Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Azure Data Lake Storage 2-го поколения (ADLS 2-го поколения) — это набор возможностей аналитики больших данных, созданный на основе хранилища BLOB-объектов Azure. С его помощью можно работать с данными с использованием парадигмы файловой системы или хранилища объектов.
В этой статье описано, как копировать данные в хранилище Azure Data Lake Storage 2-го поколения и из него с помощью действия копирования, а также как преобразовывать данные в Azure Data Lake Storage 2-го поколения с помощью Потока данных. Дополнительные сведения см. в вводной статье о Фабрике данных Azure или Azure Synapse Analytics.
Совет
Дополнительные сведения о сценарии миграции озера данных или хранилища данных см. в статье Перенос данных из озера данных или хранилища данных в Azure.
Поддерживаемые возможности
Этот соединитель Azure Data Lake Storage 2-го поколения поддерживается для следующих возможностей:
| Поддерживаемые возможности | IR | Управляемая частная конечная точка |
|---|---|---|
| Действие копирования (источник/приемник) | (1) (2) | ✓ |
| Поток данных для сопоставления (источник/приемник) | (1) | ✓ |
| Действие поиска | (1) (2) | ✓ |
| Действие получения метаданных в Фабрике данных Azure | (1) (2) | ✓ |
| Действие удаления | (1) (2) | ✓ |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Используя этот соединитель для действия копирования, можно:
- копировать данные в хранилище Azure Data Lake Storage 2-го поколения или из него с использованием аутентификации на основе ключа учетной записи, субъекта-службы или управляемых удостоверений для ресурсов Azure;
- копировать файлы "как есть" или создавать файлы с использованием поддерживаемых форматов файла и кодеков сжатия;
- сохранять метаданные файла во время копирования;
- сохранять списки управления доступом при копировании данных из Azure Data Lake Storage 1-го или 2-го поколения.
Начало работы
Совет
Пошаговое руководство по использованию соединителя Azure Data Lake Storage 2-го поколения см. в статье Загрузка данных в Azure Data Lake Storage 2-го поколения.
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
Создание связанной службы Azure Data Lake Storage 2-го поколения с помощью пользовательского интерфейса
Выполните приведенные ниже действия, чтобы создать связанную службу для Azure Data Lake Storage 2-го поколения с помощью пользовательского интерфейса на портале Azure.
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Выполните поиск Azure Data Lake Storage 2-го поколения и выберите соединитель Azure Data Lake Storage 2-го поколения.
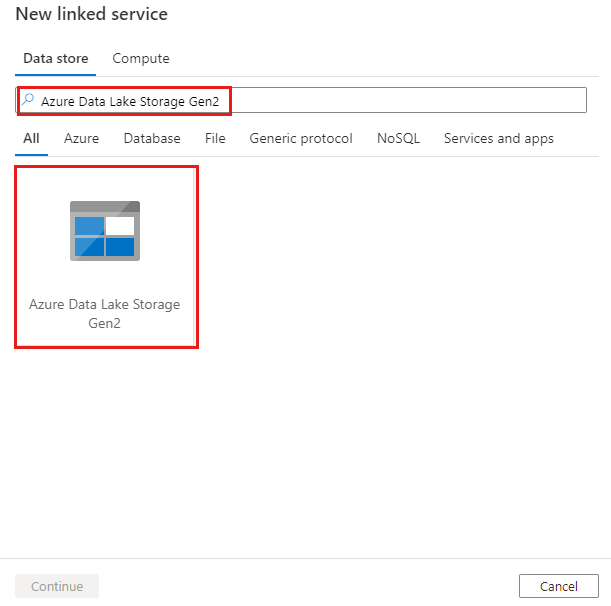
Настройте сведения о службе, проверьте подключение и создайте связанную службу.
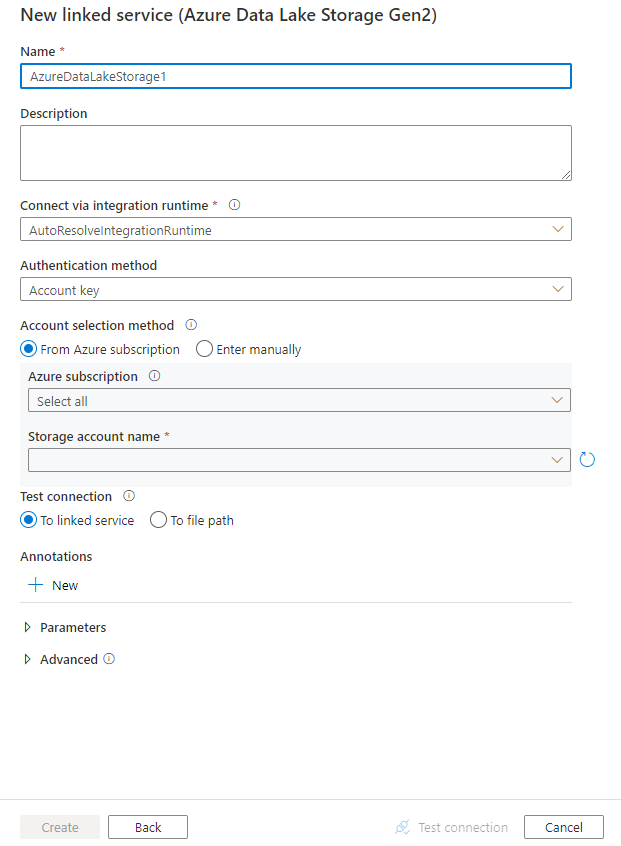
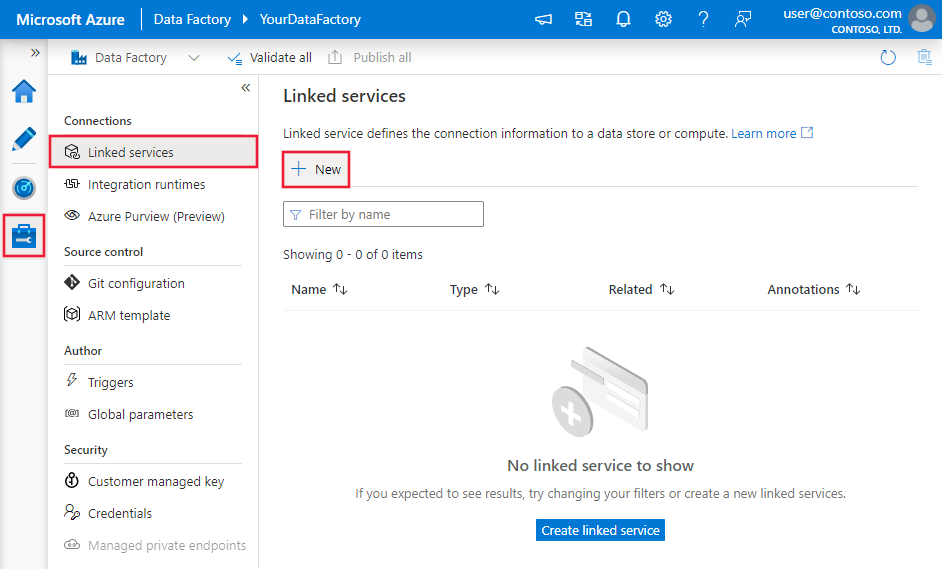
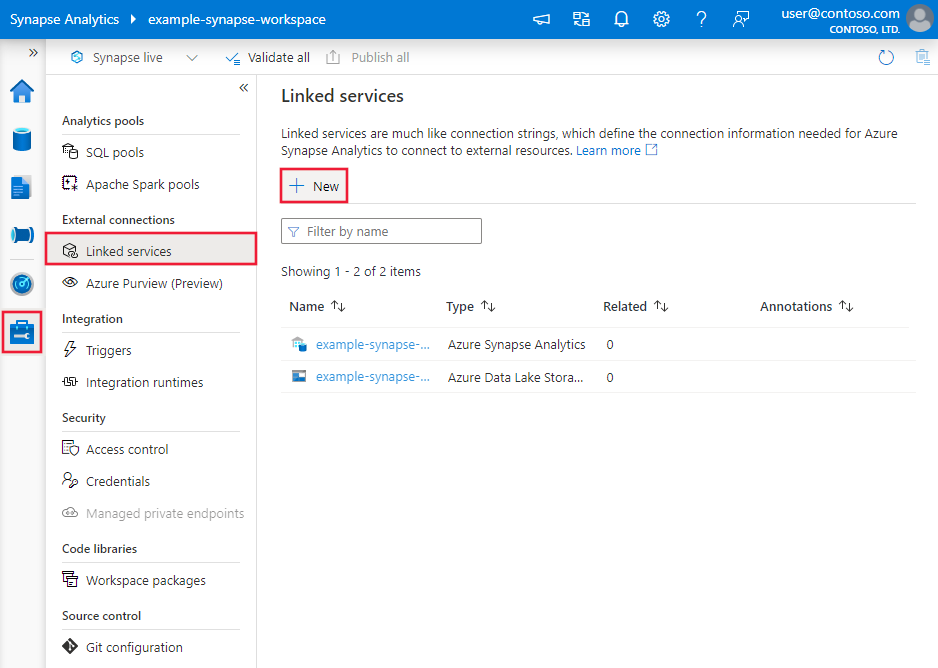
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для определения сущностей конвейеров Фабрики данных и Synapse, характерных для Azure Data Lake Storage 2-го поколения.
Свойства связанной службы
Соединитель Azure Data Lake Storage 2-го поколения поддерживает приведенные ниже типы аутентификации. Дополнительные сведения см. в соответствующих разделах:
- Проверка подлинности на основе ключа учетной записи
- Аутентификация SAS
- Проверка подлинности субъекта-службы
- Проверка подлинности с помощью назначенного системой управляемого удостоверения
- Проверка подлинности с помощью назначаемого пользователем управляемого удостоверения
Примечание.
- Если включить параметр Разрешить доверенным службам Майкрософт доступ к этой учетной записи хранения в настройках брандмауэра службы хранилища Azure, то при попытке использовать общедоступную среду выполнения интеграции Azure для подключения к Azure Data Lake Storage 2-го поколения потребуется использовать проверку подлинности на основе управляемого удостоверения. Дополнительные сведения о брандмауэрах службы хранилища см. в статье Настройка виртуальных сетей и брандмауэров службы хранилища Azure.
- Если при использовании инструкций PolyBase или COPY для загрузки данных в Azure Synapse Analytics исходное или промежуточное хранилище Data Lake Storage 2-го поколения настроено с использованием конечной точки виртуальной сети Azure, вам понадобится применить проверку подлинности на основе управляемого удостоверения в соответствии с требованиями Azure Synapse. Дополнительные предварительные требования к конфигурации см. в разделе Проверка подлинности с использованием управляемого удостоверения.
Проверка подлинности на основе ключа учетной записи
При использовании проверки подлинности на основе ключа учетной записи поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение AzureBlobFS. | Да |
| URL-адрес | Конечная точка для Azure Data Lake Storage 2-го поколения вида https://<accountname>.dfs.core.windows.net. |
Да |
| accountKey | Ключ учетной записи для Azure Data Lake Storage 2-го поколения. Пометьте это поле как SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Вы можете использовать среду выполнения интеграции Azure или локальную среду IR (если хранилище данных расположено в частной сети). Если это свойство не задано, используется Azure Integration Runtime по умолчанию. | No |
Примечание.
Дополнительная конечная точка файловой системы ADLS не поддерживается при использовании аутентификации на основе ключа учетной записи. Можно использовать другие типы аутентификации.
Пример:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"accountkey": {
"type": "SecureString",
"value": "<accountkey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Аутентификация SAS
Подпись общего доступа обеспечивает делегированный доступ к ресурсам в вашей учетной записи хранения. Вы можете использовать подписанный URL-адрес, чтобы предоставить клиенту ограниченные разрешения на работу с объектами в вашей учетной записи хранения на определенный период.
Не нужно предоставлять совместный доступ к ключам доступа для учетной записи. Подписанный URL-адрес — это универсальный код ресурса (URI), который в своих параметрах запроса содержит все сведения, необходимые для доступа к ресурсу хранилища с прохождением аутентификации. Для доступа к ресурсам хранилища с помощью подписанного URL-адреса клиенту достаточно передать SAS в соответствующий конструктор или метод.
Дополнительные сведения о подписанном URL-адресе см. в статье Использование подписанных URL-адресов (SAS).
Примечание.
- Сейчас служба поддерживает как подписанные URL-адреса уровня службы, так и подписанные URL-адреса уровня учетной записи. Дополнительные сведения о подписанных URL-адресах (SAS) см. в статье Предоставление ограниченного доступа к ресурсам Службы хранилища Azure с использованием подписанных URL-адресов.
- В более поздних конфигурациях набора данных путь к папке — это полный путь, начинающийся с уровня контейнера. Вам нужно настроить такой путь, соответствующий пути в вашем URI SAS.
Следующие свойства поддерживаются для использования проверки подлинности на основе подписанного URL-адреса.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type должно иметь значение AzureBlobFS (предлагаемое) |
Да |
| sasUri | Укажите URI подписанного URL-адреса для ресурсов службы хранилища, например для BLOB-объекта или контейнера. Установите для этого поля метку SecureString для его безопасного хранения. Также можно поместить маркер SAS в Azure Key Vault для использования автоматической ротации и для удаления части маркера. Дополнительные сведения см. в следующих примерах и в статье Хранение учетных данных в Azure Key Vault. |
Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Можно использовать среду выполнения интеграции Azure или локальную среду выполнения интеграции (если хранилище данных расположено в частной сети). Если это свойство не задано, используется среда выполнения интеграции Azure по умолчанию. | No |
Примечание.
Если используется тип связанной службы AzureStorage, он по-прежнему поддерживается как есть. Но в дальнейшем рекомендуется использовать новый тип связанной службы AzureDataLakeStorageGen2.
Пример:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример: хранение ключа учетной записи в Azure Key Vault
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
При создании URI подписанного URL-адреса необходимо учитывать следующее.
- Задайте для объектов соответствующие разрешения на чтение или запись. Они устанавливаются с учетом назначения связанной службы (чтение, запись, чтение и запись).
- Задайте время окончания срока действия соответствующим образом. Убедитесь, что срок действия доступа к объектам хранилища не истекает в период активности конвейера.
- В зависимости от потребности URI следует создать для нужного контейнера или BLOB-объекта. URI подписанного URL-адреса для большого двоичного объекта позволяет Фабрике данных Azure или конвейеру Synapse получить доступ к определенному большому двоичному объекту. URI подписанного URL-адреса для контейнера хранилища больших двоичных объектов позволяет Фабрике данных Azure или конвейеру Synapse выполнить итерацию по большим двоичным объектам в этом контейнере. Чтобы предоставить доступ к большему или меньшему количеству объектов позднее или обновить URI подписанного URL-адреса, не забудьте обновить связанную службу с помощью нового URI.
Аутентификация субъекта-службы
Чтобы использовать аутентификацию на основе субъекта-службы, выполните следующие действия.
Регистрация приложения с помощью платформы удостоверений Майкрософт. Дополнительные сведения см. в кратком руководстве. Регистрация приложения с помощью платформа удостоверений Майкрософт. Запишите эти значения, которые используются для определения связанной службы:
- Application ID
- ключ приложения.
- Идентификатор клиента
Предоставьте правильное разрешение субъекту-службе. Примеры использования разрешения в Data Lake Storage 2-го поколения см. в статье Списки управления доступом для файлов и каталогов.
- В качестве источника. В Обозревателе службы хранилища предоставьте как минимум разрешение Выполнение для ВСЕХ вышестоящих папок и файловой системы, а также разрешение Чтение для копируемых файлов. Можно также в Системе управления идентификацией и доступом (IAM) назначить по крайней мере роль Модуль чтения данных BLOB-объектов хранилища.
- В качестве приемника. В Обозревателе службы хранилища предоставьте как минимум разрешение Выполнение для ВСЕХ вышестоящих папок и файловой системы, а также разрешение Запись для папки приемника. Можно также в Системе управления идентификацией и доступом (IAM) назначить по крайней мере роль Участник для данных BLOB-объектов хранилища.
Примечание.
Если вы используете пользовательский интерфейс и не назначили для субъекта-службы роль "Модуль чтения данных BLOB-объектов хранилища" или "Участник для данных BLOB-объектов хранилища" в IAM, то при проверке подключения или просмотре папок выберите "Test connection to file path" (Проверить подключение к пути к файлу) или "Browse from specified path" (Обзор по указанному пути) и укажите путь с разрешением Чтение и выполнение, чтобы продолжить.
Приведенные ниже свойства поддерживаются в связанной службе.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение AzureBlobFS. | Да |
| URL-адрес | Конечная точка для Azure Data Lake Storage 2-го поколения вида https://<accountname>.dfs.core.windows.net. |
Да |
| servicePrincipalId | Укажите идентификатора клиента приложения. | Да |
| servicePrincipalCredentialType | Тип учетных данных для использования при проверке подлинности субъекта-службы. Допустимые значения: ServicePrincipalKey и ServicePrincipalCert. | Да |
| servicePrincipalCredential | Учетные данные субъекта-службы. При использовании в качестве типа учетных данных ServicePrincipalKey нужно указывать ключ приложения. Присвойте этому полю метку SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. При использовании ServicePrincipalCert в качестве учетных данных ссылайтесь на сертификат в Azure Key Vault и убедитесь, что тип контента сертификата — PKCS #12. |
Да |
| servicePrincipalKey | Укажите ключ приложения. Присвойте этому полю метку SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. Это свойство по-прежнему поддерживается "как есть" для servicePrincipalId + servicePrincipalKey. Когда Фабрика данных добавляет проверку подлинности сертификата нового субъекта-службы, новая модель для проверки подлинности субъекта-службы будет выглядеть так: servicePrincipalId + servicePrincipalCredentialType + servicePrincipalCredential. |
No |
| tenant | Укажите сведения о клиенте (доменное имя или идентификатор клиента), в котором находится приложение. Эти сведения можно получить, наведя указатель мыши на правый верхний угол страницы портала Azure. | Да |
| azureCloudType | Для проверки подлинности субъекта-службы укажите тип облачной среды Azure, в которой зарегистрировано приложение Microsoft Entra. Допустимые значения: AzurePublic, AzureChina, AzureUsGovernment и AzureGermany. По умолчанию используется облачная среда Фабрики данных Azure или конвейера Synapse. |
No |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Вы можете использовать среду выполнения интеграции Azure или локальную среду IR (если хранилище данных расположено в частной сети). Если не указано другое, используется среда выполнения интеграции Azure по умолчанию. | No |
Пример: использование проверки подлинности с помощью ключа субъекта-службы
Вы также можете хранить ключ субъекта-службы в Azure Key Vault.
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример: использование проверки подлинности с помощью сертификата субъекта-службы
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalCredential": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<AKV reference>",
"type": "LinkedServiceReference"
},
"secretName": "<certificate name in AKV>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Проверка подлинности с помощью назначенного системой управляемого удостоверения
Рабочую область Фабрики данных или Synapse можно связать с управляемым удостоверением, назначаемым системой. Это назначаемое системой управляемое удостоверение можно использовать непосредственно для проверки подлинности Data Lake Storage 2-го поколения так же, как для проверки собственного субъекта-службы. Оно разрешает назначенной фабрике или рабочей области обращаться к данным и копировать их из хранилища Azure Data Lake Storage 2-го поколения и в него.
Для использования проверки подлинности с помощью управляемого удостоверения, назначаемого системой, выполните приведенные ниже действия.
Получите сведения об управляемом удостоверении, назначаемом системой, скопировав значение идентификатора объекта управляемого удостоверения, созданного вместе с рабочей областью Фабрики данных или Synapse.
Предоставьте соответствующее разрешение управляемому удостоверению, назначаемому системой. Примеры использования разрешения в Data Lake Storage 2-го поколения см. в статье Списки управления доступом для файлов и каталогов.
- В качестве источника. В Обозревателе службы хранилища предоставьте как минимум разрешение Выполнение для ВСЕХ вышестоящих папок и файловой системы, а также разрешение Чтение для копируемых файлов. Можно также в Системе управления идентификацией и доступом (IAM) назначить по крайней мере роль Модуль чтения данных BLOB-объектов хранилища.
- В качестве приемника. В Обозревателе службы хранилища предоставьте как минимум разрешение Выполнение для ВСЕХ вышестоящих папок и файловой системы, а также разрешение Запись для папки приемника. Можно также в Системе управления идентификацией и доступом (IAM) назначить по крайней мере роль Участник для данных BLOB-объектов хранилища.
Приведенные ниже свойства поддерживаются в связанной службе.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение AzureBlobFS. | Да |
| URL-адрес | Конечная точка для Azure Data Lake Storage 2-го поколения вида https://<accountname>.dfs.core.windows.net. |
Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Вы можете использовать среду выполнения интеграции Azure или локальную среду IR (если хранилище данных расположено в частной сети). Если не указано другое, используется среда выполнения интеграции Azure по умолчанию. | No |
Пример:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Проверка подлинности с помощью назначаемого пользователем управляемого удостоверения
Фабрике данных может быть назначено одно или несколько управляемых удостоверений, назначаемых пользователем. Это удостоверение можно использовать для проверки подлинности хранилища BLOB-объектов, что позволяет получать доступ к данным и копировать их в Data Lake Storage 2-го поколения и обратно. Дополнительные сведения об управляемых удостоверениях для ресурсов Azure см. в статье Управляемые удостоверения для ресурсов Azure.
Для использования проверки подлинности с помощью управляемого удостоверения, назначаемого пользователем, выполните приведенные ниже действия.
Создайте одно или несколько управляемых удостоверений, назначаемых пользователем, и предоставьте доступ к Azure Data Lake Storage 2-го поколения. Примеры использования разрешения в Data Lake Storage 2-го поколения см. в статье Списки управления доступом для файлов и каталогов.
- В качестве источника. В Обозревателе службы хранилища предоставьте как минимум разрешение Выполнение для ВСЕХ вышестоящих папок и файловой системы, а также разрешение Чтение для копируемых файлов. Можно также в Системе управления идентификацией и доступом (IAM) назначить по крайней мере роль Модуль чтения данных BLOB-объектов хранилища.
- В качестве приемника. В Обозревателе службы хранилища предоставьте как минимум разрешение Выполнение для ВСЕХ вышестоящих папок и файловой системы, а также разрешение Запись для папки приемника. Можно также в Системе управления идентификацией и доступом (IAM) назначить по крайней мере роль Участник для данных BLOB-объектов хранилища.
Присвойте одно или несколько управляемых удостоверений, назначаемых пользователем, фабрике данных и создайте учетные данные для каждого подобного удостоверения.
Приведенные ниже свойства поддерживаются в связанной службе.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение AzureBlobFS. | Да |
| URL-адрес | Конечная точка для Azure Data Lake Storage 2-го поколения вида https://<accountname>.dfs.core.windows.net. |
Да |
| учетные данные | Укажите назначаемое пользователем управляемое удостоверение в качестве объекта учетных данных. | Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Вы можете использовать среду выполнения интеграции Azure или локальную среду IR (если хранилище данных расположено в частной сети). Если не указано другое, используется среда выполнения интеграции Azure по умолчанию. | No |
Пример:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Примечание.
Если вы используете пользовательский интерфейс Фабрики данных и не назначили для управляемого удостоверения роль "Модуль чтения данных BLOB-объектов хранилища" или "Участник для данных BLOB-объектов хранилища" в IAM, то при проверке подключения или просмотре папок выберите "Test connection to file path" (Проверить подключение к пути к файлу) или "Browse from specified path" (Обзор по указанному пути) и укажите путь с разрешением Чтение и выполнение, чтобы продолжить.
Внимание
Если для загрузки данных из хранилища Data Lake Storage 2-го поколения в Azure Synapse Analytics используется инструкция PolyBase или COPY, то при использовании проверки подлинности управляемого удостоверения для хранилища Data Lake Storage 2-го поколения нужно обязательно выполнить действия 1–3 из этого руководства. Эти действия будут зарегистрировать сервер с помощью идентификатора Microsoft Entra и назначить роль участника данных BLOB-объектов хранилища серверу. Фабрика данных обрабатывает остальные компоненты. Если вы настраиваете хранилище BLOB-объектов с использованием конечной точки виртуальной сети Azure, включите параметр Разрешить доверенным службам Майкрософт доступ к этой учетной записи хранения в меню настроек Брандмауэры и виртуальные сети учетной записи службы хранилища Azure в соответствии с требованиями Azure Synapse.
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в разделе Наборы данных в фабрике данных Azure.
Фабрика данных Azure поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- Формат Excel
- Формат Айсберга
- Формат JSON
- Формат ORC
- Формат Parquet
- ФОРМАТ XML
Ниже перечислены свойства, которые поддерживаются для Azure Data Lake Storage 2-го поколения в настройках location в наборе данных на основе формата.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type в разделе location в наборе данных должно быть задано значение AzureBlobFSLocation. |
Да |
| fileSystem | Имя файловой системы Azure Data Lake Storage 2-го поколения. | No |
| folderPath | Путь к папке в заданной файловой системе. Если вы хотите использовать подстановочный знак для фильтрации папок, пропустите этот параметр и укажите его в параметрах источника действия. | No |
| fileName | Имя файла по заданному пути к папке в указанной файловой системе. Если вы хотите использовать подстановочный знак для фильтрации файлов, пропустите этот параметр и укажите его в параметрах источника действия. | No |
Пример:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobFSLocation",
"fileSystem": "filesystemname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, доступен в разделах Действие копирования в фабрике данных Azure и Конвейеры и действия в фабрике данных Azure. Этот раздел содержит список свойств, поддерживаемых источником и приемником Data Lake Storage Gen2.
Azure Data Lake Storage 2-го поколения как тип источника
Фабрика данных Azure поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- Формат Excel
- Формат JSON
- Формат ORC
- Формат Parquet
- ФОРМАТ XML
Существует несколько вариантов копирования данных из ADLS 2-го поколения:
- копирование из указанного пути в наборе данных;
- фильтр с подстановочными знаками для пути к папке или имени файла (см. сведения в разделах
wildcardFolderPathиwildcardFileName); - копирование набора файлов, определенных в заданном текстовом файле (см. сведения в разделе
fileListPath).
Ниже перечислены свойства, которые поддерживаются для Azure Data Lake Storage 2-го поколения в настройках storeSettings в источнике копирования на основе формата.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type в разделе storeSettings необходимо задать значение AzureBlobFSReadSettings. |
Да |
| Поиск файлов для копирования | ||
| ВАРИАНТ 1. Статический путь |
Копирование из указанной файловой системы или пути к папке либо файлу, которые указаны в наборе данных. Если вы хотите скопировать все файлы из файловой системы или папки, дополнительно укажите для wildcardFileName значение *. |
|
| ВАРИАНТ 2. Подстановочный знак - wildcardFolderPath |
Путь к папке с подстановочными знаками в заданной файловой системе, настроенный в наборе данных для фильтрации исходных папок. Допустимые подстановочные знаки: * (соответствует нулю или большему количеству знаков) и ? (соответствует нулю или одному знаку). Для экранирования используйте ^, если фактическое имя папки содержит подстановочный знак или escape-символ. Дополнительные примеры приведены в разделе Примеры фильтров папок и файлов. |
No |
| ВАРИАНТ 2. Подстановочный знак — wildcardFileName |
Имя файла с подстановочными знаками в заданной файловой системе с параметрами folderPath или wildcardFolderPath для фильтрации исходных папок. Допустимые подстановочные знаки: * (соответствует нулю или большему количеству знаков) и ? (соответствует нулю или одному знаку). Для экранирования используйте ^, если фактическое имя файла содержит подстановочный знак или escape-символ. Дополнительные примеры приведены в разделе Примеры фильтров папок и файлов. |
Да |
| Вариант 3. Список файлов - fileListPath |
Указывает, что нужно скопировать заданный набор файлов. Укажите текстовый файл со списком файлов, которые необходимо скопировать, по одному файлу в строке (каждая строка должна содержать относительный путь к заданному в наборе данных пути). При использовании этого варианта не указывайте имя файла в наборе данных. Ознакомьтесь с дополнительными примерами в разделе Примеры списков файлов. |
No |
| Дополнительные параметры: | ||
| recursive | Указывает, следует ли читать данные рекурсивно из вложенных папок или только из указанной папки. Обратите внимание, что если для свойства recursive задано значение true, а приемником является файловое хранилище, пустые папки и вложенные папки не создаются в приемнике. Допустимые значения: true (по умолчанию) и false. Это свойство не применяется при настройке fileListPath. |
No |
| deleteFilesAfterCompletion | Указывает, удаляются ли двоичные файлы из исходного хранилища после успешного перемещения в конечное хранилище. Файлы удаляются поочередно, поэтому в случае сбоя действия копирования вы увидите, что некоторые файлы уже скопированы в место назначения и удалены из источника, в то время как остальные находятся в исходном хранилище. Это свойство допустимо только в сценарии копирования двоичных файлов. По умолчанию имеет значение false. |
No |
| modifiedDatetimeStart | Фильтр файлов на основе атрибута: Last Modified. Будут выбраны все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате "2018-12-01T05:00:00Z". Эти свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не будут применяться к этому набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то будут выбраны файлы, чей атрибут последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то будут выбраны все файлы, чей атрибут последнего изменения меньше указанного значения даты и времени.Это свойство не применяется при настройке fileListPath. |
No |
| modifiedDatetimeEnd | То же, что выше. | No |
| enablePartitionDiscovery | Для секционированных файлов укажите, следует ли анализировать секции из пути к файлу и добавлять их как дополнительные исходные столбцы. Допустимые значения: false (по умолчанию) и true. |
No |
| partitionRootPath | Если обнаружение секций включено, укажите абсолютный корневой путь, чтобы считывать секционированные папки как столбцы данных. Если параметр не задан (по умолчанию), происходит следующее. — При использовании пути к файлу в наборе данных или списке файлов в источнике корневым путем секции считается путь, настроенный в наборе данных. — При использовании фильтра папки с подстановочными знаками корневым путем секции считается часть пути до первого подстановочного знака. Предположим, что вы настроили путь в наборе данных следующим образом: "root/folder/year=2020/month=08/day=27". — Если указать корневой путь секции "root/folder/year=2020", действие копирования в дополнение к указанным в файлах столбцам создаст еще два столбца, month и day, со значениями "08" и "27" соответственно.— Если корневой путь секции не указан, дополнительные столбцы создаваться не будут. |
No |
| maxConcurrentConnections | Верхний предел одновременных подключений, установленных для хранилища данных при выполнении действия. Указывайте значение только при необходимости ограничить количество одновременных подключений. | No |
Пример:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobFSReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Data Lake Storage Gen2 как тип приемника
Фабрика данных Azure поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- Формат Айсберга
- Формат JSON
- Формат ORC
- Формат Parquet
Ниже перечислены свойства, которые поддерживаются для Azure Data Lake Storage 2-го поколения в настройках storeSettings в приемнике копирования на основе формата.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type в разделе storeSettings необходимо задать значение AzureBlobFSWriteSettings. |
Да |
| copyBehavior | Определяет поведение копирования, когда источником являются файлы из файлового хранилища данных. Допустимые значения: — PreserveHierarchy (по умолчанию). Сохраняет иерархию файлов в целевой папке. Относительный путь исходного файла в исходной папке идентичен относительному пути целевого файла в целевой папке. — FlattenHierarchy. Все файлы из исходной папки размещаются на первом уровне в целевой папке. Целевые файлы имеют автоматически сформированные имена. — MergeFiles. Объединяет все файлы из исходной папки в один файл. Если указано имя файла, то оно присваивается объединенному файлу. В противном случае присваивается автоматически созданное имя файла. |
No |
| blockSizeInMB | Укажите размер блока в МБ, используемый для записи данных в Azure Data Lake Storage 2-го поколения. Узнайте больше о блочных BLOB-объектaх. Допустимое значение — от 4 до 100 МБ. По умолчанию ADF автоматически определяет размер блока на основе типа и данных исходного хранилища. Для копирования недвоичных файлов в Azure Data Lake Storage 2-го поколения размер блока по умолчанию составляет 100 МБ, что позволяет разместить приблизительно 4,75 ТБ данных. Если объем данных не слишком велик, это может оказаться неоптимальным, особенно при использовании локальной среды выполнения интеграции с плохой сетью, что приводит к истечению времени ожидания или проблемам с производительностью. Можно явно указать размер блока, а также убедиться, что значение параметра blockSizeInMB*50000 достаточно велико для хранения данных, в противном случае выполнение действия копирования завершится ошибкой. |
No |
| maxConcurrentConnections | Верхний предел одновременных подключений, установленных для хранилища данных при выполнении действия. Указывайте значение только при необходимости ограничить количество одновременных подключений. | No |
| metadata | Задайте пользовательские метаданные при копировании в приемник. Каждый объект в массиве metadata представляет дополнительный столбец. name определяет имя ключа метаданных, а value указывает значение данных этого ключа. Если используется функция сохранения атрибутов, указанные метаданные будут объединены с метаданными исходного файла или перезаписаны ими.Допустимые значения: - $$LASTMODIFIED: зарезервированная переменная указывает на сохранение времени последнего изменения исходных файлов. Она применяется к файловому источнику, который может быть только в двоичном формате.Выражение - Статическое значение |
No |
Пример:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobFSWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
Примеры фильтров папок и файлов
В этом разделе описываются результаты применения фильтров с подстановочными знаками к пути папки и имени файла.
| folderPath | fileName | recursive | Структура исходной папки и результат фильтрации (извлекаются файлы, выделенные полужирным шрифтом) |
|---|---|---|---|
Folder* |
(Пусто, используйте значение по умолчанию) | false | ПапкаA Файл1.csv File2.json Вложенная_папка1 File3.csv File4.json File5.csv Другая_папкаB Файл6.csv |
Folder* |
(Пусто, используйте значение по умолчанию) | true | ПапкаA Файл1.csv File2.json Вложенная_папка1 File3.csv File4.json File5.csv Другая_папкаB Файл6.csv |
Folder* |
*.csv |
false | ПапкаA Файл1.csv File2.json Вложенная_папка1 File3.csv File4.json File5.csv Другая_папкаB Файл6.csv |
Folder* |
*.csv |
true | ПапкаA Файл1.csv File2.json Вложенная_папка1 File3.csv File4.json File5.csv Другая_папкаB Файл6.csv |
Примеры списков файлов
В этом разделе описывается поведение, возникающее при указании пути к списку файлов в качестве источника для действия копирования.
Предположим, что у вас есть следующая исходная структура папок и вы хотите скопировать файлы, выделенные полужирным шрифтом:
| Пример исходной структуры | Содержимое файла FileListToCopy.txt | Конфигурация ADF |
|---|---|---|
| filesystem ПапкаA Файл1.csv File2.json Вложенная_папка1 File3.csv File4.json File5.csv Метаданные FileListToCopy.txt |
Файл1.csv Вложенная_папка1/Файл3.csv Вложенная_папка1/Файл5.csv |
В наборе данных: - файловая система: filesystem– Путь к папке: FolderAВ источнике действия копирования: – Путь к списку файлов: filesystem/Metadata/FileListToCopy.txt Путь к списку файлов указывает на текстовый файл в том же хранилище данных, содержащий список файлов, которые необходимо скопировать, указав по одному файлу в строке с относительным путем к пути, заданному в наборе данных. |
Некоторые примеры recursive и copyBehavior
В данном разделе описываются результаты выполнения операции копирования при использовании различных сочетаний значений recursive и copyBehavior.
| recursive | copyBehavior | Структура папок источника | Результаты цели |
|---|---|---|---|
| true | preserveHierarchy | Папка1 Файл1 Файл2 Вложенная_папка1 Файл3 Файл4 Файл5 |
Целевая "Папка1" создается с такой же структурой, как и исходная папка: Папка1 Файл1 Файл2 Вложенная_папка1 Файл3 Файл4 Файл5 |
| true | flattenHierarchy | Папка1 Файл1 Файл2 Вложенная_папка1 Файл3 Файл4 Файл5 |
Целевая папка1 создается со следующей структурой: Папка1 автоматически созданное имя для "Файл1" автоматически созданное имя для "Файл2" автоматически созданное имя для "Файл3" автоматически созданное имя для "Файл4" автоматически созданное имя для "Файл5" |
| true | mergeFiles | Папка1 Файл1 Файл2 Вложенная_папка1 Файл3 Файл4 Файл5 |
Целевая папка1 создается со следующей структурой: Папка1 Содержимое файлов "Файл1", "Файл2", "Файл3", "Файл4" и "Файл5" объединяется в один файл с автоматически созданным именем. |
| false | preserveHierarchy | Папка1 Файл1 Файл2 Вложенная_папка1 Файл3 Файл4 Файл5 |
Целевая папка1 создается со следующей структурой: Папка1 Файл1 Файл2 Папка "Вложенная_папка1" с файлами "Файл3", "Файл4" и "Файл5" не будет включена в эту папку. |
| false | flattenHierarchy | Папка1 Файл1 Файл2 Вложенная_папка1 Файл3 Файл4 Файл5 |
Целевая папка1 создается со следующей структурой: Папка1 автоматически созданное имя для "Файл1" автоматически созданное имя для "Файл2" Папка "Вложенная_папка1" с файлами "Файл3", "Файл4" и "Файл5" не будет включена в эту папку. |
| false | mergeFiles | Папка1 Файл1 Файл2 Вложенная_папка1 Файл3 Файл4 Файл5 |
Целевая папка1 создается со следующей структурой: Папка1 Содержимое файлов "Файл1" и "Файл2" объединяется в один файл с автоматически созданным именем. автоматически созданное имя для "Файл1" Папка "Вложенная_папка1" с файлами "Файл3", "Файл4" и "Файл5" не будет включена в эту папку. |
Сохранение метаданных файла во время копирования
При копировании файлов из Amazon S3/BLOB-объекта Azure или Azure Data Lake Storage 2-го поколения в Azure Data Lake Storage 2-го поколения или BLOB-объект Azure можно сохранить метаданные файла вместе с данными. Подробнее см. в разделе Сохранение метаданных.
Сохранение списков управления доступом из Data Lake Storage 1-го поколения/2-го поколения
При копировании файлов из Azure Data Lake Storage 1-го или 2-го поколения в ADLS 2-го поколения можно сохранить списки управления доступом POSIX вместе с данными. Узнайте больше в разделе Сохранение списков управления доступом из Data Lake Storage 1-го или 2-го поколения.
Совет
Пошаговые инструкции и рекомендации по копированию данных из Azure Data Lake Storage 1-го поколения в Azure Data Lake Storage 2-го поколения см. в статье Копирование данных из Azure Data Lake Storage 1-го поколения в Azure Data Lake Storage 2-го поколения с помощью Фабрики данных Azure.
Свойства потока данных для сопоставления
При преобразовании данных в потоках данных для сопоставления считывать и записывать файлы из Azure Data Lake Storage 2-го поколения можно в следующих форматах:
Конкретные параметры приведены в документации для соответствующего формата. Дополнительные сведения см. в статьях Преобразование источника в потоке данных для сопоставления и Преобразование приемника в потоке данных для сопоставления.
Преобразование источника
В преобразовании источника можно выполнять чтение из контейнера, папки или отдельного файла в Azure Data Lake Storage 2-го поколения. Настройки управления чтением файлов находятся на вкладке Параметры источника.
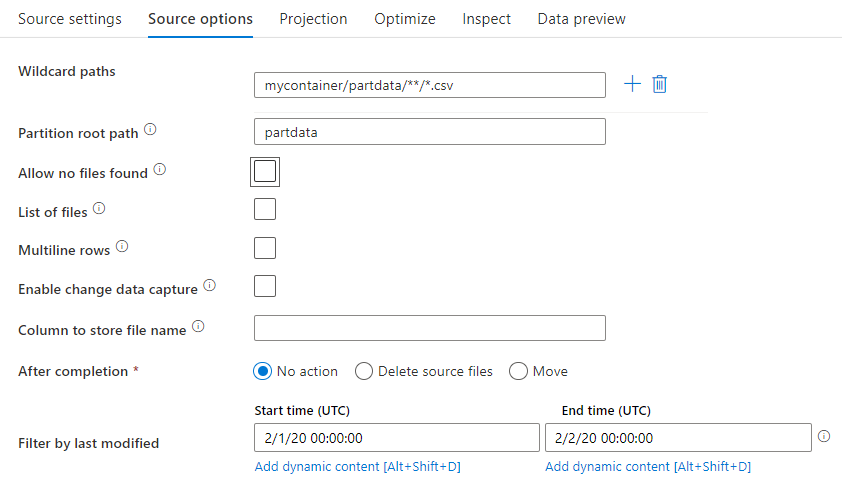
Путь к подстановочным знакам: использование шаблона подстановочного знака указывает ADF выполнять цикл по каждой соответствующей папке и файлу в одном преобразовании источника. Это эффективный способ обработки нескольких файлов в одном потоке. Добавьте несколько шаблонов сопоставления с подстановочными знаками с помощью значка плюса ("+"), который появляется при наведении указателя мыши на существующий шаблон с подстановочными знаками.
В исходном контейнере выберите файлы, соответствующие шаблону. В наборе данных можно указать только контейнер. Путь с подстановочными знаками должен также включать путь к папке из корневой папки.
Примеры подстановочных знаков:
*— представляет любой набор символов;**— представляет рекурсивную вложенность каталога;?— заменяет один символ;[]— соответствует одному или нескольким символам в квадратных скобках;/data/sales/**/*.csv— возвращает все файлы CSV в папке /data/sales;/data/sales/20??/**/— возвращает все файлы, созданные в 20 веке;/data/sales/*/*/*.csv— возвращает файлы CSV, расположенные двумя уровнями ниже папки /data/sales;/data/sales/2004/*/12/[XY]1?.csv— возвращает все файлы CSV, созданные в декабре 2004 года, которые начинаются с X или Y с двузначным числом в качестве префикса.
Корневой путь раздела. Если в источнике файлов имеются секционированные папки формата key=value (например, year=2019), то верхний уровень этого дерева секционированной папки можно назначить в качестве имени столбца в потоке данных.
Во-первых, задайте подстановочный знак, чтобы включить все пути, которые являются в секционированных папках, а также конечные файлы, которые вы хотите прочитать.
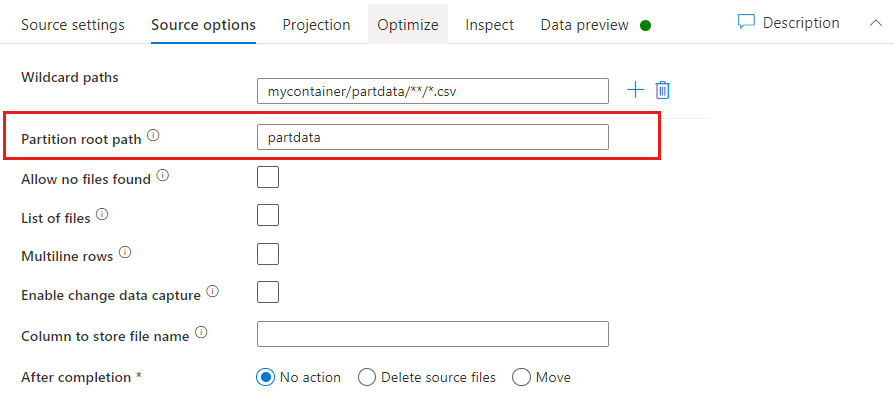
Для определения верхнего уровня структуры папок используйте параметр "Корневой путь раздела". При просмотре содержимого данных с помощью предварительного просмотра данных вы увидите, что ADF добавит разрешенные разделы, найденные на каждом уровне папок.
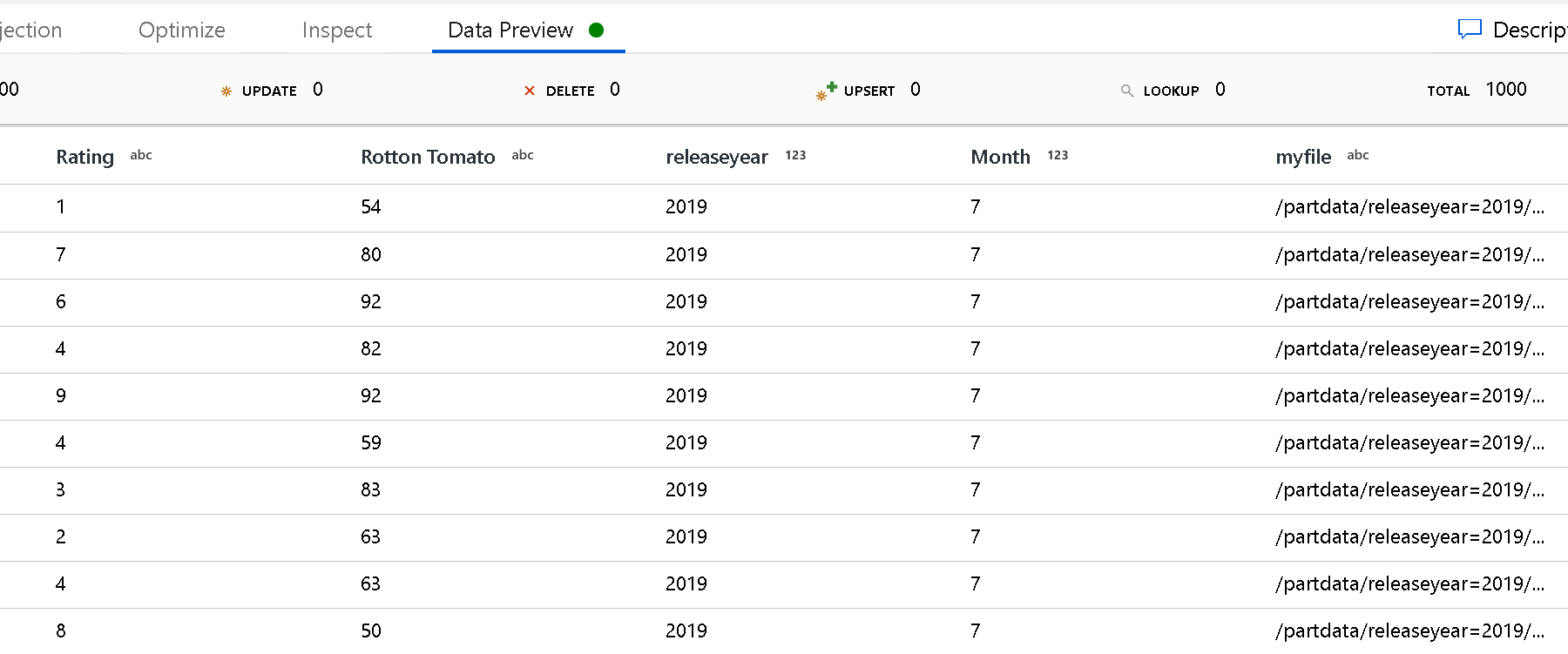
Список файлов: это набор файлов. Создайте текстовый файл, который включает список относительных путей файлов для обработки. Укажите на этот текстовый файл.
Столбец для хранения имени файла: сохраните имя исходного файла в столбце в данных. Укажите здесь новое имя столбца для хранения строки имени файла.
После завершения: выберите ничего делать с исходным файлом после запуска потока данных, удалите исходный файл или переместите исходный файл. Пути для перемещения являются относительными.
Чтобы переместить исходные файлы в другое расположение после обработки, сначала выберите "Переместить" для операции с файлом. Затем задайте исходный каталог. Если вы не используете подстановочные знаки в пути, исходным каталогом будет та же папка, что и исходная папка.
Если у вас есть исходный путь с подстановочным знаком, синтаксис будет выглядеть следующим образом.
/data/sales/20??/**/*.csv
В качестве исходной папки можно указать
/data/sales
В качестве целевой папки можно указать
/backup/priorSales
В этом случае все файлы, источником которых является папка /data/sales, перемещаются в папку /backup/priorSales.
Примечание.
Операции с файлами выполняются только в том случае, если поток данных выполняется из запуска конвейера (отладка конвейера или запуск выполнения) с использованием действия выполнения потока данных в конвейере. Операции с файлами не выполняются в режиме отладки потока данных.
Фильтр по последнему изменению: вы можете фильтровать файлы, обрабатываемые путем указания диапазона дат последнего изменения. Все значения даты и времени указаны в формате UTC.
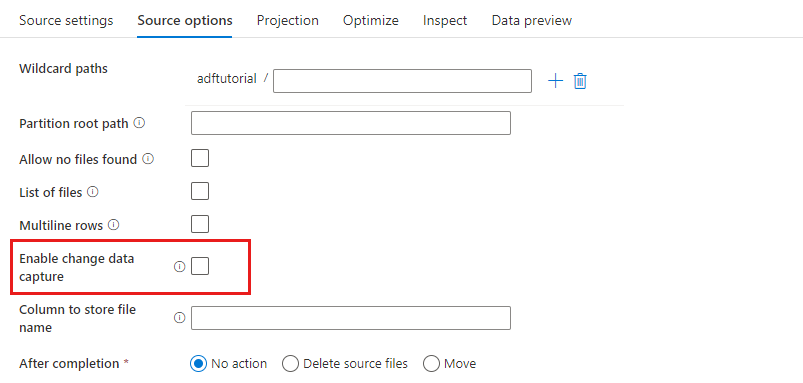
Включить систему отслеживания измененных данных: если здесь указано значение true, будут получены новые или измененные файлы только с момента последнего запуска. При первом запуске всегда выполняется начальная загрузка данных, то есть получается полный моментальный снимок, а при следующих запусках записываются только новые или измененные файлы. Дополнительные сведения см. в разделе Отслеживание измененных данных.
Свойства приемника
В преобразовании приемника можно выполнять запись в контейнер или папку в хранилище Azure Data Lake Storage 2-го поколения. Вкладка "Параметры" позволяет управлять записью файлов.
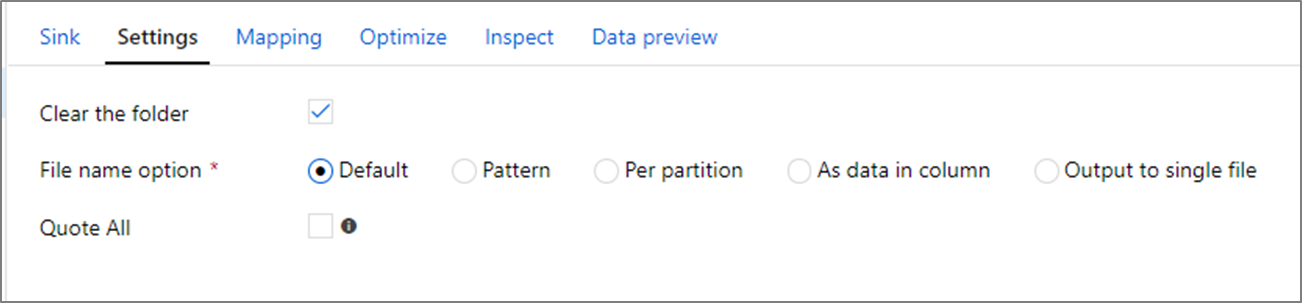
Очистить папку: определяет, очищается ли целевая папка перед записью данных.
Параметр имени файла: определяет, как целевые файлы именуются в целевой папке. Доступные параметры имени файла:
- По умолчанию: разрешить Spark именовать файлы на основе значений ПО умолчанию PART.
- Шаблон. Введите шаблон, который перечисляет выходные файлы на секцию. Например, при использовании шаблона loans[n].csv будут создаваться файлы loans1.csv, loans2.csv и т. д.
- На секцию: введите одно имя файла для каждой секции.
- Как данные в столбце: задайте выходной файл значению столбца. Путь задается относительно контейнера набора данных, а не папки назначения. Если в наборе данных имеется путь к папке, он будет переопределен.
- Выходные данные в один файл: объединение секционированных выходных файлов в один именованный файл. Путь задается относительно папки набора данных. Имейте в виду, что операция слияния может завершиться сбоем в зависимости от размера узла. Этот параметр не рекомендуется использовать для больших наборов данных.
В кавычках все: определяет, следует ли заключать все значения в кавычки
umask
При необходимости можно задать umask для файлов, используя флаги чтения, записи и выполнения POSIX для владельца, пользователя и группы.
Команды предварительной и последующей обработки
При необходимости можно выполнить команды файловой системы Hadoop до или после записи в приемник ADLS 2-го поколения. Поддерживаются следующие команды:
cpmvrmmkdir
Примеры:
mkdir /folder1mkdir -p folder1mv /folder1/*.* /folder2/cp /folder1/file1.txt /folder2rm -r /folder1
Параметры также поддерживаются в построителе выражений, например:
mkdir -p {$tempPath}/commands/c1/c2
mv {$tempPath}/commands/*.* {$tempPath}/commands/c1/c2
По умолчанию папки создаются в корневом каталоге пользователя. Для ссылки на контейнер верхнего уровня используйте "/".
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Свойства действия GetMetadata
Подробные сведения об этих свойствах см. в статье Действие GetMetadata.
Свойства действия удаления
Подробные сведения об этих свойствах см. в статье Действие удаления.
Устаревшие модели
Примечание.
Следующие модели по-прежнему поддерживаются на условиях "как есть" для обеспечения обратной совместимости. Новую модель, упомянутую в разделах выше, рекомендуется использовать в дальнейшем. Пользовательский интерфейс создания ADF был изменен для создания новой модели.
Устаревшая модель набора данных
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для набора данных должно иметь значение AzureBlobFSFile. | Да |
| folderPath | Путь к папке в Azure Data Lake Storage 2-го поколения. Если это свойство не указано, будет использоваться корневая папка. Фильтр подстановочных знаков не поддерживается. Допустимые подстановочные знаки: * (соответствует нулю или нескольким символам) и ? (соответствует нулю или одному символу). Используйте ^ для экранирования знаков, если фактическое имя папки содержит подстановочный знак или этот escape-символ. Примеры: filesystem/folder/. Дополнительные примеры приведены в разделе Примеры фильтров папок и файлов. |
No |
| fileName | Имя или фильтр подстановочных знаков для файлов по указанному folderPath. Если этому свойству не присвоить значение, набор данных будет указывать на все файлы в папке. Допустимые подстановочные знаки для фильтра: * (соответствует нулю или нескольким символам) и ? (соответствует нулю или одному символу).Пример 1. "fileName": "*.csv"Пример 2. "fileName": "???20180427.txt"Используйте ^ для экранирования символов, если фактическое имя файла содержит подстановочный знак или этот escape-символ.Если имя файла не указано для выходного набора данных и сохранитьHierarchy не указано в приемнике действий, действие копирования автоматически создает имя файла со следующим шаблоном: "Data".[ идентификатор GUID выполнения действия]. [GUID, если FlattenHierarchy]. [формат, если настроено]. [сжатие, если настроено]", например "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". При копировании из табличного источника с использованием имени таблицы вместо запроса формат имени будет таким: "[имя таблицы].[фoрмат].[сжатие, если настроено]". Например: "MyTable.csv". |
No |
| modifiedDatetimeStart | Фильтр файлов на основе атрибута времени последнего изменения. Выбираются все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате "2018-12-01T05:00:00Z". Включение этого параметра в случае, если требуется использовать фильтр файлов с огромными объемами файлов, влияет на общую производительность перемещения данных. Свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не применяются к набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения меньше указанного значения даты и времени. |
No |
| modifiedDatetimeEnd | Фильтр файлов на основе атрибута времени последнего изменения. Выбираются все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате "2018-12-01T05:00:00Z". Включение этого параметра в случае, если требуется использовать фильтр файлов с огромными объемами файлов, влияет на общую производительность перемещения данных. Свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не применяются к набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения меньше указанного значения даты и времени. |
No |
| format | Если требуется скопировать файлы между файловыми хранилищами "как есть" (двоичное копирование), можно пропустить раздел форматирования в определениях входного и выходного наборов данных. Если нужно проанализировать или создать файлы определенного формата, поддерживаются следующие типы форматов файлов: TextFormat, JsonFormat, AvroFormat, OrcFormat и ParquetFormat. Свойству type в разделе format необходимо присвоить одно из этих значений. Дополнительные сведения см. в разделах о текстовом формате, формате JSON, формате Avro, формате ORC и формате Parquet. |
Нет (только для сценария двоичного копирования) |
| compression | Укажите тип и уровень сжатия данных. Дополнительные сведения см. в разделе Поддержка сжатия. Поддерживаемые типы: **GZip**, **Deflate**, **BZip2**, and **ZipDeflate**.Поддерживаемые уровни: Optimal и Fastest. |
No |
Совет
Чтобы скопировать все файлы в папке, укажите только folderPath.
Чтобы скопировать один файл с заданным именем, укажите folderPath с путем к папке и fileName с именем файла.
Чтобы скопировать подмножество файлов в папке, укажите folderPath с частью папки и fileName с фильтром подстановочных знаков.
Пример:
{
"name": "ADLSGen2Dataset",
"properties": {
"type": "AzureBlobFSFile",
"linkedServiceName": {
"referenceName": "<Azure Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "myfilesystem/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Устаревшая модель источника действия копирования
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение AzureBlobFSSource. | Да |
| recursive | Указывает, следует ли читать данные рекурсивно из вложенных папок или только из указанной папки. Если для свойства recursive задано значение true, а приемником является файловое хранилище, то пустые папки и вложенные папки в приемнике не создаются. Допустимые значения: true (по умолчанию) и false. |
No |
| maxConcurrentConnections | Верхний предел одновременных подключений, установленных для хранилища данных при выполнении действия. Указывайте значение только при необходимости ограничить количество одновременных подключений. | No |
Пример:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen2 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureBlobFSSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Устаревшая модель приемника действия копирования
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type приемника действия копирования должно иметь значение AzureBlobFSSink. | Да |
| copyBehavior | Определяет поведение копирования, когда источником являются файлы из файлового хранилища данных. Допустимые значения: — PreserveHierarchy (по умолчанию). Сохраняет иерархию файлов в целевой папке. Относительный путь исходного файла в исходной папке идентичен относительному пути целевого файла в целевой папке. — FlattenHierarchy. Все файлы из исходной папки размещаются на первом уровне в целевой папке. Целевые файлы имеют автоматически сформированные имена. — MergeFiles. Объединяет все файлы из исходной папки в один файл. Если указано имя файла, то оно присваивается объединенному файлу. В противном случае присваивается автоматически созданное имя файла. |
No |
| maxConcurrentConnections | Верхний предел одновременных подключений, установленных для хранилища данных при выполнении действия. Указывайте значение только при необходимости ограничить количество одновременных подключений. | No |
Пример:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen2 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureBlobFSSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
система отслеживания измененных данных
Фабрика данных Azure может получать новые или измененные файлы только из Azure Data Lake Storage 2-го поколения, если включен параметр Включить отслеживание измененных данных в преобразовании источника потока данных для сопоставления. Этот параметр соединителя позволяет считывать только новые или обновленные файлы и применять преобразования перед загрузкой преобразованных данных в нужные целевые наборы.
Ни в коем случае не изменяйте имена конвейера и действия, чтобы контрольная точка последнего запуска всегда была доступна для анализа и получения изменений. Если вы измените имя конвейера или действия, контрольная точка будет сброшена и следующий запуск начнет весь процесс с начала.
При отладке конвейера также можно использовать параметр Включить отслеживание измененных данных. Имейте в виду, что при обновлении страницы в браузере во время отладки контрольная точка будет сброшена. Когда вы будете довольны результатами отладки, можно будет опубликовать и запустить конвейер. Выполнение всегда начинается с начала, даже если при запуске отладки была создана контрольная точка.
При необходимости вы можете повторно запустить конвейер из раздела мониторинга. Этот процесс всегда извлекает изменения с момента контрольной точки, записанной в выбранном запуске конвейера.
Связанный контент
Список хранилищ данных, поддерживаемых в рамках функции копирования в качестве источников и приемников, см. в разделе Поддерживаемые хранилища данных.