Наборы данных в Фабрике данных Azure и Azure Synapse Analytics
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, какие бывают наборы данных, каким образом они определяются в формате JSON, а также как они используются в конвейерах Фабрики данных Azure и Azure Synapse.
Чтобы получить общее представление о Фабрике данных, ознакомьтесь со статьей Знакомство с Фабрикой данных Azure. Дополнительную информацию об Azure Synapse см. в разделе Что такое Azure Synapse
Обзор
Рабочая область Фабрики данных Azure или Azure Synapse может содержать один или несколько конвейеров. Конвейер — это логическая группа действий, которые вместе выполняют задачу. Действия в конвейере определяют действия, выполняемые с данными. Теперь набор данных — это именованное представление данных, которое указывает данные, необходимые для использования в действиях, разделяя их на входные и выходные. Наборы данных представляют данные в разных хранилищах, например в таблицах, файлах, папках и документах. Например, набор данных больших двоичных объектов Azure указывает контейнер больших двоичных объектов и папку в хранилище BLOB-объектов, из которой действие должно считывать данные.
Перед созданием набора данных необходимо создать связанную службу, чтобы связать хранилище данных со службой. Связанные службы во многом напоминают строки подключения, определяющие сведения о подключении, необходимые для подключения службы к внешним ресурсам. Таким образом, набор данных представляет структуру данных в связанных хранилищах данных, а связанная служба определяет подключение к источнику данных. Например, связанная служба хранилища Azure привязывает учетную запись хранения. Набор данных BLOB-объектов Azure представляет собой контейнер BLOB-объектов и папку в учетной записи хранения Azure, содержащую входные BLOB-объекты для обработки.
Ниже приведен пример сценария. Чтобы скопировать данные из Хранилища BLOB-объектов в базу данных SQL, создайте две связанные службы: хранилища BLOB-объектов Azure и Базу данных SQL Azure. Затем создайте два набора данных: набор данных текста с разделителями (для связанной службы "Хранилище BLOB-объектов Azure" в предположении, что текстовые файлы используются в качестве источника) и набор данных таблицы SQL Azure (для связанной службы "База данных SQL Azure"). Связанные службы хранилища BLOB-объектов Azure и базы данных SQL Azure содержат строки подключения, которые служба использует во время выполнения для подключения к службе хранилища Azure и базе данных Azure SQL соответственно. Набор данных текста с разделителями определяет контейнер и папку больших двоичных объектов, которые содержат входные большие двоичные объекты в вашем хранилище BLOB-объектов, а также параметры форматирования. Набор данных таблицы SQL Azure определяет таблицу SQL в базе данных SQL, в которую будут копироваться данные.
На следующей схеме показана связь между конвейером, действием, набором данных и связанными службами:
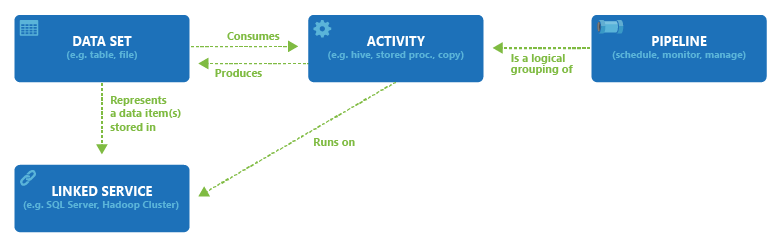
Создание набора данных с помощью пользовательского интерфейса
Чтобы создать набор данных с помощью студии Фабрики данных Azure, выберите вкладку "Автор" (со значком карандаша), а затем щелкните значок со знаком плюса, чтобы выбрать набор данных.
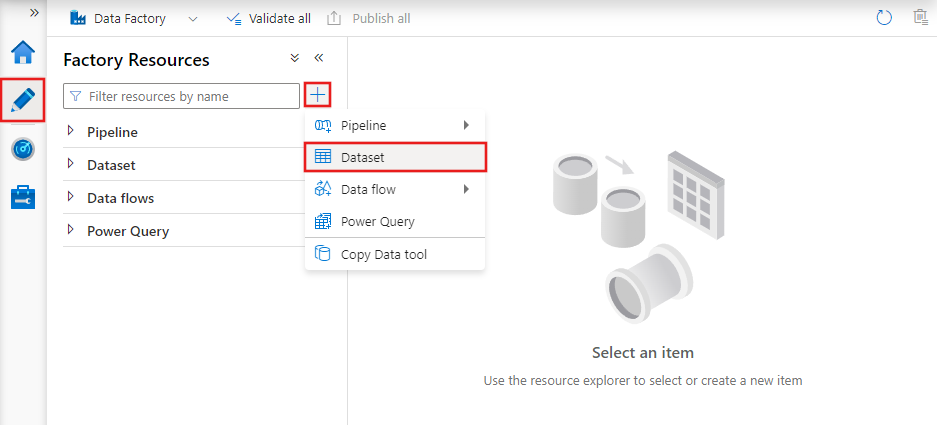
Появится окно нового набора данных, в котором можно выбрать любой из соединителей, доступных в Фабрике данных Azure, для настройки существующей или новой связанной службы.
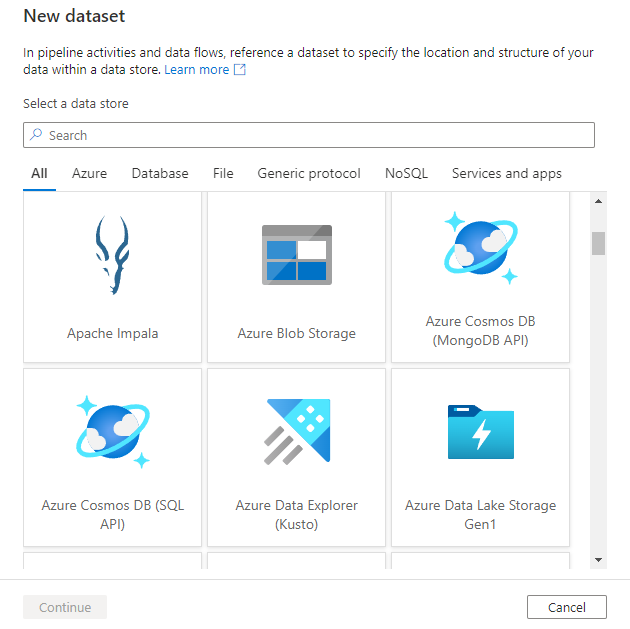
Далее вам будет предложено выбрать формат набора данных.

Наконец, можно выбрать существующую связанную службу типа, выбранного для набора данных, или создать новую, если она еще не определена.
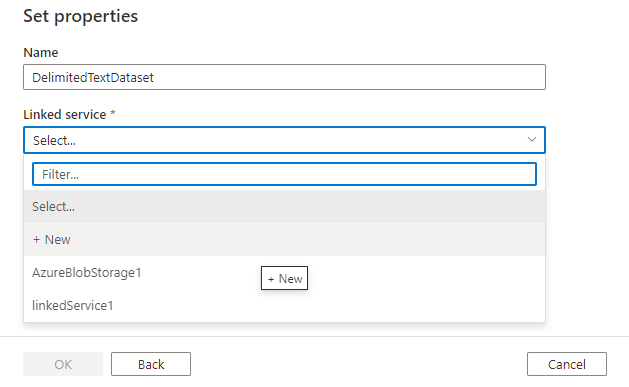
Созданный набор данных можно использовать в любом конвейере в Фабрике данных Azure.
JSON набора данных
Набор данных определяется в формате JSON следующим образом:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
В следующей таблице описаны свойства приведенного выше объекта JSON.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| name | Имя набора данных. См. Правила именования. | Да |
| type | Тип набора данных. Укажите один из типов, которые поддерживает фабрика данных (например: DelimitedText, AzureSqlTable). Дополнительные сведения см. в разделе о типах наборов данных. |
Да |
| schema | Схема в наборе данных представляет собой физический тип данных и фигуру. | No |
| typeProperties | Свойства каждого типа различаются. Сведения о поддерживаемых типах и их свойствах см. в разделе Тип набора данных. | Да |
При импорте схемы набора данных нажмите кнопку Импорт схемы и выберите импорт из источника или из локального файла. В большинстве случаев вы будете импортировать схему непосредственно из источника. Но если у вас уже есть файл локальной схемы (файл Parquet или CSV с заголовками), можно указать, чтобы служба использовала этот файл как основу для схемы.
В действии копирования применяются наборы данных в источнике и приемнике. Схема, определенная в наборе данных, является необязательной и используется для справки. Сведения о том, как настроить сопоставление столбцов и полей между источником и приемником, см. в статье о схеме и сопоставлении типов.
В средстве "Поток данных" наборы данных используются в преобразованиях источника и приемника. Наборы данных определяют базовые схемы данных. Если у ваших данных нет схемы, вы можете использовать смещение схемы для источника и приемника. Метаданные из наборов данных отображаются в исходном преобразовании в качестве проекции источника. Проекция в преобразовании источника представляет собой данные средства "Поток данных" посредством определенных имен и типов.
Тип набора данных
Служба поддерживает различные типы наборов данных в зависимости от используемых хранилищ. Список хранилищ данных, поддерживаемых хранилищами данных, см. в статье Общие сведения о соединителях. Щелкните хранилище данных, чтобы узнать, как создать для него связанную службу и набор данных.
Например, для набора данных текста с разделителями задается тип DelimitedText, как показано в следующем примере JSON:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Создайте наборы данных.
Наборы данных можно создавать с помощью таких инструментов и пакетов SDK: API .NET, PowerShell, REST API, шаблон Azure Resource Manager, портал Azure.
Наборы данных текущей версии и версии 1
Ниже приведены некоторые различия между наборами данных в текущей версии фабрики данных (и Azure Synapse) и в устаревшей версии 1 фабрики данных.
- Внешнее свойство не поддерживается в текущей версии. Оно заменено триггером.
- Политика и свойства доступности не поддерживаются в текущей версии. Время начала конвейера зависит от триггеров.
- Наборы данных с заданной областью (наборы данных, определенные в конвейере) не поддерживаются в текущей версии.
Связанный контент
Пошаговые инструкции по созданию конвейеров и наборов данных с помощью одного из указанных ниже инструментов или пакетов SDK приведены в указанных ниже руководствах.