Загрузка данных в Azure Data Lake Storage 2-го поколения с помощью Фабрики данных Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Azure Data Lake Storage 2-го поколения — это набор возможностей аналитики больших данных, созданных на основе хранилища BLOB-объектов Azure. Она позволяет работать с данными с использованием как файловой системы, так и парадигмы хранения объектов.
Фабрика данных Azure (ADF) — это полностью управляемая облачная служба интеграции данных. Эту службу можно использовать для заполнения озера данными из богатого набора локальных и облачных хранилищ данных и экономии времени при создании аналитических решений. Дополнительные сведения о поддерживаемых соединителях, см. в таблице Поддерживаемые хранилища данных и форматы.
Фабрика данных Azure предлагает масштабируемое и управляемое решение для перемещения данных. Благодаря архитектуре горизонтального масштабирования ADF, фабрика данных Azure может использовать высокую пропускную способность для приема данных. Дополнительные сведения см. в руководстве по настройке производительности действия копирования.
В этой статье показано, как с помощью средства копирования данных службы "Фабрика данных" загружать данные из службы Amazon Web Services S3 в Azure Data Lake Storage Gen2. Чтобы копировать данные из других типов хранилищ, необходимо выполнить аналогичные шаги.
Совет
См. дополнительные сведения о копировании данных из Azure Data Lake Storage 1-го поколения в Azure Data Lake Storage 2-го поколения.
Необходимые компоненты
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу.
- Учетная запись службы хранилища Azure с включенным хранилищем Azure Data Lake Storage 2-го поколения. Если у вас еще нет учетной записи службы хранилища, создайте ее, щелкнув здесь.
- Учетная запись AWS с контейнером S3, в котором содержатся данные. В этой статье показано, как скопировать данные из Amazon S3. Вы можете использовать другие хранилища данных, выполнив аналогичные действия.
Создание фабрики данных
Если вы еще не создали фабрику данных, выполните действия, описанные в кратком руководстве по созданию фабрики данных с помощью портала Azure и студии Фабрики данных Azure. После создания перейдите к фабрике данных на портале Azure.

Выберите Открыть на плитке Открыть Azure Data Factory Studio, чтобы запустить приложение интеграции данных в отдельной вкладке.
Загрузка данных в Azure Data Lake Storage 2-го поколения
На домашней странице Фабрики данных Azure выберите команду Принять, чтобы запустить средство копирования данных.
На странице Свойства в разделе Тип задачи выберите Встроенная задача копирования. Затем в разделе Периодичность или расписание задач выберите Запустить сейчас один раз, после чего щелкните Далее.
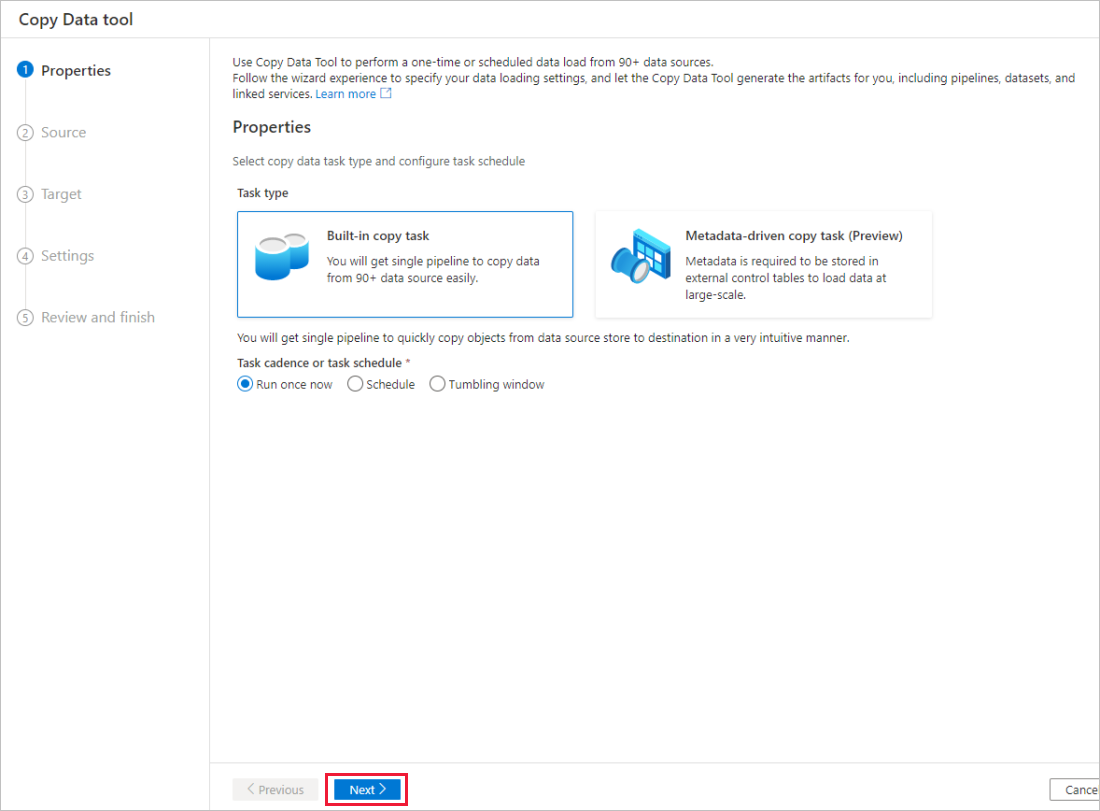
На странице Исходное хранилище данных сделайте следующее.
Выберите + Новое подключение. В галереи соединителя выберите Amazon S3 и нажмите кнопку Продолжить.

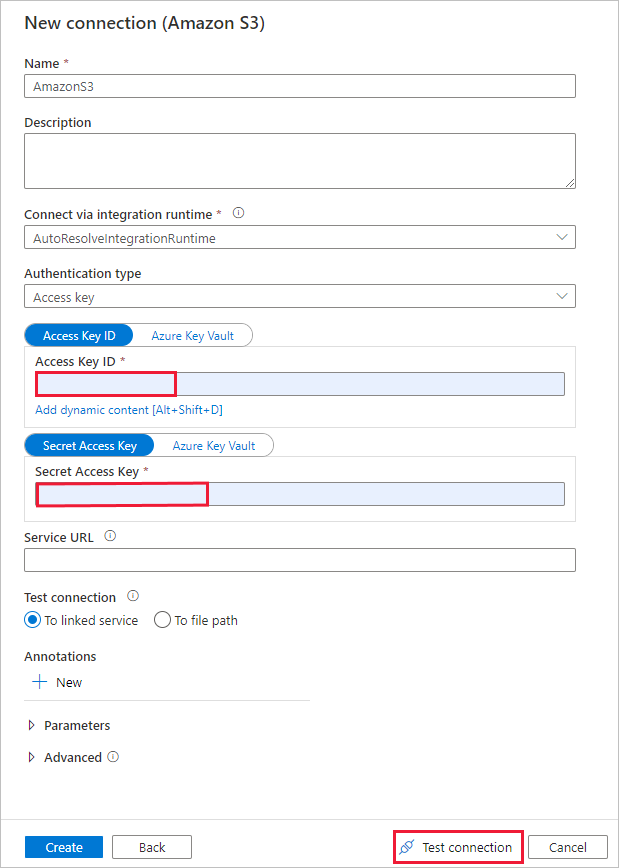
На странице Новое подключение (Amazon S3) выполните указанные ниже действия.
- Укажите идентификатор ключа доступа.
- Укажите секретный ключ доступа.
- Выберите Проверить подключение, чтобы проверить настройки, а затем нажмите Создать.
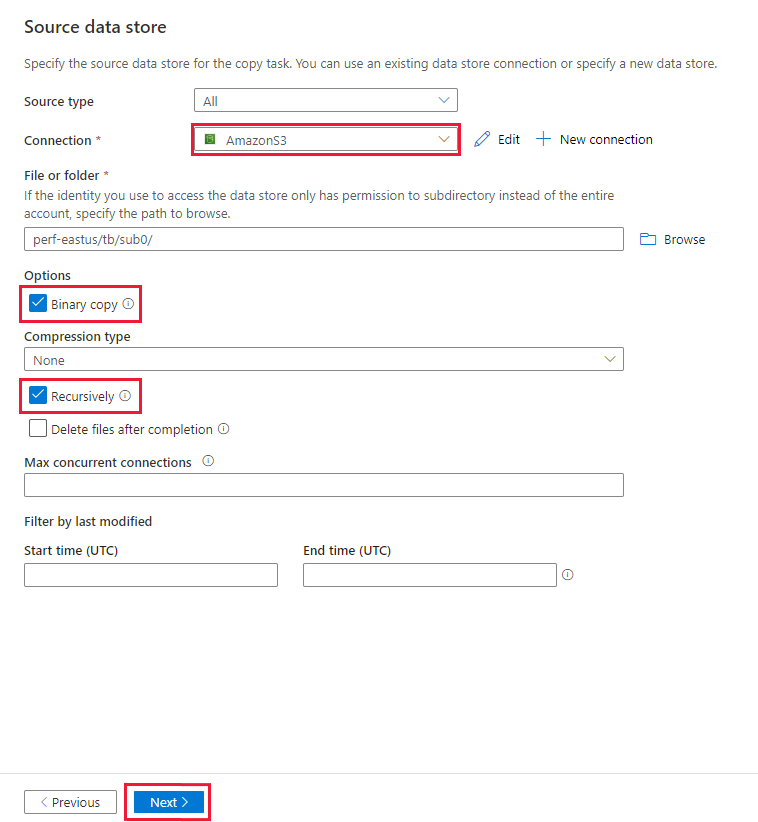
На странице Исходное хранилище данных убедитесь, что в блоке Подключение выбрано только что созданное подключение Amazon S3.
В разделе Файл или папка найдите папку и файл, которые необходимо скопировать. Выберите папку или файл и нажмите кнопку ОК.
Укажите поведение копирования, установив параметры Рекурсивное копирование и Двоичное копирование. Выберите Далее.
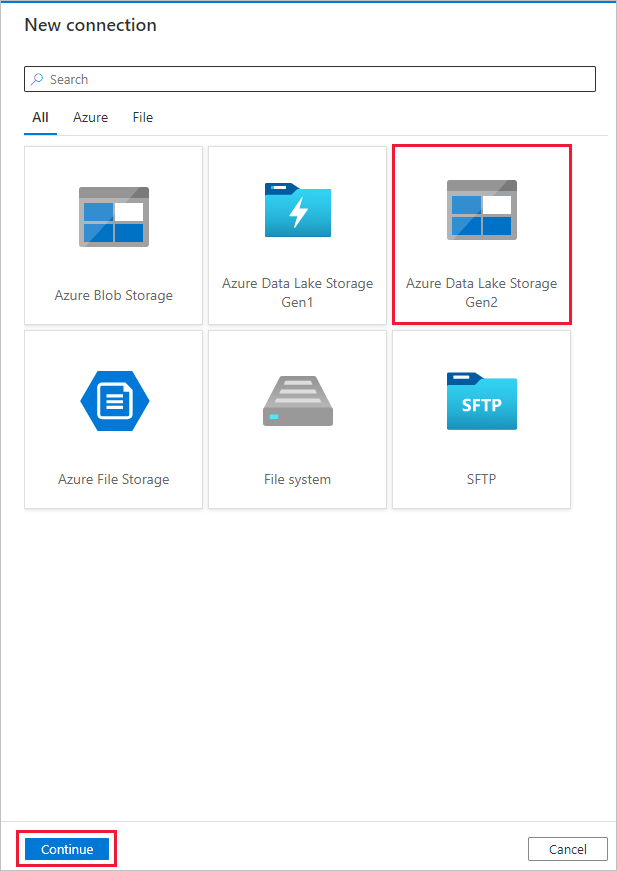
На странице Целевое хранилище данных выполните указанные ниже действия.
На странице + Создать подключение выберите Data Lake Storage 2-го поколения, а затем нажмите кнопку Продолжить.
На странице Новое подключение (Azure Data Lake Storage 2-го поколения) выберите свою учетную запись с поддержкой Data Lake Storage 2-го поколения из раскрывающегося списка "Имя учетной записи службы хранилища" и нажмите кнопку Создать, чтобы создать подключение.
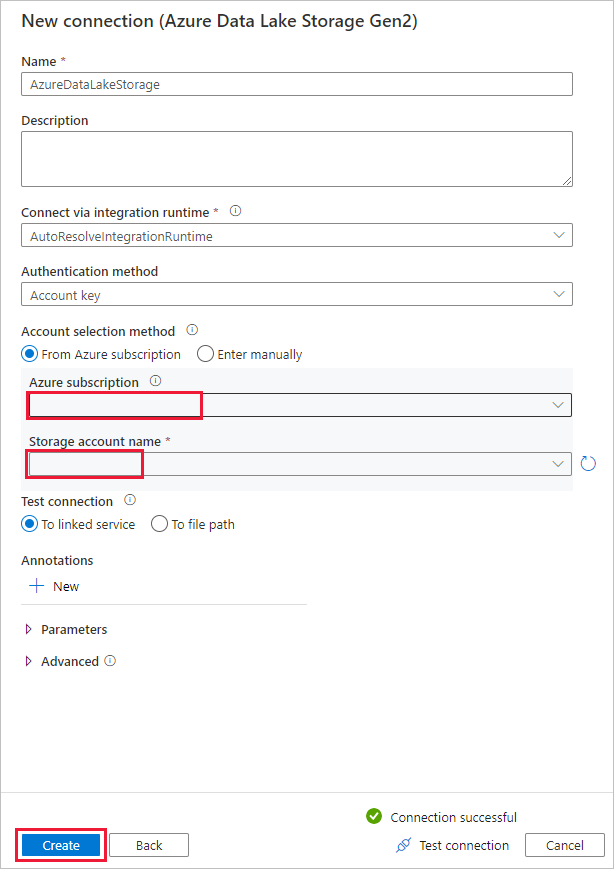
На странице Целевое хранилище данных выберите только что созданное подключение в блоке Подключение. В разделе Путь к папке введите copyfroms3 в качестве имени папки с выходными данными, а затем выберите Далее. ADF создаст при копировании соответствующую файловую систему ADLS 2-го поколения и вложенные папки, если они не существуют.
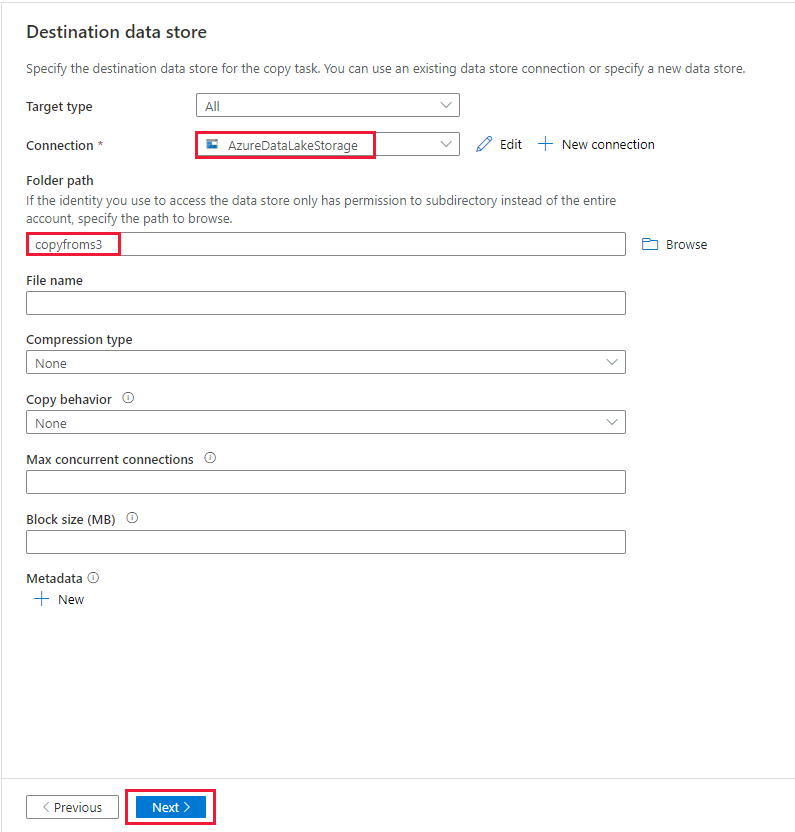
На странице Параметры укажите CopyFromAmazonS3ToADLS в поле Имя задачи, а затем выберите Далее, чтобы использовать настройки по умолчанию.
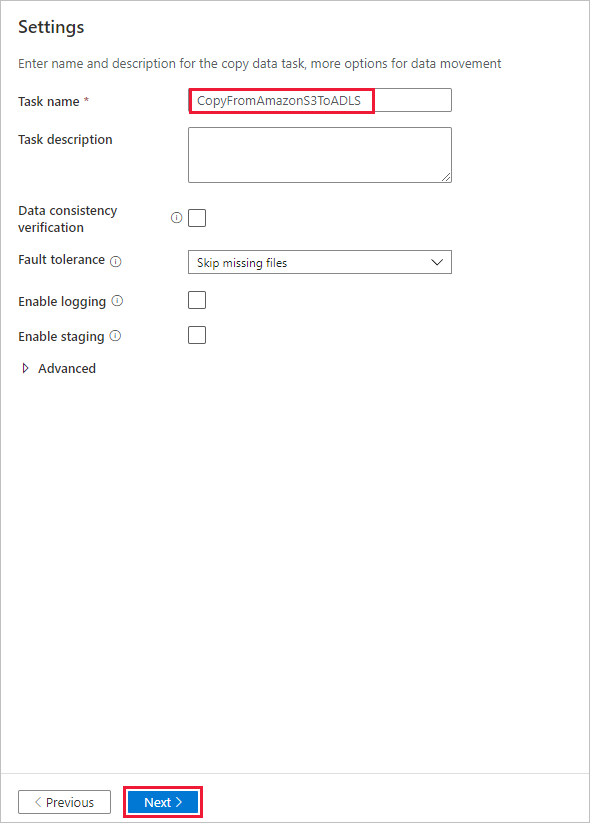
На странице Сводка проверьте параметры и нажмите кнопку Далее.
На странице Развертывание выберите Мониторинг, чтобы отслеживать созданный конвейер (задачу).
После успешного выполнения конвейера вы увидите запуск конвейера, который активируется ручным триггером. Ссылки в столбце Имя конвейера позволят просмотреть подробные сведения о действиях и повторно выполнить конвейер.
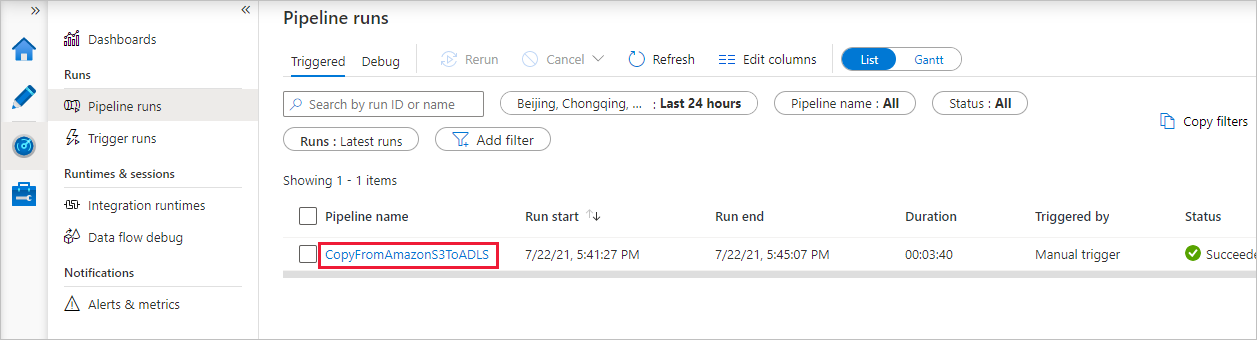
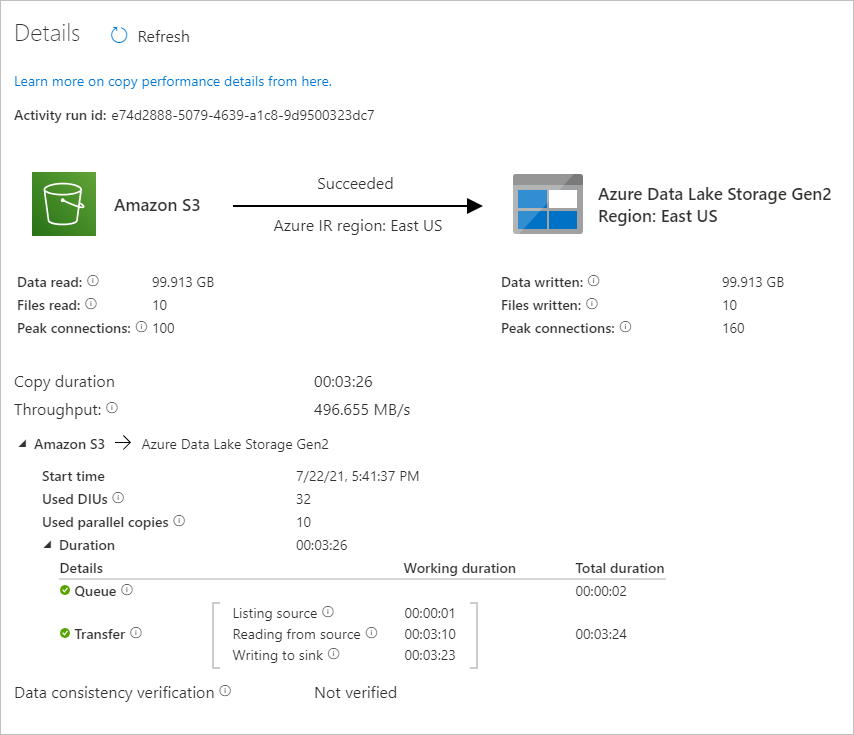
Чтобы просмотреть выполнение действий, связанных с выполнением конвейера, выберите ссылку CopyFromAmazonS3ToADLS в столбце Имя конвейера. Чтобы увидеть сведения об операции копирования, щелкните ссылку Сведения (значок очков) в столбце Название действия. Вы можете отслеживать такие сведения, как объем данных, копируемых из источника в приемник, пропускная способность данных, шаги выполнения с длительностью и используемые параметры.
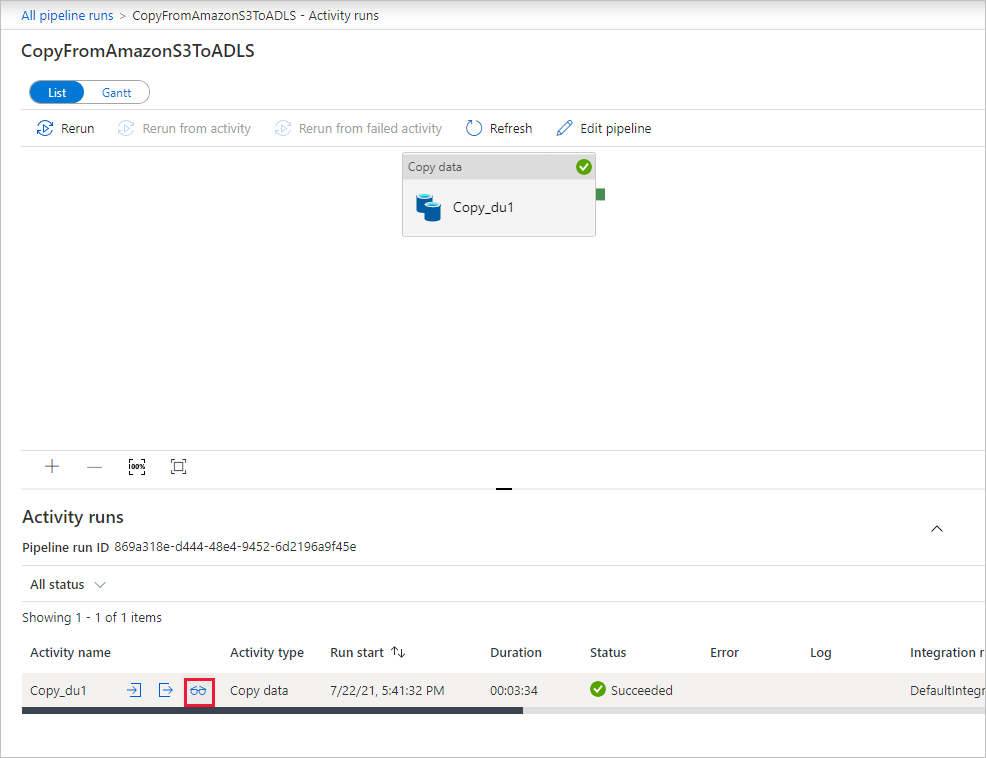
Чтобы обновить список, нажмите кнопку Обновить. Выберите Все выполнения конвейеров в верхней части окна, чтобы вернуться к представлению "Выполнения конвейеров".
Убедитесь, что данные скопированы в Data Lake Storage Gen2.
Связанный контент
- Общие сведения о действии копирования
- Copy data to or from Azure Data Lake Storage Gen2 Preview using Azure Data Factory (Preview) (Копирование данных в Azure Data Lake Storage Gen2 (предварительная версия) или из него с помощью фабрики данных Azure)
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по