Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Если вы еще не работали с фабрикой данных Azure, ознакомьтесь со статьей Введение в фабрику данных Azure.
В этом руководстве вы используете холст потока данных для создания потоков данных, которые позволяют анализировать и преобразовывать данные в Azure Data Lake Storage (ADLS) 2-го поколения и хранить их в Delta Lake.
Предварительные требования
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure, прежде чем начинать работу.
- Учетная запись хранения Azure. Хранилище ADLS используется в качестве хранилища данных источника и приемника. Если у вас нет учетной записи хранения, создайте ее, следуя действиям в этом разделе.
Файл, который мы преобразуем в этом руководстве, MoviesDB.csv, который можно найти здесь. Чтобы извлечь файл из GitHub, скопируйте его содержимое в любой текстовый редактор, а затем сохраните его на локальном компьютере в виде CSV-файла. Чтобы загрузить файл в ваше хранилище, см. Отправка BLOB-объектов с помощью портала Azure. Примеры ссылаются на контейнер с именем sample-data.
Создание фабрики данных
На этом этапе вы создадите фабрику данных и откроете пользовательский интерфейс службы "Фабрика данных" для создания конвейера в фабрике данных.
Откройте Microsoft Edge или Google Chrome. Сейчас пользовательский интерфейс Фабрики данных поддерживают только браузеры Microsoft Edge и Google Chrome.
В меню слева последовательно выберите элементы Создать ресурс>Интеграция>Фабрика данных.
На странице Новая фабрика данных в поле Имя введите ADFTutorialDataFactory.
Выберите подписку Azure, в рамках которой вы хотите создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий:
a. Выберите Использовать существующуюи укажите существующую группу ресурсов в раскрывающемся списке.
б. Выберите Создать новуюи укажите имя группы ресурсов.
Чтобы узнать о группах ресурсов, см. статью Использование групп ресурсов для управления ресурсами Azure.
В качестве версии выберите V2.
В поле Расположение выберите расположение фабрики данных. В раскрывающемся списке отображаются только поддерживаемые местоположения. Хранилища данных (например, служба хранилища Azure и База данных SQL) и вычислительные ресурсы (например, Azure HDInsight), используемые фабрикой данных, могут располагаться в других регионах.
Нажмите кнопку создания.
После завершения создания вы увидите уведомление в центре уведомлений. Нажмите кнопку Перейти к ресурсу, чтобы открыть страницу фабрики данных.
Выберите Автор и монитор, чтобы запустить пользовательский интерфейс фабрики данных на отдельной вкладке.
Создайте конвейер с действием потока данных
На этом шаге вы создаете конвейер, содержащий действие потока данных.
На домашней странице выберите Orchestrate.
На вкладке Общие для конвейера введите DeltaLake в качестве имени конвейера.
В области Действия разверните аккордеон Перемещение и преобразование. Перетащите активность Поток данных из панели инструментов на холст конвейера.
На верхней панели холста конвейера включите ползунок Отладка потока данных. Режим отладки позволяет в интерактивном режиме тестировать логику преобразования в динамическом кластере Spark. Подготовка кластеров Потоков данных занимает 5–7 минут, поэтому пользователям рекомендуем сначала включить отладку, если планируется разработка Потока данных. Дополнительные сведения см. в статье Режим отладки.
Встраивание логики преобразования в холст потока данных
Вы создаете два потока данных в этом руководстве. Первый поток данных — это простой источник для приемника для создания нового Delta Lake из CSV-файла фильмов. Наконец, вы создадите схему потока, которая следует за обновлением данных в Delta Lake.

Цели руководства
- Используйте источник набора данных MoviesCSV из предварительных требований и создайте новое Delta Lake из него.
- Создайте логику для обновления рейтингов фильмов 1988 года до 1.
- Удалите все фильмы, начиная с 1950 года.
- Вставьте новые фильмы для 2021 года путем копирования фильмов из 1960 года.
Начните с чистого холста для потока данных
Выберите преобразование источника в верхней части окна редактора потока данных и нажмите кнопку +Создать рядом со свойством набора данных в окне параметров источника:
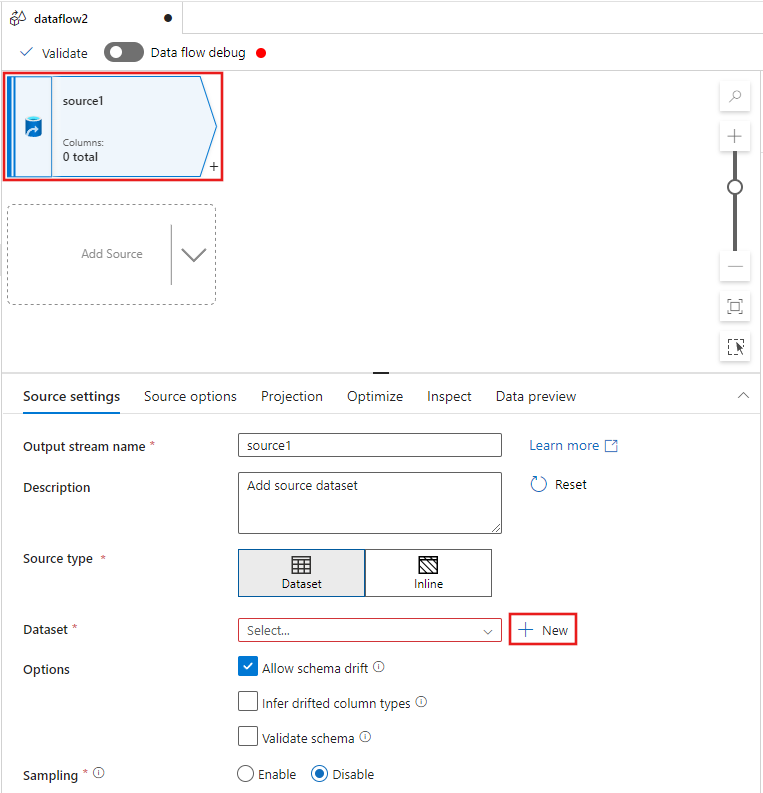
Выберите Azure Data Lake Storage 2-го поколения в появившемся окне нового набора данных и нажмите кнопку "Продолжить".
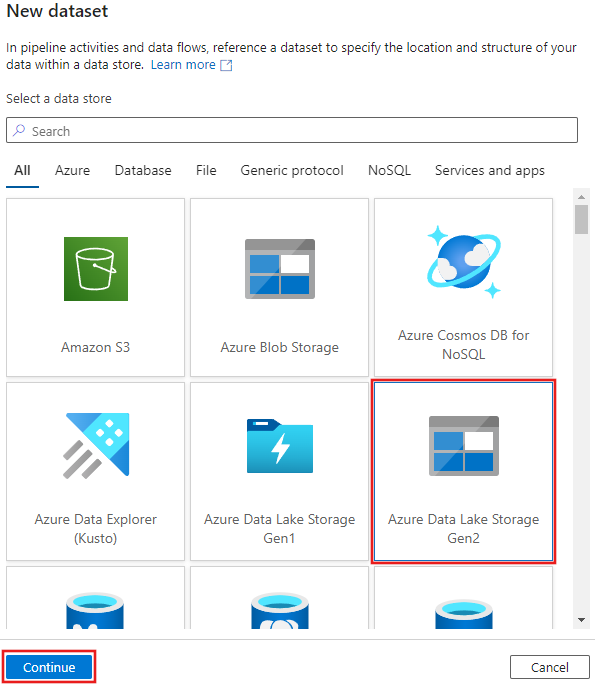
Выберите Текст с разделителями для типа набора данных и выберите Продолжить снова.

Присвойте набору данных название "MoviesCSV" и выберите + Новый в разделе Связанная служба, чтобы создать новую связанную службу для файла.
Укажите сведения о учетной записи хранения, созданной ранее в разделе предварительных требований, и перейдите к файлу MoviesCSV, который вы добавили туда.
После добавления связанной службы установите флажок "Первая строка" в качестве заголовка , а затем нажмите кнопку "ОК ", чтобы добавить источник.
Перейдите на вкладку "Проекция " окна параметров потока данных и выберите " Определить типы данных".
Теперь выберите + после источника в окне редактора потока данных и прокрутите вниз, чтобы выбрать приемникв разделе "Назначение ", добавив новый приемник в поток данных.
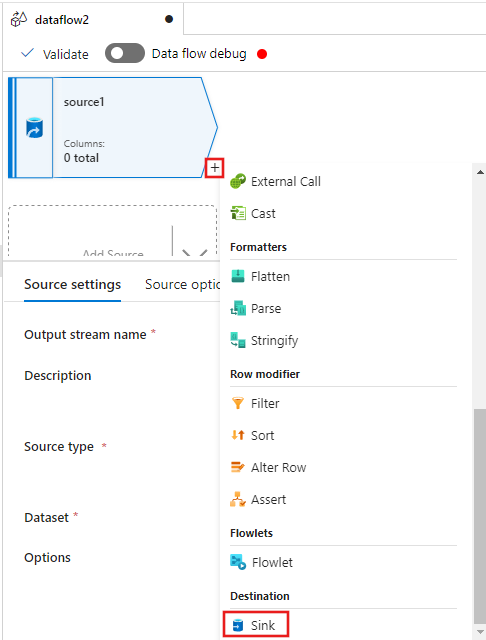
На вкладке "Приемник" для параметров приемника, отображаемых после добавления приемника, выберите Inline для типа приемника, а затем Delta для типа встроенного набора данных. Затем выберите Azure Data Lake Storage 2-го поколения для связанной службы.
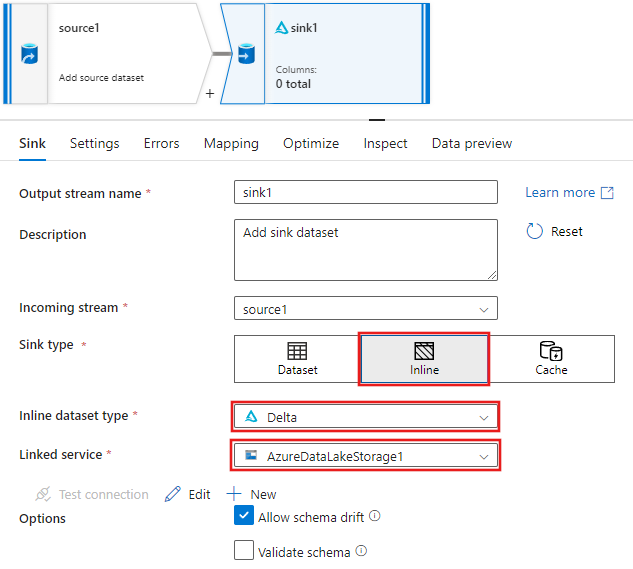
Выберите имя папки в контейнере хранилища, где служба должна создать Delta Lake.
Наконец, вернитесь к конструктору конвейера и выберите Отладка, чтобы выполнить конвейер в режиме отладки только с этой активностью потока данных на холсте. Это создает новое Delta Lake в хранилище данных Azure Data Lake 2-го поколения.
Теперь в меню "Ресурсы фабрики" слева от экрана выберите + , чтобы добавить новый ресурс, а затем выберите поток данных.
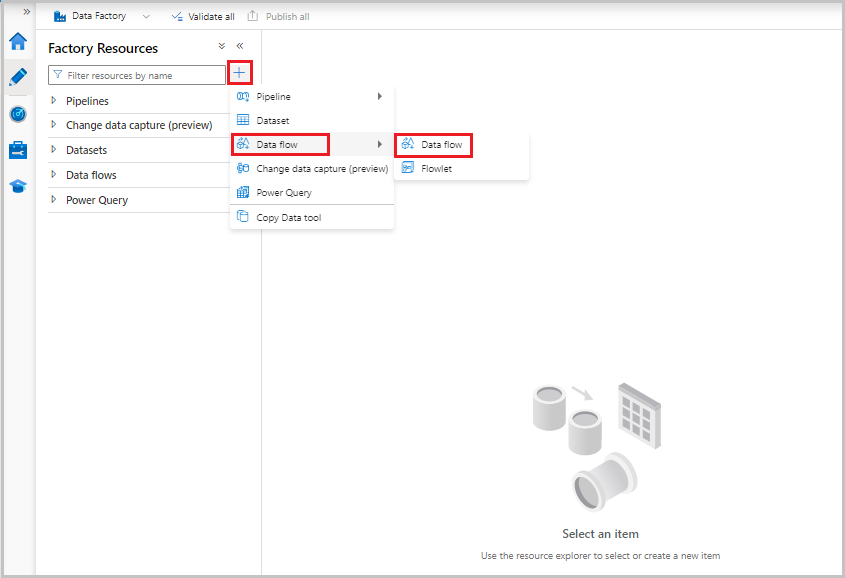
Как и ранее, снова выберите файл MoviesCSV в качестве источника, а затем снова выберите " Обнаружение типов данных" на вкладке "Проекция ".
На этот раз после создания источника выберите + в окне редактора потока данных и добавьте преобразование "Фильтр" в источник.
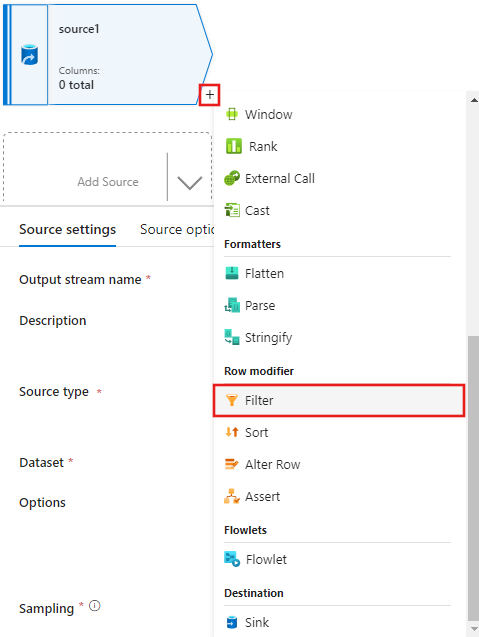
Добавьте фильтр по условию в окне параметров фильтра, которое разрешает только строки фильма, соответствующие 1950, 1960 и 1988.
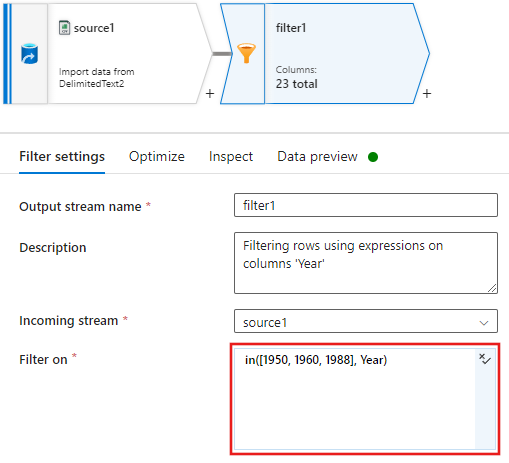
Теперь добавьте преобразование производного столбца, чтобы обновить оценки каждого фильма 1988 года на "1".
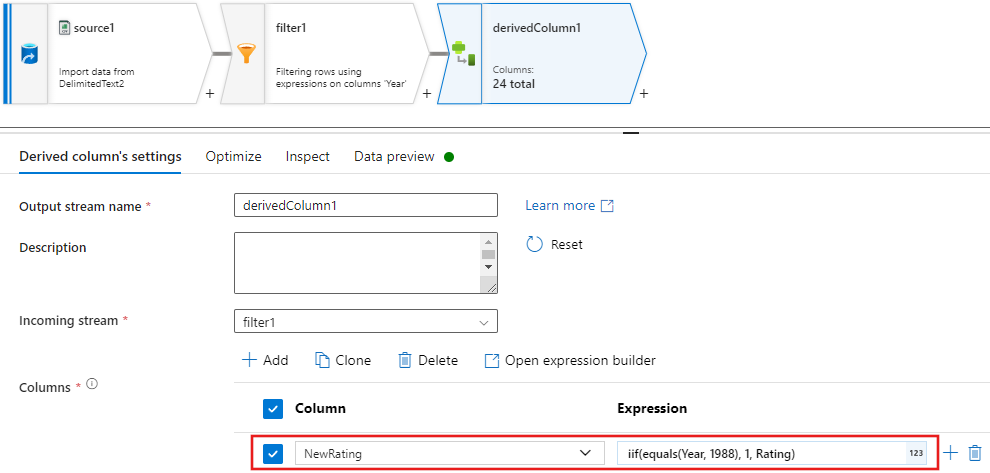
Политики
Update, insert, delete, and upsertсоздаются в преобразовании изменения строк. Добавьте преобразование изменения строк после производного столбца.Политики изменения строк должны выглядеть следующим образом.

Теперь, когда вы задали правильную политику для каждого типа строки alter, убедитесь, что в преобразовании приемника применены корректные правила обновления.
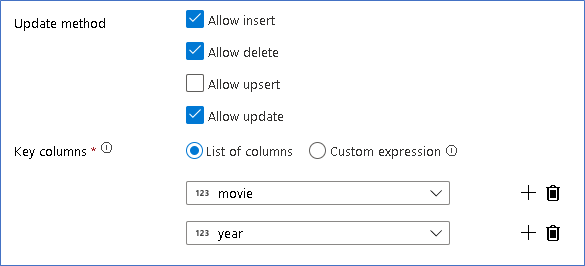
Здесь мы используем приемник Delta Lake для Хранилища данных Azure Data Lake второго поколения и разрешаем выполнять вставку, обновление и удаление.
Обратите внимание, что ключевые столбцы представляют собой составной ключ, состоящий из первичного ключевого столбца "Фильм" и столбца года. Это связано с тем, что мы создали ненастоящие фильмы 2021 года, дублируя строки 1960 года. Это позволяет избежать конфликтов при поиске существующих строк за счет обеспечения уникальности.
Загрузка готового примера
Ниже приведен пример решения для конвейера Delta с потоком данных для обновления и удаления строк в озере.
Связанный контент
Дополнительные сведения о языке выражений потока данных.