Преобразование «Сведение» в потоке данных для сопоставления
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
Используйте преобразование «Сведение», чтобы создать несколько столбцов из уникальных значений строк одного столбца. «Сведение» — это преобразование статистической обработки, с группировкой по столбцам и созданием столбцов сведения с помощью агрегатных функций.
Настройка
Преобразование «Сведение» требует трех различных входных данных: группировки по столбцам, ключа сведения и способа создания сведенных столбцов.
Группировать по
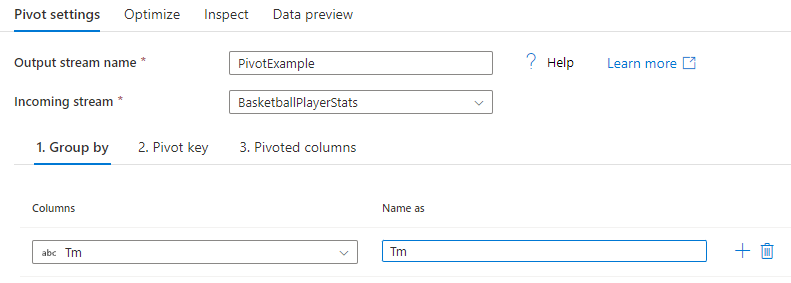
Выберите столбцы для статистической обработки сведенных столбцов. Выходные данные будут группировать все строки с одинаковыми значениями «группировать по» в одну строку. Статистическая обработка, выполненная в сведенном столбце, будет выполняться для каждой группы.
Это необязательный раздел. Если не выбрано столбцов для «группировать по», то весь поток данных будет обработан и будет выведена только одна строка.
Ключ сведения
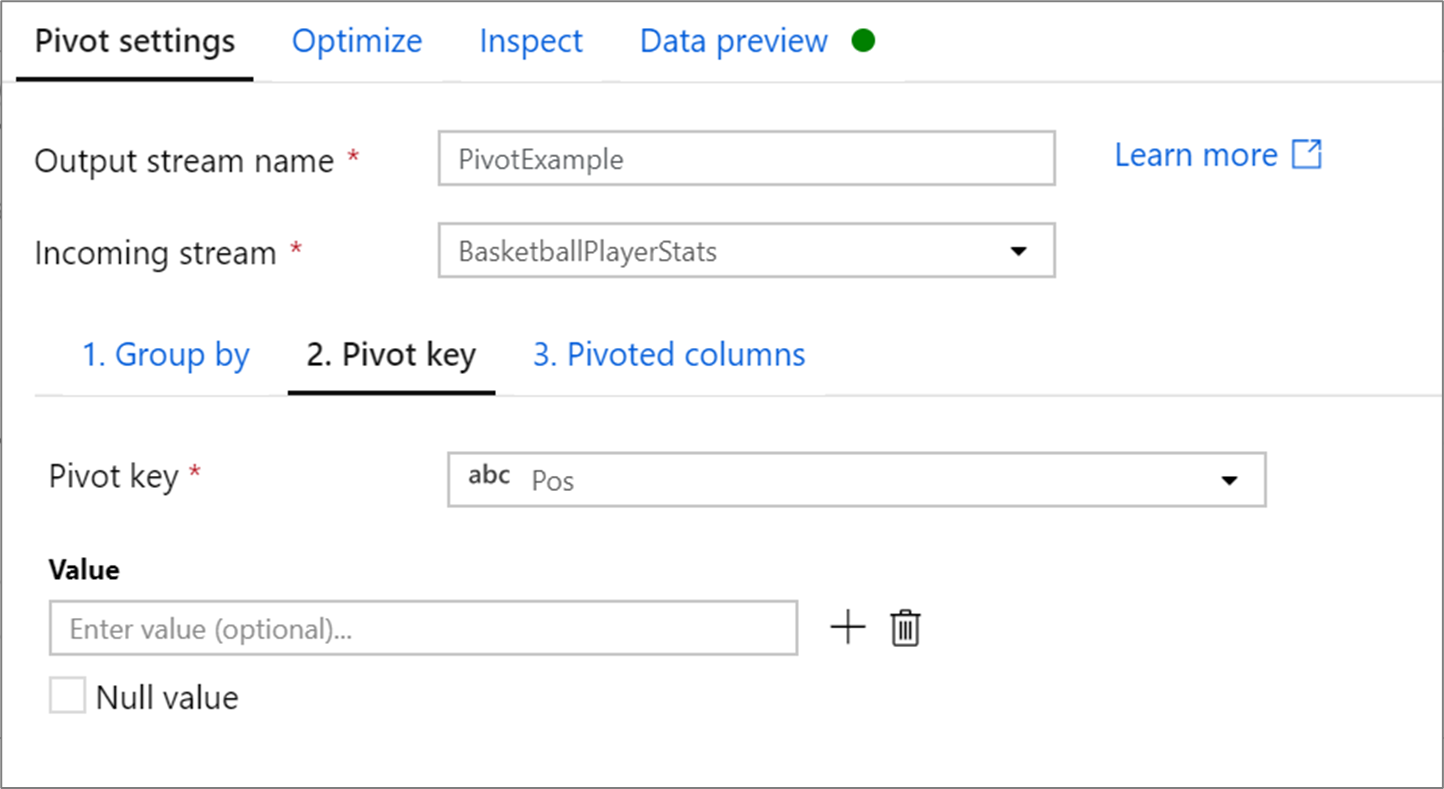
Ключ сведения — это столбец, значения строк которого сводятся в новые столбцы. По умолчанию преобразование «Сведение» создает новый столбец для каждого уникального значения строки.
В разделе Значениеможно ввести конкретные значения строк, которые следует свести. Будут сведены только значения строк, указанные в этом разделе. Включение Значение NULL создаст сводный столбец для значений NULL в столбце.
Сведенные столбцы
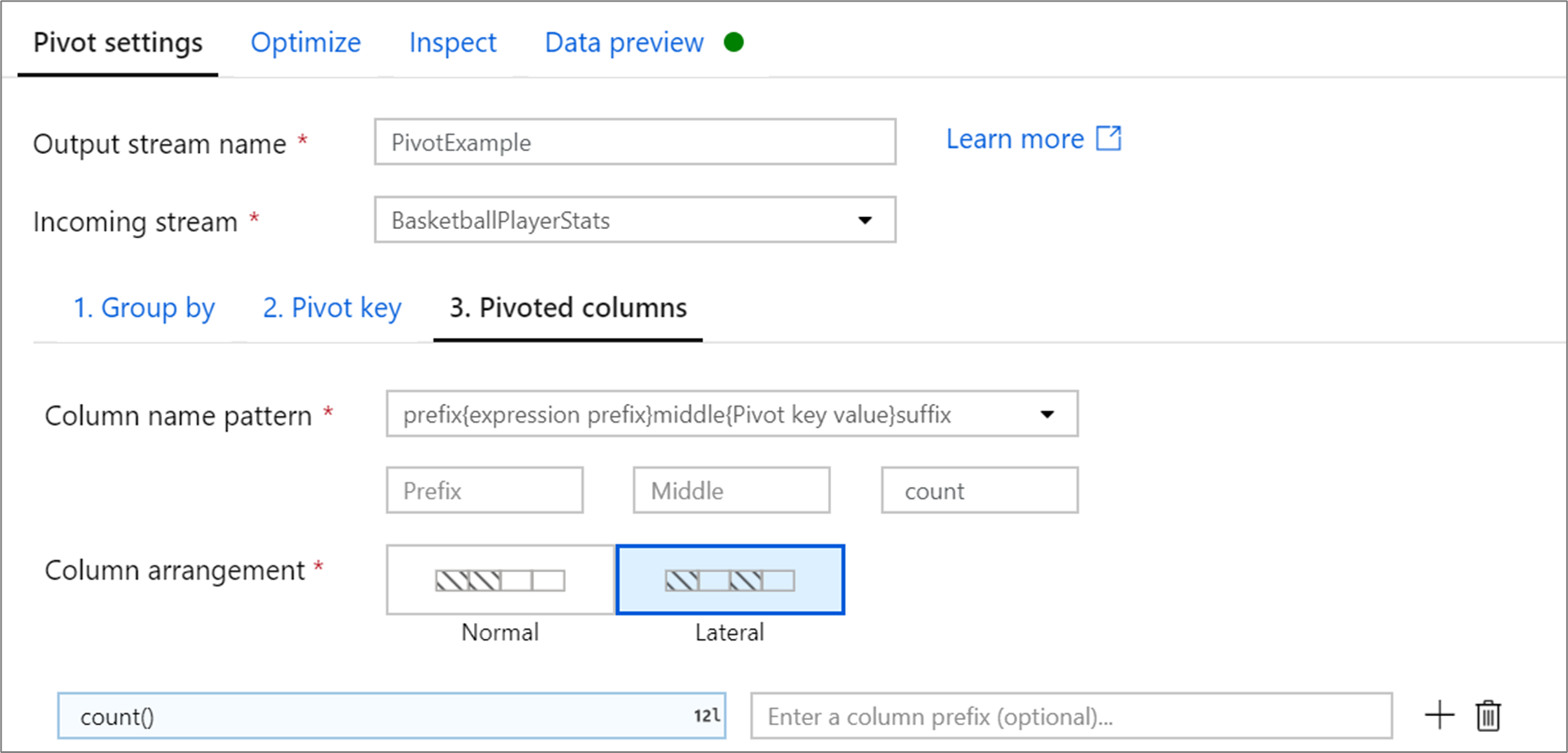
Для каждого уникального значения ключа сведения, которое преобразуется в столбец, формируется вычисленное значение строки для каждой группы. Можно создать несколько столбцов для каждого ключа сведения. Каждый столбец сведения должен содержать по крайней мере одну агрегатную функцию.
Шаблон имени столбца: выберите форматирование имени столбца для каждого столбца сводной таблицы. Имя выходного столбца будет сочетанием значения ключа сводной таблицы, префикса столбца и необязательного префикса, суффикса, среднего символа.
Расположение столбцов: если вы создаете несколько столбцов сводной таблицы на ключ сводной таблицы, выберите способ упорядочения столбцов.
Префикс столбца: при создании нескольких столбцов сводной таблицы на ключ сводной таблицы введите префикс столбца для каждого столбца. Этот параметр является необязательным, если имеется только один сведенный столбец.
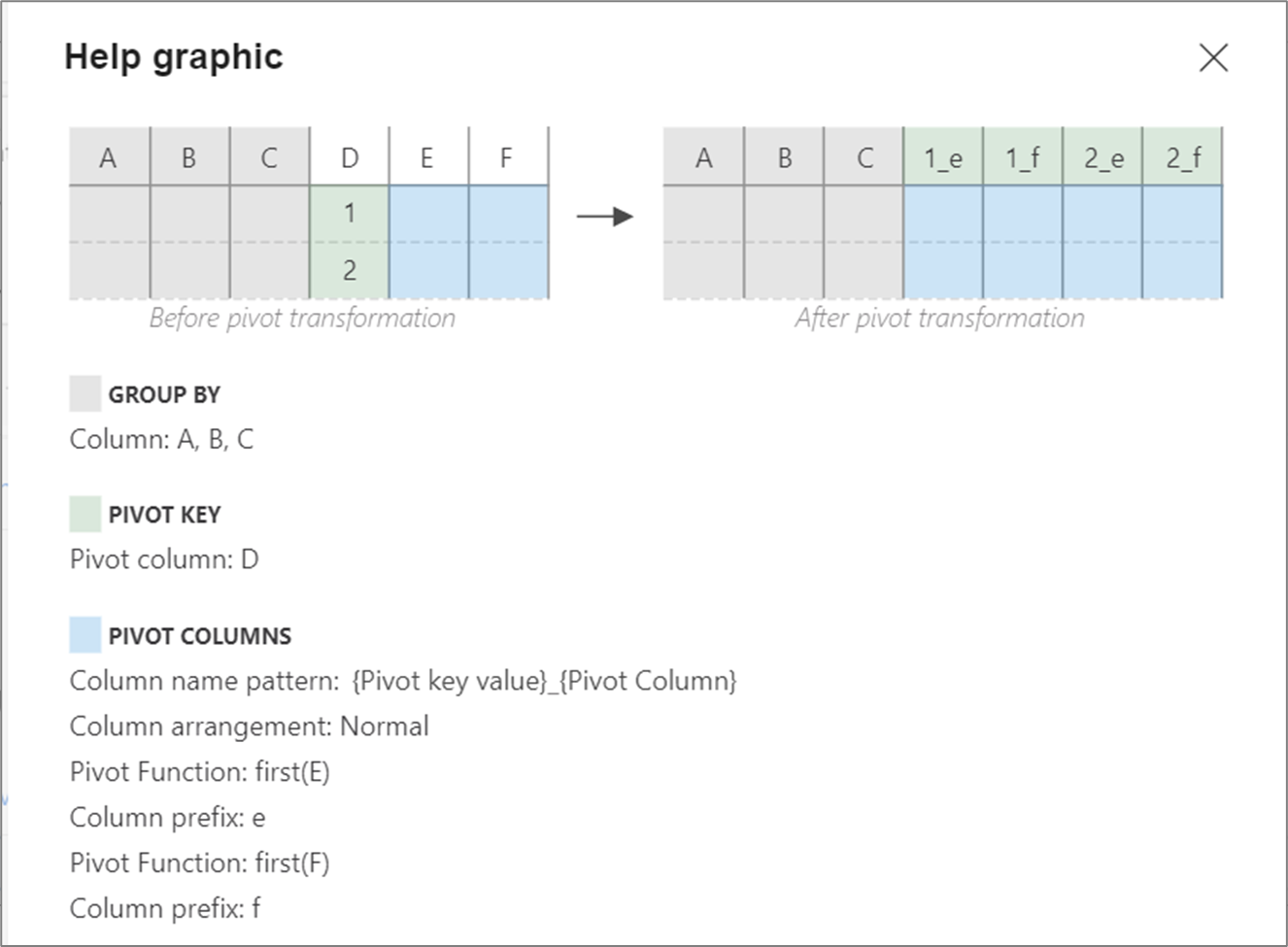
Рисунок справки
На приведенном ниже рисунке справки показано, как различные компоненты сводной таблицы взаимодействуют друг с другом.
Метаданные сведения
Если в конфигурации ключа сведения не указаны значения, сводные столбцы будут динамически создаваться во время выполнения. Число сведенных столбцов будет равным числу уникальных значений ключа сведения, умноженному на число столбцов сведения. Так как это может быть меняющееся число, пользовательский интерфейс не будет отображать метаданные столбца на вкладке Проверить и не будет распространять столбец. Чтобы преобразовать эти столбцы, используйте возможности шаблона столбца потока данных для сопоставления.
Если заданы конкретные значения ключа сведения, то в метаданных отобразятся сведенные столбцы. Имена столбцов будут доступны в сопоставлениях «Проверка» и «Приемник».
Создание метаданных из смещенных столбцов
Сведение динамически создает имена новых столбцов на основе значений строк. Эти новые столбцы можно добавить в метаданные, на которым можно будет ссылаться далее в потоке данных. Для этого используйте быстрое действие сопоставить смещенные в предварительной версии данных.
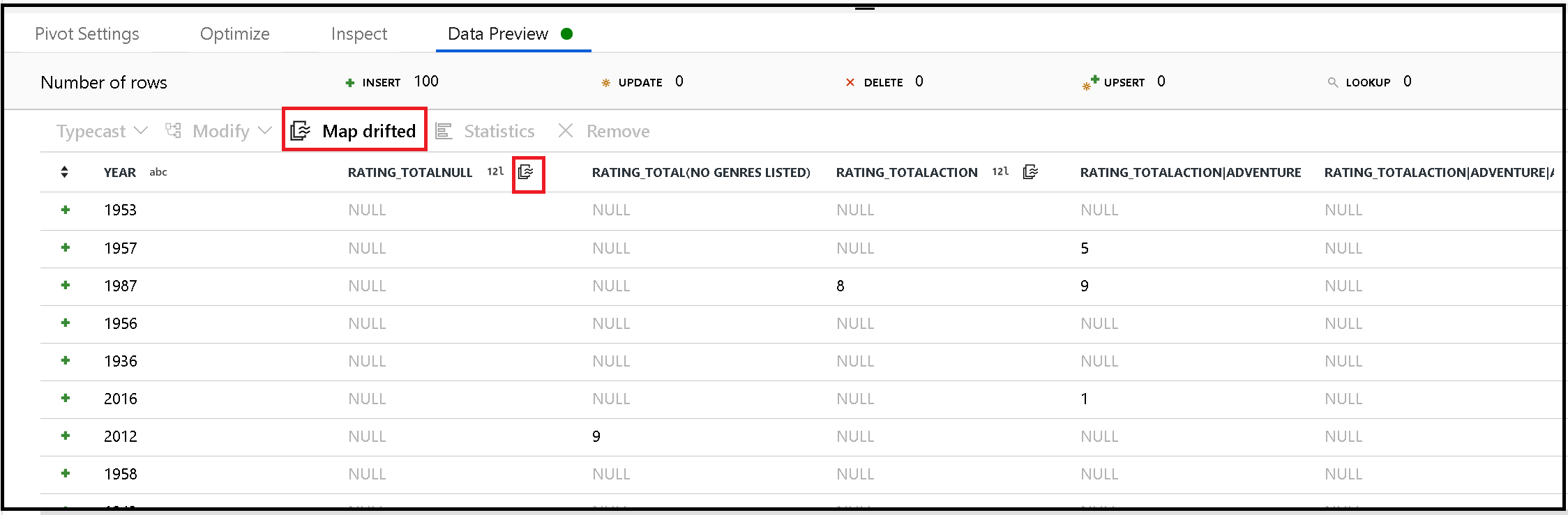
Прием сведенных столбцов
Хотя сведенные столбцы являются динамическими, они все же могут быть записаны в целевое хранилище данных. Включите Разрешить смещение схемы в параметрах приемника. Это позволит создавать столбцы, не включаемые в метаданные. Новые динамические имена не будут отображаться в метаданных столбца, но параметр «смещение схемы» позволит разместить данные.
Повторное присоединение исходных полей
Преобразование «Сведение» будет проецировать только «группировать по» и сведенные столбцы. Если вы хотите, чтобы выходные данные включали другие входные столбцы, используйте шаблон самосоединение.
Скрипт потока данных
Синтаксис
<incomingStreamName>
pivot(groupBy(Tm),
pivotBy(<pivotKeyColumn, [<specifiedColumnName1>,...,<specifiedColumnNameN>]),
<pivotColumnPrefix> = <pivotedColumnValue>,
columnNaming: '< prefix >< $N | $V ><middle >< $N | $V >< suffix >',
lateral: { 'true' | 'false'}
) ~> <pivotTransformationName
Пример
Экраны, показанные в разделе конфигурации, имеют следующий сценарий потока данных:
BasketballPlayerStats pivot(groupBy(Tm),
pivotBy(Pos),
{} = count(),
columnNaming: '$V$N count',
lateral: true) ~> PivotExample
Связанный контент
Попробуйте использовать преобразование «Отмена сведения», чтобы преобразовать значения столбцов в значения строк.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по