Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure
Фабрика данных Azure  Azure Synapse Analytics
Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Если вы еще не работали с фабрикой данных Azure, ознакомьтесь со статьей Введение в фабрику данных Azure.
В этом руководстве вы задействуете пользовательский интерфейс фабрики данных для создания конвейера, который копирует и преобразует данные из источника Data Lake Storage 2-го поколения в приемник Data Lake Storage 2-го поколения (разрешив обоим доступ только к выбранным сетям) с помощью потока данных для сопоставления в виртуальной сети, управляемой Фабрикой данных. Шаблон конфигурации, приведенный в этом кратком руководстве, можно расширить при преобразовании данных с использованием потоков данных для сопоставления.
Вот какие шаги выполняются в этом руководстве:
- Создали фабрику данных.
- создание конвейера с использованием действия "Поток данных";
- создание потока данных для сопоставления с четырьмя преобразованиями;
- тестовый запуск конвейера;
- отслеживание действий потока данных.
Необходимые компоненты
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure, прежде чем начинать работу.
- Учетная запись хранения Azure. Для хранения данных источника и приемника используется Data Lake Storage. Если у вас нет учетной записи хранения, создайте ее, следуя действиям в этом разделе. Убедитесь, что получить доступ к учетной записи хранения можно только из выбранных сетей.
Файл moviesDB.csv, который будет преобразован в этом руководстве, который можно найти на сайте содержимого GitHub. Чтобы извлечь файл из GitHub, скопируйте его содержимое в любой текстовый редактор, а затем сохраните его на локальном компьютере в виде CSV-файла. Сведения о передаче файла в учетную запись хранения см. в статье Отправка BLOB-объектов с помощью портала Azure. В примерах будет использоваться контейнер под названием sample-data.
Создание фабрики данных
На этом этапе вы создадите фабрику данных и откроете пользовательский интерфейс службы "Фабрика данных" для создания конвейера в фабрике данных.
Откройте Microsoft Edge или Google Chrome. Сейчас только эти браузеры поддерживают пользовательский интерфейс фабрики данных.
В меню слева выберите Создать ресурс>Аналитика>Фабрика данных.
На странице Новая фабрика данных в поле Имя введите ADFTutorialDataFactory.
Имя фабрики данных должно быть глобально уникальным. Если вы увидите следующую ошибку касательно значения имени, введите другое имя фабрики данных (например, yournameADFTutorialDataFactory). Дополнительные сведения о правилах именования артефактов фабрики данных см. в статье Фабрика данных Azure — правила именования.
Выберите подписку Azure, в рамках которой вы хотите создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий:
- Выберите Использовать существующуюи укажите существующую группу ресурсов в раскрывающемся списке.
- Выберите Создать новуюи укажите имя группы ресурсов.
Сведения о группах ресурсов см. в статье Общие сведения об Azure Resource Manager.
В качестве версии выберите V2.
В поле Расположение выберите расположение фабрики данных. В раскрывающемся списке отображаются только поддерживаемые расположения. Хранилища данных (например, Служба хранилища Azure и База данных Azure SQL) и вычислительные ресурсы (например, Azure HDInsight), используемые фабрикой данных, могут располагаться в других регионах.
Нажмите кнопку создания.
После завершения создания вы увидите уведомление в центре уведомлений. Выберите Перейти к ресурсу, чтобы открыть страницу фабрики данных.
Выберите "Открыть Фабрика данных Azure Studio", чтобы запустить пользовательский интерфейс фабрики данных на отдельной вкладке.
Создание среды выполнения интеграции Azure IR в управляемой виртуальной сети Фабрики данных
На этом шаге вы создадите среду выполнения интеграции Azure IR и включите управляемую виртуальную сеть Фабрики данных.
На портале Фабрики данных перейдите в раздел Управление и выберите Создать, чтобы создать среду Azure IR.
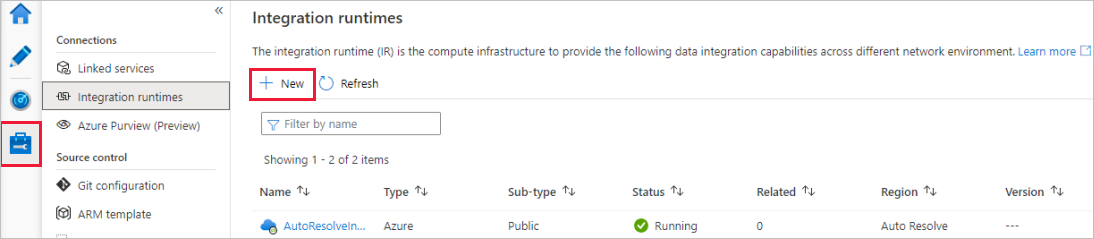
На странице Integration runtime setup (Настройка среды выполнения интеграции) выберите, какую среду выполнения интеграции следует создать на основе требуемых возможностей. По условиям этого руководства выберите Azure и нажмите кнопку Продолжить.
Выберите Azure и щелкните Продолжить, чтобы создать среду выполнения интеграции Azure.
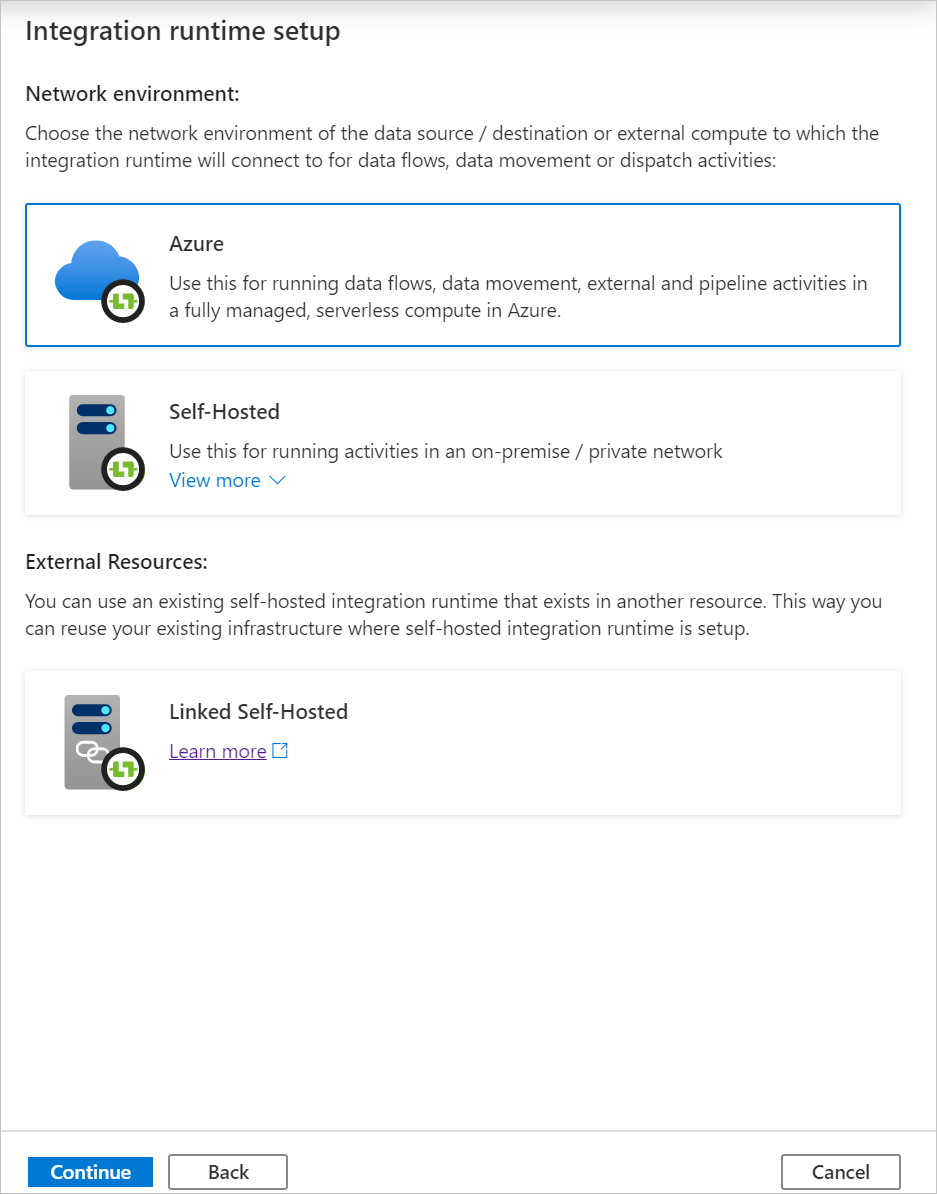
В разделе Virtual network configuration (Preview) (Конфигурация виртуальной сети (предварительная версия)) выберите Включить.
Нажмите кнопку создания.
Создание конвейера с помощью действия потока данных
На этом этапе вы создадите конвейер, содержащий действие потока данных.
На домашней странице пользовательского интерфейса Фабрики данных выберите элемент Оркестрация.
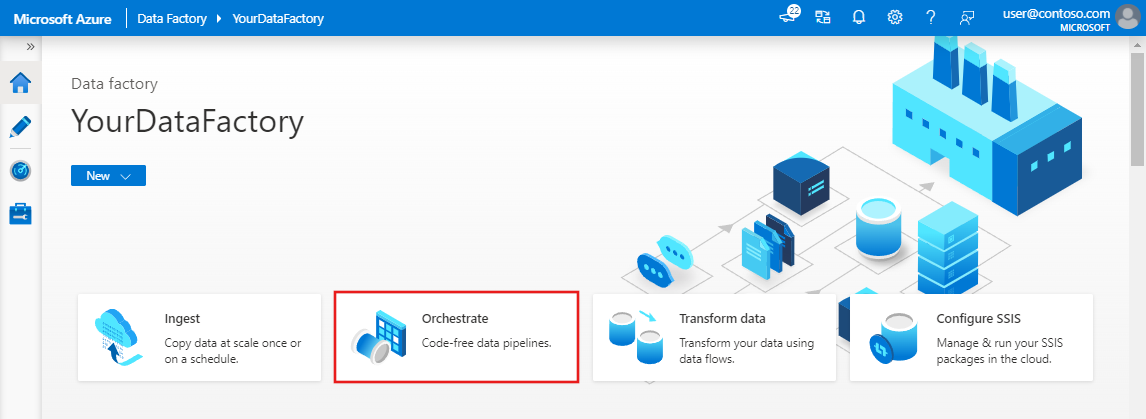
На панели свойств для конвейера введите TransformMovies в поле имени конвейера.
В области Действия разверните меню Перемещение и преобразование. Перетащите действие Поток данных из области на холст конвейера.
Во всплывающем окне Добавление потока данных выберите Создать поток данных, а затем — Поток данных для сопоставления. Завершив настройку, нажмите кнопку ОК.
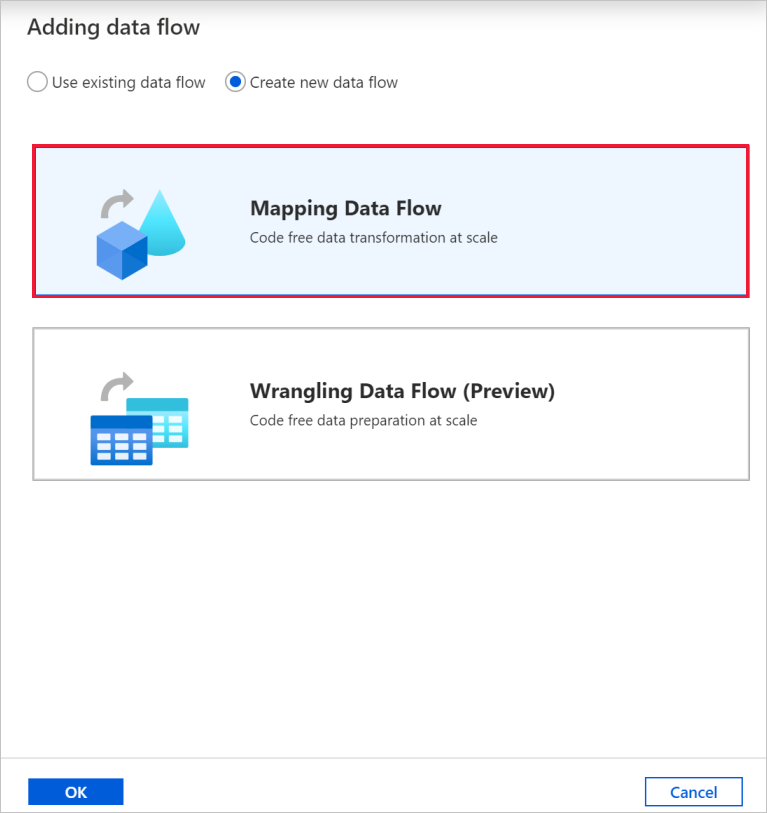
Присвойте потоку данных имя TransformMovies на странице свойств.
На верхней панели холста конвейера продвиньте ползунок Отладка потока данных. Режим отладки позволяет в интерактивном режиме тестировать логику преобразования в динамическом кластере Spark. Подготовка кластеров Потоков данных занимает 5–7 минут, поэтому пользователям рекомендуем сначала включить отладку, если планируется разработка Потока данных. Дополнительные сведения см. в статье Режим отладки.

Встраивание логики преобразования в холст потока данных
После создания потока данных он будет автоматически отправлен на холст потока данных. На этом шаге будет создан поток данных, который извлекает файл MoviesDB.csv из хранилища Data Lake Storage и вычисляет среднюю оценку комедий с 1910 по 2000 гг. Затем этот файл будет записан обратно в хранилище Data Lake Storage.
Добавление преобразования источника
На этом шаге будет настроен источник Data Lake Storage 2-го поколения.
На холсте потока данных добавьте источник, выбрав поле Добавить источник.
Присвойте источнику имя MoviesDB. Выберите Создать, чтобы создать исходный набор данных.
Выберите Azure Data Lake Storage 2-го поколения и нажмите кнопку Продолжить.
Выберите DelimitedText и нажмите кнопку Продолжить.
Присвойте набору данных имя MoviesDB. В раскрывающемся списке связанных служб выберите Создать.
На экране создания связанной службы присвойте связанной службе Data Lake Storage Gen2 имя ADLSGen2 и укажите метод проверки подлинности. Затем введите учетные данные подключения. В этом руководстве для подключения к нашей учетной записи хранения используется ключ учетной записи.
Обязательно включите режим Интерактивная разработка. Его включение может занять около минуты.
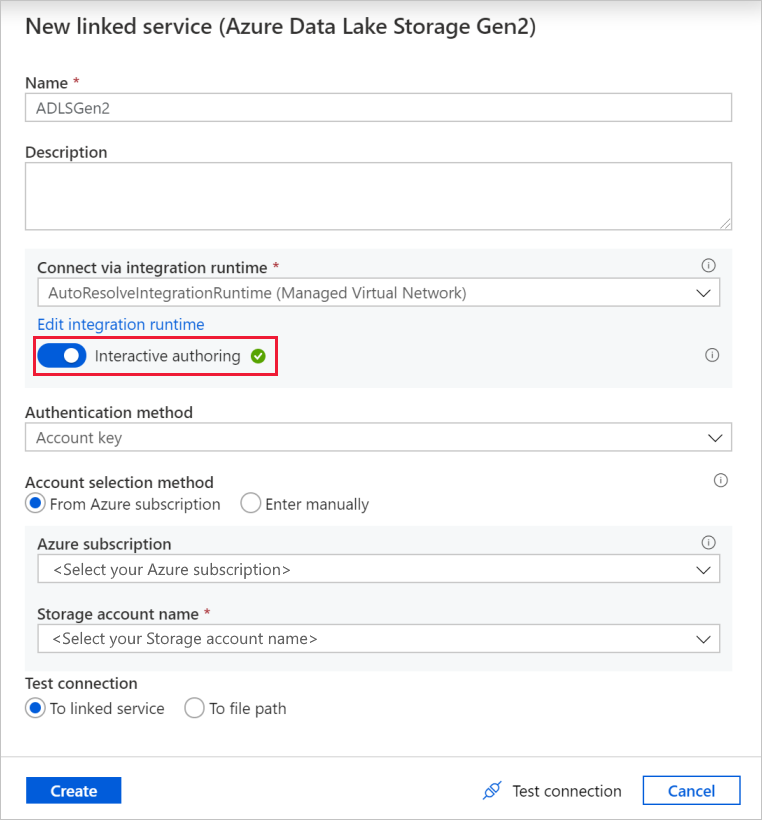
Выберите Test connection (Проверить подключение). Это должно привести к сбою, так как учетная запись хранения не разрешает к себе доступ к ней без создания и утверждения частной конечной точки. В сообщении об ошибке должна присутствовать ссылка, по которой вы можете перейти к интерфейсу создания управляемой частной конечной точки. Кроме того, можно сразу открыть вкладку Управление и выполнить инструкции из этого раздела, чтобы создать управляемую частную конечную точку.
Не закрывая это диалоговое окно, перейдите к учетной записи хранения.
Следуйте инструкциям в этом разделе, чтобы утвердить частную ссылку.
Вернитесь к диалоговому окну. Выберите Проверить соединение, а затем нажмите кнопку Создать, чтобы развернуть связанную службу.
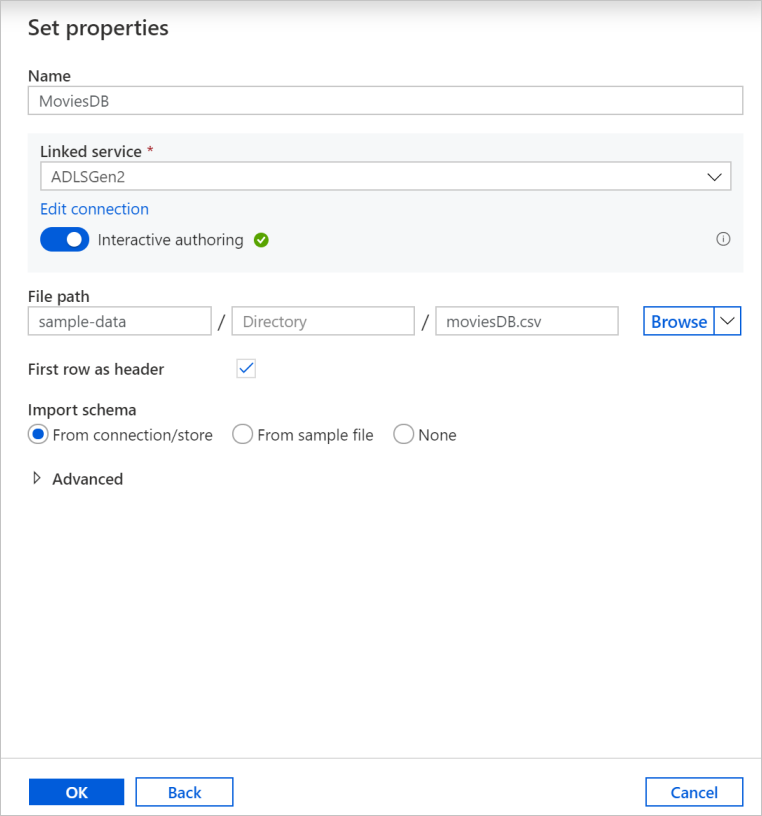
На экране создания набора данных в поле Путь к файлу введите расположение файла. В этом руководстве файл moviesDB.csv находится в контейнере sample-data. Так как файл содержит заголовки, установите флажок Использовать первую строку как заголовок. Выберите Из подключения/хранилища, чтобы импортировать схему заголовка непосредственно из файла в хранилище. Завершив настройку, нажмите кнопку ОК.
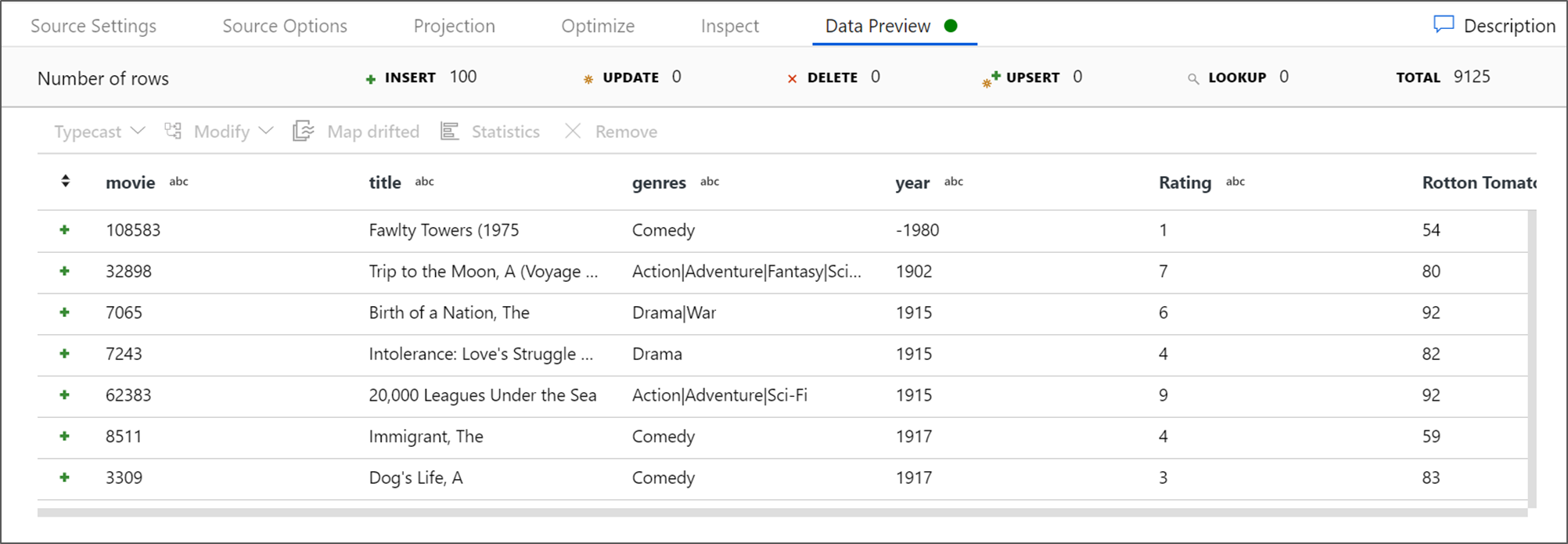
Если кластер отладки запущен, откройте вкладку Предварительный просмотр данных преобразования источника и нажмите кнопку Обновить, чтобы получить моментальный снимок данных. Предварительный просмотр данных дает возможность убедиться, что преобразование настроено правильно.
Создание управляемой частной конечной точки
Если вы не переходили по гиперссылке при проверке подключения, перейдите по указанному пути. Здесь вам нужно создать управляемую частную конечную точку, которая будет подключаться к созданной связанной службе.
Перейдите на вкладку Управление.
Примечание.
Вкладка Управление может быть доступна не для всех экземпляров фабрики данных. Если она не отображается, вы можете получить доступ к частным конечным точкам, выбрав Создание>Подключения>Частная конечная точка.
Перейдите в раздел Managed private endpoints (Управляемые частные конечные точки).
В разделе Managed private endpoints (Управляемые частные конечные точки) выберите + Создать.
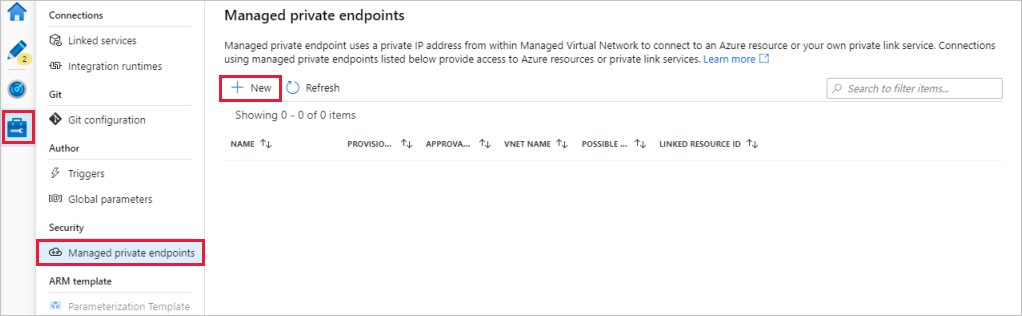
Выберите плитку Azure Data Lake Storage 2-го поколения в списке и нажмите кнопку Продолжить.
Введите имя созданной учетной записи хранения.
Нажмите кнопку создания.
Через несколько секунд для созданной частной ссылки отобразится состояние ожидания утверждения.
Выберите созданную частную конечную точку. Вы увидите гиперссылку, которая ведет к интерфейсу утверждения частной конечной точки на уровне учетной записи хранения.
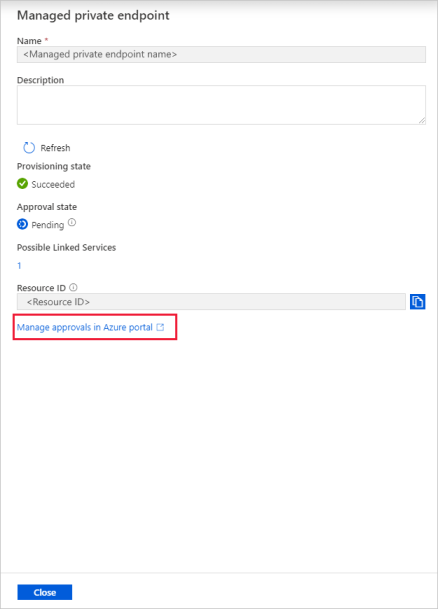
Утверждение частной ссылки в учетной записи хранения
В разделе Параметры для учетной записи хранения выберите Подключения частных конечных точек.
Установите флажок для созданной частной конечной точки и выберите Утвердить.
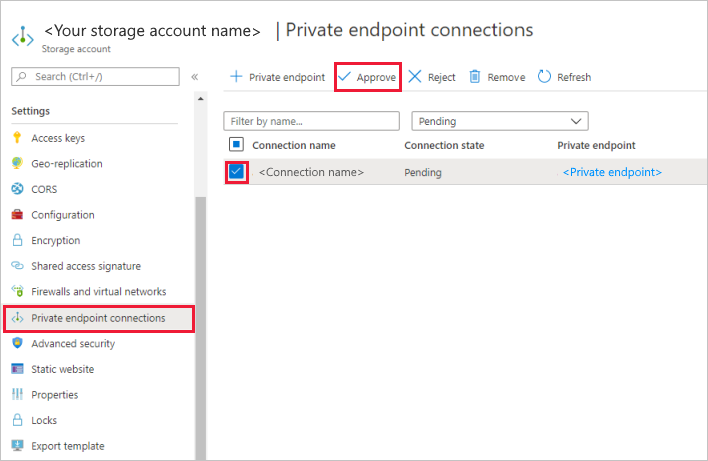
Добавьте описание и выберите Да.
Вернитесь к разделу Managed private endpoints (Управляемые частные конечные точки) на вкладке Управление для Фабрики данных.
Примерно через минуту отобразится сообщение об утверждении частной конечной точки.
Добавление преобразования фильтрации
Выберите значок "плюс" рядом с узлом источника на холсте потока данных, чтобы добавить новое преобразование. Первое добавляемое преобразование — Фильтр.
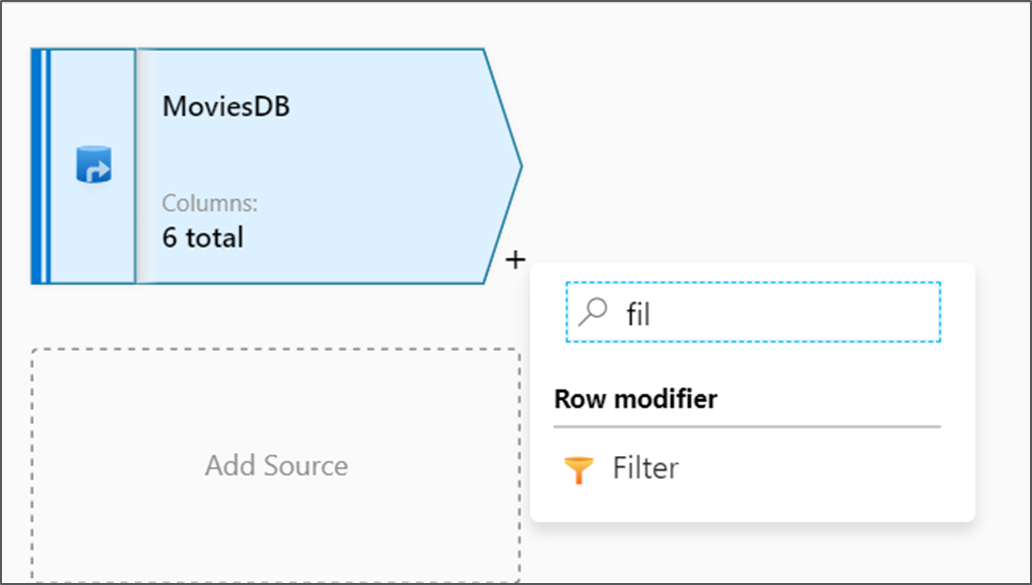
Назовите преобразование фильтра FilterYears. Выберите поле "Выражение" рядом с полем Фильтр, чтобы открыть построитель выражений. Здесь нужно указать условие фильтрации.
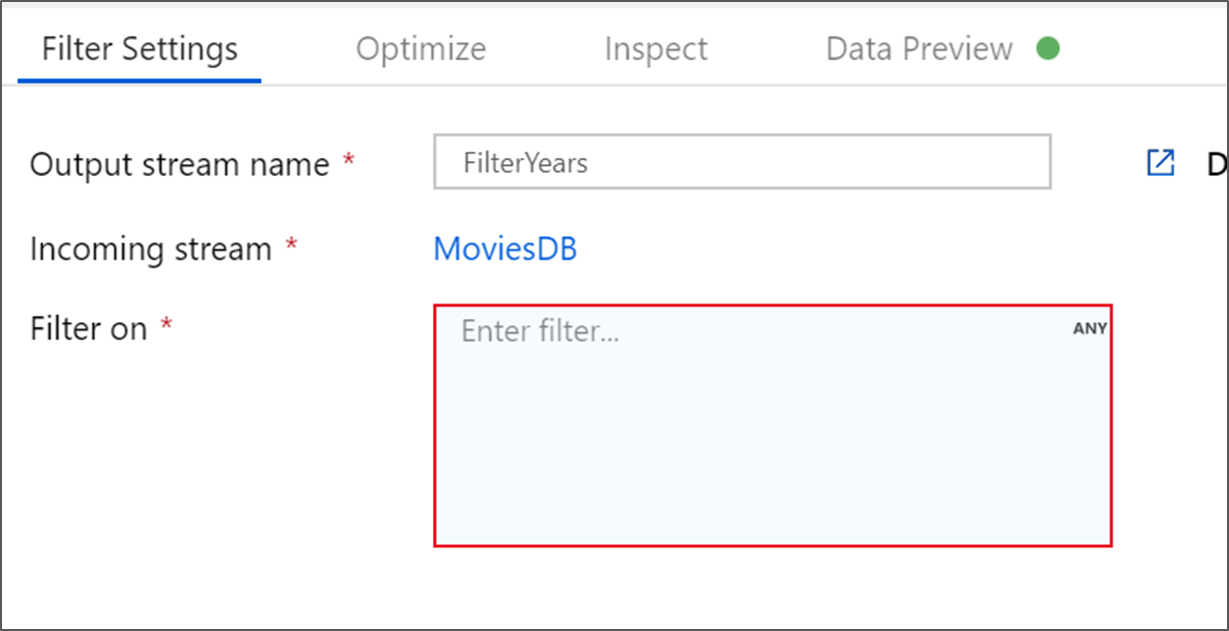
Построитель выражений потока данных позволяет интерактивно создавать выражения для использования в различных преобразованиях. Выражения могут включать встроенные функции, столбцы из входной схемы и задаваемые пользователем параметры. Дополнительные сведения о построении выражений см. в статье Построитель выражений Потока данных.
В этом руководстве будут отфильтрованы фильмы в жанре комедии, которые вышли между 1910 и 2000 годами. Поскольку в настоящее время год является строкой, его необходимо преобразовать в целое число с помощью функции
toInteger(). Используйте операторы "больше или равно" (>=) и "меньше или равно" (<=) для сравнения значений года с литералами 1910 и 2000. Объедините эти выражения с помощью оператора AND (&&). Выражение будет выглядеть следующим образом:toInteger(year) >= 1910 && toInteger(year) <= 2000Чтобы узнать, какие фильмы являются комедиями, можно использовать функцию
rlike(), позволяющую найти слово "комедия" в столбце жанров. Объедините выражениеrlikeс выражением сравнения года и получите следующее выражение:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Если кластер отладки активен, можно проверить логику, нажав кнопку Обновить, чтобы увидеть результат выражения в сравнении с входными данными. Реализовать эту логику с помощью языка выражений потока данных можно разными способами.
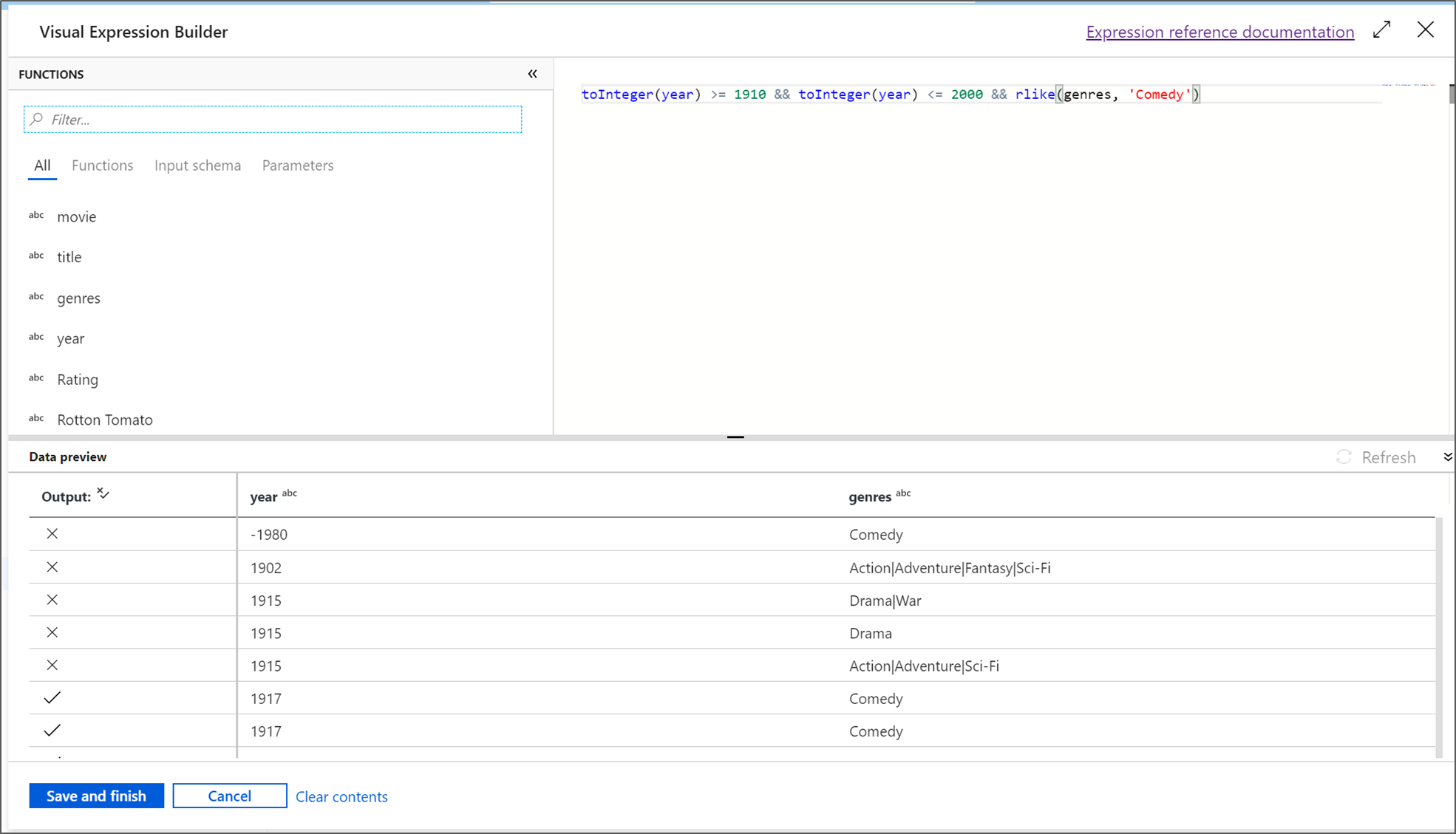
После завершения работы с выражением нажмите кнопку Сохранить и завершить.
Нажмите Предварительный просмотр данных, чтобы убедиться, что фильтр работает правильно.
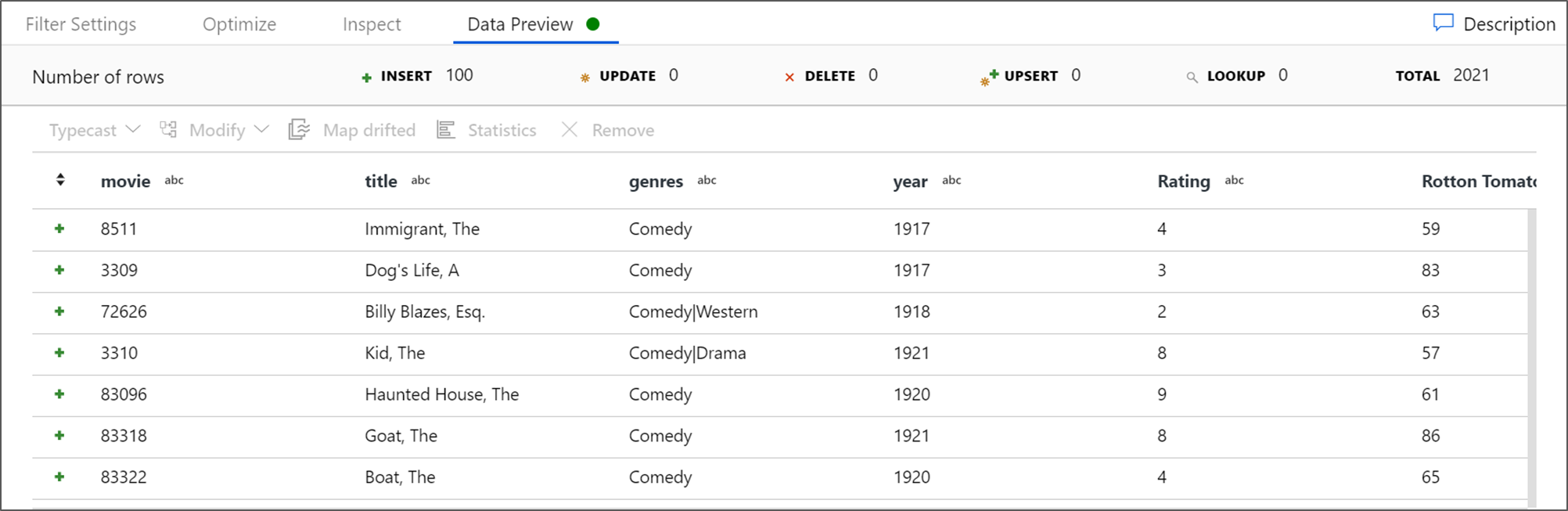
Добавление преобразования статистической обработки
Следующее преобразование, которое необходимо добавить — это преобразование Агрегат в разделе Модификатор схемы.
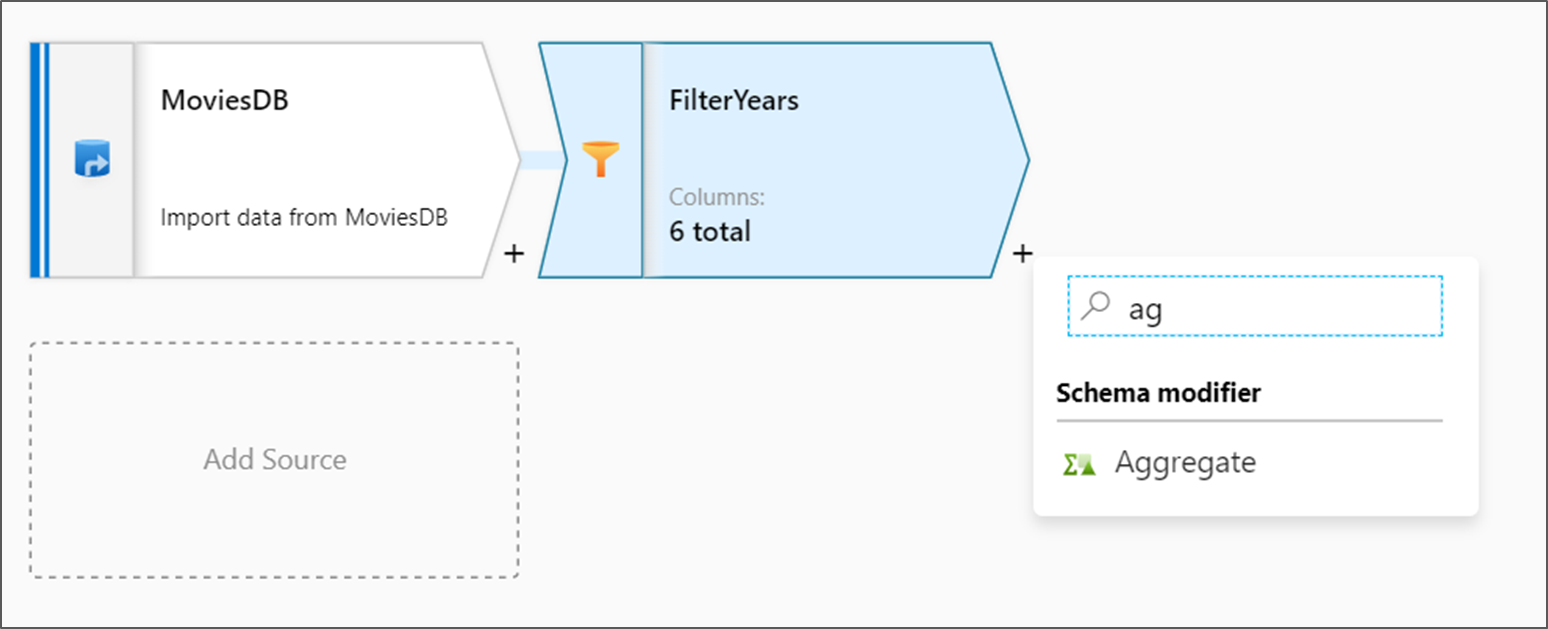
Назовите преобразование статистической обработки AggregateComedyRatings. На вкладке Группировка выберите год из раскрывающегося списка, чтобы сгруппировать агрегаты по году, в котором вышел фильм.
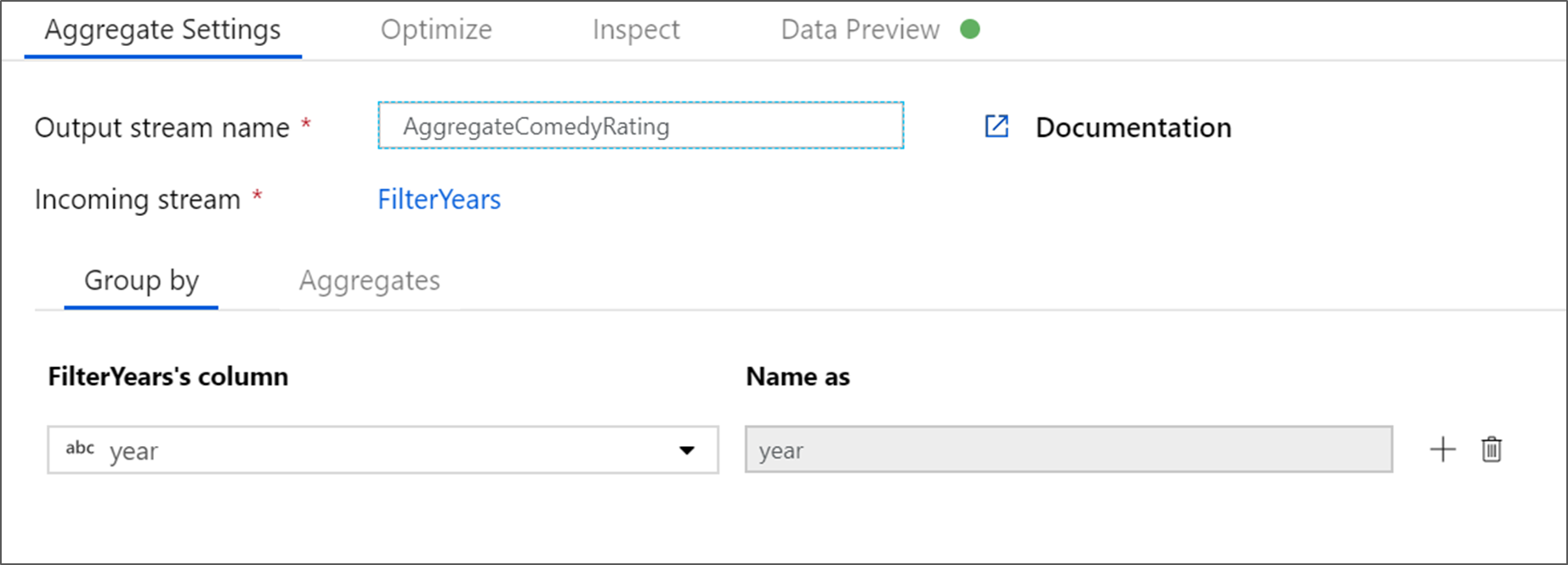
Перейдите на вкладку Статистическая обработка. В левом текстовом поле присвойте столбцу имя AverageComedyRating. Выберите правое поле выражения, чтобы ввести статистическое выражение с помощью построителя выражений.
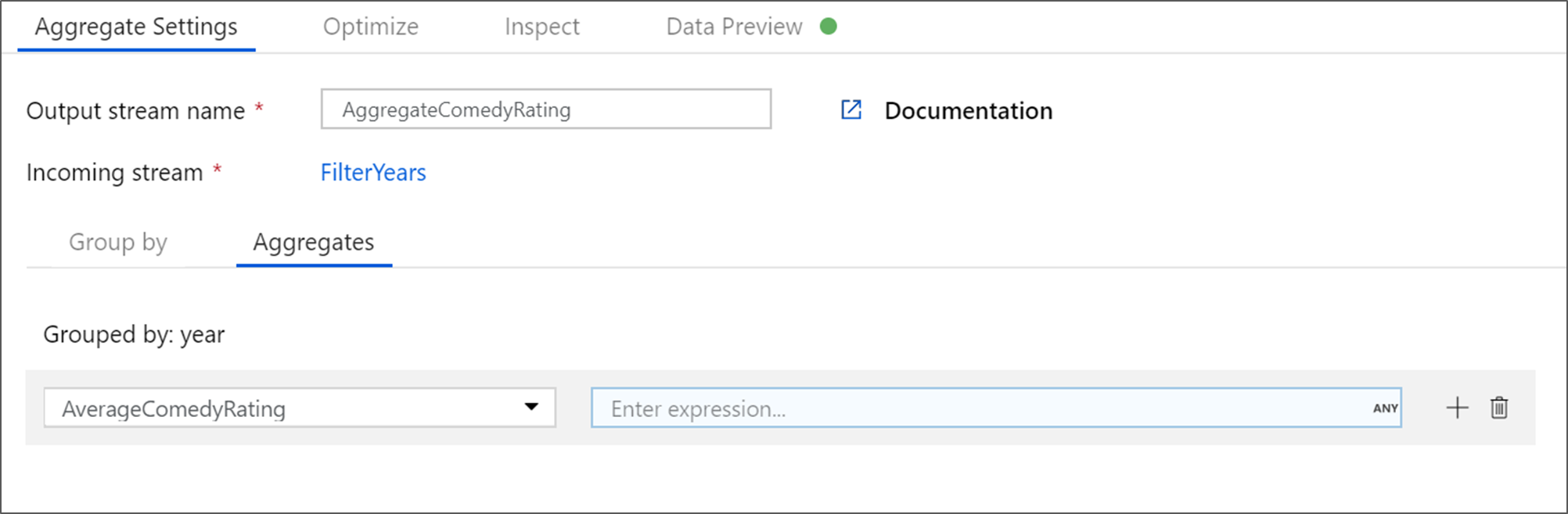
Чтобы получить среднее значение столбца Оценка, используйте агрегатную функцию
avg(). Так как оценка является строковым значением, аavg()принимает числовые входные данные, необходимо преобразовать значение в число с помощью функцииtoInteger(). Это выражение выглядит следующим образом:avg(toInteger(Rating))По завершении нажмите кнопку Сохранить и завершить.

Откройте вкладку Предварительный просмотр данных, чтобы просмотреть выходные данные преобразования. Обратите внимание, что здесь есть только два столбца: year и AverageComedyRating.
Добавление преобразования приемника
Затем необходимо добавить преобразование Приемник в качестве назначения.
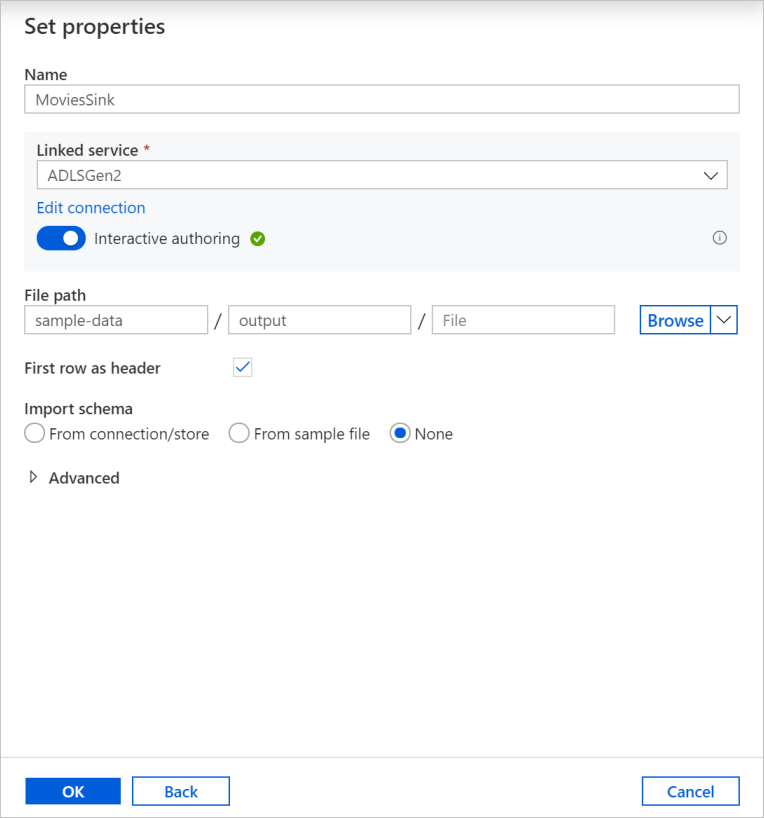
Назовите приемник Sink. Нажмите Создать, чтобы создать набор данных приемника.
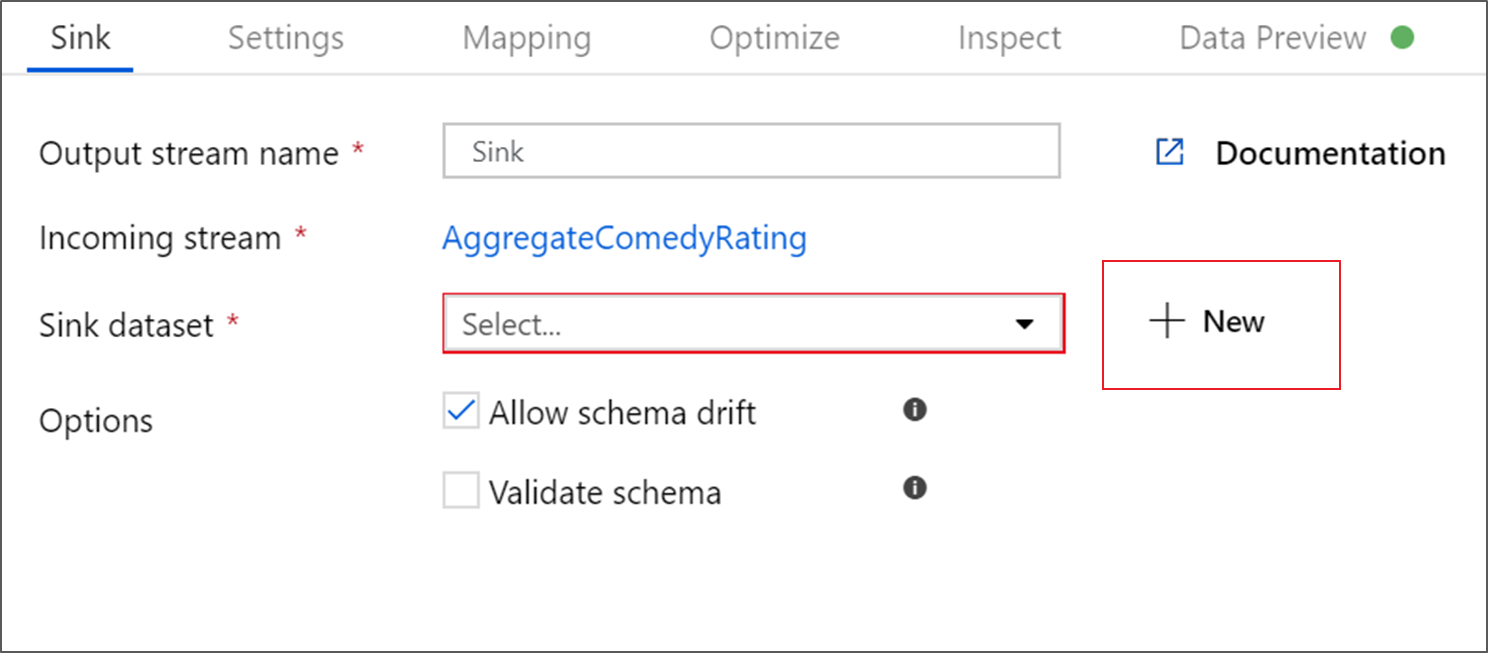
На странице Новый набор данных выберите Azure Data Lake Storage Gen2, а затем нажмите кнопку Продолжить.
На странице Выбор формата выберите DelimitedText и нажмите кнопку Продолжить.
Назовите набор данных приемника MoviesSink. Для связанной службы выберите ту же связанную службу ADLSGen2, которая была создана для преобразования источника. Введите выходную папку для записи данных. В этом кратком руководстве мы записываем данные в папку output в контейнере sample-data. Папка не обязательно должна существовать заранее и может быть создана динамически. Установите флажок Использовать первую строку как заголовок и выберите значение Нет для параметра Импорт схемы. Нажмите ОК.
Теперь создание потока данных завершено. Все готово для его запуска в конвейере.
Запуск и мониторинг потока данных
Перед публикацией можно выполнить отладку конвейера. На этом шаге будет активирован запуск отладки конвейера потока данных. При предварительном просмотре данных они не записываются, а в режиме отладки данные записываются в место назначения приемника.
Перейдите на холст конвейера. Нажмите кнопку Отладка, чтобы запустить отладку.
При отладке конвейера для действий Потока данных используется активный кластер отладки, но инициализация все равно занимает не менее минуты. Ход выполнения можно отслеживать с помощью вкладки Вывод. После успешного выполнения щелкните значок очков для просмотра сведений о выполнении.
На странице сведений можно увидеть количество строк и время, потраченное на каждый шаг преобразования.
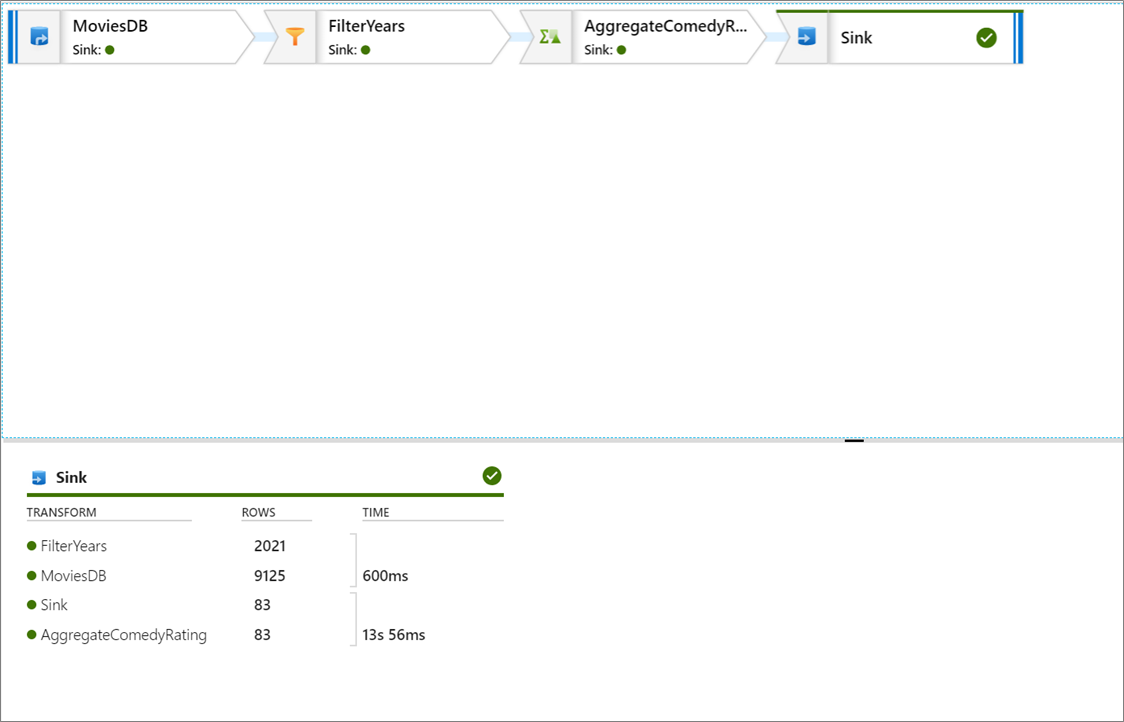
Щелкните преобразование, чтобы получить подробные сведения о столбцах и секционировании данных.
Если все действия в этом кратком руководстве выполнены правильно, то в папку приемника должны быть записаны 83 строки и 2 столбца. Данные можно проверить, проверив хранилище BLOB-объектов.
Итоги
В этом руководстве вы задействуете пользовательский интерфейс фабрики данных для создания конвейера, который копирует и преобразует данные из источника Data Lake Storage 2-го поколения в приемник Data Lake Storage 2-го поколения (разрешив обоим доступ только к выбранным сетям) с помощью потока данных для сопоставления в виртуальной сети, управляемой Фабрикой данных.