Потоки данных для сопоставления в Фабрике данных Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Сведения о сопоставлении потоков данных
Потоки данных для сопоставления — это визуально спроектированные преобразования данных в Фабрике данных Azure. Потоки данных позволяют инженерам по обработке данных разрабатывать логику преобразования данных без написания кода. Результирующие потоки данных выполняются как действия в конвейерах Фабрики данных Azure, использующих кластеры Apache Spark с горизонтальным масштабированием. Действия потока данных можно применять через уже существующие средства планирования, управления, потока и мониторинга в Фабрике данных Azure.
Потоки данных для сопоставления обеспечивают полностью визуальный интерфейс без необходимости написания кода. Потоки данных выполняются в кластерах выполнения, управляемых ADF, для обработки данных с горизонтальным масштабированием. Фабрика данных Azure обрабатывает любое преобразование кода, оптимизацию пути и выполнение заданий потока данных.
Начало работы
Потоки данных создаются из области ресурсов фабрики, такой как конвейеры и наборы данных. Чтобы создать поток данных, щелкните знак "плюс" рядом с параметром Ресурсы фабрики, а затем выберите Поток данных.
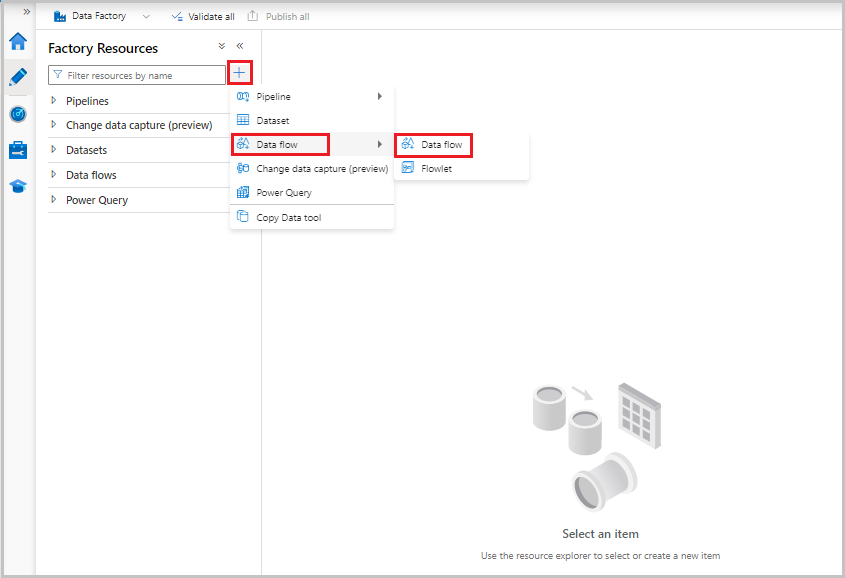 Это действие делает вас на холсте потока данных, где можно создать логику преобразования. Выберите Добавить источник, чтобы начать настройку преобразования источника. Дополнительные сведения см. в статье Преобразование источника.
Это действие делает вас на холсте потока данных, где можно создать логику преобразования. Выберите Добавить источник, чтобы начать настройку преобразования источника. Дополнительные сведения см. в статье Преобразование источника.
Создание потоков данных
У потока данных для сопоставления есть уникальный холст, предназначенный для упрощения создания логики преобразования. Холст потока данных разделен на три части: верхняя панель, диаграмма и панель конфигурации.
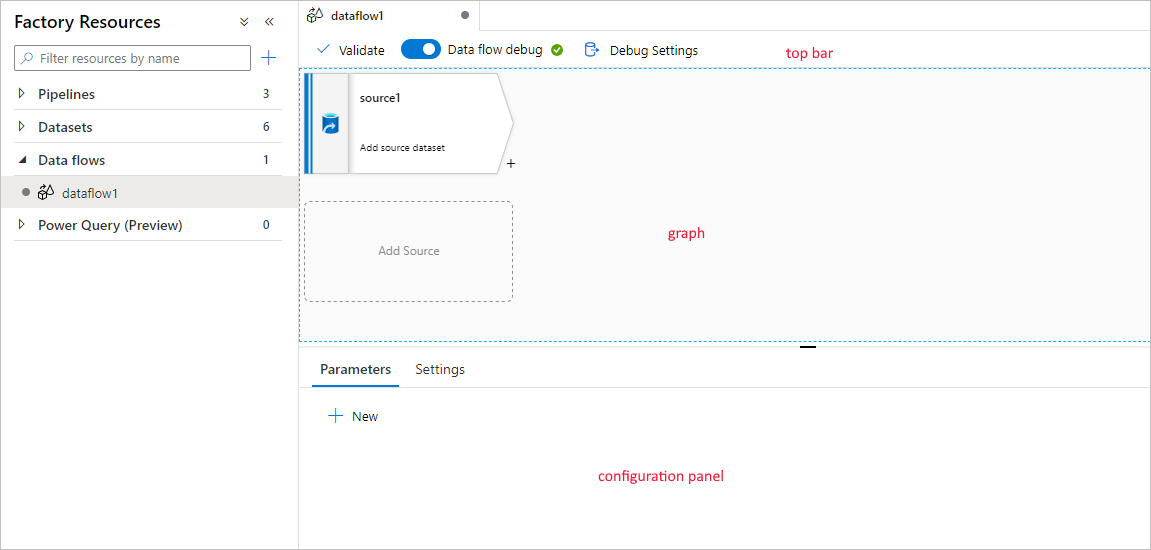
График
Диаграмма отображает поток преобразования. Здесь показан журнал преобразований источника данных по мере их передачи в один или несколько приемников. Чтобы добавить новый источник, выберите Добавить источник. Чтобы добавить новое преобразование, щелкните знак "плюс" в правом нижнем углу существующего преобразования. Узнайте больше о том, как управлять диаграммой потока данных.
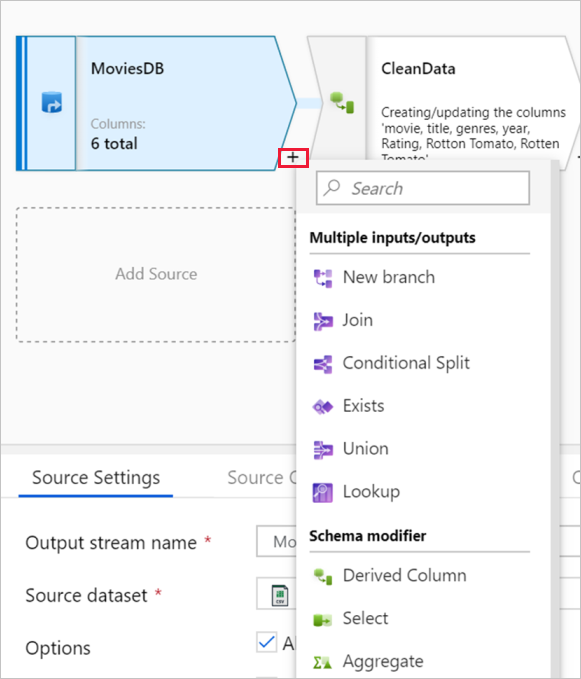
Панель конфигурации
На панели конфигурации отображаются параметры, относящиеся к текущему выбранному преобразованию. Если преобразование не выбрано, то отображается поток данных. В общей конфигурации потока данных можно добавить параметры с помощью вкладки Параметры. Дополнительные сведения см. в разделе Параметры потока данных для сопоставления.
Каждое преобразование содержит по крайней мере четыре вкладки конфигурации.
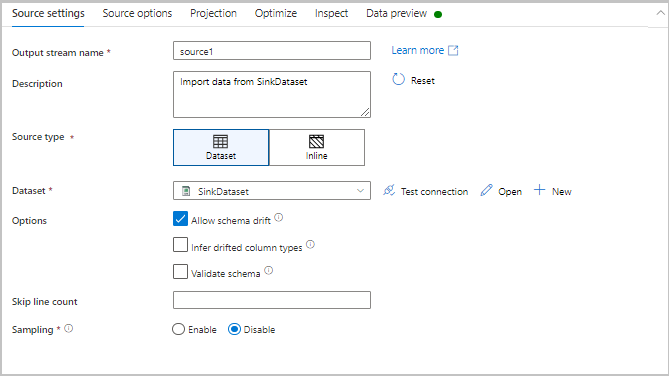
Параметры преобразования
Первая вкладка в области конфигурации каждого преобразования содержит параметры, относящиеся к этому преобразованию. Дополнительные сведения см. на странице документации по преобразованию.
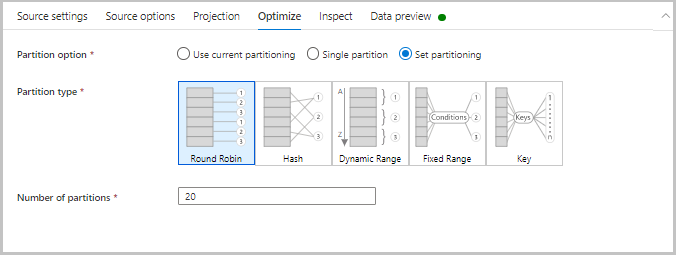
Оптимизация
Вкладка Оптимизация содержит параметры для настройки схем секционирования. Чтобы узнать больше о том, как оптимизировать потоки данных, см. руководство по повышению производительности потока данных для сопоставления.
Проверка
Вкладка Проверка содержит метаданные потока данных, который вы преобразуете. Можно просмотреть количество столбцов, изменить столбцы, добавить столбцы, типы данных, порядок столбцов и ссылки на столбцы. Проверка — это представление метаданных только для чтения. Для просмотра метаданных в области Проверка не нужно включать режим отладки.
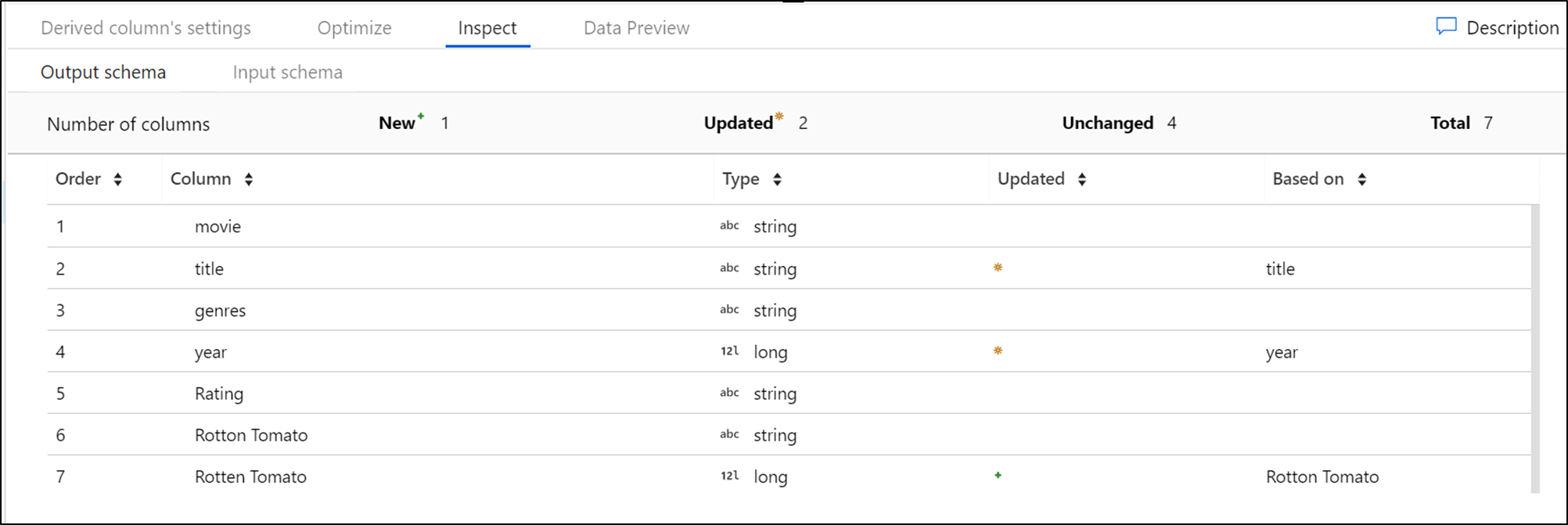
Во время изменения формы ваших данных путем преобразований вы увидите, как метаданные изменяют поток, с помощью области Проверка. Метаданные не будут отображаться в области Проверка, если в преобразовании источника не определена схема. Отсутствие метаданных часто встречается в сценариях смещения схемы.
Предварительный просмотр данных
Если включен режим отладки, на вкладке Предварительный просмотр данных отображается интерактивный моментальный снимок данных при каждом преобразовании. Дополнительные сведения см. в статье Предварительный просмотр данных в режиме отладки.
Верхняя панель
Верхняя панель содержит действия, влияющие на весь поток данных, например, на его сохранение и проверку. Можно также просмотреть базовый код JSON и скрипт потока данных для логики преобразования. Дополнительные сведения см. в статье о сценарии потока данных.
Доступные преобразования
Список доступных преобразований приведен в общих сведениях о преобразовании потока данных для сопоставления.
Типы данных потока данных
- array
- binary
- boolean
- complex
- decimal (включает точность)
- Дата
- с плавающей запятой
- integer
- длинный
- map
- short
- строка
- TIMESTAMP
Действие потока данных
Потоки данных для сопоставления выполняются в конвейерах Фабрики данных Azure с помощью действия потока данных. Все, что пользователь должен сделать, — это указать, какую среду выполнения интеграции использовать, и передать значения параметров. Дополнительные сведения см. в статье о среде выполнения интеграции Azure.
Режим отладки
Режим отладки позволяет интерактивно просматривать результаты каждого шага преобразования во время сборки и отладки потоков данных. Сеанс отладки можно использовать как при построении логики потока данных, так и при выполнении отладки конвейера с действиями потока данных. Чтобы узнать больше, см. документацию по режиму отладки.
Мониторинг потоков данных
Поток данных для сопоставления интегрируется с имеющимися возможностями мониторинга Фабрики данных Azure. Сведения о том, как понять выходные данные мониторинга потока данных, см. в разделе Мониторинг потоков данных для сопоставления.
Группа Фабрики данных Azure создала рекомендации по настройке производительности, которые помогут вам оптимизировать время выполнения потоков данных после создания бизнес-логики.
Связанный контент
- Узнайте, как создать преобразование источника.
- Узнайте, как создавать потоки данных в режиме отладки.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по