Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Примечание.
Databricks Connect рекомендует использовать Databricks Connect для Databricks Runtime 13.0 и выше .
Databricks не планирует использовать новую функцию для Databricks Connect для Databricks Runtime 12.2 LTS и ниже.
Databricks Connect позволяет подключать популярные идентификаторы, такие как Visual Studio Code и PyCharm, серверы записных книжек и другие пользовательские приложения к кластерам Azure Databricks.
В этой статье объясняется, как работает Databricks Connect, пошаговые инструкции по началу работы с Databricks Connect, объясняется, как устранять неполадки, которые могут возникнуть при использовании Databricks Connect, а также различия между запуском с помощью Databricks Connect и запуском в записной книжке Azure Databricks.
Обзор
Databricks Connect — это клиентская библиотека для среды выполнения Databricks. Она позволяет создавать задания с помощью API Spark и запускать их удаленно в кластере Azure Databricks, а не в локальном сеансе Spark.
Например, при выполнении команды spark.read.format(...).load(...).groupBy(...).agg(...).show() DataFrame с помощью Databricks Connect логическое представление команды отправляется на сервер Spark, работающий в Azure Databricks для выполнения в удаленном кластере.
Databricks Connect позволяет:
- Выполнение крупномасштабных заданий Spark из любого приложения Python, R, Scala или Java. В любом месте
import pysparkrequire(SparkR)import org.apache.sparkможно выполнять задания Spark непосредственно из приложения без необходимости устанавливать подключаемые модули интегрированной среды разработки или использовать скрипты отправки Spark. - Пошаговое выполнение и отладка кода в среде IDE даже при работе с удаленным кластером.
- Быстрое выполнение итерации при разработке библиотек. Перезапускать кластер после изменения зависимостей библиотеки Python или Java в Databricks Connect не требуется, так как каждый сеанс клиента изолирован друг от друга в кластере.
- Завершайте работу бездействующих кластеров без потери работы. Так как клиентское приложение отделяется от кластера, на него не влияют перезагрузки или обновления кластера, что обычно приводит к потере всех переменных, RDD и объектов кадров данных, определенных в записной книжке.
Примечание.
Для разработки на Python с запросами SQL, Databricks рекомендует использовать Соединитель Databricks SQL Connector для Python, а не модуль Databricks Connect. Соединитель Databricks SQL Connector для Python настраивается проще, чем Databricks Connect. Кроме того, Databricks Connect анализирует и планирует выполнение заданий на локальном компьютере, а выполняются они на удаленных ресурсах вычислений. Это может усложнить отладку ошибок времени выполнения. Соединитель Databricks SQL Connector для Python отправляет запросы SQL непосредственно к удаленным ресурсам вычислений и извлекает результаты.
Требования
В этом разделе перечислены требования для Databricks Connect.
Поддерживаются только указанные далее версии Databricks Runtime:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime версии 10.4 LTS ML, Databricks Runtime версии 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
Необходимо установить Python 3 на компьютере разработки, а дополнительная версия клиентской установки Python должна совпадать с дополнительной версией Python кластера Azure Databricks. В следующей таблице показана версия Python, установленная для каждой среды выполнения Databricks.
Версия Databricks Runtime Версия Python 12.2 LTS ML, 12.2 LTS 3,9 11.3 LTS ML, 11.3 LTS 3,9 10.4 LTS ML, 10.4 LTS 3,8 9.1 LTS ML, 9.1 LTS 3,8 7.3 LTS 3,7 Databricks настоятельно рекомендует активировать виртуальную среду Python для каждой версии Python, которая используется с Databricks Connect. Виртуальные среды Python помогают убедиться, что вы используете правильные версии Python и Databricks Connect вместе. Это может помочь сократить время, затраченное на устранение связанных технических проблем.
Например, если вы используете venv на компьютере разработки и кластер работает под управлением Python 3.9, необходимо создать
venvсреду с этой версией. В следующем примере команды создаются скрипты для активацииvenvсреды с помощью Python 3.9, а затем эта команда помещает эти скрипты в скрытую папку.venvс именем в текущем рабочем каталоге:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvСведения об использовании этих скриптов для активации этой
venvсреды см. в статье о работе venvs.В качестве другого примера, если вы используете Conda на компьютере разработки и кластер работает под управлением Python 3.9, необходимо создать среду Conda с этой версией, например:
conda create --name dbconnect python=3.9Чтобы активировать среду Conda с этим именем среды, выполните команду
conda activate dbconnect.Основная и дополнительная версии пакета Databricks Connect всегда должны соответствовать версии Databricks Runtime. Рекомендуется всегда использовать последнюю версию пакета Databricks Connect, соответствующую версии Databricks Runtime. Например, при использовании кластера Databricks Runtime 12.2 LTS необходимо также использовать
databricks-connect==12.2.*пакет.Примечание.
Список доступных выпусков Databricks Connect и обновлений обслуживания см. в разделе Заметки о выпуске Databricks Connect.
Среда выполнения Java (JRE) 8. Клиент был протестирован с OpenJDK 8 JRE. Клиент не поддерживает Java 11.
Примечание.
Если в Windows отображается ошибка, что Databricks Connect не может найти winutils.exe, см. статью «Не удается найти winutils.exe в Windows».
Настройка клиента
Выполните следующие действия, чтобы настроить локальный клиент для Databricks Connect.
Примечание.
Прежде чем приступить к настройке локального клиента Databricks Connect, необходимо выполнить требования для Databricks Connect.
Шаг 1. Установка клиента Databricks Connect
После активации виртуальной среды удалите PySpark, если оно уже установлено, выполнив
uninstallкоманду. Это необходимо, так как пакетdatabricks-connectконфликтует с PySpark. Дополнительные сведения см. в разделе Конфликтующие установки PySpark. Чтобы проверить, установлен ли PySpark, выполнитеshowкоманду.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkПри активации виртуальной среды установите клиент Databricks Connect, выполнив
installкоманду.--upgradeИспользуйте параметр для обновления любой существующей установки клиента до указанной версии.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Примечание.
Databricks рекомендует добавить нотацию dot-asterisk, чтобы указать
databricks-connect==X.Y.*вместо нееdatabricks-connect=X.Y, чтобы убедиться, что установлен последний пакет.
Шаг 2: Настройка свойств подключения
Соберите следующие свойства конфигурации.
URL-адрес azure Databricks для каждой рабочей области. Это также совпадает со
https://значением имени узла сервера для кластера. Дополнительные сведения о подключении для вычислительного ресурса Azure Databricks см. в статье>. Ваш личный маркер доступа Azure Databricks или маркер Microsoft Entra ID (прежнее название — Azure Active Directory).
- Для сквозного прохождения учетных данных Azure Data Lake Storage (ADLS) необходимо использовать маркер идентификатора Microsoft Entra. Сквозное руководство по учетным данным идентификатора Microsoft Entra поддерживается только в кластерах уровня "Стандартный" под управлением Databricks Runtime 7.3 LTS и выше и несовместимо с проверкой подлинности субъекта-службы.
- Дополнительные сведения о проверке подлинности с помощью маркеров идентификатора Microsoft Entra см. в разделе "Проверка подлинности с помощью маркеров идентификатора Microsoft Entra".
Идентификатор вашего классического вычислительного ресурса. Вы можете получить классический идентификатор вычислений из URL-адреса. Идентификатор представлен как
1108-201635-xxxxxxxx. См. также URL-адрес и идентификатор ресурса вычислений.
Уникальный идентификатор организации для вашей рабочей области. См. сведения о получении идентификаторов для объектов рабочей области.
Порт, к которому подключается Databricks Connect в кластере. По умолчанию используется порт
15001. Если кластер настроен для использования другого порта, например8787, который был указан в предыдущих инструкциях для Azure Databricks, используйте настроенный номер порта.
Настройте подключение следующим образом.
Можно использовать CLI, конфигурации SQL или переменные среды. Приоритет методов настройки от самого высокого до самого низкого: ключи конфигурационные SQL, CLI и переменные среды.
интерфейс командной строки (CLI)
Запустите
databricks-connect.databricks-connect configureОтображение лицензии:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Примите условия лицензии и укажите значения конфигурации. В поле Узел Databricks и Токен Databricks введите URL-адрес рабочей области и личный токен доступа, записанный в шаге 1.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Если вы получаете сообщение о том, что маркер идентификатора Microsoft Entra слишком длинный, вы можете оставить поле маркера Databricks пустым и вручную ввести
~/.databricks-connectмаркер.
Конфигурации SQL или переменные среды. В следующей таблице приведены ключи конфигурации SQL и переменные среды, соответствующие свойствам конфигурации, записанным на шаге 1. Чтобы задать ключ конфигурации SQL, используйте
sql("set config=value"). Например:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Параметр Ключ конфигурации SQL Имя переменной среды Узел Databricks spark.databricks.service.address DATABRICKS_ADDRESS Токен Databricks spark.databricks.service.token DATABRICKS_API_TOKEN Идентификатор кластера spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID Идентификатор организации spark.databricks.service.orgId DATABRICKS_ORG_ID Порт spark.databricks.service.port DATABRICKS_PORT
При активации виртуальной среды проверьте подключение к Azure Databricks следующим образом.
databricks-connect testЕсли настроенный кластер не запущен, тест запускает кластер, который останется запущенным до истечения заданного времени автоматического завершения. Результат должен выглядеть следующим образом:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiЕсли ошибки, связанные с подключением, не отображаются (
WARNсообщения в порядке), вы успешно подключились.
Использование Databricks Connect
В этом разделе описывается настройка предпочтительной интегрированной среды разработки или сервера записной книжки для использования клиента для Databricks Connect.
В этом разделе рассматриваются следующие вопросы.
- JupyterLab
- Классическая записная книжка Jupyter
- PyCharm
- SparkR и RStudio Desktop
- sparklyr и RStudio Desktop
- IntelliJ (Scala или Java)
- PyDev с Eclipse
- Затмение
- SBT
- Оболочка Spark
JupyterLab
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Чтобы использовать Databricks Connect с JupyterLab и Python, следуйте этим инструкциям.
Чтобы установить JupyterLab с активированной виртуальной средой Python, выполните следующую команду из терминала или командной строки:
pip3 install jupyterlabЧтобы запустить JupyterLab в веб-браузере, выполните следующую команду из активированной виртуальной среды Python:
jupyter labЕсли JupyterLab не отображается в веб-браузере, скопируйте URL-адрес, начинающийся с
localhostили127.0.0.1, из вашей виртуальной среды, и введите его в адресную строку веб-браузера.Создайте записную книжку: в JupyterLab щелкните Файл новой записной книжки в главном меню, выберите > и нажмите кнопку ">".
В первой ячейке записной книжки введите пример кода или собственный код. Если вы используете собственный код, необходимо создать экземпляр экземпляра
SparkSession.builder.getOrCreate(), как показано в примере кода.Чтобы запустить записную книжку, нажмите кнопку "Выполнить > все ячейки".
Чтобы выполнить отладку записной книжки, щелкните значок ошибки (включить отладчик) рядом с Python 3 (ipykernel) на панели инструментов записной книжки. Установите одну или несколько точек останова и нажмите кнопку "Выполнить > все ячейки".
Чтобы завершить работу JupyterLab, нажмите кнопку >Завершить работу файла". Если процесс JupyterLab по-прежнему выполняется в терминале или командной строке, остановите этот процесс, нажав
Ctrl + cи введяyдля подтверждения.
Дополнительные инструкции по отладке см. в разделе "Отладчик".
Классическая записная книжка Jupyter
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Скрипт конфигурации для Databricks Connect автоматически добавляет пакет в конфигурацию проекта. Чтобы приступить к работе в ядре Python, выполните:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Чтобы включить сокращение %sql для запуска и визуализации запросов SQL, используйте следующий фрагмент кода:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Чтобы использовать Databricks Connect с Visual Studio Code, сделайте следующее:
Убедитесь, что расширение Python установлено.
Откройте палитру команд (Command+Shift+P на macOS и Ctrl+Shift+P на Windows / Linux).
Выбор интерпретатора Python Перейдите по пути Код > Настройки > Параметры и выберите настройки Python.
Запустите
databricks-connect get-jar-dir.Добавьте каталог, возвращенный из команды, в параметры пользователя JSON в разделе
python.venvPath. Его следует добавить в конфигурацию Python.Отключите анализатор кода. Нажмите … справа и измените параметры JSON. Изменены следующие параметры:
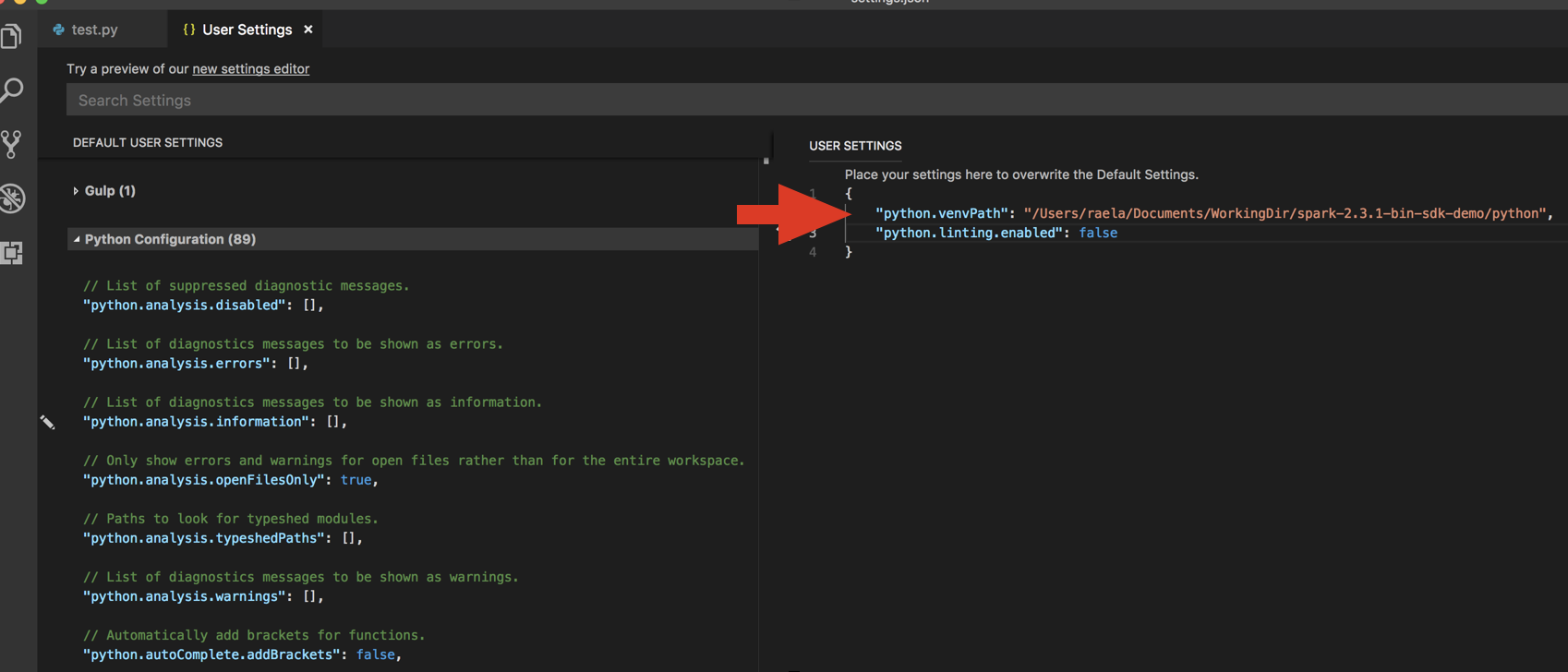
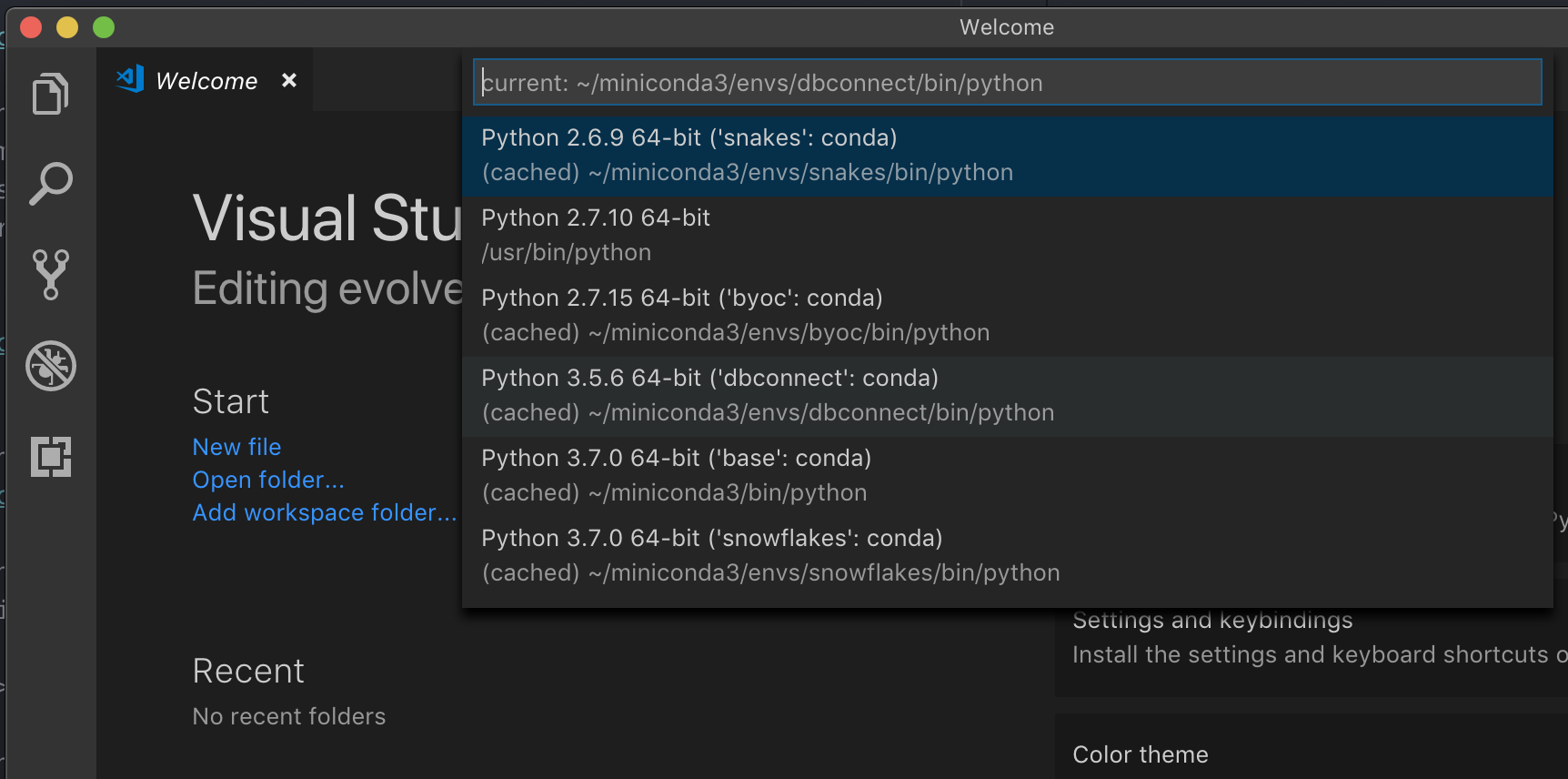
При работе с виртуальной средой, которая является рекомендуемым способом разработки для Python в VS Code, в палитре команд введите
select python interpreterи укажите среду, которая соответствует версии Python для кластера.
Например, если кластер — Python 3.9, среда разработки должна быть Python 3.9.
PyCharm
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Скрипт конфигурации для Databricks Connect автоматически добавляет пакет в конфигурацию проекта.
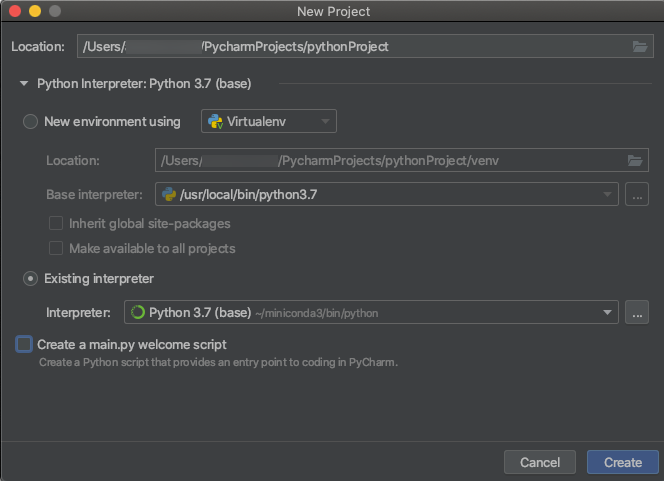
Кластеры Python 3
При создании проекта PyCharm выберите Существующий интерпретатор. В раскрывающемся меню выберите созданную среду Conda (см. раздел Требования).
Выберите Запуск > Изменить конфигурации.
Добавьте
PYSPARK_PYTHON=python3как переменную среды.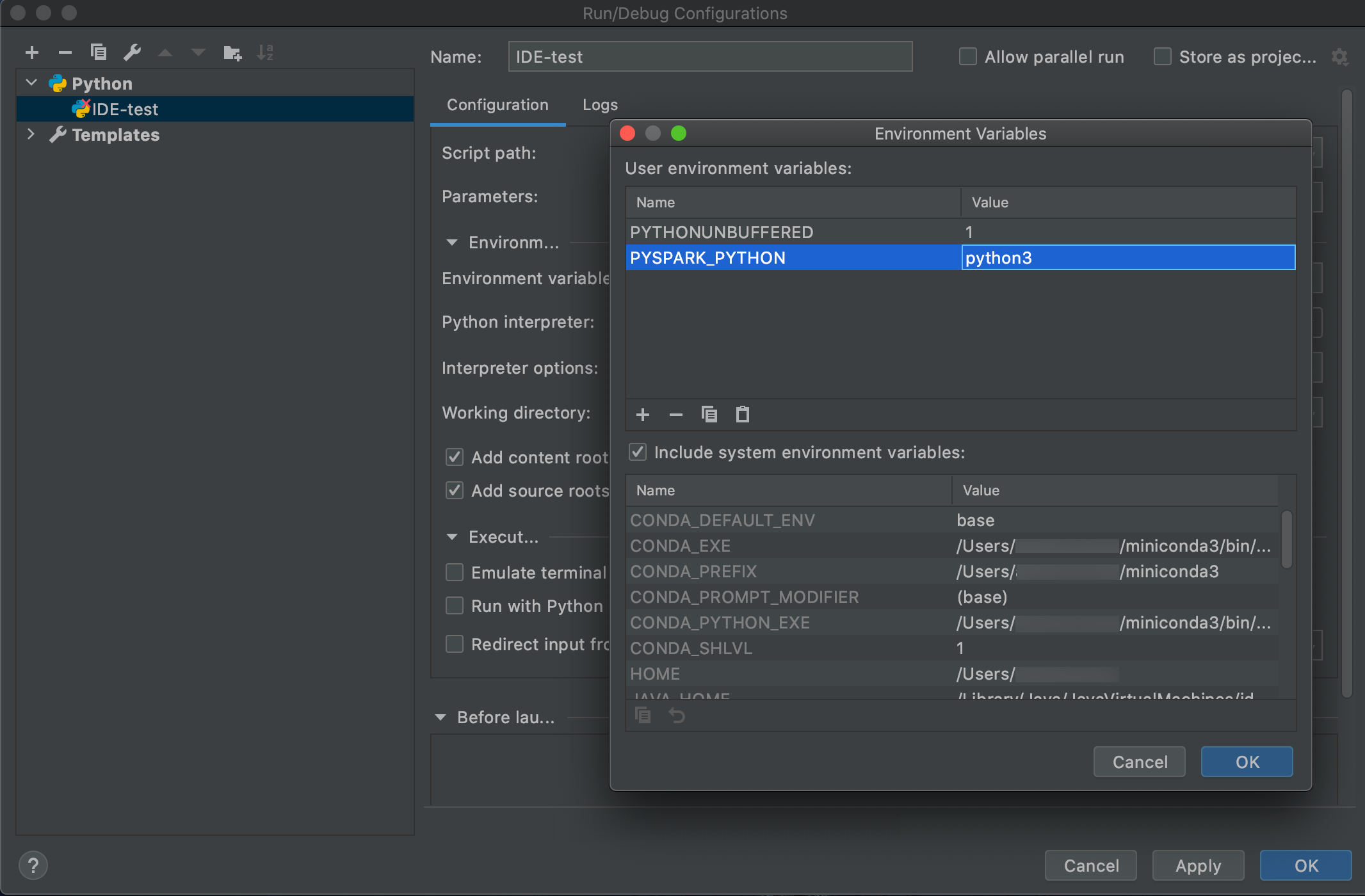
SparkR и RStudio Desktop
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Чтобы использовать Databricks Connect с SparkR и RStudio Desktop, сделайте следующее:
Скачайте и распакуйте дистрибутив открытый код Spark на компьютер разработки. Выберите ту же версию, что и в кластере Azure Databricks (Hadoop 2.7).
Запустите
databricks-connect get-jar-dir. Эта команда возвращает путь, например/usr/local/lib/python3.5/dist-packages/pyspark/jars. Скопируйте путь к файлу одного каталога над путем к файлу каталога JAR, например,/usr/local/lib/python3.5/dist-packages/pyspark, который является каталогомSPARK_HOME.Настройте путь к библиотеке Spark и домашнюю страницу Spark, добавив их в начало скрипта R. Укажите значение
<spark-lib-path>для каталога, в котором был распакован пакет Spark с открытым исходным кодом на шаге 1. Задайте значение<spark-home-path>для каталога Databricks Connect из шага 2.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Запустите сеанс Spark и начните выполнение команд SparkR.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr и RStudio Desktop
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
Вы можете скопировать зависимый от sparklyr код, разработанный локально с помощью Databricks Connect, и запустить его в записной книжке Azure Databricks или размещенном сервере RStudio в рабочей области Azure Databricks с минимальным или без изменений кода.
В этом разделе рассматриваются следующие вопросы.
- Требования
- Установка, настройка и использование sparklyr
- Ресурсы
- Ограничения sparklyr и RStudio Desktop
Требования
- sparklyr 1.2 или более поздней версии.
- Databricks Runtime 7.3 LTS или более поздней версии Databricks Connect.
Установка, настройка и использование sparklyr
В RStudio Desktop установите sparklyr 1.2 или более поздней версии из CRAN или установите последнюю основную версию из GitHub.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Активируйте среду Python с правильной версией Databricks Connect и выполните следующую команду в терминале, чтобы получить
<spark-home-path>следующую команду:databricks-connect get-spark-homeЗапустите сеанс Spark и начните выполнение команд sparklyr.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countЗакройте подключение.
spark_disconnect(sc)
Ресурсы
Дополнительные сведения см. в файле README sparklyr GitHub.
Примеры кода см. в разделе sparklyr.
Ограничения sparklyr и RStudio Desktop
Следующие возможности не поддерживаются:
- API потоковой передачи sparklyr
- API машинного обучения sparklyr
- API broom
- режим сериализации csv_file
- Отправка spark
IntelliJ (Scala или Java)
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Чтобы использовать Databricks Connect с IntelliJ (Scala или Java), выполните следующие действия:
Запустите
databricks-connect get-jar-dir.Укажите зависимости к каталогу, возвращенному из команды. Перейдите к Файл > Структура проекта > Модули > Зависимости > значок '+' > JAR-архивы или каталоги.
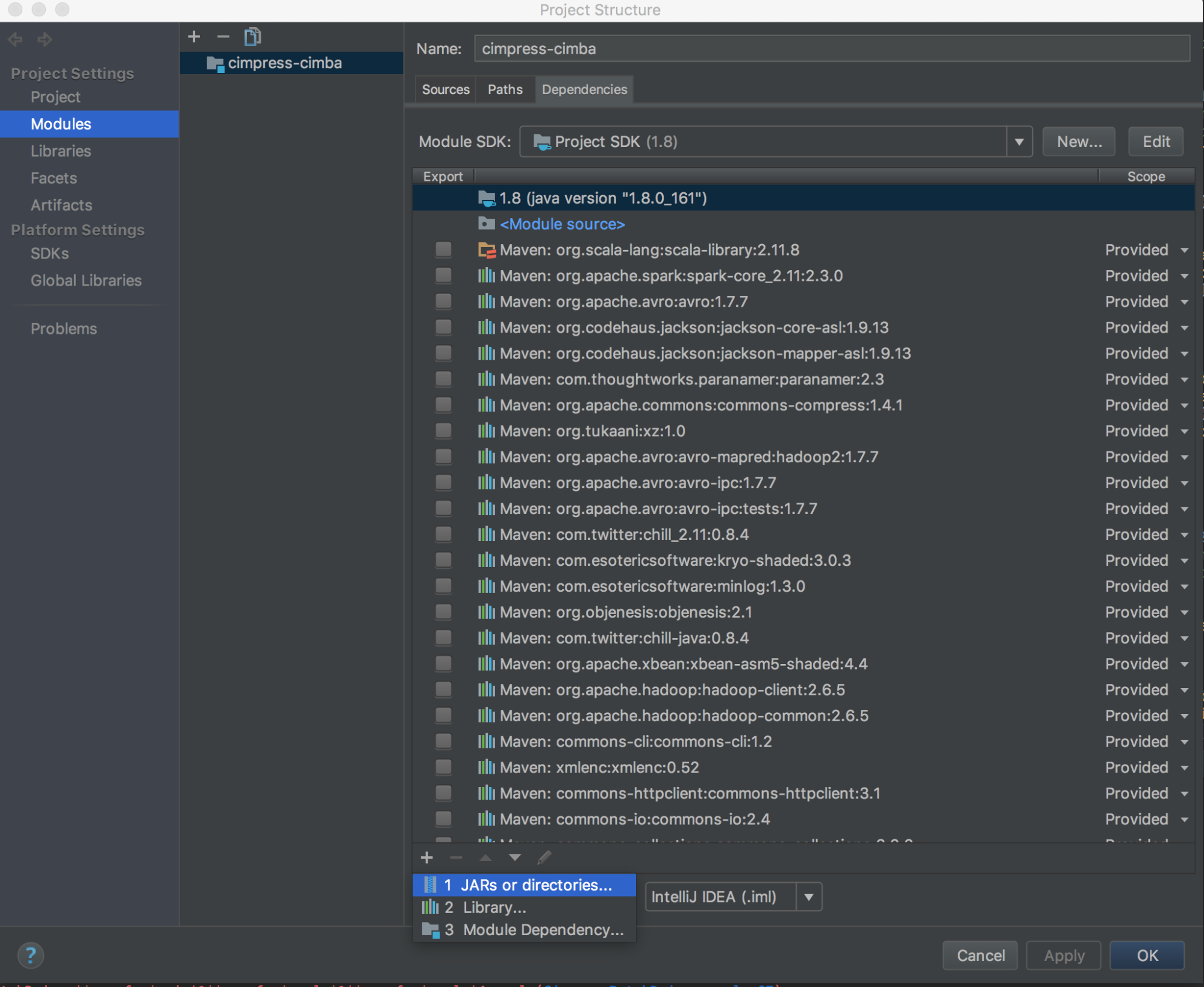
Во избежание конфликтов настоятельно рекомендуется удалить все остальные установки Spark из подкаталогов классов. Если это невозможно, убедитесь, что добавляемый JAR находится в начале подкаталогов классов. В частности, они должны опережать любую другую установленную версию Spark (в противном случае вы будете использовать одну из этих версий Spark и запускать ее локально или создавать
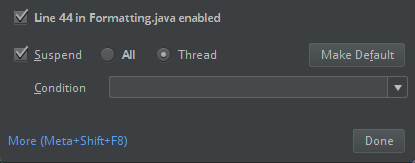
ClassDefNotFoundError).Проверьте значение параметра прерываний в IntelliJ. Значение по умолчанию — All и вызовет тайм-ауты сети при установке точек останова для отладки. Задайте для него значение Поток, чтобы избежать остановки фоновых сетевых потоков.
PyDev с Eclipse
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Чтобы использовать Databricks Connect и PyDev с Eclipse, следуйте этим инструкциям.
- Запустите Eclipse.
- Создайте проект: нажмите кнопку "Файл > нового > проекта PyDev > PyDev" >и нажмите кнопку "Далее".
- Укажите имя проекта.
- Для содержимого проекта укажите путь к виртуальной среде Python.
- Прежде чем продолжить, нажмите кнопку "Настроить интерпретатор".
- Щелкните конфигурацию вручную.
- Нажмите кнопку "Создать > обзор" для python/pypy exe.
- Перейдите и выберите полный путь к интерпретатору Python, на который ссылается виртуальная среда, и нажмите кнопку "Открыть".
- В диалоговом окне "Выбор интерпретатора" нажмите кнопку "ОК".
- В диалоговом окне "Выбор" нажмите кнопку "ОК".
- В диалоговом окне "Параметры" нажмите кнопку "Применить" и "Закрыть".
- В диалоговом окне "Проект PyDev" нажмите кнопку "Готово".
- Нажмите кнопку "Открыть перспективу".
- Добавьте в проект файл кода Python (
.py), содержащий пример кода или собственный код. Если вы используете собственный код, необходимо создать экземпляр экземпляраSparkSession.builder.getOrCreate(), как показано в примере кода. - При открытии файла кода Python задайте все точки останова, в которых код будет приостановлен во время выполнения.
- Нажмите кнопку >" или "Выполнить > отладку".
Дополнительные инструкции по выполнению и отладке см. в разделе "Запуск программы".
Затмение
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Чтобы использовать Databricks Connect и Eclipse, сделайте следующее:
Запустите
databricks-connect get-jar-dir.Направьте конфигурацию внешних JAR на каталог, возвращенный из команды. Перейдите по пути Меню проекта > Свойства > Путь сборки Java > Библиотеки > Добавить внешние JAR.
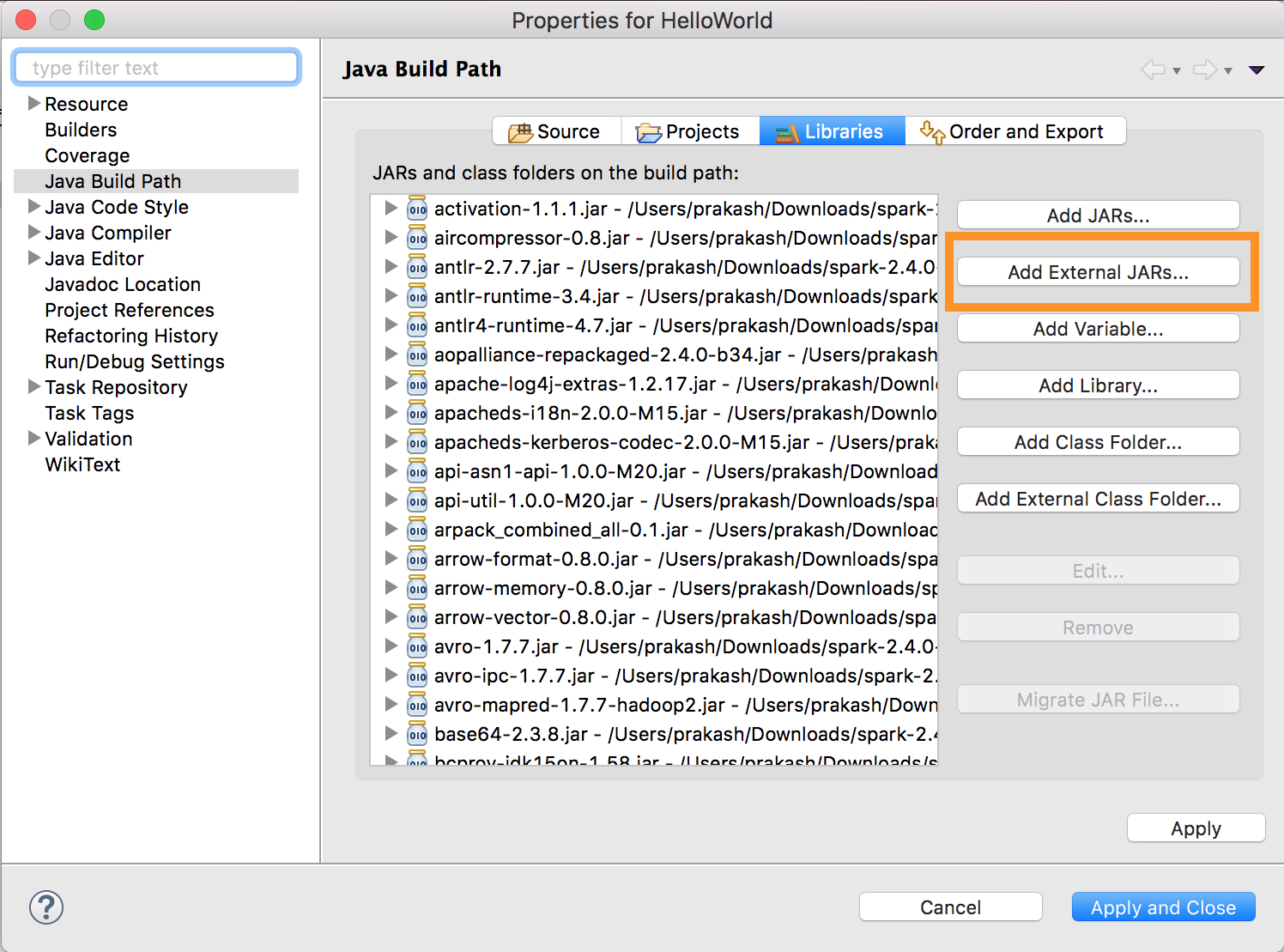
Во избежание конфликтов настоятельно рекомендуется удалить все остальные установки Spark из подкаталогов классов. Если это невозможно, убедитесь, что добавляемый JAR находится в начале подкаталогов классов. В частности, они должны опережать любую другую установленную версию Spark (в противном случае вы будете использовать одну из этих версий Spark и запускать ее локально или создавать
ClassDefNotFoundError).
SBT
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Чтобы использовать Databricks Connect с SBT, необходимо настроить build.sbt файл для связывания с JAR Databricks Connect вместо обычной зависимости библиотеки Spark. Это можно сделать с помощью директивы unmanagedBase в следующем примере файла сборки, который предполагает, что приложение Scala имеет основной объект com.example.Test:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Оболочка Spark
Примечание.
Прежде чем приступать к работе с Databricks Connect, необходимо выполнить требования и настроить клиент для Databricks Connect.
Чтобы использовать Databricks Connect с оболочкой Spark и Python или Scala, следуйте этим инструкциям.
При активации виртуальной среды убедитесь, что
databricks-connect testкоманда успешно запущена в настройке клиента.После активации виртуальной среды запустите оболочку Spark. Для Python выполните
pysparkкоманду. Для Scala выполнитеspark-shellкоманду.# For Python: pyspark# For Scala: spark-shellПоявится оболочка Spark, например для Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>Для Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>-
Используйте встроенную
sparkпеременную для представленияSparkSessionв работающем кластере, например для Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsДля Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rows Чтобы остановить оболочку Spark, нажмите
Ctrl + dилиCtrl + zзапустите командуquit()илиexit()для Python или:q:quitScala.
Примеры кода
Этот простой пример кода запрашивает указанную таблицу, а затем отображает первые 5 строк указанной таблицы. Чтобы использовать другую таблицу, настройте вызов spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
В этом более длинном примере кода выполняется следующее:
- Создает кадр данных в памяти.
- Создает таблицу с именем
zzz_demo_temps_tableв схемеdefault. Если таблица с этим именем уже существует, сначала удаляется таблица. Чтобы использовать другую схему или таблицу, настройте вызовыspark.sqlилиtemps.write.saveAsTableоба. - Сохраняет содержимое DataFrame в таблицу.
-
SELECTВыполняет запрос к содержимому таблицы. - Отображает результат запроса.
- Удаляет таблицу.
Питон
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
язык программирования Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Ява
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Работа с зависимостями
Как правило, основной класс или файл Python будут иметь другие JAR и файлы зависимости. Можно добавлять такие JAR и файлы зависимости, вызвав sparkContext.addJar("path-to-the-jar") или sparkContext.addPyFile("path-to-the-file"). В интерфейс addPyFile() также можно добавлять файлы Egg и ZIP-файлы. Каждый раз при выполнении кода в интегрированной среде разработки, в кластере устанавливаются JAR и файлы зависимостей.
Питон
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Определяемые пользователем функции Python и Java
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
язык программирования Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Доступ к служебным программам Databricks
В этом разделе описывается, как использовать Databricks Connect для доступа к служебным программам Databricks.
Вы можете использовать dbutils.fs и dbutils.secrets служебные программы эталонного модуля Databricks Utilities (dbutils).
Поддерживаются такие команды: dbutils.fs.cp, dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirs, dbutils.fs.mv, dbutils.fs.put, dbutils.fs.rm, dbutils.secrets.get, dbutils.secrets.getBytes, dbutils.secrets.list, dbutils.secrets.listScopes.
См. раздел Программа файловой системы (dbutils.fs) или запустите dbutils.fs.help() и Программа секретов (dbutils.secrets) или запустите dbutils.secrets.help().
Питон
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
При использовании Databricks Runtime 7.3 LTS или более поздней версии для доступа к модулю DBUtils таким образом, который работает как локально, так и в кластерах Azure Databricks, используйте следующее get_dbutils():
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
Или используйте следующее get_dbutils():
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
язык программирования Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Копирование файлов между локальной и удаленной файловой системой
Можно использовать dbutils.fs для копирования файлов между клиентом и удаленной файловой системой. Схема file:/ ссылается на локальную файловую систему на клиенте.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
Максимальный размер файла, который можно передать таким образом, составляет 250 МБ.
Включите dbutils.secrets.get
Из-за ограничений безопасности возможность вызова dbutils.secrets.get по умолчанию отключена. Обратитесь в службу поддержки Azure Databricks, чтобы включить эту функцию для рабочей области.
Настройка конфигураций Hadoop
На клиенте можно задать конфигурации Hadoop с помощью API spark.conf.set, который применяется к SQL и операциям с кадрами данных. Конфигурации Hadoop, заданные для sparkContext, должны быть установлены в конфигурации кластера или с помощью записной книжки. Это обусловлено тем, что конфигурации, заданные для sparkContext, не привязаны к пользовательским сеансам, но применяются ко всему кластеру.
Устранение неполадок
Выполните команду databricks-connect test, чтобы проверить наличие проблем с подключением. В этом разделе описываются некоторые распространенные проблемы, с которыми вы можете столкнуться с Databricks Connect и как их устранить.
В этом разделе рассматриваются следующие вопросы.
- Несоответствие версии Python
- Сервер не включен
- Конфликтующие установки PySpark
-
Противоречивый
SPARK_HOME -
Конфликтующая или недостающая
PATHзапись для двоичных файлов - Конфликтующие параметры сериализации в кластере
-
Не удается найти
winutils.exeв Windows - Неправильный синтаксис имени файла, имени каталога или метки тома в Windows
Несоответствие версии Python
Убедитесь, что в версии Python, используемой локально, имеется по крайней мере тот же дополнительный выпуск, что и в кластере (например, 3.9.16 с 3.9.15 приемлемо, а 3.9 с 3.8 — нет).
При наличии нескольких версий Python, установленных локально, убедитесь, что Databricks Connect использует правильную версию, задав переменную среды PYSPARK_PYTHON (например, PYSPARK_PYTHON=python3).
Сервер не включен
Убедитесь, что в кластере включен сервер Spark с spark.databricks.service.server.enabled true. Если это так, в журнале драйвера должны отобразиться следующие строки:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
Конфликтующие установки PySpark
Пакет databricks-connect конфликтует с PySpark. Наличие обеих установленных экземпляров приведет к ошибкам при инициализации контекста Spark в Python. Это может проявиться несколькими способами, включая ошибки "поток поврежден" или "класс не найден". Если в среде Python установлен PySpark, перед установкой databricks-connect убедитесь, что он удален. После удаления PySpark необходимо полностью переустановить пакет Databricks Connect.
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
Конфликт с SPARK_HOME.
Если ранее на устройстве вы использовали Spark, в интегрированной среде разработки можно настроить использование одной из других версий Spark, а не Databricks Connect Spark. Это может проявиться несколькими способами, включая ошибки "поток поврежден" или "класс не найден". Чтобы узнать, какая версия Spark используется, проверьте значение переменной среды SPARK_HOME:
Питон
import os
print(os.environ['SPARK_HOME'])
язык программирования Scala
println(sys.env.get("SPARK_HOME"))
Ява
System.out.println(System.getenv("SPARK_HOME"));
Разрешение
Если для версии Spark задано SPARK_HOME, отличное от той, что указано в клиенте, следует удалить переменную SPARK_HOME и повторить попытку.
Проверьте параметры переменных интегрированной среды разработки, файл .bashrc, .zshrc или .bash_profile, а также другие установленные параметры переменные среды. Вам, скорее всего, придется выйти и перезапустить интегрированную среду разработки, чтобы очистить старое состояние, а при повторении ошибки может потребоваться создать новый проект.
Вам не нужно задавать для SPARK_HOME новое значение. Удаление будет достаточным.
Конфликтующие или отсутствующие записи PATH для двоичных файлов
Возможно, ваш путь настроен таким образом, чтобы команды, такие как spark-shell, запускали другой ранее установленный двоичный файл вместо того, который был предоставлен с Databricks Connect. Это может привести к сбою databricks-connect test. Необходимо убедиться в том, что двоичные файлы Databricks Connect имеют приоритет, либо удалить ранее установленные.
Если вы не можете выполнять команды, такие как spark-shell, возможно, что ваш PATH не был автоматически настроен с помощью pip3 install, и вам потребуется вручную добавить каталог установки bin в PATH. Можно использовать Databricks Connect со средами разработки, даже если настройка не выполнена. Однако команда databricks-connect test не будет работать.
Конфликтующие параметры сериализации в кластере
Если при запуске databricks-connect test отображается ошибка "поток поврежден", это может быть вызвано несовместимыми конфигурациями сериализации кластера. Например, установка конфигурации spark.io.compression.codec может привести к возникновению этой проблемы. Чтобы устранить эту проблему, рассмотрите возможность удаления этих конфигураций из параметров кластера или настройки конфигурации в клиенте Databricks Connect.
Не удается найти winutils.exe в Windows
Если вы используете Databricks Connect в Windows и видите:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Следуйте инструкциям по настройке пути Hadoop в Windows.
Неверный синтаксис имени файла, папки или метки тома в Windows
Если вы используете Windows и Databricks Connect и видите следующее:
The filename, directory name, or volume label syntax is incorrect.
Java или Databricks Connect были установлены в каталог с пробелом в пути. Это можно обойти, установив путь к каталогу без пробелов или настроив путь с помощью формы короткого имени.
Проверка подлинности с помощью маркеров идентификатора Microsoft Entra
Примечание.
Следующие сведения относятся только к Databricks Connect версии 7.3.5–12.2.x.
Databricks Connect для Databricks Runtime 13.3 LTS и выше в настоящее время не поддерживает маркеры идентификатора Microsoft Entra.
При использовании Databricks Connect версии 7.3.5–12.2.x можно пройти проверку подлинности с помощью маркера идентификатора Microsoft Entra, а не личного маркера доступа. Маркеры идентификатора Microsoft Entra имеют ограниченное время существования. Когда срок действия маркера идентификатора Microsoft Entra истекает, Databricks Connect завершается ошибкой Invalid Token .
Для Databricks Connect версии 7.3.5–12.2.x можно указать маркер идентификатора Microsoft Entra в работающем приложении Databricks Connect. Приложению необходимо получить новый маркер доступа и присвоить ему ключ конфигурации SQL spark.databricks.service.token.
Питон
spark.conf.set("spark.databricks.service.token", new_aad_token)
язык программирования Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
После обновления маркера приложение может продолжать использовать те же SparkSession и все объекты и состояние, созданные в контексте сеанса. Чтобы избежать периодических ошибок, Databricks рекомендует предоставить новый маркер до истечения срока действия старого.
Вы можете продлить время существования маркера идентификатора Microsoft Entra, чтобы сохраниться во время выполнения приложения. Для этого подключите tokenLifetimePolicy с соответствующим временем существования к приложению авторизации идентификатора Microsoft Entra, которое использовалось для получения маркера доступа.
Примечание.
Сквозное руководство по идентификатору Microsoft Entra использует два маркера: маркер доступа к идентификатору Microsoft Entra, который ранее был описан в Databricks Connect версий 7.3.5–12.2.x, а маркер доступа ADLS для определенного ресурса, который Databricks генерирует, а Databricks обрабатывает запрос. Нельзя продлить время существования маркеров сквозного руководства ADLS с помощью политик времени существования маркера идентификатора Microsoft Entra. При отправке кластеру команды, которая занимает больше часа, произойдет сбой, если команда обращается к ресурсу ADLS после пометки в один час.
Ограничения
- Каталог Unity.
- Структурированная потоковая передача
- Выполнение произвольного кода, который не является частью задания Spark, в удаленном кластере.
- Собственные интерфейсы API Scala, Python и R для операций с разностными таблицами (например,
DeltaTable.forPath) не поддерживаются. Однако поддерживаются API SQL (spark.sql(...)) с операциями Delta Lake и API Spark (например,spark.read.load) в разностных таблицах. - Копирование в.
- Использование функций SQL, а также определяемых пользователем функций (UDF) Python или Scala, которые являются частью каталога сервера. Однако локально появились функции Scala и UDFS Python.
- Apache Zeppelin 0.7.x и более ранние версии.
- Подключение к кластерам с контролем доступа к таблицам.
- Подключение к кластерам с включенной изоляцией процессов (иными словами, где
spark.databricks.pyspark.enableProcessIsolationимеет значениеtrue). - Команда SQL Delta
CLONE. - Глобальные временные представления.
-
Коала и
pyspark.pandas. -
CREATE TABLE table AS SELECT ...Команды SQL не всегда работают. Используйтеspark.sql("SELECT ...").write.saveAsTable("table").
- Сквозное руководство по учетным данным идентификатора Microsoft Entra поддерживается только в стандартных кластерах под управлением Databricks Runtime 7.3 LTS и более поздних версий и несовместимо с проверкой подлинности субъекта-службы.
- Справочник по следующим служебным программам Databricks (
dbutils):