Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Это важно
Azure Cosmos DB для PostgreSQL больше не поддерживается для новых проектов. Не используйте эту службу для новых проектов. Вместо этого используйте одну из этих двух служб:
Используйте Azure Cosmos DB для NoSQL как распределенное решение базы данных, предназначенное для крупномасштабных сценариев с соглашением об уровне доступности (SLA) 99.999%, мгновенным автомасштабированием и автоматическим переключением в случае отказа в нескольких регионах.
Используйте функцию эластичных кластеров Базы данных Azure для PostgreSQL для сегментированного PostgreSQL с помощью расширения Citus с открытым кодом.
Совместное размещение — это хранение взаимосвязанных данных вместе на одних и тех же узлах. Когда все необходимые данные доступны без дополнительных сетевых запросов, то запросы выполняются быстрее. Совместное размещение взаимосвязанных данных на разных узлах позволяет эффективно выполнять запросы параллельно на каждом узле.
Совместное размещение данных для таблиц с хэш-распределением
В Azure Cosmos DB для PostgreSQL строка хранится в сегменте, если хэш значения в столбце распределения попадает в хэш-диапазон сегментов. Сегменты с одинаковым диапазоном хэша всегда размещены на одном узле. Строки с одинаковыми значениями столбца распределения всегда находятся на одном узле в разных таблицах. Концепция хэш-распределенных таблиц также называется сегментированием на основе строк. В шардировании на основе схемы таблицы в распределенной схеме всегда размещаются в одном месте.
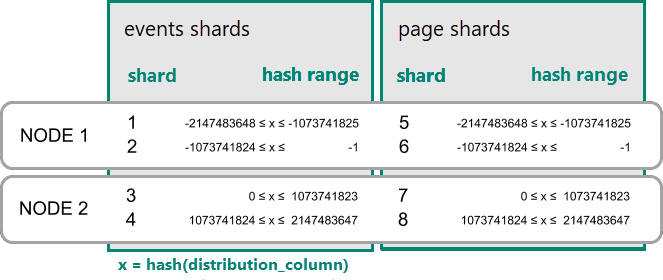
Практический пример совместного размещения
Рассмотрим следующие таблицы, которые могут быть частью многопользовательской веб-аналитики как услуги (SaaS).
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Теперь мы хотим ответить на запросы, которые могут выдаваться на панели мониторинга для клиента. Пример запроса: "Получить количество посещений за прошлую неделю для всех страниц, начинающихся с '/blog', для арендатора 6".
Если наши данные находились на одном сервере PostgreSQL, можно легко выразить запрос с помощью полнофункциональных операций, предлагаемых SQL:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Пока рабочий набор для этого запроса умещается в памяти, подходящим решением является таблица с одним сервером. Рассмотрим возможности масштабирования модели данных с помощью Azure Cosmos DB для PostgreSQL.
Распределение таблиц по идентификатору
Запросы к одному серверу начинают замедляться по мере роста количества арендаторов и объема данных, хранимых для каждого арендатора. Рабочий набор больше не помещается в памяти, а ЦП становится узким местом.
В этом случае можно сегментировать данные по многим узлам с помощью Azure Cosmos DB для PostgreSQL. Первый и самый важный выбор при решении сегментирования — это выбор столбца распределения. Начнем с упрощенного выбора использования event_id для таблицы событий и page_id для таблицы page:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Если данные распределены между разными узлами, мы не сможем выполнить соединение так, как это делается на одном узле PostgreSQL. Вместо этого необходимо выполнить два запроса.
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
После этого приложение должно объединить результаты выполнения двух шагов.
Процессу выполнения запросов необходимо обращаться к данным в сегментах, разбросанных по узлам.
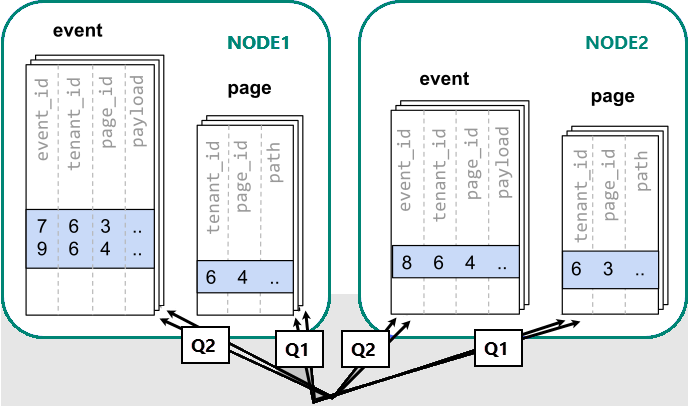
В этом случае распределение данных создает существенные недостатки.
- Затраты на выполнение запросов к каждому сегменту и запуск нескольких запросов.
- Дополнительные расходы на Q1, возвращающий множество строк клиенту.
- Q2 становится большим.
- Если необходимо записать запросы в несколько шагов, приложение нужно будет изменить.
Данные распределены, поэтому запросы можно выполнить параллельно. Это полезно только в том случае, если объем работы, выполняемой запросом, значительно превышает издержки, связанные с запросом к многим сегментам.
Распределение таблиц по клиентам
В Azure Cosmos DB для PostgreSQL строки с одинаковым значением столбца распространения гарантированно находятся на одном узле. Начиная заново, мы можем создавать таблицы с параметром tenant_id в качестве столбца распределения.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Теперь Azure Cosmos DB для PostgreSQL может ответить на исходный запрос с одним сервером без изменений (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Благодаря фильтрации и соединению по tenant_id система Azure Cosmos DB для PostgreSQL знает, что весь запрос может быть выполнен с помощью набора колокированных сегментов, содержащих данные для данного конкретного tenant. Один узел PostgreSQL может ответить на запрос за один шаг.
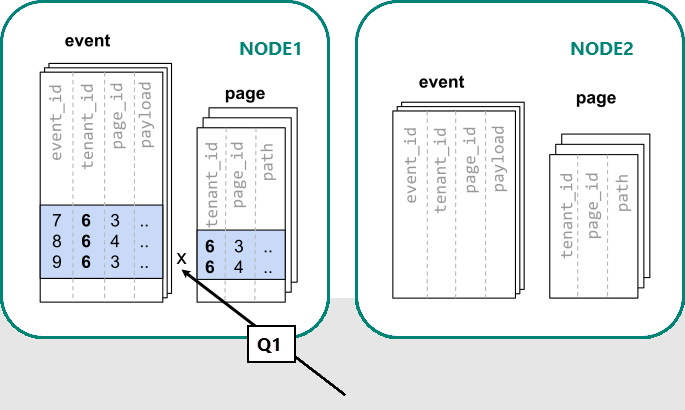
В некоторых случаях необходимо изменить запросы и схемы таблиц, добавив идентификатор клиента к уникальным ограничениям и условиям соединения. Это изменение обычно является простым.
Следующие шаги
- Узнайте, как данные арендатора совмещены в мультитенантном руководстве.