Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Используйте следующие стратегии оптимизации производительности для операций преобразования в потоках данных сопоставления в Фабрике данных Azure и конвейерах Azure Synapse Analytics.
Оптимизация операций соединения, проверки существования и поиска
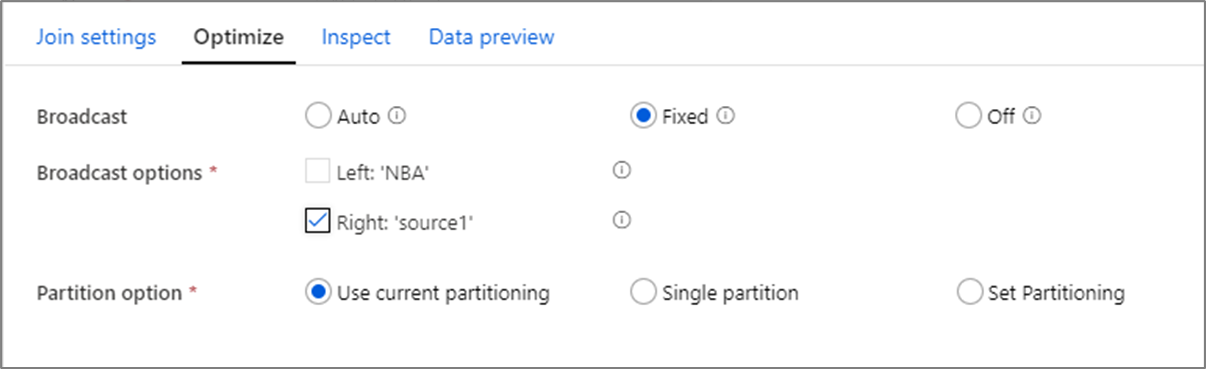
Вещания
Если при преобразованиях соединения, поиска или проверки существования размер одного или обоих потоков данных достаточно мал, чтобы они поместились в память рабочего узла, можно оптимизировать производительность, включив трансляцию. Трансляция означает, что мелкие кадры данных отправляются на все узлы в кластере. Это позволяет обработчику Spark выполнять соединение, не перемешивая данные в большом потоке. По умолчанию подсистема Spark автоматически решает, следует ли транслировать одну сторону соединения. Если вы знакомы с входящими данными и знаете, что один поток меньше другого, можно выбрать фиксированное вещание. Фиксированная трансляция указывает Spark транслировать выбранный поток.
Если размер широковещательных данных слишком велик для узла Spark, может возникнуть ошибка памяти. Чтобы избежать ошибок из-за нехватки памяти, используйте оптимизированные для операций в памяти кластеры. Если во время выполнения потока данных возникают ошибки из-за превышения времени ожидания трансляции, то можно отключить оптимизацию трансляции. Однако это приводит к замедлению выполнения потоков данных.
При работе с источниками данных, которые могут занять больше времени для запроса, например больших запросов к базе данных, рекомендуется отключить трансляцию для соединений. Источник, запросы к которому выполняются долго, может привести к превышению времени ожидания Spark, когда кластер пытается транслировать данные на вычисленные узлы. Еще одна ситуация, в которой стоит отключить трансляцию, — когда в потоке данных есть поток, который агрегирует значения, используемые в последующем преобразовании поиска. Такой сценарий может запутать оптимизатор Spark и привести к превышению времени ожидания.
Перекрестные соединения
Если вы используете литеральные значения в условиях соединения или имеете несколько совпадений на обеих сторонах соединения, Spark запускает соединение в качестве перекрестного соединения. Перекрестное соединение — это полное декартово произведение, после которого соединенные значения отфильтровываются. Это медленнее, чем другие типы соединений. Убедитесь, что в условиях соединения обеих сторон указаны ссылки на столбцы, чтобы избежать снижения производительности.
Сортировка перед соединением
В отличие от таких инструментов, как SQL Server Integration Services, преобразование "Соединение" необязательно является операцией соединения слиянием. Перед преобразованием не требуется выполнять сортировку по ключам соединения. Использование преобразований сортировки в потоках данных сопоставления не рекомендуется.
Производительность преобразования окна
Преобразование окна в потоке данных для сопоставления секционирует данные по значению в столбцах, выбранных для предложения over() в параметрах преобразования. Существует множество популярных агрегатных и аналитических функций, предоставляемых в преобразовании Windows. Однако если ваш вариант использования заключается в создании окна по всему набору данных для ранжирования rank() или номера rowNumber()строк, рекомендуется вместо этого использовать преобразование Ранга и преобразование суррогатного ключа. Эти преобразования выполняют более полные операции набора данных с помощью этих функций.
Повторное секционирование неравномерно распределенных данных
Некоторые преобразования, такие как соединение и агрегирование, перемешивают секции данных в случайном порядке и иногда могут приводить к неравномерному распределению данных. Сложенные данные означают, что данные равномерно не распределяются по секциям. Очень неравномерное распределение данных может привести к замедлению нисходящих операций преобразования и записи в приемники. Можно проверить асимметрию данных в любой точке выполнения потока данных, щелкнув преобразование на экране мониторинга.
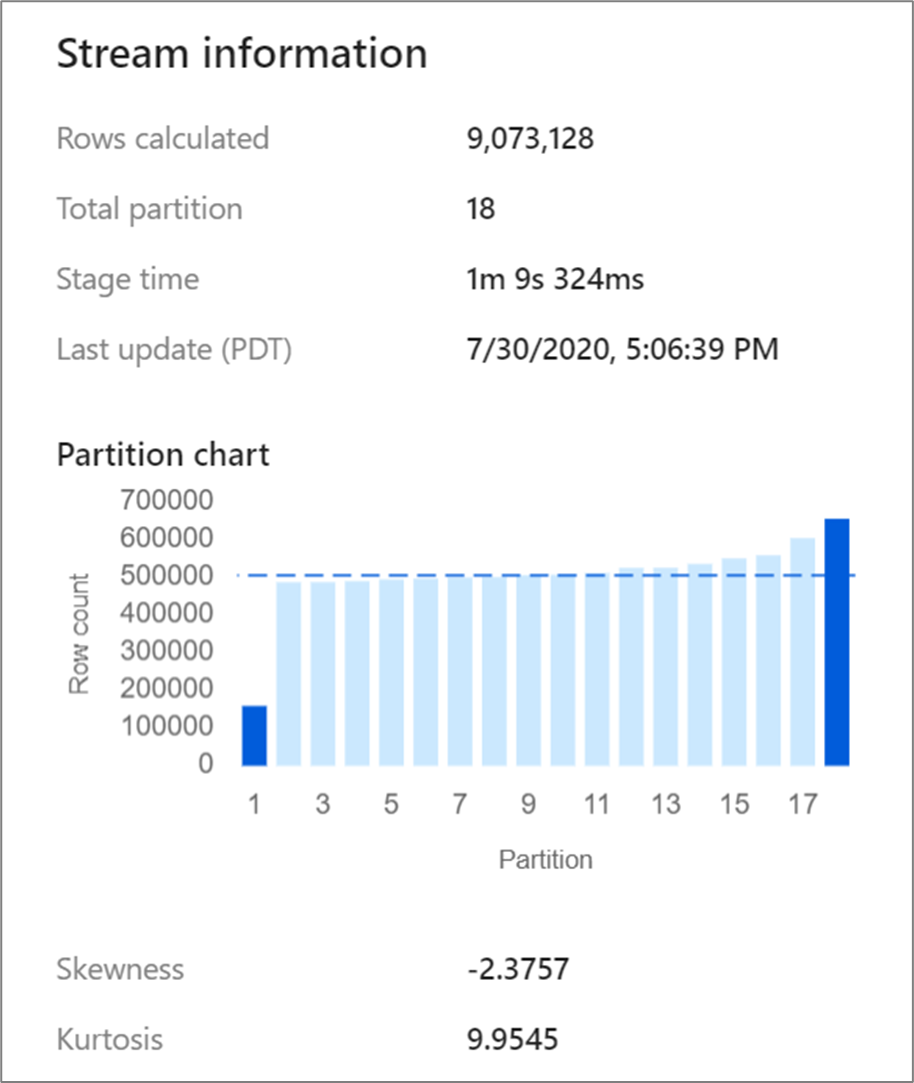
На экране мониторинга показано, как данные распределяются по каждой секции вместе с двумя метриками, отклонением и куртозом. Асимметрия — это мера того, насколько асимметричны данные. Этот показатель может иметь положительное, нулевое, отрицательное или неопределенное значение. Отрицательная асимметрия означает, что левый "хвост" длиннее правого. Эксцесс — это мера того, распределены ли данные с медленно или быстро убывающим "хвостом". Высокие значения куртоза не желательна. Оптимальные диапазоны асимметрии находятся между –3 и 3, а диапазоны эксцесса не должны превышать 10. Простой способ интерпретации этих чисел смотрит на диаграмму секционирования и видит, больше ли 1 линейчатой, чем остальные.
Если данные не секционируются равномерно после преобразования, можно использовать вкладку оптимизации для повторного разделения. Перетасовка данных занимает время и может не повысить производительность потока данных.
Совет
Если вам нужно повторно секционировать данные, но имеются нисходящие преобразования, которые перемешивают данные в случайном порядке, то следует использовать хэш-секционирование по столбцу, используемому в качестве ключа соединения.
Примечание.
Преобразования внутри потока данных (за исключением преобразования приемника) не изменяют секционирование файлов и папок неактивных данных. Секционирование в каждом преобразовании перераспределяет данные в кадрах данных временного бессерверного кластера Spark, которым управляет ADF для каждого выполнения потока данных.
Связанный контент
- Обзор производительности потока данных
- Оптимизация источников
- Оптимизация приемников
- Использование потоков данных в конвейерах
Ознакомьтесь с другими статьями о производительности потоков данных.