
нормализация
Нормализация теряет смысл, так как с помощью Azure Synapse Link можно соединять контейнеры, используя T-SQL или Spark SQL. Ожидаемые преимущества нормализации:
- меньший объем данных как в транзакционном, так и в аналитическом хранилище;
- меньший масштаб транзакций;
- меньше свойств в каждом документе;
- структуры данных с меньшим количеством уровней вложенности.
Обратите внимание, что два последних фактора (меньше свойств и меньше уровней), не только способствуют производительности аналитических запросов, но и снижают вероятность того, что часть данных не будет представлена в аналитическом хранилище. Как описано в статье о правилах автоматического вывода схемы, существуют ограничения на количество уровней и свойств, представленных в аналитическом хранилище.
Еще одним важным фактором нормализации является то, что бессерверные пулы SQL в Azure Synapse поддерживают наборы результатов с количеством столбцов до 1000, а в этом ограничении учитываются и отображаемые вложенные столбцы. Другими словами, как для аналитического хранилища, так и для бессерверных пулов SQL в Synapse действует ограничение в 1000 свойств.
Но что делать, ведь нормализация — это важный способ моделирования данных для Azure Cosmos DB? Ответ заключается в том, что вы должны найти правильный баланс для транзакционных и аналитических рабочих нагрузок.
Ключ раздела
В аналитическом хранилище ключ секции Azure Cosmos DB не используется. И теперь вы можете использовать для копий аналитического хранилища настраиваемое секционирование аналитического хранилища, используя любой ключ секции. Благодаря такой изоляции можно выбрать ключ секции для транзакционных данных, сосредотачиваясь на приеме данных и операциях точечного чтения, а запросы между секциями можно выполнять с помощью Azure Synapse Link. Рассмотрим пример.
В гипотетическом сценарии с глобальной сетью IoT device id — хороший вариант ключа секции, так как все устройства содержат похожий объем данных и в такой ситуации не возникнет проблема "горячей" секции. Но если вы хотите проанализировать данные на более чем одном устройстве, например "все данные со вчерашнего дня" или "итоги по городу", могут возникнуть проблемы, так как это запросы между секциями. Эти запросы могут навредить производительности транзакций, так как для их выполнения используется часть пропускной способности в ЕЗ. Но с помощью Azure Synapse Link можно выполнять эти аналитические запросы, не тратя ЕЗ. Столбцовый формат аналитического хранилища оптимизирован для аналитических запросов, и служба Azure Synapse Link использует это, чтобы обеспечить высокую производительность при работе со средами выполнения Azure Synapse Analytics.
Типы данных и имена свойств
В статье о правилах автоматического вывода схемы перечислены поддерживаемые типы данных. В то время как неподдерживаемый тип данных блокирует представление в аналитическом хранилище, поддерживаемые типы данных могут по-разному обрабатываться средами выполнения Azure Synapse. Один из примеров: при использовании строк даты и времени, которые соответствуют стандарту ISO 8601 UTC, пулы Spark в Azure Synapse будут представлять эти столбцы как string, а бессерверные пулы SQL в Azure Synapse — как varchar(8000).
Еще одна проблема заключается в том, что Azure Synapse Spark принимает не все символы. Пробелы принимаются, в отличие от таких символов, как двоеточие, знак ударения и запятая. Предположим, что у документа есть свойство Имя, фамилия. Это свойство будет представлено в аналитическом хранилище, и бессерверный пул Synapse SQL сможет без проблем прочитать его. Но поскольку оно хранится в аналитическом хранилище, Azure Synapse Spark не может прочитать никаких данных из аналитического хранилища, включая все остальные свойства. В конечном счете использовать Azure Synapse Spark нельзя, если у вас есть одно свойство с неподдерживаемыми символами в имени.
Преобразование данных в плоскую структуру
Все свойства в корневом уровне данных Azure Cosmos DB будут представлены в аналитическом хранилище в виде столбца и все остальное, что находится на более глубоких уровнях модели данных документа, будет представлено в виде JSON, а также в вложенных структурах. Вложенные структуры требуют дополнительной обработки данных в средах выполнения Azure Synapse, чтобы преобразовать данные в структурированном формате в плоскую структуру, что может быть проблемой в сценариях с использованием больших данных.
В документе ниже в аналитическом хранилище будут храниться только два столбца — id и contactDetails. Для чтения всех остальных данных (email и phone) по отдельности требуется дополнительная обработка с использованием функций SQL.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
В документе ниже в аналитическом хранилище будут храниться три столбца: id, email, и phone. Все данные доступны напрямую в виде столбцов.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Распределение данных по уровням
Azure Synapse Link позволяет снизить затраты с учетом следующего:
- Меньше запросов в транзакционной базе данных.
- Ключ секции, оптимизированный для приема данных и операций точечного чтения, что уменьшает размер данных, сокращает частоту сценариев с "горячей" секцией и случаев разделения секций.
- Разделение данных на уровни, так как аналитический срок жизни (attl) не зависит от транзакционного срока жизни (tttl). Транзакционные данные можно хранить в транзакционном хранилище в течение нескольких дней, недель, месяцев, а в аналитическом хранилище — годами или вечно. Столбцовый формат аналитического хранилища обеспечивает естественное сжатие данных со степенью сжатия от 50 % до 90 %. А его стоимость за ГБ составляет около 10 % от фактической стоимости транзакционного хранилища. Дополнительные сведения о текущих ограничениях резервного копирования см. в статье Общие сведения об аналитическом хранилище.
- В вашей среде нет заданий извлечения, преобразования и загрузки, т. е. вам не нужно выделять на них ЕЗ.
Контролируемая избыточность
Это отличный вариант для ситуаций, когда модель данных уже существует и ее нельзя изменить. При этом существующая модель данных не подходит для аналитического хранилища из-за правил автоматического вывода схем, таких как предел вложенных уровней или максимальное количество свойств. В этом случае можно использовать канал изменений Azure Cosmos DB для репликации данных в другой контейнер, применив необходимые преобразования для модели данных, подходящей для Azure Synapse Link. Рассмотрим пример.
Сценарий
Контейнер CustomersOrdersAndItems используется для хранения онлайн-заказов, включая сведения о клиентах и товарах: адрес выставления счета, адрес доставки, способ доставки, состояние доставки, цена товара и т. д. Представлены только первые 1000 свойств, а ключевой информации аналитическое хранилище не содержит, что блокирует использование Azure Synapse Link. Контейнер содержит петабайты записей, невозможно изменить приложение и перестроить данные.
Еще один аспект проблемы — большой объем данных. Отдел аналитики постоянно использует миллиарды строк, что не позволяет ему применить tttl для удаления старых данных. Ведение всей истории данных в транзакционной базе данных из-за аналитических нужд требует постоянно выделять все больше ЕЗ, что влияет на затраты. Транзакционные и аналитические рабочие нагрузки конкурируют, пытаясь одновременно получить одни и те же ресурсы.
Что делать?
Решение с помощью канала изменений
- Команда технических решений решила использовать канал изменений для заполнения трех новых контейнеров:
Customers,OrdersиItems. При использовании канала изменений данные нормализуются и преобразуются в плоскую структуру. Из модели данных удаляются ненужные сведения, и каждый контейнер имеет почти 100 свойств, что позволяет избежать потери данных из-за ограничений автоматического вывода схемы. - В этих новых контейнерах включено аналитическое хранилище, и теперь в отделе аналитики для чтения данных используется Synapse Analytics, что сокращает использование ЕЗ, так как аналитические запросы выполняются в Synapse Apache Spark и беcсерверных пулах SQL.
- Контейнер
CustomersOrdersAndItemsтеперь имеет набор tttl для хранения данных только в течение шести месяцев, что позволяет сократить использование единиц запросов, так как в Azure Cosmos DB имеется не менее 1 единиц запросов на ГБ. Меньше данных, меньше единиц запросов.
Общие выводы
Самые большие выводы из этой статьи заключается в том, чтобы понять, что моделирование данных в мире без схемы является как никогда важным.
Точно так же, как не существует единственного способа представить элемент данных на экране, нет такого способа и для моделирования данных. Необходимо разобраться в принципах работы приложения, его механизмах формирования, использования и обработки данных. После этого с помощью представленных здесь рекомендаций вы можете приступить к созданию модели, которая оптимально соответствует основным потребностям вашего приложения. Благодаря отсутствию схемы в базе данных вы можете оперативно вносить изменения в приложения и легко корректировать модель данных соответствующим образом.
Следующие шаги
Дополнительные сведения об Azure Cosmos DB см. на странице документации по этой службе.
Чтобы понять, как сегментировать данные по нескольким разделам, ознакомьтесь со статьей Секционирование, ключи секции и масштабирование в DocumentDB.
Чтобы получить сведения о том, как моделировать и секционировать данные в Azure Cosmos DB и ознакомиться с практическим примером, ознакомьтесь со статьей Моделирование и секционирование данных с помощью практического примера.
См. учебный модуль Моделирование и секционирование данных в Azure Cosmos DB.
См. сведения о настройке и использовании Azure Synapse Link для Azure Cosmos DB.
Если вы планируете ресурсы для миграции в Azure Cosmos DB, Для планирования ресурсов можно использовать сведения об имеющемся кластере базы данных.
- Если вам известно только количество виртуальных ядер и серверов в существующем кластере баз данных, см. сведения об оценке единиц запросов на основе виртуальных ядер и серверов.
- Если вам известна стандартная частота запросов для текущей рабочей нагрузки базы данных, ознакомьтесь со статьей о расчете единиц запросов с помощью планировщика ресурсов Azure Cosmos DB
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по