Что представляет собой Azure Data Lake Storage 1-го поколения?
Примечание.
Azure Data Lake Storage 1-го поколения теперь прекращена. Ознакомьтесь с объявлением о выходе на пенсию здесь.Data Lake Storage 1-го поколения ресурсы больше не доступны.
Azure Data Lake Storage 1-го поколения — это крупномасштабный репозиторий корпоративного уровня для рабочих нагрузок анализа больших данных. Azure Data Lake позволяет сохранять данные с любым размером, типом и скоростью приема в одном месте для эксплуатационной и исследовательской аналитики.
Data Lake Storage 1-го поколения доступно из Hadoop (имеется в кластере HDInsight) с помощью интерфейсов REST API, совместимых с WebHDFS. Он разработан для анализа хранимых данных и адаптирован к различным сценариям аналитики данных. Data Lake Storage 1-го поколения включает в себя все возможности корпоративного уровня — безопасность, управляемость, масштабируемость, надежность и доступность.
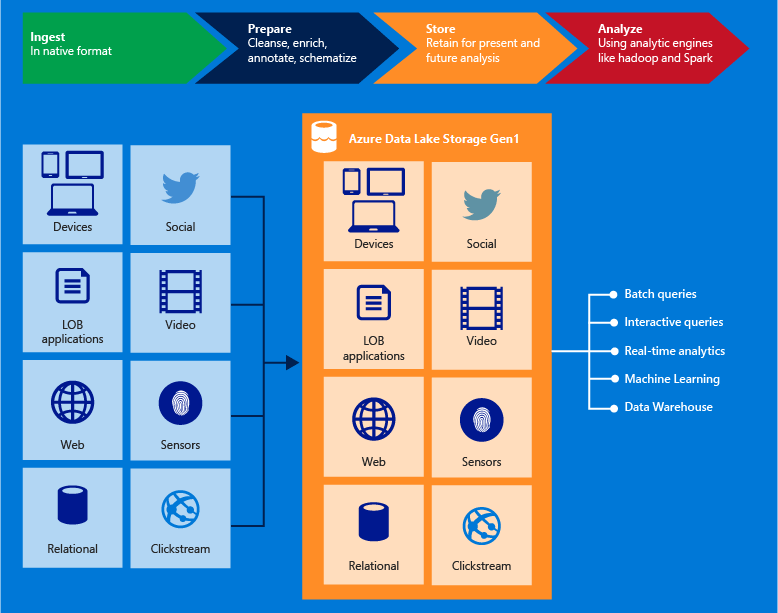
Основные возможности
Ниже перечислены некоторые основные возможности Data Lake Storage 1-го поколения.
Поддержка Hadoop
Data Lake Storage 1-го поколения имеет файловую систему Apache Hadoop, которая совместима с распределенной файловой системой Hadoop и поддерживает экосистему Hadoop. Существующие приложения и службы HDInsight, использующие API-интерфейс WebHDFS, могут легко интегрироваться с Data Lake Storage 1-го поколения. Data Lake Storage 1-го поколения также предоставляет для приложений интерфейс REST, совместимый с WebHDFS.
Данные, хранящиеся в Data Lake Storage 1-го поколения, можно легко анализировать с помощью аналитических платформ Hadoop, например MapReduce или Hive. Для прямого доступа к данным, хранящимся в Data Lake Storage 1-го поколения, можно подготовить и настроить кластеры Azure HDInsight.
Неограниченное пространство хранения, файлы петабайтного размера
Data Lake Storage 1-го поколения предоставляет неограниченное пространство и может использоваться для хранения разнообразных данных для анализа. В нем нет никаких ограничений на размер учетной записи, размер файла или объем данных, которые могут храниться в Data Lake. Размер отдельных файлов может варьироваться от одного килобайта до нескольких петабайтов. Надежность хранения данных обеспечивается за счет создания нескольких копий. Кроме того, нет никаких ограничений на продолжительность хранения данных в озере данных.
Настройки производительности для анализа больших данных
Data Lake Storage 1-го поколения предназначен для работы в крупномасштабных аналитических системах, где требуется высокая пропускная способность для запроса и анализа больших объемов данных. В озере данных фрагменты файлов распределяются по нескольким отдельным серверам хранилища. Это повышает пропускную способность при параллельном чтении файла для проведения анализа данных.
Готовность предприятия: высокий уровень доступности и безопасности
Data Lake Storage 1-го поколения обладает доступностью и надежностью, соответствующими отраслевым стандартам. Надежность хранения данных обеспечивается созданием избыточных копий для защиты от любых непредвиденных сбоев.
Data Lake Storage 1-го поколения также обеспечивает безопасность корпоративного уровня для сохраненных данных. Дополнительные сведения см. в статье о защите данных в Data Lake Storage 1-го поколения.
Все данные
В Data Lake Storage 1-го поколения можно хранить любые данные в собственном формате без выполнения каких-либо предварительных преобразований. Data Lake Storage 1-го поколения не требует определять схему перед загрузкой данных. Интерпретацию данных и определение схемы осуществляет конкретная аналитическая платформа во время анализа. Возможность хранения файлов произвольных форматов и размера позволяет обрабатывать в Data Lake Storage 1-го поколения структурированные, полуструктурированные и неструктурированные данные.
В Data Lake Storage 1-го поколения хранятся контейнеры для данных — папки и файлы. Вы работаете с сохраненными данными с помощью пакетов SDK, портал Azure и Azure PowerShell. Используя эти интерфейсы и соответствующие контейнеры, вы можете сохранять любые типы данных. Data Lake Storage 1-го поколения обрабатывает сохраняемые данные без учета их типа.
Защита данных
Data Lake Storage 1-го поколения использует идентификатор Microsoft Entra для проверки подлинности и списки управления доступом (ACL) для управления доступом к данным.
| Возможность | Description |
|---|---|
| Authentication | Data Lake Storage 1-го поколения интегрируется с идентификатором Microsoft Entra для управления удостоверениями и доступом для всех данных, хранящихся в Data Lake Storage 1-го поколения. Из-за интеграции Data Lake Storage 1-го поколения преимущества всех функций Microsoft Entra, таких как многофакторная проверка подлинности, условный доступ, управление доступом на основе ролей Azure, мониторинг использования приложений, мониторинг безопасности и оповещения и т. д. Data Lake Storage 1-го поколения поддерживает протокол OAuth 2.0 для аутентификации в интерфейсе REST. См. статью Проверка подлинности в Data Lake Storage 1-го поколения. |
| Управление доступом | Data Lake Storage 1-го поколения обеспечивает контроль доступа за счет поддержки разрешений POSIX, предоставляемых протоколом WebHDFS. Списки управления доступом можно включить для корневой папки, вложенных папок, а также отдельных файлов. Дополнительные сведения о принципе работы списков управления доступом в контексте Data Lake Storage 1-го поколения см. в статье Контроль доступа в Azure Data Lake Storage 1-го поколения. |
| Шифрование | В Data Lake Storage 1-го поколения можно также включить шифрование данных, хранящихся в учетной записи. Параметры шифрования можно задать во время создания учетной записи Data Lake Storage 1-го поколения. Шифрование данных можно как включить, так и отключить. Дополнительные сведения см. в статье Шифрование данных в Data Lake Storage 1-го поколения. Инструкции по настройке шифрования см. в статье Начало работы с Data Lake Storage Gen1 с помощью портала Azure. |
Инструкции по защите данных в Azure Data Lake Storage 1-го поколения см. в этой статье.
Совместимость приложений
Data Lake Storage 1-го поколения совместимо с большинством компонентов с открытым исходным кодом в экосистеме Hadoop. К тому же он отлично интегрируется с прочими службами Azure. Чтобы узнать больше о том, как можно использовать Data Lake Storage 1-го поколения с компонентами с открытым кодом и другими службами Azure, воспользуйтесь следующими ссылками:
- Ознакомьтесь со списком приложений с открытым кодом, совместимых с Data Lake Storage 1-го поколения.
- См. статью Интеграция с другими службами Azure, где описано, как использовать Data Lake Storage 1-го поколения с другими службами Azure для реализации других сценариев.
- См. статью о сценариях работы с Data Lake Storage 1-го поколения, включая прием, обработку, загрузку и визуализацию данных.
Файловая система Data Lake Storage 1-го поколения
Доступ к Data Lake Storage 1-го поколения может осуществляться через файловую систему AzureDataLakeFilesystem (adl://) в средах Hadoop (имеется в кластере HDInsight). Приложения и службы, использующие adl://, могут использовать дополнительные возможности оптимизации производительности, которые в настоящее время недоступны в WebHDFS. В результате Data Lake Storage 1-го поколения предоставляет возможность либо воспользоваться максимальной производительностью с помощью adl:// (это рекомендуемый вариант), либо сохранить существующий код, продолжая использовать интерфейс API WebHDFS напрямую. Azure HDInsight использует все возможности AzureDataLakeFilesystem для обеспечения максимальной производительности в Data Lake Storage 1-го поколения.
Для доступа к данным в Data Lake Storage 1-го поколения можно использовать adl://<data_lake_storage_gen1_name>.azuredatalakestore.net. Дополнительные сведения о доступе к данным в Data Lake Storage 1-го поколения см. в статье Просмотр свойств хранимых данных.