Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описываются основные различия между пакетной и потоковой передачей, две разные семантики обработки данных, используемые для рабочих нагрузок проектирования данных, включая прием, преобразование и обработку в режиме реального времени.
Потоковая передача обычно ассоциируется с низкой задержкой и непрерывной обработкой через системы обмена сообщениями, такие как Apache Kafka.
Однако в Azure Databricks он имеет более обширное определение. Базовый модуль декларативных конвейеров Lakeflow (Apache Spark и структурированная потоковая передача) имеет унифицированную архитектуру для пакетной и потоковой обработки:
- Модуль может рассматривать такие источники, как облачное хранилище объектов и Delta Lake , как источники потоковой передачи для эффективной добавочной обработки.
- Потоковая обработка может выполняться в триггерном или непрерывном режиме, обеспечивая гибкость в управлении затратами и производительностью для стриминговых рабочих нагрузок.
Ниже приведены основные семантические различия между пакетной и потоковой обработкой, включая их преимущества и недостатки, и соображения по их выбору для ваших рабочих нагрузок.
Семантика пакетной обработки
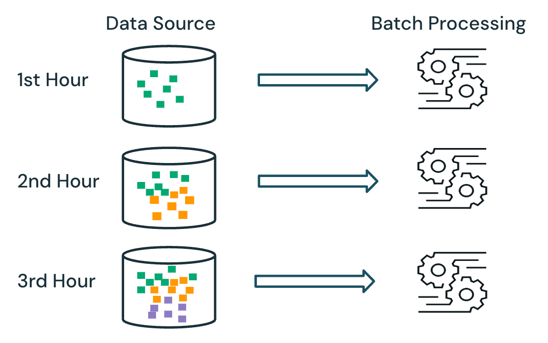
При пакетной обработке подсистема не отслеживает, какие данные уже обрабатываются в источнике. Все данные, доступные в настоящее время в источнике, обрабатываются во время обработки. На практике источник пакетных данных обычно секционируется логически, например по дням или регионам, чтобы ограничить обработку данных.
Например, вычисление средней цены продажи товара, агрегированное по часовой детализации, для мероприятия по продажам, проводимого компанией электронной коммерции, можно запланировать как пакетную обработку, чтобы вычислять среднюю цену продаж каждый час. При пакетной обработке данных из предыдущих часов каждый час выполняется повторная обработка, а ранее вычисляемые результаты перезаписываются для отражения последних результатов.
Семантика потоковой передачи
При потоковой обработке подсистема отслеживает обработку данных и обрабатывает только новые данные в последующих запусках. В приведенном выше примере можно запланировать потоковую обработку вместо пакетной обработки, чтобы вычислить среднюю цену продаж каждый час. При потоковой передаче только новые данные, добавленные в источник с момента последнего выполнения, обрабатываются. Новые вычисляемые результаты должны быть добавлены к ранее вычисляемым результатам, чтобы проверить полные результаты.
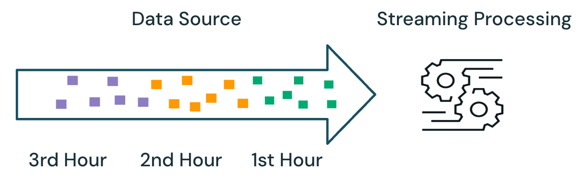
Пакетная передача и потоковая передача
В приведенном выше примере потоковая передача лучше пакетной обработки, так как она не обрабатывает те же данные, обработанные в предыдущих запусках. Однако потоковая обработка становится более сложной с сценариями, такими как устаревшие и поздние данные прибытия в источнике.
Пример позднего поступления данных: некоторые данные о продажах за первый час поступают в систему только ко второму часу.
- При пакетной обработке данные позднего прибытия из первого часа будут обрабатываться вместе с данными второго часа и существующими данными из первого часа. Предыдущие результаты за первый час будут перезаписаны и исправлены на основе данных о поздних прибытиях.
- При потоковой обработке поздно поступающие данные с первого часа будут обрабатываться без учета других данных первого часа, которые уже были обработаны. Логика обработки должна хранить сведения о сумме и подсчете данных из средних вычислений первого часа, чтобы правильно обновить предыдущие результаты.
Эти сложности потоковой передачи обычно возникают при обработке с учетом состояния, таких как соединения, агрегации и дедупликации.
Для потоковой обработки без состояния, например добавления новых данных из источника, обработка неупорядоченных и поздно поступающих данных менее сложна, так как данные, поступающие с задержкой, можно добавлять к предыдущим результатам по мере поступления данных из источника.
В таблице ниже описаны преимущества и минусы пакетной и потоковой обработки, а также различные функции продукта, поддерживающие эти две семантики обработки в Databricks Lakeflow.
| Партия | Стриминг | |
|---|---|---|
| Плюсы |
|
|
| Минусы |
|
|
| Продукты проектирования данных |
|
|
Рекомендации
В таблице ниже описана рекомендуемая семантика обработки на основе характеристик рабочих нагрузок обработки данных на каждом уровне архитектуры медальона.
| Слой медальона | Характеристики рабочей нагрузки | Рекомендация |
|---|---|---|
| Бронза |
|
|
| Серебро |
|
|
| Золото |
|
|