Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Azure Databricks имеет несколько служебных программ и API для взаимодействия с файлами в следующих расположениях:
- Тома каталога Unity
- Файлы рабочей области
- Облачное хранилище объектов
- Подключения DBFS и корневой каталог DBFS
- Эфемерное хранилище, подключенное к узлу драйвера кластера
В этой статье приведены примеры взаимодействия с файлами в этих расположениях для следующих средств:
- Apache Spark
- Spark SQL и Databricks SQL
- Служебные программы файловой системы Databricks (
dbutils.fsили%fs) - Интерфейс командной строки Databricks
- Databricks REST API
- Команды оболочки Bash (
%sh) - Установка библиотеки с областью действия записной книжки с помощью
%pip - Панды
- Программы управления файлами и обработки OSS Python
Важный
Некоторые операции в Databricks, особенно с помощью библиотек Java или Scala, выполняются как процессы JVM, например:
- Указание зависимости от JAR-файла с использованием
--jarsв конфигурациях Spark - Вызов
catилиjava.io.Fileв ноутбуках Scala - Пользовательские источники данных, такие как
spark.read.format("com.mycompany.datasource") - Библиотеки, загружающие файлы с помощью Java
FileInputStreamилиPaths.get()
Эти операции не поддерживают чтение или запись в тома каталога Unity или файлы рабочей области с использованием стандартных путей к файлам, например /Volumes/my-catalog/my-schema/my-volume/my-file.csv. Если вам нужно получить доступ к файлам томов или файлам рабочей области из JAR-зависимостей или библиотек на основе JVM, скопируйте файлы сначала на локальное хранилище с помощью команд Python или %sh, таких как %sh mv.. Не используйте %fs и dbutils.fs, которые используют JVM. Чтобы получить доступ к файлам, уже скопированным локально, используйте команды, такие как Python shutil или %sh. Если файл должен присутствовать во время запуска кластера, используйте скрипт инициализации для первого перемещения файла. См. Что такое скрипты инициализации?.
Нужно ли предоставить схему URI для доступа к данным?
Пути доступа к данным в Azure Databricks соответствуют одному из следующих стандартов:
пути в стиле URI включают схему URI. Для решений доступа к данным на основе Databricks схемы URI являются необязательными для большинства вариантов использования. При непосредственном доступе к данным в облачном хранилище объектов необходимо предоставить правильную схему URI для типа хранилища.
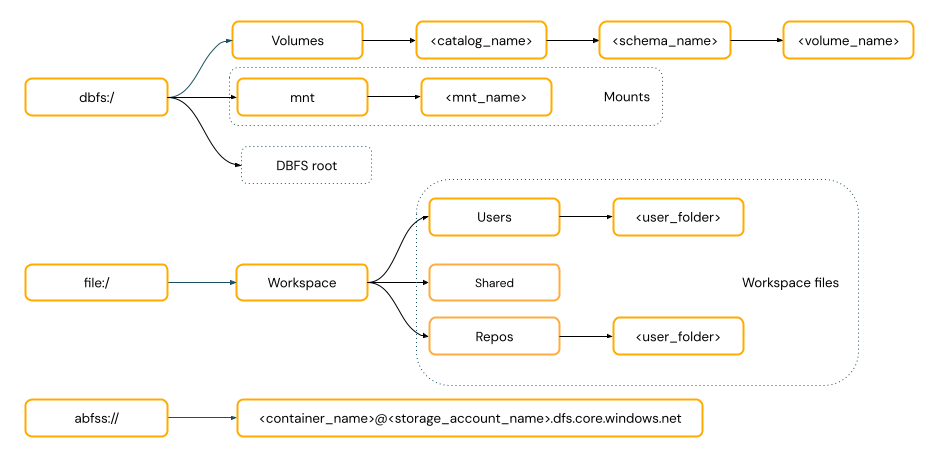
Пути, соответствующие POSIX-стандарту, предоставляют доступ к данным относительно корневого каталога драйвера (
/). Пути в стиле POSIX никогда не требуют схемы. Вы можете использовать тома каталога Unity или подключения DBFS для предоставления доступа к данным в облачном хранилище объектов в стиле POSIX. Многие платформы машинного обучения и другие модули Python OSS требуют FUSE и могут использовать только пути в стиле POSIX.схема путей POSIX
Заметка
Операции с файлами, требующие доступа к данным FUSE, не могут напрямую получить доступ к облачному хранилищу объектов с помощью URI. Databricks рекомендует использовать тома Unity Catalog для конфигурирования доступа к этим расположениям для FUSE.
При вычислении, настроенном с выделенным режимом доступа (ранее однопользовательским режимом доступа) и Databricks Runtime 14.3 и выше, Scala поддерживает FUSE для томов каталога Unity и файлов рабочей области, за исключением подпроцессов, запускаемых из Scala, таких как команда Scala "cat /Volumes/path/to/file".!!.
Работа с файлами в томах каталога Unity
Databricks рекомендует использовать тома каталога Unity для настройки доступа к файлам не табличных данных, хранящимся в облачном хранилище объектов. Полная документация по управлению файлами в томах, включая подробные инструкции и рекомендации, см. в статье "Работа с файлами в томах каталога Unity".
В следующих примерах показаны распространенные операции с помощью различных инструментов и интерфейсов:
| Инструмент | Пример |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL и Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`;LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Служебные программы файловой системы Databricks | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/")%fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Интерфейс командной строки Databricks | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create{"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Команды оболочки Bash | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Установка библиотеки | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Панды | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| ПО с открытым исходным кодом Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Сведения об ограничениях томов и обходных решениях см. в разделе "Ограничения работы с файлами в томах".
Работа с файлами рабочей области
Файлы рабочей области Databricks — это файлы в рабочей области, хранящиеся в учетной записи хранения рабочей области . Файлы рабочей области можно использовать для хранения и доступа к файлам, таким как записные книжки, файлы исходного кода, файлы данных и другие ресурсы рабочей области.
Важный
Так как файлы рабочей области имеют ограничения на размер, Databricks рекомендует хранить только небольшие файлы данных здесь в первую очередь для разработки и тестирования. Рекомендации по хранению других типов файлов см. в разделе "Типы файлов".
| Инструмент | Пример |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL и Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Служебные программы файловой системы Databricks | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/")%fs ls file:/Workspace/Users/<user-folder>/ |
| Интерфейс командной строки Databricks | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete{"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Команды оболочки Bash | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| Установка библиотеки | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Панды | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| ПО с открытым исходным кодом Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Заметка
Схема file:/ требуется при работе с служебными программами Databricks, Apache Spark или SQL.
В рабочих областях, где корневой каталог и подключения DBFS отключены, можно также использовать dbfs:/Workspace для доступа к файлам рабочих областей с помощью служебных программ Databricks. Для этого требуется Databricks Runtime 13.3 LTS или более поздней версии. См. Отключить доступ к корневому каталогу DBFS и точкам монтирования в существующей рабочей области Azure Databricks.
Ограничения при работе с файлами рабочей области см. в Ограничениях.
Куда идут удаленные файлы рабочей области?
Удаление файла в рабочей области отправляет его в корзину. Вы можете восстановить или окончательно удалить файлы из корзины с помощью пользовательского интерфейса.
См. Удалить объект.
Работа с файлами в облачном хранилище объектов
Databricks рекомендует использовать тома каталога Unity для настройки безопасного доступа к файлам в облачном хранилище объектов. Необходимо настроить разрешения, если вы решили получить доступ к данным непосредственно в облачном хранилище объектов с помощью URI. См. раздел "Управляемые и внешние тома".
В следующих примерах используются URI для доступа к данным в облачном хранилище объектов:
| Инструмент | Пример |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL и Databricks SQL |
SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`;
LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path';
|
| Служебные программы файловой системы Databricks |
dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/")
%fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/
|
| Интерфейс командной строки Databricks | Не поддерживается |
| Databricks REST API | Не поддерживается |
| Команды оболочки Bash | Не поддерживается |
| Установка библиотеки | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Панды | Не поддерживается |
| ПО с открытым исходным кодом Python | Не поддерживается |
Работа с файлами в маунтах DBFS и корневом каталоге DBFS
Важный
И корень DBFS, и монтирования DBFS устарели и их использование не рекомендуется компанией Databricks. Новые учетные записи подготавливаются без доступа к этим функциям. Databricks рекомендует использовать тома каталога Unity, внешние расположения или файлы рабочей области .
| Инструмент | Пример |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL и Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Служебные программы файловой системы Databricks | dbutils.fs.ls("/mnt/path")%fs ls /mnt/path |
| Интерфейс командной строки Databricks | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Команды оболочки Bash | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| Установка библиотеки | %pip install /dbfs/mnt/path/to/my_library.whl |
| Панды | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| ПО с открытым исходным кодом Python | os.listdir('/dbfs/mnt/path/to/directory') |
Заметка
При работе с интерфейсом командной строки Databricks требуется схема dbfs:/.
Работа с файлами в эфемерном хранилище, подключенном к узлу драйвера
Эфемерное хранилище, подключенное к узлу драйвера, — это блочное хранилище с встроенным доступом к файловым путям на основе POSIX. Все данные, хранящиеся в этом расположении, исчезают при завершении или перезапуске кластера.
| Инструмент | Пример |
|---|---|
| Apache Spark | Не поддерживается |
| Spark SQL и Databricks SQL | Не поддерживается |
| Служебные программы файловой системы Databricks | dbutils.fs.ls("file:/path")%fs ls file:/path |
| Интерфейс командной строки Databricks | Не поддерживается |
| Databricks REST API | Не поддерживается |
| Команды оболочки Bash | %sh curl http://<address>/text.zip > /tmp/text.zip |
| Установка библиотеки | Не поддерживается |
| Панды | df = pd.read_csv('/path/to/data.csv') |
| ПО с открытым исходным кодом Python | os.listdir('/path/to/directory') |
Заметка
Схема file:/ требуется при работе с служебными программами Databricks.
Перемещение данных из эфемерного хранилища в тома
Возможно, вам потребуется получить доступ к данным, скачанным или сохраненным в эфемерное хранилище с помощью Apache Spark. Так как эфемерное хранилище подключено к драйверу, а Spark — это распределённая система обработки данных, не все операции могут напрямую обращаться к данным здесь. Предположим, что необходимо переместить данные из файловой системы драйвера в тома каталога Unity. В этом случае можно скопировать файлы с помощью магических команд или служебных программ Databricks, как показано в следующих примерах:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>