Справочник по конфигурации вычислений
В этой статье описываются параметры конфигурации, доступные в пользовательском интерфейсе создания вычислений. Большинство пользователей создают вычислительные ресурсы с помощью назначенных политик, что ограничивает настраиваемые параметры. Если в пользовательском интерфейсе не отображается определенный параметр, это связано с тем, что выбранная политика не позволяет настраивать этот параметр.
Конфигурации и средства управления, описанные в этой статье, относятся как ко всем назначениям, так и к вычислениям заданий. Дополнительные сведения о настройке вычислений заданий см. в разделе "Настройка вычислений для заданий".
Создание нового вычислительного ресурса для всех целей
Чтобы создать новый вычислительный ресурс для всех целей, выполните приведенные действия.
- На боковой панели рабочей области щелкните " Вычисления".
- Нажмите кнопку "Создать вычисления ".
- Настройте вычислительный ресурс.
- Нажмите кнопку "Создать вычисления".
Новый вычислительный ресурс автоматически запустится и будет готов к использованию в ближайшее время.
Политики
Политики — это набор правил, используемых для ограничения параметров конфигурации, доступных пользователям при создании вычислительных ресурсов. Если у пользователя нет права на создание неограниченного кластера, они могут создавать вычислительные ресурсы только с помощью предоставленных политик.
Чтобы создать вычислительные ресурсы в соответствии с политикой, выберите политику в раскрывающемся меню "Политика ".
По умолчанию все пользователи имеют доступ к политике личных вычислений , позволяя им создавать вычислительные ресурсы с одним компьютером. Если вам нужен доступ к персональным вычислениям или любым дополнительным политикам, обратитесь к администратору рабочей области.
Вычисление с одним узлом или несколькими узлами
В зависимости от политики можно выбрать между созданием вычислительного ресурса одного узла или вычислительным ресурсом с несколькими узлами.
Вычисления с одним узлом предназначены для заданий, использующих небольшие объемы данных или нераспределенные рабочие нагрузки, такие как библиотеки машинного обучения с одним узлом. Вычислительные ресурсы с несколькими узлами следует использовать для более крупных заданий с распределенными рабочими нагрузками.
Свойства одного узла
Вычислительный ресурс одного узла имеет следующие свойства:
- Локальный запуск Spark.
- Драйвер выступает как в качестве главного, так и рабочего, без рабочих узлов.
- Создает один поток исполнителя на логическое ядро в вычислительном ресурсе, минус 1 ядро для драйвера.
- Сохраняет все
stderrstdoutвыходные данные журнала иlog4jжурналов в журнале драйверов. - Невозможно преобразовать в вычислительный ресурс с несколькими узлами.
Выбор одного или нескольких узлов
Рассмотрим вариант использования при выборе между вычислительными ресурсами с одним или несколькими узлами:
Обработка крупномасштабных данных исчерпает ресурсы на одном вычислительном ресурсе узла. Для этих рабочих нагрузок Databricks рекомендует использовать вычислительные ресурсы с несколькими узлами.
Вычислительные ресурсы с одним узлом не предназначены для общего доступа. Чтобы избежать конфликтов ресурсов, Databricks рекомендует использовать вычислительный ресурс с несколькими узлами при совместном использовании вычислительных ресурсов.
Вычислительный ресурс с несколькими узлами нельзя масштабировать до 0 рабочих ролей. Вместо этого используйте вычислительные ресурсы с одним узлом.
Вычисление с одним узлом несовместимо с изоляцией процесса.
Планирование GPU не включено в вычислительных ресурсах одного узла.
При вычислении с одним узлом Spark не может считывать файлы Parquet с помощью столбца UDT. В результате появляется следующее сообщение об ошибке:
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.Чтобы обойти эту проблему, отключите собственное средство чтения Parquet:
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Режимы доступа
Режим доступа — это функция безопасности, которая определяет, кто может использовать вычислительный ресурс и данные, к которым они могут получить доступ с помощью вычислительного ресурса. Каждый вычислительный ресурс в Azure Databricks имеет режим доступа.
Databricks рекомендует использовать режим общего доступа для всех рабочих нагрузок. Используйте режим доступа с одним пользователем только в том случае, если необходимые функциональные возможности не поддерживаются режимом общего доступа.
| Режим доступа | Видимый пользователю | Поддержка каталога Unity | Поддерживаемые языки | Примечания. |
|---|---|---|---|---|
| Один пользователь | Всегда | Да | Python, SQL, Scala, R | Можно назначать и использовать одним пользователем. Называется назначенным режимом доступа в некоторых рабочих областях. |
| Совмещаемая блокировка | Всегда (требуется план "Премиум") | Да | Python (в Databricks Runtime 11.3 LTS и более поздних версиях), SQL, Scala (на вычислительных ресурсах с поддержкой каталога Unity с помощью Databricks Runtime 13.3 LTS и более поздних версий) | Может использоваться несколькими пользователями с изоляцией данных среди пользователей. |
| Отсутствие общей изоляции | Администраторы могут скрыть этот режим доступа, применяя изоляцию пользователей на странице параметров администратора. | No | Python, SQL, Scala, R | Существует связанный параметр уровня учетной записи для общих вычислений без изоляции. |
| Пользовательское | Скрытый (для всех новых вычислений) | No | Python, SQL, Scala, R | Этот параметр отображается только в том случае, если у вас есть существующий вычислительный ресурс без указанного режима доступа. |
Вы можете обновить существующий вычислительный ресурс, чтобы удовлетворить требования каталога Unity, задав режим доступа для одного пользователя или общего доступа. Подробные сведения о функциональных возможностях, поддерживаемых каждым из этих режимов доступа в рабочих областях с поддержкой каталога Unity, см. в разделе Об ограничениях режима доступа к вычислительным ресурсам каталога Unity.
Примечание.
В Databricks Runtime 13.3 LTS и более поздних версиях скрипты и библиотеки инициализации поддерживаются всеми режимами доступа. Требования и уровни поддержки различаются. См. статью " Где можно установить скрипты инициализации" и библиотеки с областью действия кластера.
Версии Databricks Runtime
Databricks Runtime — это набор основных компонентов, которые выполняются в вычислительных средах. Выберите среду выполнения с помощью раскрывающегося меню "Версия среды выполнения Databricks". Дополнительные сведения о конкретных версиях среды выполнения Databricks см. в заметках о выпуске Databricks и совместимости. Все версии включают Apache Spark. В Databricks рекомендуется следующее:
- Для всех целевых вычислений используйте самую последнюю версию, чтобы обеспечить последнюю оптимизацию и самую актуальную совместимость между кодом и предварительно загруженными пакетами.
- Для вычислений заданий, выполняющих операционные рабочие нагрузки, рекомендуется использовать версию среды выполнения Databricks(LTS). Использование версии LTS обеспечит отсутствие проблем совместимости и может тщательно протестировать рабочую нагрузку перед обновлением.
- Для вариантов использования для обработки и анализа данных и машинного обучения рассмотрите версию машинного обучения Databricks Runtime.
Использование ускорения фотона
Фотона включена по умолчанию для вычислений, работающих под управлением Databricks Runtime 9.1 LTS и более поздних версий.
Чтобы включить или отключить ускорение Фотона, установите флажок "Использовать ускорение фотона ". Дополнительные сведения о Фотоне см. в статье "Что такое Photon?".
Типы узлов рабочих и драйверов
Вычислительный ресурс состоит из одного узла драйвера и нуля или нескольких рабочих узлов. Можно выбрать отдельные типы экземпляров поставщика облачных служб для узлов драйверов и рабочих узлов, хотя по умолчанию узел драйвера использует тот же тип экземпляра, что и рабочий узел. Различные семейства типов экземпляров подходят для различных вариантов использования, таких как рабочие нагрузки, потребляющие большой объем памяти или вычислительных ресурсов.
Вы также можете выбрать пул для использования в качестве рабочего узла или узла драйвера. В качестве рабочего типа используется только пул с точечными экземплярами. Выберите отдельный тип драйвера по запросу, чтобы предотвратить восстановление драйвера. См. статью "Подключение к пулам".
Тип работника
В вычислительных ресурсах с несколькими узлами рабочие узлы запускают исполнителя Spark и другие службы, необходимые для правильного функционирования вычислительного ресурса. При распределении рабочей нагрузки с помощью Spark вся распределенная обработка выполняется на рабочих узлах. Azure Databricks запускает один исполнитель на каждый рабочий узел. Поэтому термины исполнителя и рабочей роли используются взаимозаменяемо в контексте архитектуры Databricks.
Совет
Для выполнения задания Spark требуется по меньшей мере один рабочий узел. Если вычислительный ресурс имеет нулевых рабочих ролей, вы можете выполнять команды, отличные от Spark, на узле драйвера, но команды Spark завершаются ошибкой.
IP-адреса рабочего узла
Azure Databricks запускает рабочие узлы с двумя частными IP-адресами. Основной частный IP-адрес узла содержит внутренний трафик Azure Databricks. Вторичный частный IP-адрес используется контейнером Spark для взаимодействия внутри кластера. Эта модель позволяет Azure Databricks обеспечить изоляцию между несколькими вычислительными ресурсами в одной рабочей области.
Тип драйвера
Узел драйвера сохраняет сведения о состоянии всех записных книжек, подключенных к вычислительному ресурсу. Узел драйвера также поддерживает SparkContext, интерпретирует все команды, выполняемые из записной книжки или библиотеки в вычислительном ресурсе, и запускает мастер Apache Spark, который координируется с исполнителями Spark.
Значение типа узла драйвера по умолчанию совпадает с типом рабочего узла. Если планируется collect() большой объем данных от рабочих ролей Spark и анализировать их в записной книжке, можно выбрать тип узла драйвера большего размера с большим объемом памяти.
Совет
Учитывая, что узел драйвера хранит все сведения о состоянии подключенных записных книжек, не забудьте отключить неиспользуемые записные книжки от узла драйвера.
Типы экземпляров GPU
Для вычислительных задач, требующих высокой производительности, таких как те, которые связаны с глубоким обучением, Azure Databricks поддерживает вычислительные ресурсы, ускоряемые с помощью единиц обработки графики (GPU). Дополнительные сведения см. в разделе вычислений с поддержкой GPU.
Виртуальные машины конфиденциальных вычислений Azure
Типы виртуальных машин конфиденциальных вычислений Azure предотвращают несанкционированный доступ к данным во время его использования, включая оператора облака. Этот тип виртуальной машины подходит для строго регулируемых отраслей и регионов, а также предприятий с конфиденциальными данными в облаке. Дополнительные сведения о конфиденциальных вычислениях Azure см. в статье о конфиденциальных вычислениях Azure.
Чтобы запустить рабочие нагрузки с помощью виртуальных машин конфиденциальных вычислений Azure, выберите из типов виртуальных машин серии DC или EC в раскрывающемся списке рабочих и драйверов. См . параметры конфиденциальной виртуальной машины Azure.
Экземпляры точечных виртуальных машин
Чтобы сэкономить средства, можно использовать экземпляры точечных виртуальных машин, которые также называются точечными виртуальными машинами Azure, установив флажок Экземпляры точечных виртуальных машин.

Первый экземпляр всегда будет предоставляться по запросу (узел драйвера всегда предоставляется по запросу), и последующие экземпляры будут экземплярами точечных виртуальных машин.
Если экземпляры вытесняться из-за недоступности, Azure Databricks попытается приобрести новые точечные экземпляры для замены вытеснения экземпляров. Если не удается получить точечные экземпляры, экземпляры по запросу развертываются для замены вытеснённых экземпляров. Это восстановление размещения по запросу поддерживается только для локальных экземпляров, которые были полностью приобретены и запущены. Точечные экземпляры, которые завершаются сбоем во время установки, не заменяются автоматически.
Кроме того, при добавлении новых узлов в существующие вычислительные ресурсы Azure Databricks пытается получить точечные экземпляры для этих узлов.
Включение автомасштабирования
При проверке автоматического масштабирования можно указать минимальное и максимальное количество рабочих ролей для вычислительного ресурса. Затем Databricks выбирает соответствующее количество рабочих ролей, необходимых для выполнения задания.
Чтобы задать минимальное и максимальное количество рабочих ролей, между вычислительным ресурсом будет автоматически масштабироваться, используйте поля Min и Max worker рядом с раскрывающимся списком "Рабочий тип ".
Если автомасштабирование не включено, необходимо ввести фиксированное число рабочих ролей в поле "Рабочие " рядом с раскрывающимся списком "Рабочий тип ".
Примечание.
При запуске вычислительного ресурса на странице сведений о вычислениях отображается количество выделенных рабочих ролей. Можно сравнить число выделенных рабочих ролей с конфигурацией рабочей роли и внести необходимые изменения.
Преимущества автомасштабирования
При автомасштабировании Azure Databricks динамически перераспределяет рабочие роли с учетом характеристик конкретного задания. Некоторые части конвейера могут быть более ресурсоемкими, чем другие, и Databricks автоматически добавляет дополнительные рабочие роли на данных этапах задания (и удаляют их, когда они перестают быть нужными).
Автоматическое масштабирование упрощает высокую загрузку, так как не требуется подготавливать вычислительные ресурсы для сопоставления рабочей нагрузки. Это относится, в частности, к рабочим нагрузкам, требования к которым изменяются с течением времени (например, исследование набора данных в течение дня), однако это также может относиться и к короткой одноразовой рабочей нагрузке с неизвестными требованиями к подготовке. Таким образом, автомасштабирование предоставляет два преимущества:
- Рабочие нагрузки могут выполняться быстрее по сравнению с недостаточно подготовленным вычислительным ресурсом постоянного размера.
- Автоматическое масштабирование может снизить общие затраты по сравнению со статическим вычислительным ресурсом.
В зависимости от постоянного размера вычислительного ресурса и рабочей нагрузки автоматическое масштабирование обеспечивает одно или оба этих преимущества одновременно. Размер вычислений может быть ниже минимального количества рабочих ролей, выбранных при завершении экземпляров поставщиком облачных служб. В этом случае Azure Databricks постоянно предпринимает попытки повторной инициализации экземпляров для сохранения минимального числа рабочих ролей.
Примечание.
Автомасштабирование недоступно для заданий spark-submit.
Примечание.
Автоматическое масштабирование вычислений имеет ограничения, ограничивающие размер кластера для структурированных рабочих нагрузок потоковой передачи. Databricks рекомендует для потоковых рабочих нагрузок использовать разностные динамические таблицы (Delta Live Tables) с расширенным автомасштабированием. См. статью "Оптимизация использования кластеров конвейеров Delta Live Tables с расширенным автомасштабированием".
Как осуществляется автомасштабирование
Рабочая область плана Premium использует оптимизированное автомасштабирование. Рабочие области в стандартном ценовом плане используют стандартную автомасштабирование.
Оптимизированное автомасштабирование имеет следующие характеристики:
- Увеличение масштаба с минимального до максимального за два этапа.
- Может уменьшить масштаб, даже если вычислительный ресурс неактивен, просматривая состояние файла перетасовки.
- Поддерживается уменьшение масштаба с учетом процента текущих узлов.
- При вычислении задания масштабируется, если вычислительный ресурс не используется за последние 40 секунд.
- Если вычислительный ресурс не используется за последние 150 секунд, масштабируется на всех целевых вычислительных ресурсах.
- Свойство
spark.databricks.aggressiveWindowDownSконфигурации Spark указывает в секундах частоту принятия решений по уменьшению масштаба вычислений. Увеличение значения приводит к замедлению масштабирования вычислений. Максимальное значение — 600.
Автомасштабирование уровня "Стандартный" используется в рабочих областях стандартного плана. Стандартная автомасштабирование имеет следующие характеристики:
- Начинается с добавления 8 узлов. Затем масштабируется экспоненциально, принимая столько шагов, сколько требуется для достижения максимальной величины.
- Выполняется уменьшение масштаба, если 90% узлов не занято в течение 10 минут, и вычисление неактивно в течение не менее 30 секунд.
- Поддерживается экспоненциальное уменьшение масштаба, начиная с 1 узла.
Автомасштабирование с пулами
Если вы подключаете вычислительный ресурс к пулу, рассмотрите следующее:
Убедитесь, что запрошенный размер вычислительных ресурсов меньше или равен минимальному количеству экземпляров простоя в пуле. Если это больше, время запуска вычислений будет эквивалентно вычислениям, которые не используют пул.
Убедитесь, что максимальный размер вычислительных ресурсов меньше или равен максимальной емкости пула. Если это больше, создание вычислений завершится ошибкой.
Пример автомасштабирования
При перенастройке статического вычислительного ресурса для автомасштабирования Azure Databricks немедленно изменяет размер вычислительного ресурса в пределах минимальной и максимальной границы, а затем запускает автомасштабирование. Например, в следующей таблице показано, что происходит с вычислительным ресурсом с определенным начальным размером при перенастройке вычислительного ресурса для автомасштабирования между 5 и 10 узлами.
| Начальный размер | Размер после изменения настройки |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Включение автоматического масштабирования локального хранилища
Зачастую бывает трудно оценить, сколько дискового пространства потребуется на определенное задание. Чтобы сэкономить от необходимости оценить количество гигабайт управляемых дисков для подключения к вычислительным ресурсам во время создания, Azure Databricks автоматически включает автоматическое масштабирование локального хранилища во всех вычислительных ресурсах Azure Databricks.
При автоматическом масштабировании локального хранилища Azure Databricks отслеживает объем свободного места на диске, доступного для рабочих ролей Spark вычислений. Если рабочая роль начинает выполняться на диске слишком медленно, то модуль обработки данных автоматически присоединяет новый управляемый диск к рабочей роли до того, как на нем закончится свободное место. Диски присоединяются до достижения общего объема дискового пространства 5 ТБ для каждой виртуальной машины (включая исходное локальное хранилище виртуальной машины).
Управляемые диски, присоединенные к виртуальной машине, отсоединяются только при возврате виртуальной машины в Azure. То есть управляемые диски никогда не отсоединяются от виртуальной машины, пока они являются частью запущенных вычислений. Чтобы уменьшить использование управляемого диска, Azure Databricks рекомендует использовать эту функцию в вычислительных ресурсах, настроенных с автомасштабированием вычислений или автоматическим завершением.
Шифрование локальных дисков
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
Некоторые типы экземпляров, используемые для запуска вычислений, могут иметь локальные подключенные диски. Azure Databricks может хранить данные в произвольном порядке или временные данные на этих локально присоединенных дисках. Чтобы обеспечить шифрование всех неактивных данных для всех типов хранилища, включая перетасовку данных, хранящихся временно на локальных дисках вычислительного ресурса, можно включить шифрование локальных дисков.
Внимание
Рабочие нагрузки могут выполняться медленнее из-за влияния на производительность операций чтения и записи зашифрованных данных в локальных томах.
Если шифрование локального диска включено, Azure Databricks создает ключ шифрования локально, уникальный для каждого вычислительного узла и используется для шифрования всех данных, хранящихся на локальных дисках. Область ключа является локальной для каждого вычислительного узла и уничтожается вместе с самим вычислительным узлом. На протяжении времени существования ключ находится в памяти для целей шифрования и расшифровки и хранится на диске в зашифрованном виде.
Чтобы включить шифрование локальных дисков, необходимо использовать API кластеров. Во время создания или редактирования вычислений задайте значение enable_local_disk_encryption true.
Автоматическое завершение
Вы можете настроить автоматическое завершение вычислений. Во время создания вычислений укажите период бездействия в минутах, после которого требуется завершить работу вычислительного ресурса.
Если разница между текущим временем и последней командой, выполняемой на вычислительном ресурсе, превышает указанный период бездействия, Azure Databricks автоматически завершает вычисление. Ресурс Для получения дополнительных сведений о завершении вычислений см. раздел "Завершение вычисления".
Теги
Теги позволяют легко отслеживать стоимость облачных ресурсов, используемых различными группами в организации. Укажите теги в качестве пар "ключ-значение" при создании вычислений, а Azure Databricks применяет эти теги к облачным ресурсам, таким как виртуальные машины и тома дисков, а также отчеты об использовании DBU.
Для вычислений, запускаемых из пулов, пользовательские теги применяются только к отчетам об использовании DBU и не распространяется на облачные ресурсы.
Подробные сведения о совместной работе типов тегов пула и вычислительных тегов см. в разделе "Мониторинг использования с помощью тегов"
Чтобы добавить теги в вычислительный ресурс, выполните приведенные далее действия.
- В разделе "Теги" добавьте пару "ключ-значение" для каждого пользовательского тега.
- Нажмите кнопку Добавить.
Конфигурация Spark
Чтобы точно настроить задания Spark, можно указать настраиваемые свойства конфигурации Spark.
На странице конфигурации вычислений щелкните переключатель "Дополнительные параметры ".
Перейдите на вкладку Spark.
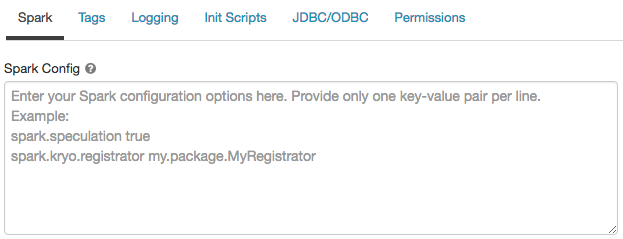
В файле конфигурации Spark укажите свойства конфигурации в виде одной пары «ключ-значение» в каждой строке.
При настройке вычислений с помощью API кластеров задайте свойства Spark в поле в spark_conf api создания кластера или API обновления кластера.
Чтобы применить конфигурации Spark к вычислительным ресурсам, администраторы рабочих областей могут использовать политики вычислений.
Получение свойства конфигурации Spark из секрета
Databricks рекомендует хранить конфиденциальные данные, такие как пароли, в формате секрета, а не в формате обычного текста. Чтобы создать ссылку на секрет в конфигурации Spark, используйте следующий синтаксис:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Например, чтобы настроить для свойства конфигурации Spark с именем password значение секрета, хранящегося в secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Дополнительные сведения см. в разделе Синтаксис для создания ссылок на секреты в свойстве конфигурации Spark или переменной среды.
SSH-доступ к вычислительным ресурсам
По соображениям безопасности в Azure Databricks порт SSH закрыт по умолчанию. Если вы хотите включить SSH-доступ к кластерам Spark, обратитесь к узлу драйвера SSH.
Примечание.
SSH можно включить, только если рабочая область развернута в вашей собственной виртуальной сети Azure.
Переменные среды
Настройте настраиваемые переменные среды, к которым можно получить доступ из скриптов инициализации, работающих на вычислительном ресурсе. Databricks также предоставляет предопределенные переменные среды, которые можно использовать в этих скриптах. Эти предопределенные переменные среды нельзя переопределить.
На странице конфигурации вычислений щелкните переключатель "Дополнительные параметры ".
Перейдите на вкладку Spark.
Задайте переменные среды в поле Переменные среды.
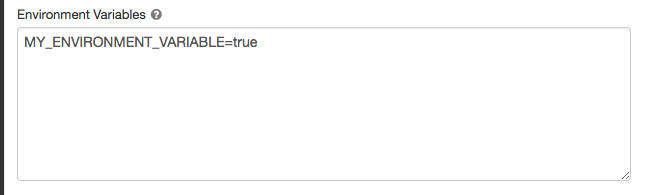
Можно также задать переменные среды с помощью spark_env_vars поля в API создания кластера или API обновления кластера.
Доставка журналов вычислений
При создании вычислений можно указать расположение для доставки журналов для узла драйвера Spark, рабочих узлов и событий. Журналы доставляются каждые пять минут и архивируются почасово в выбранном месте назначения. После завершения вычислительного ресурса Azure Databricks гарантирует доставку всех журналов, созданных до завершения вычислительного ресурса.
Назначение журналов зависит от вычислительных ресурсов cluster_id. Если задано назначение dbfs:/cluster-log-delivery, вычислительные журналы для 0630-191345-leap375 доставки передаются dbfs:/cluster-log-delivery/0630-191345-leap375в .
Чтобы настроить целевое расположение для доставки журналов, выполните следующие действия.
- На странице вычислений щелкните переключатель "Дополнительные параметры ".
- Перейдите на вкладку Ведение журнала.
- Выберите целевой тип.
- Введите путь к журналу вычислений.
Примечание.
Эта функция также доступна в REST API. См. API кластеров.