Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Примечание.
В этой статье рассматривается Databricks Connect для Databricks Runtime версии 13.3 LTS и более новых версий.
Databricks Connect — это клиентская библиотека для среды выполнения Databricks, которая позволяет подключаться к вычислительным ресурсам Azure Databricks из IDE, таких как Visual Studio Code, PyCharm и IntelliJ IDEA, а также из ноутбуков и любых пользовательских приложений, обеспечивая новые интерактивные пользовательские возможности, основанные на Azure Databricks Lakehouse.
Databricks Connect доступен для следующих языков:
Что я могу сделать с помощью Databricks Connect?
С помощью Databricks Connect можно написать код с помощью API Spark и удаленно запускать их на Azure Databricks вычислений, а не в локальном сеансе Spark.
Интерактивная разработка и отладка из любой интегрированной среды разработки. Databricks Connect позволяет разработчикам разрабатывать и отлаживать свой код на вычислительных ресурсах Databricks с помощью собственных функций запуска и отладки интегрированной среды разработки. Расширение Visual Studio Code Databricks использует Databricks Connect для обеспечения встроенной отладки пользовательского кода в Databricks.
Создание интерактивных приложений данных. Как и драйвер JDBC, библиотека Databricks Connect может быть внедрена в любое приложение для взаимодействия с Databricks. Databricks Connect обеспечивает полную экспрессивность Python через PySpark, устраняя несоответствие языка программирования SQL и позволяя выполнять все преобразования данных с помощью Spark на платформе Databricks с её бессерверными и масштабируемыми вычислительными ресурсами.
Как это работает?
Databricks Connect построен на базе Spark Connect с открытым исходным кодом, которая имеет отложенную архитектуру клиентского сервера для Apache Spark, которая обеспечивает удаленное подключение к кластерам Spark с помощью API кадра данных. Базовый протокол использует неразрешенные логические планы Spark и Apache Arrow на основе gRPC. Клиентский API спроектирован быть тонким, чтобы его можно было внедрять везде: на серверах приложений, в средах разработки (IDE), записных книжках и языках программирования.
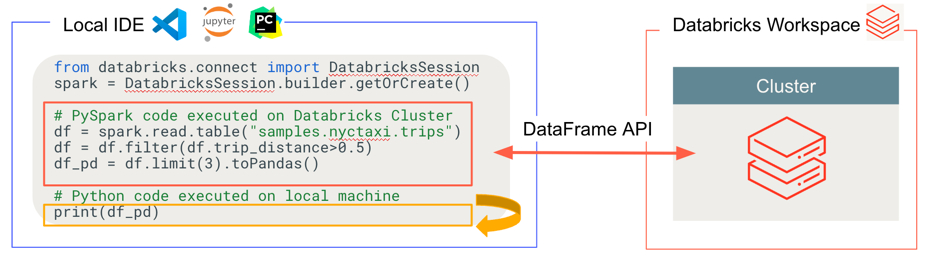
- General code выполняется локально: Python и код Scala выполняется на стороне клиента, что позволяет выполнять интерактивную отладку. Весь код выполняется локально, а весь код Spark продолжает работать в удаленном кластере.
-
API DataFrame выполняются на платформе Databricks. Все преобразования данных преобразуются в планы Spark и выполняются на вычислительных ресурсах Databricks через удаленный сеанс Spark. Они материализуются на локальном клиенте при использовании таких команд, как
collect(),show().toPandas() -
Код UDF выполняется на вычислительных ресурсах Databricks: локально определяемые функции сериализуются и передаются в кластер, где они выполняются. API, выполняющие пользовательский код в Databricks, включают: определяемые пользователем функции,
foreach,foreachBatch, а такжеtransformWithState. - Для управления зависимостями:
- Установите зависимости приложений на локальном компьютере. Они выполняются локально и должны быть установлены как часть проекта, например часть виртуальной среды Python.
- Установите зависимости UDF в Databricks. См. статью "Управление зависимостями UDF".
Как связаны Databricks Connect и Spark Connect?
Spark Connect — это протокол на основе gRPC с открытым кодом в Apache Spark, который позволяет удаленно выполнять рабочие нагрузки Spark с помощью API кадра данных.
Для Databricks Runtime 13.3 LTS и более поздних версий Databricks Connect является расширением Spark Connect с дополнениями и изменениями для поддержки работы с режимами вычислений Databricks и каталогом Unity.
Дополнительные ресурсы
Ознакомьтесь со следующими руководствами, чтобы быстро приступить к разработке решений Databricks Connect:
- Руководство по классической вычислительной системе для Python с использованием Databricks Connect
- Учебник по Databricks Connect для бессерверных вычислений с Python
- Учебник по использованию классических вычислений Databricks Connect для Scala
- Руководство по бессерверным вычислениям Databricks Connect для Scala
- Руководство по Databricks Connect для R
Чтобы увидеть примеры приложений, использующих Databricks Connect, посмотрите в репозитории примеров GitHub, который включает следующие примеры: