Настройка кластеров
Примечание.
Это инструкции для устаревшего пользовательского интерфейса создания кластера и включены только для исторической точности. Все клиенты должны использовать обновленный пользовательский интерфейс кластера.
В этой статье описываются параметры конфигурации, доступные при создании и изменении кластеров Azure Databricks. В статье рассматривается создание кластеров и управление ими с помощью пользовательского интерфейса. Другие методы см. в интерфейсе командной строки Databricks, API кластеров и поставщике Databricks Terraform.
Комбинации параметров конфигурации, которые оптимально соответствуют вашим требованиям, см. в статье Практические рекомендации по настройке кластера.
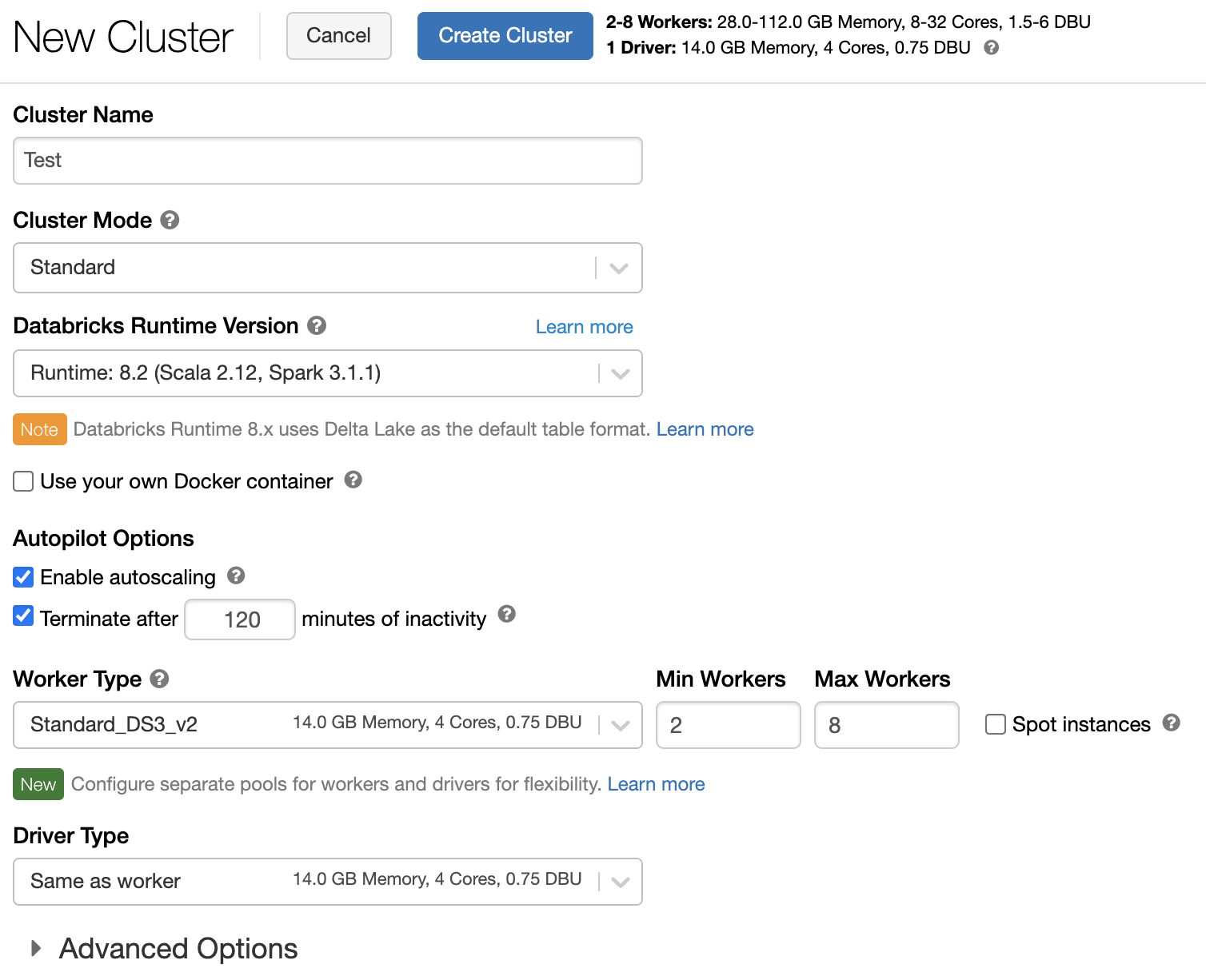
Политика кластера
Политика кластера ограничивает возможность настройки кластеров на основе набора правил. Правила политики ограничивают атрибуты и значения атрибутов, доступные для создания кластера. Политики кластера содержат списки управления доступом, которые ограничивают их использование конкретными пользователями и группами, тем самым ограничивая выбор политик при создании кластера.
Чтобы настроить политику кластера, выберите ее в раскрывающемся списке Политика.
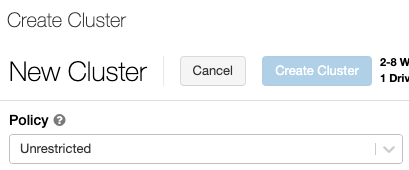
Примечание.
Если в рабочей области не созданы политики, раскрывающийся список Политики не отображается.
Если у вас:
- есть разрешение на создание кластера, можно выбрать политику Без ограничений и создать полностью настраиваемые кластеры; Политика Без ограничений не ограничивает атрибуты кластера или значения атрибутов.
- оба кластера создают разрешение и доступ к политикам кластера, можно выбрать политику Без ограничений и политики, к которым у вас есть доступ;
- есть доступ только к политикам кластера, можно выбрать политики, к которым у вас есть доступ.
Режим кластера
Примечание.
В этой статье описан пользовательский интерфейс устаревших кластеров. Сведения о новом пользовательском интерфейсе кластеров (в предварительной версии) см . в справочнике по конфигурации вычислений. К ним относятся некоторые изменения терминологии для типов и режимов доступа к кластеру. Сравнение новых и устаревших типов кластеров см. в разделе "Изменения пользовательского интерфейса кластеров" и режимы доступа к кластеру. В пользовательском интерфейсе предварительной версии:
- Кластеры стандартного режима теперь называются кластерами режима общего доступа без изоляции.
- Высокий параллелизм с списками ACL таблиц теперь называется кластерами режима общего доступа.
Azure Databricks поддерживает три режима кластера: "Стандартный", "Высокий параллелизм" и "Один узел". По умолчанию используется режим кластера «Стандартный».
Внимание
- Если рабочая область назначена хранилищу метаданных Unity Catalog, кластеры с высоким параллелизмом будут недоступными. Вместо этого вы будете использовать режим доступа, чтобы обеспечить целостность элементов управления доступом и обеспечить надежную изоляцию. См. также режимы доступа.
- Режим кластера нельзя изменить после создания кластера. Если требуется другой режим кластера, необходимо создать новый кластер.
Конфигурация кластера включает параметр автоматического завершения, для которого значение по умолчанию зависит от режима кластера:
- Кластеры уровня «Стандартный» и «Один узел» по умолчанию завершают работу автоматически через 120 минут.
- Кластеры уровня «Высокий параллелизм» не завершаются автоматически по умолчанию.
Кластеры уровня «Стандартный»
Предупреждение
Кластеры стандартного режима (иногда называемые "Без изоляции общих кластеров") могут совместно использоваться несколькими пользователями без изоляции между пользователями. Если вы используете режим кластера высокой параллелизма без дополнительных параметров безопасности, таких как списки управления доступом к таблицам или сквозное руководство учетных данных, те же параметры используются в качестве кластеров стандартного режима. Администраторы учетных записей могут запретить автоматически создавать внутренние учетные данные для администраторов рабочих областей Databricks в этих типах кластера. Для более безопасных вариантов Databricks рекомендует альтернативные варианты, такие как кластеры с высоким параллелизмом с таблицами ACL.
Для отдельных пользователей рекомендуется использовать стандартный кластер. Стандартные кластеры могут выполнять рабочие нагрузки, разработанные в Python, SQL, R и Scala.
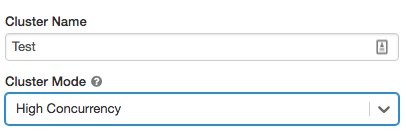
Кластеры уровня «Высокий параллелизм».
Кластер уровня «Высокий параллелизм» — это управляемый облачный ресурс. Основные преимущества кластеров уровня «Высокий параллелизм» заключается в том, что они предоставляют общий доступ с детализацией для максимизации объема потребляемых ресурсов и минимизации задержек при обработке запросов.
Кластеры уровня «Высокий параллелизм» могут выполнять рабочие нагрузки, разработанные в SQL, Python и R. Производительность и безопасность таких кластеров обеспечивается за счет выполнения пользовательского кода в отдельных процессах, что невозможно в Scala.
Кроме того, управление доступом к таблицеподдерживается только в кластерах уровня «Высокий параллелизм».
Чтобы создать такой кластер, задайте для параметра Режим кластера значение Высокий параллелизм.
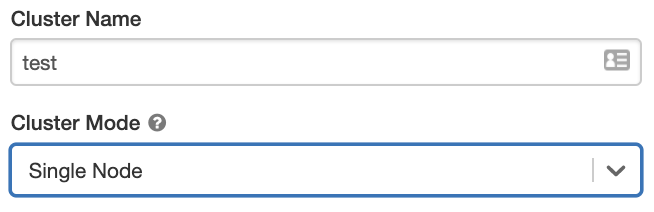
Кластеры уровня «Один узел»
Такой кластер не имеет рабочих ролей и выполняет задания Spark на узле драйвера.
И наоборот, для выполнения заданий Spark кластеру уровня «Стандартный» помимо узла драйвера требуется по меньшей мере один рабочий узел Spark.
Чтобы создать кластер «Один узел», задайте для параметра Режим кластера значение Один узел.
Дополнительные сведения о работе с кластерами с одним узлом см. в статье с одним узлом или несколькими узлами.
Пулы
Чтобы сократить время запуска кластера, можно подключить кластер к предварительно определенному пулу неактивных экземпляров для узлов драйвера и рабочих узлов. Кластер создается с помощью экземпляров в пулах. Если в пуле недостаточно неактивных ресурсов для создания запрашиваемых узлов драйвера или рабочих узлов, пул расширяется путем выделения новых экземпляров от поставщика экземпляров. При завершении работы подключенного кластера используемые им экземпляры возвращаются в пулы и могут быть повторно использованы другим кластером.
Если выбрать пул для рабочих узлов, но не для узла драйвера, узел драйвера наследует пул от конфигурации узлов рабочей роли.
Внимание
Если вы попытаетесь выбрать пул для узла драйвера, но не для рабочих узлов, возникнет ошибка и кластер не будет создан. Это требование позволяет избежать ситуаций, когда узлу драйвера приходится ожидать создания рабочих узлов или наоборот.
Дополнительные сведения о работе с пулами в Azure Databricks см . в справочнике по конфигурации пула.
Databricks Runtime
Databricks Runtime представляет собой набор основных компонентов, которые выполняются в кластерах. Все среды выполнения Databricks Runtime включают Apache Spark и предоставляют компоненты и обновления, повышающие удобство использования, производительность и безопасность. Дополнительные сведения см. в заметках о выпуске Databricks Runtime и совместимости.
При создании или изменении кластера Azure Databricks предоставляет несколько типов сред выполнения и несколько версий таких типов в раскрывающемся списке Версия Databricks Runtime.
Ускорение Photon
Photon доступен для кластеров под управлением Databricks Runtime 9.1 LTS и более поздних версий.
Чтобы включить ускорение Photon, выберите поле "Использование проверка ускорения фотона".
При необходимости можно указать тип экземпляра в раскрывающемся списке "Тип рабочей роли" и "Тип драйвера".
Для достижения оптимального соотношения цены и производительности в Databricks рекомендуется использовать следующие типы экземпляров.
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
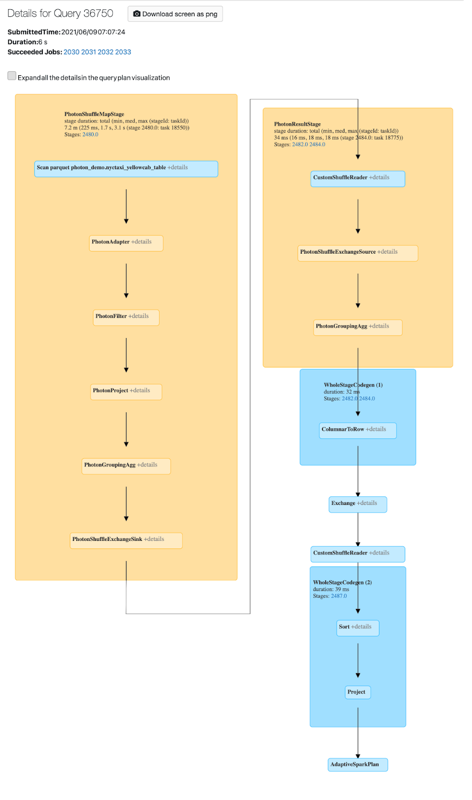
Можно просмотреть действия Photon в пользовательском интерфейсе Spark. На следующем снимке экрана показан направленный ациклический граф (DAG) со сведениями о запросе. В графе DAG существует два указания на Photon. Во первых, операторы Photon начинаются с «Photon», например PhotonGroupingAgg. Во-вторых, на графе DAG операторы и этапы Photon выделяются бежево-розовым цветом, а те, которые не имеют отношения к Photon — синим цветом.
Образы Docker
Для некоторых версий Databricks Runtime можно указать образ Docker при создании кластера. Примеры вариантов использования: настройка библиотеки, окончательная среда контейнера, которая уже не изменяется, и интеграция процессов CI/CD Docker.
Образы Docker можно также использовать для создания пользовательских сред глубокого обучения в кластерах с устройствами GPU.
Инструкции см. в разделе "Настройка контейнеров" с помощью службы контейнеров Databricks и служб контейнеров Databricks на вычислительных ресурсах GPU.
Тип узла кластера
Кластер состоит из одного узла драйвера и может включать или не включать рабочие узлы.
Можно выбрать отдельные типы экземпляров поставщика облачных служб для узлов драйверов и рабочих узлов, хотя по умолчанию узел драйвера использует тот же тип экземпляра, что и рабочий узел. Различные семейства типов экземпляров подходят для различных вариантов использования, таких как рабочие нагрузки, потребляющие большой объем памяти или вычислительных ресурсов.
Примечание.
Если требования к безопасности включают изоляцию вычислений, выберите экземпляр Standard_F72s_V2 в качестве типа рабочей роли. Такие типы экземпляра представляют изолированные виртуальные машины, которые занимают весь физический узел и обеспечивают достаточный уровень изоляции, требуемый, например, для поддержки рабочих нагрузок уровня защиты 5 (IL5) Министерства обороны США.
Узел драйвера
Узел драйвера хранит сведения о состоянии всех записных книжек, подключенных к кластеру. Узел драйвера также поддерживает SparkContext и интерпретирует все команды, выполняемые из записной книжки или библиотеки в кластере, и запускает главный узел Apache Spark, который координирует работу с исполнителями Spark.
Значение типа узла драйвера по умолчанию совпадает с типом рабочего узла. Если планируется collect() большой объем данных от рабочих ролей Spark и анализировать их в записной книжке, можно выбрать тип узла драйвера большего размера с большим объемом памяти.
Совет
Учитывая, что узел драйвера хранит все сведения о состоянии подключенных записных книжек, не забудьте отключить неиспользуемые записные книжки от узла драйвера.
Рабочий узел
Рабочие узлы Azure Databricks запускают исполнители Spark и другие службы, необходимые для надлежащей работы кластеров. При распределении рабочей нагрузки с помощью Spark вся распределенная обработка выполняется на рабочих узлах. Azure Databricks запускает по одному исполнителю на каждый рабочий узел, поэтому термины исполнитель и рабочая роль являются взаимозаменяемыми в контексте архитектуры Azure Databricks.
Совет
Для выполнения задания Spark требуется по меньшей мере один рабочий узел. Если в кластере нет рабочих ролей, можно выполнить команды, не относящиеся к Spark, на узле драйвера, однако выполнение команд Spark будет невозможным.
Типы экземпляров GPU
Для вычислительных задач, требующих высокой производительности, например задач, связанных с глубоким обучением, Azure Databricks поддерживает кластеры с ускорением за счет графических процессоров (GPU). Дополнительные сведения см. в разделе вычислений с поддержкой GPU.
Экземпляры точечных виртуальных машин
Чтобы сэкономить средства, можно использовать экземпляры точечных виртуальных машин, которые также называются точечными виртуальными машинами Azure, установив флажок Экземпляры точечных виртуальных машин.

Первый экземпляр всегда будет предоставляться по запросу (узел драйвера всегда предоставляется по запросу), и последующие экземпляры будут экземплярами точечных виртуальных машин. Если экземпляры точечных виртуальных машин удаляются из-за недоступности, для замены удаленных экземпляров развертываются экземпляры по запросу.
Размер кластера и автомасштабирование
При создании кластера Azure Databricks можно предоставить фиксированное число рабочих ролей для кластера или предоставить минимальное и максимальное количество рабочих ролей для кластера.
При предоставлении кластера фиксированного размера Azure Databricks гарантирует, что в кластере будет содержаться указанное число рабочих ролей. Если вы укажете диапазон для количества рабочих ролей, Databricks выберет подходящее количество рабочих ролей, необходимых для выполнения задания. Этот процесс называется автомасштабированием.
При автомасштабировании Azure Databricks динамически перераспределяет рабочие роли с учетом характеристик конкретного задания. Некоторые части конвейера могут быть более ресурсоемкими, чем другие, и Databricks автоматически добавляет дополнительные рабочие роли на данных этапах задания (и удаляют их, когда они перестают быть нужными).
Автоматическое масштабирование позволяет максимизировать использование кластера, ведь вам не придется подготавливать кластер в соответствии с рабочей нагрузкой. Это относится, в частности, к рабочим нагрузкам, требования к которым изменяются с течением времени (например, исследование набора данных в течение дня), однако это также может относиться и к короткой одноразовой рабочей нагрузке с неизвестными требованиями к подготовке. Таким образом, автомасштабирование предоставляет два преимущества:
- Рабочие нагрузки могут выполняться быстрее по сравнению с не полностью подготовленным кластером с постоянным размером.
- Автомасштабирование кластеров позволяет снизить общие затраты по сравнению с кластером со статическим размером.
В зависимости от постоянного размера кластера и рабочей нагрузки автомасштабирование предоставляет только одно или сразу оба этих преимущества. Размер кластера может быть меньше минимального числа рабочих ролей, выбранных при завершении работы экземпляров поставщиком облачных служб. В этом случае Azure Databricks постоянно предпринимает попытки повторной инициализации экземпляров для сохранения минимального числа рабочих ролей.
Примечание.
Автомасштабирование недоступно для заданий spark-submit.
Как осуществляется автомасштабирование
- Увеличение масштаба с минимального до максимального за два этапа.
- Поддерживается уменьшение масштаба, даже если кластер не находится в неактивном состоянии, за счет просмотра состояния файла в случайном порядке.
- Поддерживается уменьшение масштаба с учетом процента текущих узлов.
- В кластерах заданий поддерживается уменьшение масштаба, если кластер недостаточно активно использовался в последние 40 секунд.
- В универсальных кластерах поддерживается уменьшение масштаба, если кластер недостаточно активно использовался в последние 150 секунд.
- Свойство конфигурации Spark
spark.databricks.aggressiveWindowDownSуказывает интервал выполнения кластером решений по уменьшению масштаба (в секундах). Увеличение этого значения приводит к замедлению уменьшения масштаба кластера. Максимальное значение — 600.
Включение и настройка автомасштабирования
Чтобы разрешить Azure Databricks автоматически изменять размер кластера, включите автомасштабирование для кластера и предоставьте минимальный и максимальный диапазон рабочих ролей.
Примените функцию автомасштабирования.
Универсальный кластер: на странице «Создание кластера» установите флажок Включить автомасштабирование в поле Параметры автопилота:

Кластер задания: на странице «Настройка кластера» установите флажок Включить автомасштабирование в поле Параметры автопилота:

Настройте минимальное и максимальное количество рабочих ролей.

При запуске кластера на странице сведений о кластере отображается количество выделенных рабочих ролей. Можно сравнить число выделенных рабочих ролей с конфигурацией рабочей роли и внести необходимые изменения.
Внимание
При использовании пула экземпляров:
- Убедитесь, что запрошенный размер кластера меньше или равен минимальному количеству свободных экземпляров в пуле. Если размер больше, время запуска кластера будет эквивалентным таковому для кластера, который не использует пул.
- Убедитесь, что максимальный размер кластера меньше или равен максимальной емкости пула. Если размер больше, создание кластера завершится ошибкой.
Пример автомасштабирования
Если изменить настройку статического кластера для автомасштабирования кластера, Azure Databricks сразу изменит размер кластера в пределах минимальной и максимальной границ, а затем начнет автомасштабирование. Например, в следующей таблице показано, что происходит с кластерами с определенным исходным размером при изменении настройки этого кластера для автоматического масштабирования 5--10 узлов.
| Начальный размер | Размер после изменения настройки |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Автомасштабирование локального хранилища
Зачастую бывает трудно оценить, сколько дискового пространства потребуется на определенное задание. Чтобы не подсчитывать, сколько гигабайт на управляемом диске будет присоединено к кластеру во время создания, Azure Databricks автоматически включает автомасштабирование локального хранилища во всех кластерах Azure Databricks.
При автомасштабировании локального хранилища Azure Databricks отслеживает объем свободного дискового пространства, доступного в рабочих ролях Spark в кластере. Если рабочая роль начинает выполняться на диске слишком медленно, то модуль обработки данных автоматически присоединяет новый управляемый диск к рабочей роли до того, как на нем закончится свободное место. Диски присоединяются до достижения общего объема дискового пространства 5 ТБ для каждой виртуальной машины (включая исходное локальное хранилище виртуальной машины).
Управляемые диски, присоединенные к виртуальной машине, отсоединяются только при возврате виртуальной машины в Azure. То есть, управляемые диски никогда не отсоединяются от виртуальной машины, пока она является частью работающего кластера. Чтобы уменьшить масштаб использования управляемого диска, Azure Databricks рекомендует использовать эту функцию в кластере, настроенном с размером кластера и автомасштабированием или непредвиденным завершением.
Шифрование локальных дисков
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
Некоторые типы экземпляров, используемые для запуска кластеров, могут содержать локально присоединенные диски. Azure Databricks может хранить данные в произвольном порядке или временные данные на этих локально присоединенных дисках. Чтобы обеспечить шифрование всех неактивных данных для всех типов хранилищ, включая данные в произвольном порядке, которые временно хранятся на локальных дисках кластера, можно включить шифрование локального диска.
Внимание
Рабочие нагрузки могут выполняться медленнее из-за влияния на производительность операций чтения и записи зашифрованных данных в локальных томах.
Если включено шифрование локальных дисков, Azure Databricks локально создает ключ шифрования, уникальный для каждого узла кластера, который используется для шифрования всех данных, хранящихся на локальных дисках. Область действия ключа является локальной для каждого узла кластера и уничтожается вместе с самим узлом кластера. На протяжении времени существования ключ находится в памяти для целей шифрования и расшифровки и хранится на диске в зашифрованном виде.
Чтобы включить шифрование локальных дисков, необходимо использовать API кластеров. Во время создания или изменения кластера настройте следующие параметры:
{
"enable_local_disk_encryption": true
}
Примеры вызова этих API см. в API кластеров.
Ниже приведен пример вызова операции создания кластера, который активирует шифрование локального диска:
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Режим безопасности
Если рабочая область назначена хранилищу метаданных Unity Catalog, используйте режим безопасности вместо режима кластера с высоким параллелизмом, чтобы обеспечить целостность элементов управления доступом и надежную изоляцию. Режим кластера с высоким параллелизмом недоступен в каталоге Unity.
В разделе Дополнительные параметры выберите следующие режимы безопасности кластера:
- Нет: без изоляции. Не выполняет принудительный контроль доступа к локальной таблице в рабочей области или сквозную передачу учетных данных. Не может получить доступ к данным каталога Unity.
- Один пользователь: может использоваться только одним пользователем (по умолчанию пользователем, создавшим кластер). Другие пользователи не могут подключаться к кластеру. При доступе к представлению из кластера с режимом безопасности Один пользователь представление выполняется с разрешениями пользователя. Кластеры с одним пользователем поддерживают рабочие нагрузки с помощью Python, Scala и R. Сценарии Init, установка библиотеки и подключения DBFS поддерживаются в кластерах с одним пользователем. Для автоматических заданий должны использоваться однопользовательские кластеры.
- Изоляция пользователей: может совместно использоваться несколькими пользователями. Поддерживаются только рабочие нагрузки SQL. Установка библиотеки, скрипты и подключения DBFS отключены для обеспечения строгой изоляции среди пользователей кластера.
- Только таблицы ACL (прежние версии): обеспечивает управление доступом к локальной таблице рабочей области, но не может получить доступ к данным каталога Unity.
- Сквозная передача (прежние версии): обеспечивает сквозную передачу локальных учетных данных рабочей области, но не может получить доступ к данным каталога Unity.
Единственными режимами безопасности, поддерживаемыми рабочими нагрузками каталога Unity, являются Один пользователь и Изоляция пользователей.
Дополнительные сведения см. в режимах доступа.
Конфигурация Spark
Для точной настройки заданий Spark можно указать настраиваемые свойства конфигурации Spark в конфигурации кластера.
На странице "Конфигурация кластера" щелкните переключатель Дополнительные параметры.
Перейдите на вкладку Spark.
В файле конфигурации Spark укажите свойства конфигурации в виде одной пары «ключ-значение» в каждой строке.
При настройке кластера с помощью API кластера задайте свойства Spark в поле в spark_confразделе "Создание нового API кластера" или "Обновить API конфигурации кластера".
Databricks не рекомендует использовать глобальные скрипты инициализации.
Чтобы задать свойства Spark для всех кластеров, создайте глобальный сценарий инициализации:
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Получение свойства конфигурации Spark из секрета
Databricks рекомендует хранить конфиденциальные данные, такие как пароли, в формате секрета, а не в формате обычного текста. Чтобы создать ссылку на секрет в конфигурации Spark, используйте следующий синтаксис:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Например, чтобы настроить для свойства конфигурации Spark с именем password значение секрета, хранящегося в secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Дополнительные сведения см. в разделе Синтаксис для создания ссылок на секреты в свойстве конфигурации Spark или переменной среды.
Переменные среды
Можно настроить пользовательские переменные среды, доступ к которым можно получить из скриптов инициализации, выполняемых в кластере. Databricks также предоставляет предопределенные переменные среды, которые можно использовать в этих скриптах. Эти предопределенные переменные среды нельзя переопределить.
На странице "Конфигурация кластера" щелкните переключатель Дополнительные параметры.
Перейдите на вкладку Spark.
Задайте переменные среды в поле Переменные среды.
Можно также задать переменные среды с помощью spark_env_vars поля в API создания кластера или API конфигурации кластера обновления.
Теги кластера
Теги кластера позволяют легко отслеживать затраты на облачные ресурсы, используемые различными группами в организации. Теги можно указать в виде пар "ключ-значение" при создании кластера, после чего Azure Databricks применяет их к облачным ресурсам, таким как виртуальные машины и тома дисков, а также отчеты о потреблении единиц Databricks.
Для кластеров, запускаемых из пулов, пользовательские теги кластера применяются только к отчетам об использовании DBU (единиц Databricks) и не распространяются на облачные ресурсы.
Подробные сведения о том, как работают типы тегов пула и кластера, см. в разделе "Мониторинг использования с помощью тегов".
Для удобства Azure Databricks применяет четыре стандартных тега к каждому кластеру: Vendor, Creator, ClusterName и ClusterId.
Кроме того, в кластерах заданий Azure Databricks применяет два стандартных тега: RunName и JobId.
В ресурсах, используемых Databricks SQL, Azure Databricks также применяет стандартный тег SqlWarehouseId.
Предупреждение
Не назначайте пользовательский тег с ключом Name для кластера. Каждый кластер имеет тег Name, значение которого задается в Azure Databricks. Если изменить значение, связанное с ключом Name, Azure Databricks больше не будет отслеживать этот кластер. Как следствие, работа кластера может не завершиться после того, как он станет неактивным, и плата за его использование будет взиматься далее.
Пользовательские теги можно добавить при создании кластера. Чтобы настроить теги кластера, выполните следующие действия.
На странице "Конфигурация кластера" щелкните переключатель Дополнительные параметры.
В нижней части страницы нажмите кнопку Теги.
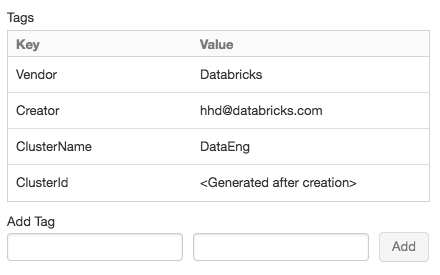
Добавьте пару «ключ-значение» для каждого пользовательского тега. Можно добавить до 43 пользовательских тегов.
SSH-доступ к кластерам
По соображениям безопасности в Azure Databricks порт SSH закрыт по умолчанию. Чтобы включить доступ по протоколу SSH к кластерам Spark, обратитесь в службу поддержки Azure Databricks.
Примечание.
SSH можно включить, только если рабочая область развернута в вашей собственной виртуальной сети Azure.
Доставка журнала кластера
При создании кластера можно указать расположение для доставки журналов узла драйвера Spark, рабочих узлов и событий. Журналы доставляются каждые пять минут в выбранное целевое расположение. После завершения работы кластера Azure Databricks гарантирует доставку всех журналов, созданных до завершения работы кластера.
Целевая папка для журналов зависит от идентификатора кластера. Если указано целевое расположение dbfs:/cluster-log-delivery, журналы кластера для 0630-191345-leap375 доставляются в dbfs:/cluster-log-delivery/0630-191345-leap375.
Чтобы настроить целевое расположение для доставки журналов, выполните следующие действия.
На странице "Конфигурация кластера" щелкните переключатель Дополнительные параметры.
Перейдите на вкладку Ведение журнала.
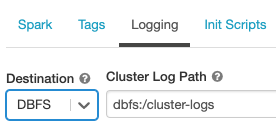
Выберите целевой тип.
Введите путь к журналу кластера.
Примечание.
Эта функция также доступна в REST API. См. API кластеров.
Скрипты инициализации
Сценарий инициализации узла кластера (или сценарий init) — это сценарий оболочки, который запускается во время запуска каждого узла кластера перед запуском драйвера Spark или рабочей роли виртуальной машины Java. Можно использовать сценарии init для установки пакетов и библиотек, не включенных в среду выполнения Databricks, изменения системного пути класса виртуальной машины Java, настройки свойств системы и переменных среды, используемых виртуальной машиной Java, или изменения параметров конфигурации Spark в числе других задач настройки.
Можно присоединить сценарии инициализации к кластеру, развернув раздел Дополнительные параметры и щелкнув вкладку Сценарии init.
Подробные инструкции см. в разделе "Что такое скрипты инициализации?".
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по