Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
Используйте активность Data Flow для преобразования и перемещения данных с помощью потоков данных с отображением. Если вы не знакомы с потоками данных, ознакомьтесь с обзором Mapping Data Flow
Создайте действие Data Flow с использованием пользовательского интерфейса
Чтобы использовать действие Data Flow в конвейере, выполните следующие действия:
Найдите Data Flow в области действий конвейера и перетащите активность Data Flow на холст конвейера.
Выберите новое действие Data Flow на холсте, если оно еще не выбрано, и перейдите на вкладку Settings, чтобы изменить его сведения.
Показывает интерфейс пользователя для действия Data Flow.
Ключ контрольной точки используется для установки контрольной точки, если поток данных используется для получения измененных данных. Его можно перезаписать. Действия потока данных используют значение GUID в качестве ключа контрольной точки вместо "имя конвейера + имя действия", чтобы всегда отслеживать состояние фиксации измененных данных клиента, даже при совершении каких-либо действий по переименованию. Все существующие действия потока данных используют старый ключ шаблона для обратной совместимости. Ниже приведен параметр ключа контрольной точки для ресурса потока данных после публикации новой активности потока данных с включенной функцией захвата изменений данных.
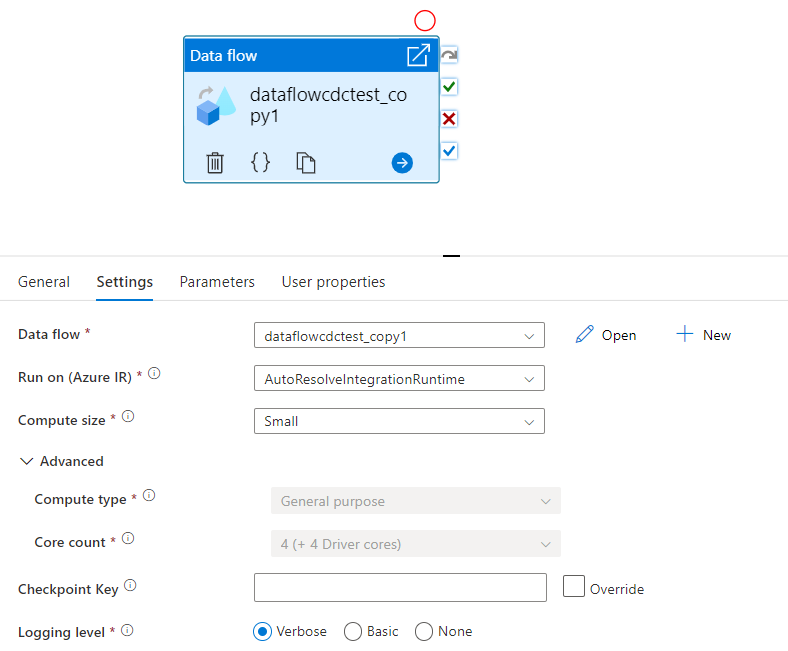
Выберите существующий поток данных или создайте новый с помощью кнопки «Создать». Выберите другие параметры, необходимые для завершения настройки.
Синтаксис
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Свойства типа
| Свойство | Описание | Допустимые значения | Обязательное поле |
|---|---|---|---|
| поток данных | Ссылка на выполняемый поток данных | DataFlowReference | Да |
| integrationRuntime | Вычислительная среда, в которой выполняется поток данных. Если это не указано, используется автоматическая среда выполнения интеграции Azure. | IntegrationRuntimeReference | Нет |
| compute.coreCount | Количество ядер, используемых в кластере Spark. Можно указать только в том случае, если используется автоматически разрешаемая интеграционная среда выполнения Azure | 8, 16, 32, 48, 80, 144, 272 | Нет |
| compute.computeType | Тип вычисления, используемого в кластере Spark. Можно указать только в том случае, если используется автоматически разрешаемая интеграционная среда выполнения Azure | "Общие" | Нет |
| staging.linkedService | Если вы используете Azure Synapse Analytics источник или приемник, укажите учетную запись хранения, используемую для промежуточного хранения PolyBase. Если ваш Azure Storage настроен с конечной точкой службы VNet, необходимо использовать аутентификацию с управляемым удостоверением и включенным параметром "Разрешить доверенные службы Microsoft" на учетной записи хранения. См. раздел Влияние использования конечных точек службы VNet с хранилищем Azure. Также ознакомьтесь с необходимыми конфигурациями соответственно для Azure Blob и Azure Data Lake Storage Gen2. |
LinkedServiceReference | Только если поток данных считывает или записывает данные в Azure Synapse Analytics |
| staging.folderPath | Если вы используете источник или приемник Azure Synapse Analytics, путь к папке в учетной записи хранилища BLOB, используемой для промежуточного хранения PolyBase | Строка | Только если поток данных считывает или записывает данные в Azure Synapse Analytics |
| traceLevel | Установка уровня ведения журнала для исполнения активности потока данных | Прекрасно, грубая, нет | Нет |
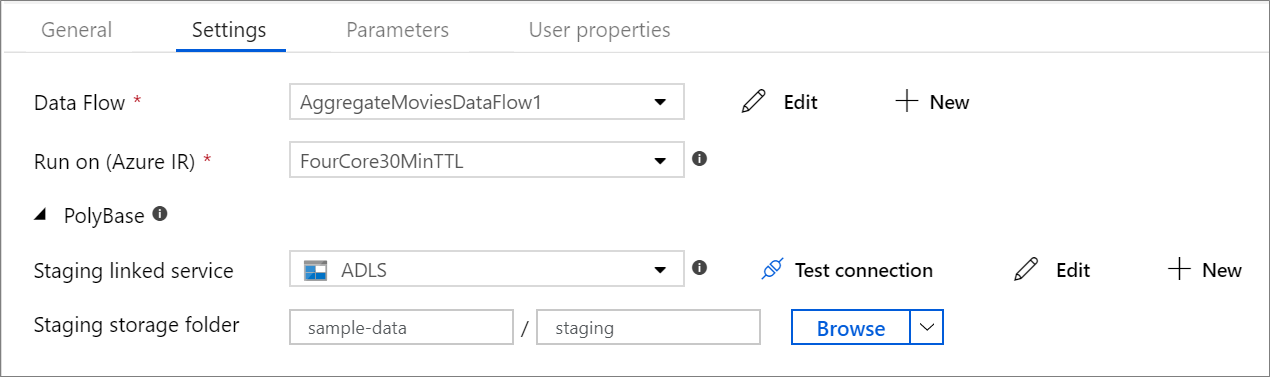
Динамически изменяйте размер вычислительных ресурсов для обработки потока данных во время выполнения
Свойства "Число ядер" и "Тип вычисления" можно динамически установить для регулировки размера входящих данных источника в среде выполнения. Используйте такие действия конвейера, как "Поиск" или "Получение метаданных", чтобы определить размер данных набора данных источника. Затем используйте добавление динамического содержимого в свойствах действия Data Flow. Можно выбрать объем вычислительных ресурсов Small (Малый), Medium (Средний) или Large (Большой). Можно также выбрать Custom (Настраиваемый) и настроить типы вычислений и количество ядер вручную.
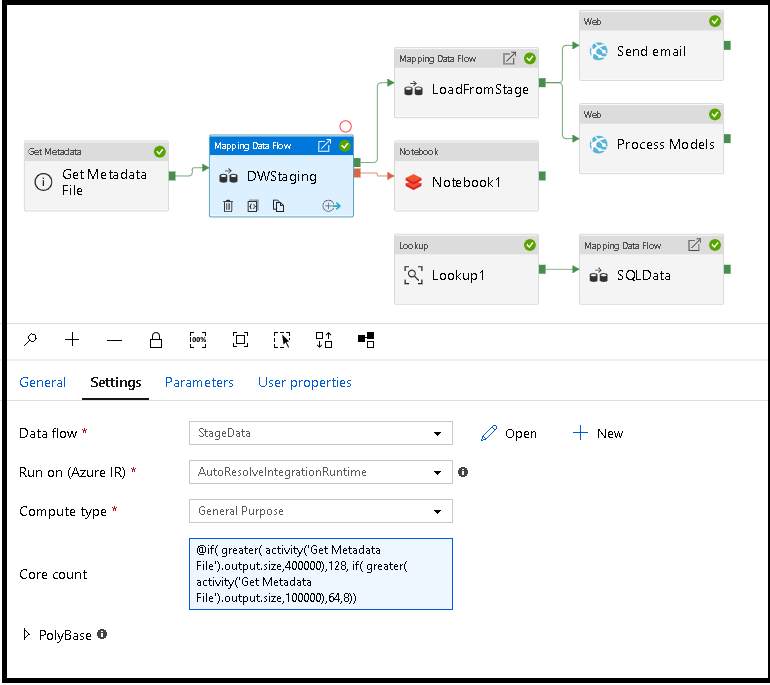
Вот краткое видео учебник, объясняющее этот метод
среда выполнения интеграции потока данных
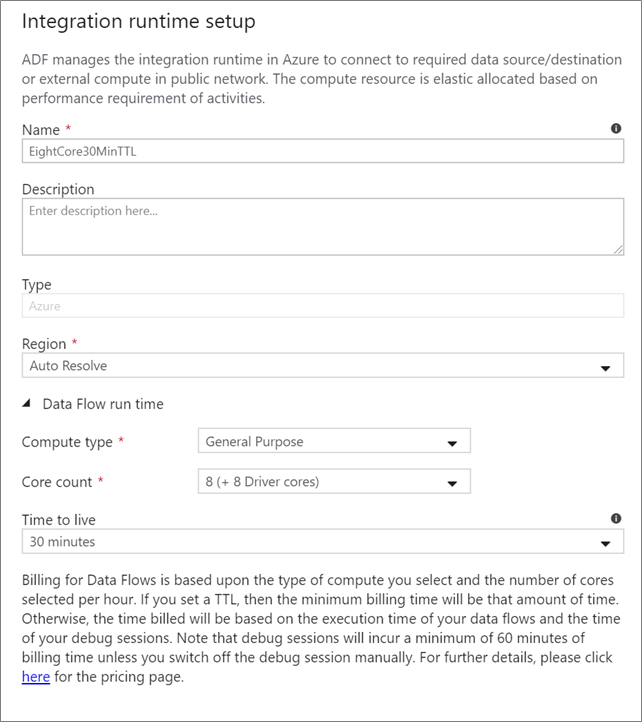
Выберите, какие Integration Runtime использовать для выполнения действия Data Flow. По умолчанию служба использует авторешаемую среду выполнения интеграции Azure с четырьмя рабочими ядрами. Эта IR использует вычислительный тип общего назначения и работает в том же регионе, что и экземпляр службы. Для рабочих конвейеров настоятельно рекомендуется создать собственные среды выполнения интеграции Azure, определяющие определенные регионы, тип вычислений, количество ядер и TTL для выполнения действия потока данных.
Минимальный тип вычислений общего назначения с конфигурацией 8 + 8 (всего 16 виртуальных ядер) и 10-минутным сроком жизни — это рекомендуемый минимум для большинства производственных рабочих нагрузок. Задав небольшой срок жизни (TTL), Azure IR может поддерживать теплый кластер, что позволит избежать задержки в несколько минут на запуск холодного кластера. Дополнительные сведения см. в разделе интеграционная среда выполнения Azure.
Внимание
Выбор Integration Runtime в действии Data Flow применяется только к инициированным выполнениям конвейера. Отладка конвейера с потоками данных выполняется в кластере, указанном в сеансе отладки.
PolyBase
Если вы используете Azure Synapse Analytics в качестве приемника или источника, вам необходимо выбрать промежуточное расположение для пакетной загрузки с помощью PolyBase. Polybase обеспечивает групповую пакетную загрузку вместо построчной загрузки данных. PolyBase значительно сокращает время загрузки в Azure Synapse Analytics.
Ключ контрольной точки
При использовании параметра отслеживания изменений для источников потока данных ADF поддерживает контрольную точку и управляет ею автоматически. Ключ контрольной точки по умолчанию — это хэш имени потока данных и имени конвейера. Если вы используете динамический шаблон для исходных таблиц или папок, вы можете переопределить этот хэш и задать собственное значение ключа контрольной точки здесь.
Уровень ведения журнала
Если вам не нужно, чтобы каждое выполнение конвейера данных записывало все подробные журналы телеметрии, при необходимости можно установить уровень ведения журнала до "Базовый" или "Нет". При выполнении потоков данных в режиме "Подробный" (по умолчанию) вы запрашиваете у службы ведение полного журнала активности на уровне каждого отдельного раздела во время преобразования данных. Это может быть ресурсоемкой операцией, поэтому включать режим подробного ведения журнала следует только при устранении неполадок. Такой подход может повысить общую производительность потоков данных и конвейеров. Режим "Базовый" регистрирует только длительность преобразования, а "Нет" — только сводку по длительности.

Свойства приемника
Функция группировки в потоках данных позволяет задать порядок выполнения приемников, а также группировать приемники вместе с одинаковым номером группы. Чтобы упростить управление группами, можно настроить службу для параллельного запуска приемников в одной группе. Можно также настроить группу приемников для продолжения работы, даже если один из приемников встретит ошибку.
По умолчанию приемники потоков данных выполняются поочередно, последовательно, и поток данных прерывается при возникновении ошибки в приемнике. Кроме того, все приемники по умолчанию входят в одну группу, если только вы не перешли к свойствам потока данных и не установили разные приоритеты для приемников.

Только первая строка
Этот параметр доступен только для потоков данных, в которых включены приемники кэша для вывода в действие. Выходные данные из потока данных, которые вводятся непосредственно в ваш конвейер, ограничены 2 МБ. Установка параметра "Только первая строка" позволяет ограничить объем выводимых данных потока при интеграции результата действия потока данных непосредственно в ваш конвейер.
Параметризация потоков данных
Параметризованные наборы данных
Если в потоке данных используются параметризованные наборы данных, задайте значения параметров на вкладке Параметры.
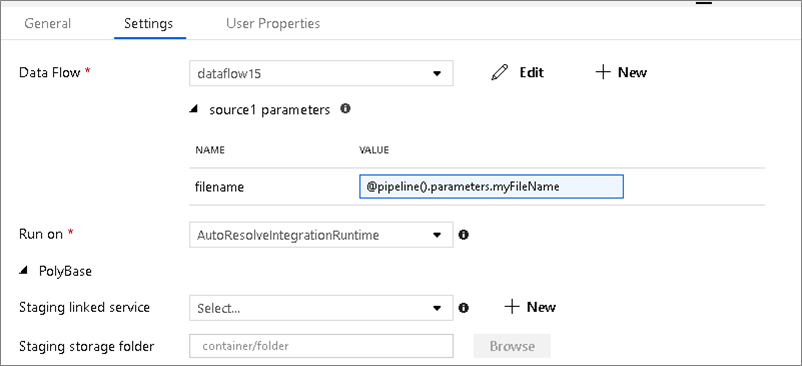
Параметризованные потоки данных
Если поток данных является параметризованным, задайте динамические значения параметров потока данных на вкладке Параметры. Для назначения динамических или литеральных значений параметров можно использовать язык выражений конвейера или язык выражений потока данных. Дополнительные сведения см. раздел Параметры потока данных.
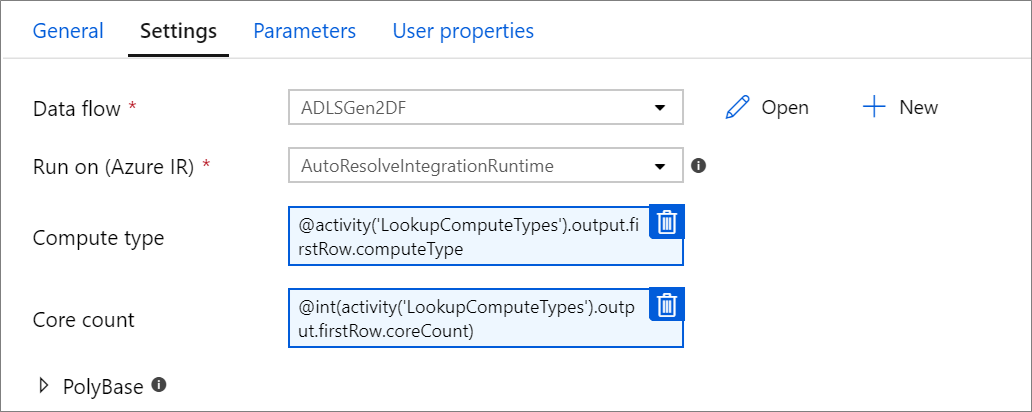
Параметризованные свойства вычислений.
Параметризовать число ядер или тип вычислений можно, если вы используете среду выполнения Azure Integration с автоматическим разрешением и указываете значения compute.coreCount и compute.computeType.
Отладка конвейера действия Data Flow
Чтобы выполнить отладочный запуск канала с активностью Data Flow, необходимо включить режим отладки Data Flow с помощью ползунка Data Flow Debug на верхней панели. Режим отладки позволяет запускать поток данных в активном кластере Spark. Дополнительные сведения см. в статье Режим отладки.

Конвейер отладки выполняется в активном кластере отладки, а не в среде выполнения интеграции, указанной в параметрах действия Data Flow. При запуске режима отладки можно выбрать среду вычислений для отладки.
Мониторинг активности Data Flow
Действие Data Flow имеет специальный интерфейс мониторинга, в котором можно просматривать сведения о секционированиях, времени этапа и происхождения данных. Откройте панель мониторинга с помощью значка очков в разделе Действия. Дополнительные сведения см. в статье Мониторинг потоков данных.
Использование действия Data Flow приводит к последующему действию
Операция потока данных выводит метрики, касающиеся количества строк, записанных в каждый приемник, и строк, считываемых из каждого источника. Эти результаты возвращаются в раздел output "Результат выполнения действия". Возвращаемые метрики представлены в формате JSON, показанном ниже.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Например, чтобы получить количество строк, записанных в приемник с именем "sink1" в активности с именем "dataflowActivity", используйте @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Чтобы получить количество строк, прочитанных из источника с именем "source1", который использовался в этом приемнике, используйте @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Примечание.
Если приемник содержит нулевые строки, он не будет отображаться в метриках. Существование можно проверить с помощью функции contains. Например, contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') проверяет, были ли строки записаны в приемник1.
Связанный контент
Ознакомьтесь с поддерживаемыми действиями потока управления: