Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
В этой статье описывается, как использовать действие копирования в конвейерах Azure Data Factory или Synapse Analytics для копирования данных из Netezza. Статья основывается на Copy Activity, в которой представлены общие сведения об этом процессе.
Tip
Для сценария миграции данных из Netezza в Azure узнайте больше из раздела Миграция данных с локального сервера Netezza на Azure.
Important
Соединитель Netezza версии 1.0 находится на этапе удаления. Рекомендуется обновить соединитель Netezza с версии 1.0 до версии 2.0.
Поддерживаемые возможности
Соединитель Netezza поддерживается для следующих возможностей:
| Поддерживаемые возможности | IR |
|---|---|
| Copy activity (источник/-) | (1) (только для версии 1.0) (2) |
| Поисковая активность | (1) (только для версии 1.0) (2) |
(1) Azure среды выполнения интеграции (2) локальная среда выполнения интеграции
Список хранилищ данных, поддерживаемых действием копирования в качестве источников и приемников, приведен в разделе Поддерживаемые хранилища данных и форматы.
Этот соединитель Netezza поддерживает следующее:
- Параллельное копирование из источника. Дополнительные сведения см. в разделе Параллельное копирование из Netezza.
- Netezza Performance Server версия 11
- Версии Windows в этой статье.
В службе предоставляется встроенный драйвер, который обеспечивает подключение. Не нужно вручную устанавливать драйвер для использования этого соединителя.
Для версии 2.0 необходимо вручную установить драйвер IBM Netezza ODBC . Для версии 1.0 служба предоставляет встроенный драйвер для включения подключения. Не нужно вручную устанавливать драйвер для использования этого соединителя.
Prerequisites
Если хранилище данных находится в локальной сети, виртуальной сети Azure или Amazon Virtual Private Cloud, необходимо настроить самостоятельно размещаемую среду выполнения интеграции для подключения к нему.
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Для версии 1.0
Если хранилище данных является управляемой облачной службой данных, можно использовать Azure Integration Runtime. Если доступ ограничен IP-адресами, утвержденными в правилах брандмауэра, вы можете добавить в список разрешений IP-адреса Azure Integration Runtime.
Вы также можете использовать функцию управляемой среды выполнения интеграции виртуальной сети в Azure Data Factory для доступа к локальной сети без установки и настройки локальной среды выполнения интеграции.
Установка драйвера ODBC Netezza для версии 2.0
Чтобы использовать соединитель Netezza с версией 2.0, установите драйвер IBM Netezza ODBC версии 11.02.02 или более поздней версии на компьютере, на котором запущена локальная среда выполнения интеграции.
Get started
Конвейер, использующий действие копирования, можно создать с помощью пакета SDK .NET, пакета SDK Python, Azure PowerShell, REST API или шаблона Azure Resource Manager. Пошаговые инструкции по созданию канала данных с операцией копирования см. в учебнике по операции Copy.
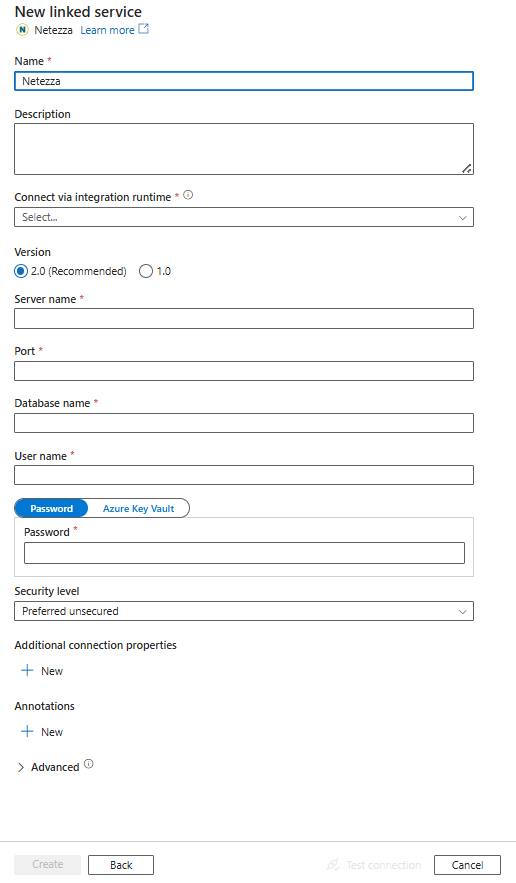
Создание связанной службы для Netezza с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу с Netezza в пользовательском интерфейсе портала Azure.
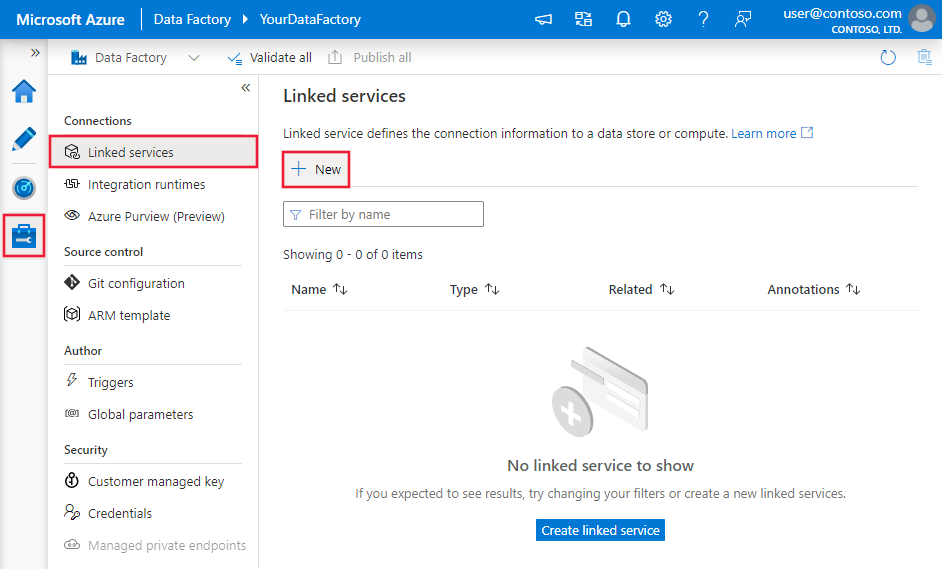
Перейдите на вкладку "Управление" в рабочей области Azure Data Factory или Synapse и выберите "Связанные службы", а затем нажмите кнопку "Создать".
Выполните поиск по Netezza и выберите коннектор Netezza.

Настройте сведения о службе, проверьте подключение и создайте связанную службу.
Сведения о конфигурации соединителя
В разделах ниже приведены сведения о свойствах, которые используются для определения сущностей, относящихся к соединителю Netezza.
Свойства связанной службы
Соединитель Netezza теперь поддерживает версию 2.0. Ознакомьтесь с этим разделом , чтобы обновить версию соединителя Netezza с версии 1.0. Чтобы узнать подробности о свойстве, см. соответствующие разделы.
Версия 2.0
Связанная служба Netezza поддерживает следующие свойства при применении версии 2.0:
| Property | Description | Required |
|---|---|---|
| type | Для свойства type необходимо задать значение Netezza. | Yes |
| version | Версия, которую вы указали. Значение равно 2.0. |
Yes |
| server | Имя узла или IP-адрес сервера Netezza. | Yes |
| port | Номер порта прослушивателя сервера. | Yes |
| database | Имя базы данных Netezza. | Yes |
| uid | Идентификатор пользователя, используемый для подключения к базе данных. | Yes |
| pwd | Пароль, используемый для подключения к базе данных. | Yes |
| SecurityLevel | Уровень безопасности, который драйвер использует для подключения к хранилищу данных. Пример: SecurityLevel=preferredUnSecured. Поддерживаются значения:- Только незащищенный (onlyUnSecured): драйвер не использует SSL. - Предпочтительно незащищенный (preferredUnSecured) (по умолчанию): если сервер предоставляет возможность выбора, драйвер не использует SSL. |
No |
| connectVia | Integration Runtime для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные условия. Вы можете использовать только локальную среду выполнения интеграции. | No |
Example
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"version": "2.0",
"typeProperties": {
"server": "<server>",
"port": "<port>",
"database": "<database>",
"uid": "<username>",
"pwd": {
"type": "SecureString",
"value": "<password>"
},
"securityLevel": "preferredUnSecured"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Версия 1.0
Следующие свойства поддерживаются для связанной службы Netezza при применении версии 1.0:
| Property | Description | Required |
|---|---|---|
| type | Для свойства type необходимо задать значение Netezza. | Yes |
| connectionString | Строка подключения ODBC для подключения к Netezza. Вы также можете поместить пароль в Azure Key Vault и извлечь конфигурацию pwd из connection string. Дополнительные сведения см. в следующих примерах и статье Хранение учетных данных в Azure Key Vault. |
Yes |
| connectVia | Integration Runtime для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные условия. Если не указано, используется Azure Integration Runtime по умолчанию. | No |
Типичное connection string — Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>. В следующей таблице описаны дополнительные свойства, которые можно задать.
| Property | Description | Required |
|---|---|---|
| SecurityLevel | Уровень безопасности, который драйвер использует для подключения к хранилищу данных. Пример: SecurityLevel=preferredUnSecured. Поддерживаются значения:- Только незащищенный (onlyUnSecured): драйвер не использует SSL. - Предпочтительно незащищенный (preferredUnSecured) (по умолчанию): если сервер предоставляет возможность выбора, драйвер не использует SSL. |
No |
Note
Соединитель не поддерживает SSLv3, так как он официально не рекомендуется Netezza.
Example
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: хранение пароля в Azure Key Vault
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;",
"pwd": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Этот раздел содержит список свойств, поддерживаемых набором данных Netezza.
Для получения полного списка разделов и свойств, доступных для определения наборов данных, см. Datasets.
Чтобы скопировать данные из Netezza, установите для свойства type набора данных значение NetezzaTable. Поддерживаются следующие свойства:
| Property | Description | Required |
|---|---|---|
| type | Свойство типа набора данных должно иметь значение: NetezzaTable | Yes |
| schema | Имя схемы. | Нет (если в источнике активности указано свойство "query") |
| table | Имя таблицы. | Нет (если в источнике активности указано свойство "query") |
| tableName | Имя таблицы со схемой. Это свойство поддерживается только для обеспечения обратной совместимости. Для новых рабочих нагрузок используйте schema и table. |
Нет (если в источнике активности указано свойство "query") |
Example
{
"name": "NetezzaDataset",
"properties": {
"type": "NetezzaTable",
"linkedServiceName": {
"referenceName": "<Netezza linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Свойства действия копирования
Этот раздел содержит список свойств, поддерживаемых источником Netezza.
Полный список разделов и свойств, доступных для определения действий, см. в разделе Конвейеры.
Netezza в качестве источника
Tip
Чтобы эффективно загружать данные из Netezza с использованием секционирования данных, изучите дополнительные сведения в разделе Параллельное копирование из Netezza.
Чтобы копировать данные из Netezza, установите для типа source в действии копирования значение NetezzaSource. В разделе source действия копирования поддерживаются следующие свойства:
| Property | Description | Required |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение NetezzaSource. | Yes |
| query | Используйте пользовательский SQL-запрос для чтения данных. Пример: "SELECT * FROM MyTable" |
Нет (если для набора данных задано свойство tableName) |
| partitionOptions | Задает параметры секционирования данных, используемые для загрузки данных из Netezza. Допустимые значения: None (по умолчанию), DataSlice и DynamicRange. Если параметр секционирования включен (любое значение кроме None), степень параллелизма для параллельной загрузки данных из базы данных Netezza управляется параметром parallelCopies в действии копирования. |
No |
| partitionSettings | Позволяет указать группу параметров для секционирования данных. Применяется, если параметр секционирования имеет значение, отличное от None. |
No |
| partitionColumnName | Укажите имя исходного столбца целочисленного типа, который будет использоваться для секционирования по диапазонам при параллельном копировании. Если значение не указано, автоматически определяется первичный ключ таблицы и используется в качестве столбца секционирования. Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionColumnName в предложении WHERE. Пример см. в разделе Параллельное копирование из Netezza. |
No |
| partitionUpperBound | Максимальное значение столбца секционирования для копирования данных наружу. Применяется, если параметр секционирования имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionUpbound в предложении WHERE. Пример можно найти в разделе Параллельное копирование из Netezza. |
No |
| partitionLowerBound | Минимальное значение столбца секционирования для извлечения данных. Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionLowbound в предложении WHERE. Пример можно найти в разделе Параллельное копирование из Netezza. |
No |
Example:
"activities":[
{
"name": "CopyFromNetezza",
"type": "Copy",
"inputs": [
{
"referenceName": "<Netezza input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Параллельное копирование данных из Netezza
Соединитель Data Factory для Netezza предоставляет функцию встроенного секционирования данных для параллельного копирования данных из Netezza. Параметры секционирования данных можно найти в исходной таблице для действия копирования.

Если включено копирование с секционированием, служба выполняет параллельные запросы к источнику Netezza для загрузки данных по секциям. Степень параллелизма определяется с помощью параметра parallelCopies для действия копирования. Например, если parallelCopies имеет значение 4, служба одновременно создаст и выполнит четыре запроса с учетом указанного способа и параметров секционирования, где каждый запрос извлекает часть данных из базы данных Netezza.
Рекомендуется включить параллельное копирование с секционированием данных, особенно при загрузке большого объема данных из базы данных Netezza. Ниже приведены рекомендуемые конфигурации для разных сценариев. Если данные копируются в файловое хранилище данных, то рекомендуется сохранять данные в папку несколькими файлами (указывая только имя папки), так как производительность в таком случае будет выше, чем при записи в один файл.
| Scenario | Рекомендуемые параметры |
|---|---|
| Полная загрузка из большой таблицы. |
Опция секционирования: срез данных. Во время выполнения служба автоматически секционирует данные по встроенным срезам данных Netezza и копирует данные отдельно для каждой секции. |
| Для загрузки больших объемов данных используйте пользовательский запрос. |
Опция секционирования: срез данных. Запрос: SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>.Во время выполнения служба заменяет ?AdfPartitionCount (на количество параллельных операций, установленное для действия копирования) и ?AdfDataSliceCondition логикой секционирования срезов данных, а затем отправляет в Netezza. |
| Для загрузки большого объема данных используйте пользовательский запрос с целочисленным столбцом, значения которого распределены равномерно для поддержки секционирования по диапазонам. |
Варианты разделов: раздел динамического диапазона. Запрос: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Столбец секционирования: укажите столбец, используемый для секционирования данных. Секционирование можно выполнять по столбцу с целочисленным типом данных. Верхняя граница секции и нижняя граница секции: Укажите, следует ли фильтровать данные в столбце секции, чтобы получать данные только в диапазоне между нижней и верхней границей. Во время выполнения служба заменяет ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound и ?AdfRangePartitionLowbound именем столбца и фактическими диапазонами значений для каждого раздела, а затем отправляет в Netezza. Например, если указан столбец секционирования ID с нижней границей 1 и верхней границей 80 при этом для параллельного копирования указано значение 4, служба будет извлекать данные по 4 секциям. Для них будут применены следующие диапазоны значений идентификаторов: [1, 20], [21, 40], [41, 60] и [61, 80]. |
Пример: запрос с секционированием по срезу данных
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>",
"partitionOption": "DataSlice"
}
Пример: запрос с секционированием по динамическому диапазону
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Сопоставление типов данных для Netezza
При копировании данных из Netezza следующие сопоставления применяются из типов данных Netezza к внутренним типам данных, используемым службой. Чтобы узнать, как действие копирования сопоставляет исходную схему и типы данных с приемником, см. раздел Сопоставление схем и типов данных.
| Тип данных Netezza | Тип данных промежуточной службы (для версии 2.0) | Тип данных промежуточной службы (для версии 1.0) |
|---|---|---|
| BOOLEAN | Boolean | Boolean |
| CHAR | String | String |
| VARCHAR | String | String |
| NCHAR | String | String |
| NVARCHAR | String | String |
| DATE | Date | DateTime |
| TIMESTAMP | DateTime | DateTime |
| TIME | Time | TimeSpan |
| INTERVAL | Не поддерживается | TimeSpan |
| ВРЕМЯ С ЧАСОВЫМ ПОЯСОМ | String | String |
| NUMERIC(p,s) | Decimal | Decimal |
| REAL | Single | Single |
| ДВОЙНАЯ ТОЧНОСТЬ | Double | Double |
| INTEGER | Int32 | Int32 |
| BYTEINT | Int16 | SByte |
| SMALLINT | Int16 | Int16 |
| BIGINT | Int64 | Int64 |
Свойства операции поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Жизненный цикл и обновление соединителя Netezza
В следующей таблице показаны этап выпуска и журналы изменений для различных версий соединителя Netezza:
| Version | Этап выпуска | Журнал изменений |
|---|---|---|
| Версия 1.0 | Removed | Неприменимо. |
| Версия 2.0 | GA версия доступна | • Поддерживает только локальную среду выполнения интеграции. • BYTEINT считывается как тип данных Int16. • ДАТА считывается как тип данных Date. • ВРЕМЯ считывается как тип данных времени. • ИНТЕРВАЛ не поддерживается. |
Обновление соединителя Netezza с версии 1.0 до версии 2.0
- На странице "Изменить связанную службу" выберите версию 2.0. Дополнительные сведения см. в свойствах связанной службы версии 2.0.
- Сопоставление типов данных для связанной службы Netezza версии 2.0 отличается от сопоставления типов данных для версии 1.0. Сведения о последнем сопоставлении типов данных см. в разделе "Сопоставление типов данных" для Netezza.
- Поддерживает только локальную среду выполнения интеграции. Azure среда выполнения интеграции не поддерживается версией 2.0.
Связанный контент
Список хранилищ данных, поддерживаемых действием копирования в качестве источников и приемников, приведен в разделе Поддерживаемые хранилища данных и форматы.