Перенос данных из Apache HBase в учетную запись Azure Cosmos DB для NoSQL
ОБЛАСТЬ ПРИМЕНЕНИЯ: ![]() NoSQL
NoSQL
Azure Cosmos DB — это масштабируемая, глобально распределенная, полностью управляемая база данных. Она обеспечивает гарантированный доступ к данным с низкой задержкой. Дополнительные сведения об Azure Cosmos DB см. в этой обзорной статье. В этой статье описывается перенос данных из HBase в учетную запись Azure Cosmos DB для NoSQL.
Различия между Azure Cosmos DB и HBase
Перед миграцией вам следует понять различия между Azure Cosmos DB и HBase.
Модель ресурсов
Azure Cosmos DB имеет следующую модель ресурсов: 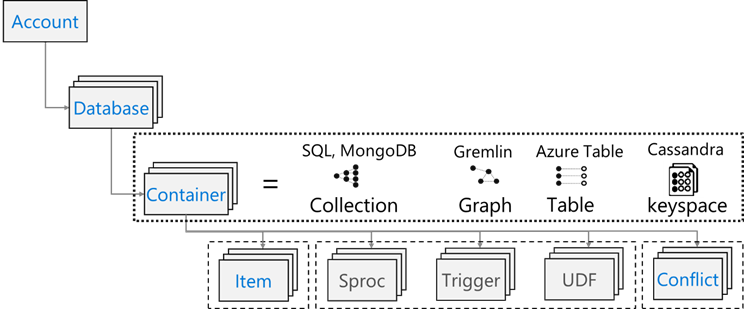
HBase имеет следующую модель ресурсов: 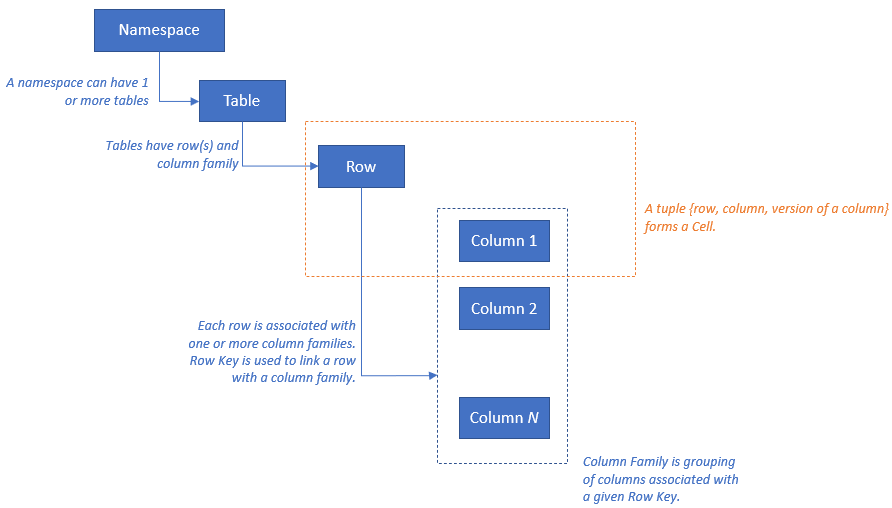
Сопоставление ресурсов
В следующей таблице показан принцип сопоставления между Apache HBase, Apache Phoenix и Azure Cosmos DB.
| HBase | Phoenix | Azure Cosmos DB |
|---|---|---|
| Кластер | Кластер | Счет |
| Пространство имен | Схема (если включена) | База данных |
| Таблица | Таблица | Контейнер или коллекция |
| Семейство столбцов | Семейство столбцов | Н/П |
| Row | Row | Элемент или документ |
| Версия (метка времени) | Версия (метка времени) | Неприменимо |
| Неприменимо | Первичный ключ | Ключ раздела |
| Н/П | Указатель | Указатель |
| Н/П | Вторичный индекс | Вторичный индекс |
| Н/П | Представления | Неприменимо |
| Неприменимо | Sequence | Н/П |
Сравнение структуры данных и различия
Основные различия между структурой данных Azure Cosmos DB и HBase:
RowKey
В HBase данные хранятся с помощью RowKey и по горизонтали разделяются на области по диапазону значений RowKey, указанному при создании таблицы.
С другой стороны, Azure Cosmos DB распределяет данные по секциям на основе хэш-значения указанного ключа секции.
Семейство столбцов
В HBase столбцы группируются в семейство столбцов.
Azure Cosmos DB (API для NoSQL) сохраняет данные в виде документа JSON . Следовательно, применяются все свойства, связанные со структурой данных JSON.
Timestamp
В HBase для обозначения версии нескольких экземпляров отдельной ячейки используется метка времени. С помощью метки времени можно запрашивать разные версии ячейки.
Azure Cosmos DB поставляется с возможностью Канал изменений, которая собирает и сохраняет все изменения в контейнере в порядке их возникновения. Затем он выводит отсортированный список документов в порядке, в котором они были изменены.
Формат данных
Формат данных HBase состоит из значений RowKey, Column Family (семейство столбцов): Column Name (имя столбца), Timestamp (Метка времени), Value (значение). Ниже приведен пример записи таблицы HBase:
ROW COLUMN+CELL 1000 column=Office:Address, timestamp=1611408732448, value=1111 San Gabriel Dr. 1000 column=Office:Phone, timestamp=1611408732418, value=1-425-000-0002 1000 column=Personal:Name, timestamp=1611408732340, value=John Dole 1000 column=Personal:Phone, timestamp=1611408732385, value=1-425-000-0001В Azure Cosmos DB для NoSQL объект JSON представляет формат данных. Ключ секции находится в поле документа и определяет, какое поле является ключом секции для коллекции. Azure Cosmos DB не имеет понятия метки времени, используемой для семейства столбцов или версии. Как уже было отмечено, эта служба поддерживает канал изменен, с помощью которого можно отслеживать и записывать изменения, внесенные в контейнер. Ниже приведен пример документа.
{ "RowId": "1000", "OfficeAddress": "1111 San Gabriel Dr.", "OfficePhone": "1-425-000-0002", "PersonalName": "John Dole", "PersonalPhone": "1-425-000-0001", }
Совет
HBase хранит данные в байтовом массиве, поэтому если вы хотите перенести данные, которые содержат двухбайтовые символы, в Azure Cosmos DB, данные должны быть закодированы в кодировке UTF-8.
Модель согласованности
В HBase чтение и запись строго согласованы.
Azure Cosmos DB предлагает пять четко определенных уровней согласованности. Каждый уровень предоставляет компромиссы по доступности и производительности. Поддерживаемые уровни согласованности — от самой строгой до самой слабой:
- Строгие
- Ограниченное устаревание
- Сеанс
- Постоянный префикс
- В конечном счете
Определение параметров
HBase
При развертывании HBase в корпоративном масштабе размер в первую очередь зависит от Master, Region Servers и ZooKeeper. Как и любое распределенное приложение, HBase предназначено для горизонтального увеличения масштаба. Производительность HBase в основном определяется размером RegionServers. Размер в основном определяется двумя ключевыми требованиями: пропускной способностью и размером наборов данных, которые должны храниться на базе HBase.
Azure Cosmos DB
Azure Cosmos DB — это решение PaaS корпорации Майкрософт, и подробные сведения о развертывании инфраструктуры скрыты от конечных пользователей. При подготовке контейнера Azure Cosmos DB платформа Azure автоматически подготавливает базовую инфраструктуру (вычислительные ресурсы, хранилище, память, сетевой стек) для поддержки требований к производительности данной рабочей нагрузки. Стоимость всех операций базы данных нормализуется с помощью Azure Cosmos DB и выражается в единицах запроса (ЕЗ).
При оценке количества ЕЗ, потребляемых вашей рабочей нагрузкой, учитывайте следующие факторы:
Существует калькулятор емкости, доступный для помощи в упражнении по размеру для ЕЗ.
Вы также можете использовать автомасштабирование подготовленной пропускной способности в Azure Cosmos DB, чтобы автоматически и мгновенно масштабировать пропускную способность (количество единиц запросов в секунду) для базы данных или контейнера. Пропускная способность масштабируется на основе использования без воздействия на доступность, задержку, пропускную способность или производительность рабочей нагрузки.
Распределение данных
Hbase HBase сортирует данные в соответствии с RowKey. Затем данные будут разделяться на регионы и храниться в RegionServers. Автоматическое секционирование разделяет регионы горизонтально в соответствии с политикой секционирования. Оно управляется значением, присвоенным параметру HBase hbase.hregion.max.filesize (по умолчанию — 10 ГБ). Запись в HBase с заданным значением RowKey всегда относится к одному региону. Кроме того, данные разделены на диске для каждого семейства столбцов. Это позволяет выполнять фильтрацию во время чтения и изоляции операций ввода/вывода в HFile.
Azure Cosmos DB Azure Cosmos DB использует секционирование, чтобы масштабировать отдельные контейнеры в базе данных. Секционирование разделяет элементы в контейнере на отдельные подмножества, называемые "логическими секциями". Логические секции формируются на основе значения "ключа секции", связанного с каждым элементом в контейнере. У всех элементы в логической секции одинаковое значение ключа секции. Каждая логическая секция может содержать до 20 ГБ данных.
Физические секции содержат реплика данных и экземпляр ядра СУБД Azure Cosmos DB. Эта структура позволяет обеспечить надежность и высокую доступность ваших данных, а пропускная способность делится поровну между локальными физическими секциями. Физические секции создаются и настраиваются автоматически, и вы не можете контролировать их размер, расположение или то, какие логические секции они содержат. Логические секции не разделяются между физическими секциями.
Как и для RowKey HBase, для Azure Cosmos DB важна структура ключа раздела. Ключ записи HBase работает путем сортировки и хранения непрерывных данных, а ключ секции Azure Cosmos DB — другой механизм, так как он выполняет хэш-распространение данных. Предполагая, что приложение с помощью HBase оптимизировано для шаблонов доступа к данным в HBase, используя тот же RowKey для ключа секции, не даст хороших результатов производительности. Так как это сортированные в HBase данные, может оказаться полезным составной индекс Azure Cosmos DB. Это необходимо, если вы хотите использовать предложение ORDER BY в нескольких полях. Кроме того, можно повысить производительность многих запросов на равенство и на диапазоны, определив составной индекс.
Доступность
HBase HBase состоит из Master, Region Server и ZooKeeper. Можно добиться высокого уровня доступности в одном кластере, сделав каждый компонент избыточным. При настройке геоизбыточности можно развернуть кластеры HBase в различных физических центрах обработки данных и использовать репликацию для синхронизации нескольких кластеров.
Azure Cosmos DB Azure Cosmos DB не требует какой-либо конфигурации, например избыточности компонентов кластера. Она предоствляет полный перечень Соглашений об уровне обслуживания для высокого уровня доступности, согласованности и задержки. Дополнительные сведения см . в разделе об уровне обслуживания azure Cosmos DB .
надежность данных.
Hbase HBase создана на основе распределенной файловой системы Hadoop (HDFS), и данные, хранимые в HDFS, реплицируются трижды.
Azure Cosmos DB Azure Cosmos DB обеспечивает высокий уровень доступности двумя основными способами. Сначала Azure Cosmos DB реплика tes данные между регионами, настроенными в учетной записи Azure Cosmos DB. Во-вторых, Azure Cosmos DB хранит четыре копии данных в регионе.
Факторы, которые следует учитывать перед миграцией
Зависимости системы
Этот аспект планирования ориентирован на понимание вышестоящих и нижестоящих зависимостей экземпляра HBase, переносимого в Azure Cosmos DB.
Пример нижестоящих зависимостей — приложения, которые читают данные из HBase. Для чтения из Azure Cosmos DB нужно выполнить их рефакторинг. При миграции необходимо учитывать следующие аспекты:
Вопросы по оценке зависимостей— является ли текущая система HBase независимым компонентом? Или она вызывает процесс в другой системе, или вызывается процессом в другой системе, или доступ к ней осуществляется с использованием службы каталогов? Работают ли другие важные процессы в кластере HBase? Необходимо уточнить эти системные зависимости, чтобы определить влияние миграции.
RPO и RTO для локального развертывания HBase.
Автономная и интерактивная миграция
Для успешной миграции данных важно понимать характеристики бизнеса, использующего базу данных, и решить, как ее выполнить. Выберите автономную миграцию, если вы можете полностью отключить систему, выполнить перенос данных и перезапустить систему в конечной точке. Кроме того, если база данных всегда занята и вы не можете позволить себе длительный простой, рассмотрите возможность миграции с подключением по сети.
Примечание.
В этом документе описывается только автономная миграция.
При выполнении автономной миграции данных она зависит от используемой версии HBase и доступных средств. Дополнительные сведения см. в разделе Перенос данных.
Замечания, связанные с быстродействием
Этот аспект планирования предназначен для понимания целевых показателей производительности для HBase и их перевод на семантику Azure Cosmos DB. Например, чтобы достичь X операций ввода-вывода в секунду в HBase, сколько единиц запросов (ЕЗ/с) потребуется в Azure Cosmos DB. Между HBase и Azure Cosmos DB существуют различия. В этом упражнении основное внимание уделяется описанию принципов перевода целевых показателей производительности из HBase в Azure Cosmos DB. На этом будет основано масштабирование.
Вопросы, на которые нужно ответить:
- В развертывании HBase будет много операций чтения или много операций записи?
- Какое соотношение между числом операций чтения и записи?
- Какое целевое значение операций ввода-вывода в секунду в виде процентиля?
- Как и какие приложения используются для загрузки данных в HBase?
- Как и какие приложения используются для чтения данных из HBase?
При выполнении запросов отсортированных данных, HBase быстро возвращает результат, так как данные отсортированы по RowKey. Однако у Azure Cosmos DB нет такой концепции. Чтобы оптимизировать производительность, можно использовать составные индексы.
Рекомендации по развертыванию
Вы можете использовать портал Azure или Azure CLI для развертывания Azure Cosmos DB для NoSQL. Так как назначение миграции — Azure Cosmos DB для NoSQL, выберите "NoSQL" для API в качестве параметра при развертывании. Кроме того, в соответствии с вашими требованиями к доступности настройте геоизбыточность, выполнение операций записи в нескольких регионах и зоны доступности.
Аспекты, связанные с сетевым подключением
Azure Cosmos DB имеет три основных варианта сети. Первый — это конфигурация, использующая общедоступный IP-адрес и контролирующая доступ с помощью брандмауэра IP-адресов (по умолчанию). Второй вариант — это конфигурация, использующая общедоступный IP-адрес и позволяющая получать доступ только из определенной подсети конкретной виртуальной сети (конечной точки службы). Третий — это конфигурация (частная конечная точка), которая соединяет частную сеть с использованием личного IP-адреса.
Дополнительные сведения о трех вариантах сети см. в следующих документах:
- Общедоступный IP-адрес с брандмауэром
- Общедоступный IP-адрес с конечной точкой службы
- Частная конечная точка
Оценка существующих данных
Поиск данных
Заранее соберите информацию из существующего кластера HBase, чтобы определить данные, которые вы хотите перенести. Это поможет вам определить, как перенести данные, определить, какие таблицы нужно перенести, понять структуру этих таблиц и как построить модель данных. Например, соберите такие сведения:
- версия HDI HBase;
- целевые таблицы миграции;
- сведения о семье столбцов;
- состояние таблиц.
Следующие команды показывают, как собирать сведения выше с помощью сценария оболочки hbase и хранить их в локальной файловой системе рабочего компьютера.
Получение версии HBase
hbase version -n > hbase-version.txt
Выходные данные:
cat hbase-version.txt
HBase 2.1.8.4.1.2.5
Получение списка таблиц
Вы можете получить список таблиц, которые хранятся в HBase. Если вы создали пространство имен, отличное от стандартного, оно будет выводиться в формате "Пространство имен: таблица".
echo "list" | hbase shell -n > table-list.txt
HBase 2.1.8.4.1.2.5
Выходные данные:
echo "list" | hbase shell -n > table-list.txt
cat table-list.txt
TABLE
COMPANY
Contacts
ns1:t1
3 row(s)
Took 0.4261 seconds
COMPANY
Contacts
ns1:t1
Определение таблиц, которые нужно перенести
Получите подробные сведения о семействах столбцов в таблице, указав имя переносимой таблицы.
echo "describe '({Namespace}:){Table name}'" | hbase shell -n > {Table name} -schema.txt
Выходные данные:
cat {Table name} -schema.txt
Table {Table name} is ENABLED
{Table name}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'cf2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.5775 seconds
Получение семейств столбцов в таблице и их параметров
echo "status 'detailed'" | hbase shell -n > hbase-status.txt
Выходные данные:
{HBase version}
0 regionsInTransition
active master: {Server:Port number}
2 backup masters
{Server:Port number}
{Server:Port number}
master coprocessors: []
# live servers
{Server:Port number}
requestsPerSecond=0.0, numberOfOnlineRegions=44, usedHeapMB=1420, maxHeapMB=15680, numberOfStores=49, numberOfStorefiles=14, storefileUncompressedSizeMB=7, storefileSizeMB=7, compressionRatio=1.0000, memstoreSizeMB=0, storefileIndexSizeKB=15, readRequestsCount=36210, filteredReadRequestsCount=415729, writeRequestsCount=439, rootIndexSizeKB=15, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=464, currentCompactedKVs=464, compactionProgressPct=1.0, coprocessors=[GroupedAggregateRegionObserver, Indexer, MetaDataEndpointImpl, MetaDataRegionObserver, MultiRowMutationEndpoint, ScanRegionObserver, SecureBulkLoadEndpoint, SequenceRegionObserver, ServerCachingEndpointImpl, UngroupedAggregateRegionObserver]
[...]
"Contacts,,1611126188216.14a597a0964383a3d923b2613524e0bd."
numberOfStores=2, numberOfStorefiles=2, storefileUncompressedSizeMB=7168, lastMajorCompactionTimestamp=0, storefileSizeMB=7, compressionRatio=0.0010, memstoreSizeMB=0, readRequestsCount=4393, writeRequestsCount=0, rootIndexSizeKB=14, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=0, currentCompactedKVs=0, compactionProgressPct=NaN, completeSequenceId=-1, dataLocality=0.0
[...]
Вы можете получить полезные сведения об определении размера, такие как размер памяти для кучи, количество регионов, количество запросов в качестве состояния кластера и размер данных в сжатом или не сжатом состоянии таблицы.
Если вы используете Apache Phoenix в кластере HBase, необходимо также собирать данные из Phoenix.
- Целевая таблица миграции
- Схемы таблиц
- Индексы
- Первичный ключ
Подключение к Apache Phoenix на кластере
sqlline.py ZOOKEEPER/hbase-unsecure
Получение списка таблиц
!tables
Получение сведений о таблице
!describe <Table Name>
Получение сведений об индексе
!indexes <Table Name>
Получение сведений о первичном ключе
!primarykeys <Table Name>
Перенос данных
Варианты переноса
Существуют различные методы переноса данных в автономном режиме, но здесь мы рассмотрим, как использовать Фабрика данных Azure.
| Решение | Исходная версия | Рекомендации |
|---|---|---|
| Azure Data Factory | HBase < 2 | Простота настройки. Подходит для больших наборов данных. HBase 2 и более поздних версий не поддерживается. |
| Apache Spark | Все версии | Поддержка всех версий HBase. Подходит для больших наборов данных. Требуется настройка Spark. |
| Пользовательское средство с библиотекой массового исполнителя Azure Cosmos DB | Все версии | Наибольшая гибкость для создания пользовательских инструментов переноса данных с помощью библиотек. Требуется больше усилий по настройке. |
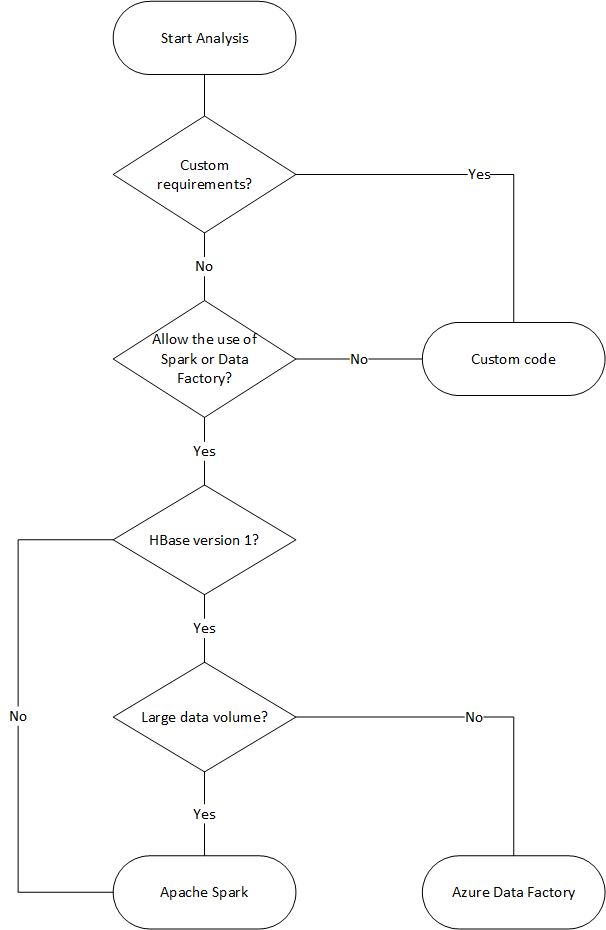
В следующей блок-схеме используются определенные условия для выбора доступных способов переноса данных.
Перенос данных с помощью Фабрики данных
Этот вариант подходит для больших наборов данных. Используется библиотека исполнителя массовых операций в Azure Cosmos DB. Контрольных точек нет, поэтому если во время миграции возникнут проблемы, вам придется перезапустить процесс. Вы также можете использовать локальную среду выполнения интеграции Фабрики данных для подключения к локальной базе данных HBase или развертывания Фабрики данных в управляемой виртуальной сети и подключения к локальной сети через VPN или ExpressRoute.
Действие копирования Фабрики данных поддерживает HBase в качестве источника данных. Дополнительные сведения см. в статье Копирование данных из HBase с помощью фабрики данных Azure.
Azure Cosmos DB (API для NoSQL) можно указать в качестве назначения для данных. Дополнительные сведения см. в статье о копировании и преобразовании данных в Azure Cosmos DB (API для NoSQL) с помощью Фабрика данных Azure статьи.
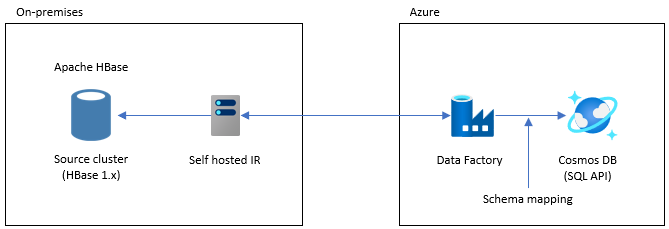
Миграция с помощью Apache Spark — apache HBase Подключение or и соединителя Azure Cosmos DB Spark
Вот пример переноса данных в Azure Cosmos DB. В нем предполагается, что HBase 2.1.0 и Spark 2.4.0 работают в одном кластере.
Apache Spark — репозиторий Apache HBase Connector можно найти в разделе Apache Spark — Apache HBase Connector.
Для использования соединителя Azure Cosmos DB Spark обратитесь к краткому руководству и загрузите соответствующую библиотеку для своей версии Spark.
Скопируйте hbase-site.xml в каталог конфигурации Spark.
cp /etc/hbase/conf/hbase-site.xml /etc/spark2/conf/Запустите spark -shell с соединителем Spark HBase и соединитеелем Azure Cosmos DB Spark.
spark-shell --packages com.hortonworks.shc:shc-core:1.1.0.3.1.2.2-1 --repositories http://repo.hortonworcontent/groups/public/ --jars azure-cosmosdb-spark_2.4.0_2.11-3.6.8-uber.jarПосле запуска оболочки Spark выполните код Scala описанным ниже образом. Импорт библиотек, необходимых для загрузки данных из HBase.
// Import libraries import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.execution.datasources.hbase._ import org.apache.spark.{SparkConf, SparkContext} import spark.sqlContext.implicits._Определите схему каталога Spark для таблиц HBase. Здесь используется Namespace (Пространство имен) по умолчанию (default), а таблица называется Contacts (Контакты). Ключ записи указывается как ключ. Значения Columns (Столбцы), Column Family (Семейство столбцов) и Column (Столбец) сопоставляются с каталогом Spark.
// define a catalog for the Contacts table you created in HBase def catalog = s"""{ |"table":{"namespace":"default", "name":"Contacts"}, |"rowkey":"key", |"columns":{ |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} |} |}""".stripMarginЗатем определите метод получения данных из таблицы контактов HBase как DataFrame.
def withCatalog(cat: String): DataFrame = { spark.sqlContext .read .options(Map(HBaseTableCatalog.tableCatalog->cat)) .format("org.apache.spark.sql.execution.datasources.hbase") .load() }Создайте DataFrame определенным методом.
val df = withCatalog(catalog)Затем импортируйте библиотеки, необходимые для использования соединителя Spark Для Azure Cosmos DB.
import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark._ import com.microsoft.azure.cosmosdb.spark.config.ConfigНастройте параметры записи данных в Azure Cosmos DB.
val writeConfig = Config(Map( "Endpoint" -> "https://<cosmos-db-account-name>.documents.azure.com:443/", "Masterkey" -> "<comsmos-db-master-key>", "Database" -> "<database-name>", "Collection" -> "<collection-name>", "Upsert" -> "true" ))Запишите данные DataFrame в Azure Cosmos DB.
import org.apache.spark.sql.SaveMode df.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
Запись выполняется параллельно с высокой скоростью и производительностью. Обратите внимание на то, что это может расходовать единицы запроса в секунду на стороне Azure Cosmos DB.
Phoenix
Phoenix поддерживается как источник данных Фабрики данных. Пошаговые инструкции см. в следующих документах.
- Копирование данных из Phoenix с помощью Фабрики данных Azure
- Копирование данных из HBase с помощью Фабрики данных Azure
Перенос кода
В этом разделе описываются различия между созданием приложений в Azure Cosmos DB для NoSQLs и HBase. В примерах ниже используются API Apache HBase 2.x и Azure Cosmos DB Java SDK 4.
Эти примеры кода HBase основаны на тех, которые описаны в официальной документации HBase.
Приведенный здесь код для Azure Cosmos DB основан на документации по Azure Cosmos DB для NoSQL: примеры пакета SDK java версии 4. Полный пример кода можно найти в документации.
Ниже показаны сопоставления миграции кода, но ключи секций HBase и Azure Cosmos DB, используемые в этих примерах, не всегда хорошо разработаны. Разработайте их в соответствии с фактической моделью данных источника миграции.
Установка подключения
HBase
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","zookeepernode0,zookeepernode1,zookeepernode2");
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.cluster.distributed", "true");
Connection connection = ConnectionFactory.createConnection(config)
Phoenix
//Use JDBC to get a connection to an HBase cluster
Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333",props);
Azure Cosmos DB
// Create sync client
client = new CosmosClientBuilder()
.endpoint(AccountSettings.HOST)
.key(AccountSettings.MASTER_KEY)
.consistencyLevel(ConsistencyLevel.{ConsistencyLevel})
.contentResponseOnWriteEnabled(true)
.buildClient();
Создание базы данных, таблицы или коллекции
HBase
// create an admin object using the config
HBaseAdmin admin = new HBaseAdmin(config);
// create the table...
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("FamilyTable"));
// ... with single column families
tableDescriptor.addFamily(new HColumnDescriptor("ColFam"));
admin.createTable(tableDescriptor);
Phoenix
CREATE IF NOT EXISTS FamilyTable ("id" BIGINT not null primary key, "ColFam"."lastName" VARCHAR(50));
Azure Cosmos DB
// Create database if not exists
CosmosDatabaseResponse databaseResponse = client.createDatabaseIfNotExists(databaseName);
database = client.getDatabase(databaseResponse.getProperties().getId());
// Create container if not exists
CosmosContainerProperties containerProperties = new CosmosContainerProperties("FamilyContainer", "/lastName");
// Provision throughput
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
// Create container with 400 RU/s
CosmosContainerResponse databaseResponse = database.createContainerIfNotExists(containerProperties, throughputProperties);
container = database.getContainer(databaseResponse.getProperties().getId());
Создание записи или документа
HBase
HTable table = new HTable(config, "FamilyTable");
Put put = new Put(Bytes.toBytes(RowKey));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes("1"));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Witherspoon"));
table.put(put)
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Witherspoon’);
Azure Cosmos DB
Azure Cosmos DB обеспечивает безопасность типов с помощью модели данных. Мы используем модель данных с именем Family.
public class Family {
public Family() {
}
public void setId(String id) {
this.id = id;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String id="";
private String lastName="";
}
Выше приведена часть кода. См. полный пример кода.
Класс Family используется для определения документа и вставки элемента.
Family family = new Family();
family.setLastName("Witherspoon");
family.setId("1");
// Insert this item as a document
// Explicitly specifying the /pk value improves performance.
container.createItem(family,new PartitionKey(family.getLastName()),new CosmosItemRequestOptions());
Чтение записи или документа
HBase
HTable table = new HTable(config, "FamilyTable");
Get get = new Get(Bytes.toBytes(RowKey));
get.addColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Result result = table.get(get);
byte[] col = result.getValue(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Phoenix
SELECT lastName FROM FamilyTable;
Azure Cosmos DB
// Read document by ID
Family family = container.readItem(documentId,new PartitionKey(documentLastName),Family.class).getItem();
String sql = "SELECT lastName FROM c";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
Обновление данных
HBase
Для обновления значения в HBase используйте метод append и метод checkAndPut. append — это процесс добавления значения атомарным образом в конец текущего значения, а checkAndPut сравнивает текущее значение с ожидаемым значением и обновляет текущее значение только в том случае, если они совпадают.
// append
HTable table = new HTable(config, "FamilyTable");
Append append = new Append(Bytes.toBytes(RowKey));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes(2));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Harris"));
Result result = table.append(append)
// checkAndPut
byte[] row = Bytes.toBytes(RowKey);
byte[] colfam = Bytes.toBytes("ColFam");
byte[] col = Bytes.toBytes("lastName");
Put put = new Put(row);
put.add(colfam, col, Bytes.toBytes("Patrick"));
boolearn result = table.checkAndPut(row, colfam, col, Bytes.toBytes("Witherspoon"), put);
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Brown’)
ON DUPLICATE KEY UPDATE id = "1", lastName = "Whiterspoon";
Azure Cosmos DB
В Azure Cosmos DB обновления обрабатываются как операции upsert. То есть, если документ не существует, он будет вставлен.
// Replace existing document with new modified document (contingent on modification).
Family family = new Family();
family.setLastName("Brown");
family.setId("1");
CosmosItemResponse<Family> famResp = container.upsertItem(family, new CosmosItemRequestOptions());
Удаление записи или документа
HBase
В Hbase нет способа прямого удаления строки по значению. Возможно, вы реализовала процесс удаления в сочетании с ValueFilter и т. п. В этом примере запись, которую нужно удалить, определяется по RowKey.
HTable table = new HTable(config, "FamilyTable");
Delete delete = new Delete(Bytes.toBytes(RowKey));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("id"));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
table.dalate(delete)
Phoenix
DELETE FROM TableName WHERE id = "xxx";
Azure Cosmos DB
Метод удаления с идентификатора документа показан ниже.
container.deleteItem(documentId, new PartitionKey(documentLastName), new CosmosItemRequestOptions());
Запросы к записям/документам
HBase При использовании HBase можно извлечь несколько строк с помощью сканирования. Вы можете использовать фильтр, чтобы задать подробные условия сканирования. Встроенные типов фильтров HBase см. в статье Фильтры запросов клиента.
HTable table = new HTable(config, "FamilyTable");
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("ColFam"),
Bytes.toBytes("lastName"), CompareOp.EQUAL, New BinaryComparator(Bytes.toBytes("Witherspoon")));
filter.setFilterIfMissing(true);
filter.setLatestVersionOnly(true);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
Phoenix
SELECT * FROM FamilyTable WHERE lastName = "Witherspoon"
Azure Cosmos DB
Операция фильтрации
String sql = "SELECT * FROM c WHERE c.lastName = 'Witherspoon'";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
Удаление таблицы или коллекции
HBase
HBaseAdmin admin = new HBaseAdmin(config);
admin.deleteTable("FamilyTable")
Phoenix
DROP TABLE IF EXISTS FamilyTable;
Azure Cosmos DB
CosmosContainerResponse containerResp = database.getContainer("FamilyContainer").delete(new CosmosContainerRequestOptions());
Другие вопросы
Кластеры HBase можно использовать с рабочими нагрузками HBase и MapReduce, Hive, Spark и другими. Если у вас есть другие рабочие нагрузки для текущей базы данных HBase, их также необходимо перенести. Подробные сведения можно найти в соответствующем руководстве по миграции.
- MapReduce
- HBase
- Spark
Программирование на стороне сервера
В HBase есть несколько функций программирования на стороне сервера. Если вы используете эти функции, вам также потребуется перенести их обработку.
HBase
-
В HBase по умолчанию доступны различные фильтры, но вы также можете реализовать собственные фильтры. Настраиваемые фильтры можно реализовать, если фильтры, доступные по умолчанию в HBase, не соответствуют вашим требованиям.
-
Сопроцессор — это платформа, позволяющая запускать собственный код на Region Server. С помощью сопроцессора можно выполнять обработку, которая выполнялась на стороне клиента, на стороне сервера, и в зависимости от характера обработки ее можно сделать более эффективной. Существует два типа сопроцессоров: наблюдатель и конечная точка.
каталога
- Наблюдатель перехватывает определенные операции и события. Это функция для добавления произвольной обработки. Эта функция аналогична триггерам реляционной СУБД.
Конечная точка
- Конечная точка — это функция для расширения RPC HBase. Это функция, аналогичная хранимой процедуре RDBMS.
Azure Cosmos DB
-
- Хранимые процедуры Azure Cosmos DB записываются в JavaScript и могут выполнять такие операции, как создание, обновление, чтение, запрос и удаление элементов в контейнерах Azure Cosmos DB.
-
- Триггеры можно указать для операций с базой данных. Существует два способа: предварительный триггер предварительного выполнения, который запускается до изменения элемента базы данных, и триггер последующего выполнения, который запускается после изменения элемента базы данных.
Определяемая пользователем функция
- Azure Cosmos DB позволяет задавать определяемые пользователем функции (UDF). Определяемые пользователем функции можно также написать на языке JavaScript.
Хранимые процедуры и триггеры расходуют ЕЗ с учетом сложности выполняемых операций. При разработке обработки на стороне сервера рассмотрите необходимое использование, чтобы лучше понять, сколько единиц запроса использует каждая операция. Подробные сведения см. в статьях Единицы запросов в базе данных Azure Cosmos DB и Оптимизация затрат на обработку запросов в Azure Cosmos DB.
Примеры программирования на стороне сервера
| HBase | Azure Cosmos DB | Description |
|---|---|---|
| Пользовательские фильтры | Предложение WHERE | Если обработку, реализованная настраиваемом фильтром, нельзя достичь с помощью предложения WHERE в Azure Cosmos DB, используйте в сочетании с определяемой пользователем функцией. |
| Сопроцессор (наблюдатель) | Триггер | Наблюдатель — это триггер, который выполняется до и после определенного события. Так же, как наблюдатель поддерживает предварительные и пост-вызовы, триггер Azure Cosmos DB также поддерживает предварительные и пост-триггеры. |
| Сопроцессор (конечная точка) | Хранимая процедура | Конечная точка — это механизм обработки данных на стороне сервера, который выполняется для каждого региона. Она похожа на хранимую процедуру реляционной СУБД. Хранимые процедуры Azure Cosmos DB записываются с помощью JavaScript. Он предоставляет доступ ко всем операциям, которые можно выполнять в Azure Cosmos DB с помощью хранимых процедур. |
Примечание.
В Azure Cosmos DB могут потребоваться различные сопоставления и реализации в зависимости от обработки, реализованной в HBase.
Безопасность
Ответственность за безопасность данных лежит как на клиенте, так и на поставщике базы данных. Для локального решения клиенты должны обеспечить все — от защиты конечной точки до физической безопасности оборудования, что является непростой задачей. При выборе поставщика облачной базы данных PaaS, такого как Azure Cosmos DB, участие клиентов уменьшено. Azure Cosmos DB выполняется на платформе Azure, поэтому его можно улучшить по-другому, чем HBase. Azure Cosmos DB не требует установки дополнительных компонентов для обеспечения безопасности. Рекомендуем перенести реализацию системы безопасности базы данных с помощью следующего контрольного списка:
| Управление безопасностью | HBase | Azure Cosmos DB |
|---|---|---|
| Безопасность сети и параметры брандмауэра | Управляйте трафиком с помощью функций безопасности, таких как сетевые устройства. | Поддержка управления доступом на основе IP-адресов на основе политики во брандмауэре входящих подключений. |
| Аутентификация пользователей и детальные пользовательские элементы управления | Точное управление доступом за счет сочетания протокола LDAP с компонентами безопасности, такими как Apache Ranger. | Первичный ключ учетной записи можно использовать для создания ресурсов пользователей и разрешений для каждой базы данных. Токены ресурсов связаны с разрешениями в базе данных, чтобы определять то, как пользователи могут получать доступ к ресурсам приложения в базе данных (чтение и запись, только чтение или без доступа). Вы также можете использовать идентификатор Microsoft Entra для проверки подлинности запросов данных. Это позволяет авторизовать запросы данных с использованием точной модели управления доступом на основе ролей. |
| Возможность глобальной репликации данных в случае регионального сбоя | Сделайте реплику базы данных в удаленном центре обработки данных с помощью репликации HBase. | Azure Cosmos DB выполняет глобальное распределение без настройки и позволяет реплика te данные в центры обработки данных по всему миру в Azure с помощью кнопки. С точки зрения безопасности глобальная репликация обеспечивает защиту данных от локальных сбоев. |
| Возможность переключения из одного центра обработки данных в другой при отработке отказа | Отработку отказа необходимо выполнить самостоятельно. | Если вы реплицируете данные в несколько центров обработки данных и центр обработки данных в регионе переходит в автономный режим, Azure Cosmos DB автоматически переключит операцию. |
| Репликация локальных данных в рамках центра обработки данных | Механизм HDFS позволяет использовать несколько реплик на узлах в одной файловой системе. | Azure Cosmos DB автоматически реплика tes данные для обеспечения высокой доступности даже в одном центре обработки данных. Вы можете выбрать уровень согласованности самостоятельно. |
| Автоматическая архивация данных | Функция автоматического резервного копирования отсутствует. Вам нужно реализовать резервное копирование данных самостоятельно. | Azure Cosmos DB регулярно выполняет резервное копирование и хранится в геоизбыточное хранилище. |
| Защита и изолирование конфиденциальных данных | Например, если вы используете Apache Ranger, можно использовать политику Ranger для применения политики к таблице. | Вы можете отделить личные и другие конфиденциальные данные в определенные контейнеры и выполнять операции чтения и записи, а также ограничить доступ только для чтения для определенных пользователей. |
| Мониторинг атак | Его нужно реализовать с помощью продуктов сторонних разработчиков. | С помощью ведения журнала аудита и журналов действий можно отслеживать учетную запись на наличие аномальной активности. |
| Реагирование на атаки | Его нужно реализовать с помощью продуктов сторонних разработчиков. | Когда вы обращаетесь в службу поддержки Azure и сообщаете о потенциальной атаке, начинается процесс реагирования на инцидент, состоящий из пяти шагов. |
| Возможность защитить данные в пределах геозоны в соответствии с ограничениями, установленными для управления данными | Необходимо проверка ограничения для каждой страны или региона и реализовать его самостоятельно. | Гарантирует управление данными для независимых регионов (Германия, Китай, США и т. д.). |
| Физическая защита серверов в защищенных центрах обработки данных | Зависит от центра обработки данных, в котором находится система. | Список последних сертификатов см. на глобальном сайте соответствия требованиям Azure. |
| Сертификации | Зависит от распределения Hadoop. | См. документацию по обеспечению соответствия требованиям Azure. |
Дополнительные сведения о безопасности можно найти в статье Безопасность в Azure Cosmos DB. Обзор.
Наблюдение
HBase обычно отслеживает кластер с помощью веб-интерфейса метрик кластера или c помощью Ambari, Cloudera Manager или других средств мониторинга. Azure Cosmos DB позволяет использовать механизм мониторинга, встроенный в платформу Azure. Дополнительные сведения о мониторинге Azure Cosmos DB см. в статье Monitor Azure Cosmos DB.
Если в вашей среде используется мониторинг системы HBase для отправки оповещений, например по электронной почте, вы можете заменить его оповещениями Azure Monitor. Вы можете получать оповещения на основе метрик или событий журнала действий для учетной записи Azure Cosmos DB.
Дополнительные сведения об оповещениях в Azure Monitor можно найти в статье Создание оповещений для Azure Cosmos DB с помощью Azure Monitor.
Кроме того, см . метрики и типы журналов Azure Cosmos DB, которые можно собирать с помощью Azure Monitor.
Резервное копирование и аварийное восстановление
Резервное копирование
Существует несколько способов получить резервную копию HBase. Например, моментальный снимок, экспорт, CopyTable, автономная резервная копия данных HDFS и другие настраиваемые резервные копии.
Azure Cosmos DB автоматически выполняет резервное копирование данных через периодические интервалы, что не влияет на производительность или доступность операций базы данных. Резервные копии хранятся в хранилище Azure. При необходимости их можно использовать для восстановления данных. Существует два типа резервных копий Azure Cosmos DB:
Аварийное восстановление
HBase — это устойчивая к сбоям распределенная система, но в случае сбоя уровня центра обработки данных необходимо выполнить аварийное восстановление с помощью моментального снимка, репликации и т. д., если отработка отказа при сбоя на уровне центра обработки данных требуется в расположении резервной копии. Репликацию HBase можно настроить с помощью трех моделей репликации: "ведущий — ведомый", "ведущий — ведущий" и "циклическая". Если исходный HBase реализует аварийное восстановление, необходимо понять, как настроить аварийное восстановление в Azure Cosmos DB и удовлетворить требования к системе.
Azure Cosmos DB — это глобально распределенная база данных со встроенными возможностями аварийного восстановления. Данные DB можно реплицировать в любой регион Azure. Azure Cosmos DB обеспечивает высокий уровень доступность к базе данных в маловероятном случае сбоя сразу в нескольких регионах.
Учетная запись Cosmos Azure DB, использующая только один регион, может быть недоступна в случае сбоя региона. Мы рекомендуем настроить, по меньшей мере, два региона, чтобы обеспечить высокий уровень доступности в течение всего уровня. Вы также можете обеспечить высокий уровень доступности операций записи и чтения, настроив учетную запись Azure Cosmos DB так, чтобы она охватывала, по меньшей мере, два региона с несколькими областями записи, чтобы обеспечить высокую доступность операций записи и чтения. Для учетных записей с несколькими регионами, которые состоят из нескольких областей записи, отработка отказа между регионами выявляется и обрабатывается клиентом Azure Cosmos DB. Такие случаи являются временными и не требуют каких-либо изменений в приложении. Таким образом можно добиться конфигурации доступности, которая включает аварийное восстановление для Azure Cosmos DB. Как упоминание ранее, HBase реплика tion можно настроить с тремя моделями, но Azure Cosmos DB можно настроить с доступностью на основе SLA, настроив однозаписные и многозаписные регионы.
Дополнительные сведения о высоком уровне доступности см. в статье Как Azure Cosmos DB обеспечивает высокую доступность.
Часто задаваемые вопросы
Почему миграция на API для NoSQL вместо других API в Azure Cosmos DB?
API для NoSQL предоставляет лучший комплексный интерфейс с точки зрения интерфейса, клиентской библиотеки пакета SDK службы. Новые функции, развернутые в Azure Cosmos DB, будут впервые доступны в вашей учетной записи API для NoSQL. Кроме того, API для NoSQL поддерживает аналитику и обеспечивает разделение производительности между рабочими и аналитическими рабочими нагрузками. Если вы хотите использовать обновленные технологии для создания приложений, API для NoSQL рекомендуется.
Можно ли назначить RowKey HBase ключу секции Azure Cosmos DB?
Возможно, он не будет оптимизирован. В HBase данные сортируются по указанному значению RowKey, который хранится в регионе и делится на фиксированные размеры. Это поведение отличается от секционирования в Azure Cosmos DB. Поэтому ключи необходимо изменить, чтобы лучше распределить данные в соответствии с характеристиками рабочей нагрузки. Дополнительные сведения см. в разделе Распределение данных.
Данные отсортированы по RowKey в HBase, но секционирование по ключу в Azure Cosmos DB. Как Azure Cosmos DB может достичь сортировки и коллокации?
В Azure Cosmos DB можно добавить составной индекс для сортировки данных по возрастанию или убыванию, чтобы повысить производительность запросов на равенство и диапазон. См. разделы Распределение данных и Составной индекс в документации по продукту.
Аналитическая обработка выполняется на основе данных HBase с помощью Hive или Spark. Как модернизировать их в Azure Cosmos DB?
Вы можете использовать аналитическое хранилище Azure Cosmos DB для автоматической синхронизации рабочих данных с другим хранилищем столбцов. Формат хранилища столбцов подходит для больших аналитических запросов, которые выполняются оптимизировано, что уменьшает задержки для таких запросов. Azure Synapse Link позволяет создать решение HTAP без извлечения, преобразования и загрузки, напрямую связывая хранилище аналитических данных Azure Cosmos DB с Azure Synapse Analytics. Это позволяет выполнять масштабный анализ операционных данных практически в реальном времени. Synapse Analytics поддерживает Apache Spark и бессерверные пулы SQL в хранилище аналитики Azure Cosmos DB. Вы можете воспользоваться этой функцией для переноса аналитической обработки данных. Дополнительные сведения см. в статье о Хранилище аналитических данных.
Как пользователи могут использовать запрос метки времени в HBase в Azure Cosmos DB?
Azure Cosmos DB не имеет точно той же функции управления версиями меток времени, что и HBase. Но Azure Cosmos DB предоставляет возможность доступа к каналу изменений и его можно использовать для управления версиями.
Храните каждую версию или изменения как отдельный элемент.
Прочитайте канал изменений, чтобы объединять или консолидировать изменения и запускать соответствующие действия с помощью фильтрации по полю _ts. Кроме того, можно задать срок жизни для старых версий данных.
Следующие шаги
Чтобы выполнить тестирование производительности, см. статью Тестирование производительности и масштабирования с помощью Azure Cosmos DB.
Чтобы оптимизировать код, см. статью Советы по повышению производительности для Azure Cosmos DB.
Ознакомьтесь с Java Async V3 SDK и справочником по пакету SDK в репозитории GitHub.