Оркестрация заданий Azure Databricks с помощью Apache Airflow
В этой статье описывается поддержка Apache Airflow для оркестрации конвейеров данных с помощью Azure Databricks, содержит инструкции по установке и настройке Airflow локально, а также пример развертывания и запуска рабочего процесса Azure Databricks с помощью Airflow.
Оркестрация заданий в конвейере данных
Для разработки и развертывания конвейера обработки данных часто требуется управлять сложными зависимостями между задачами. Например, конвейер может считывать данные из источника, очищать данные, преобразовывать чистые данные и записывать преобразованные данные в целевой объект. При выполнении конвейера также требуется поддержка тестирования, планирования и устранения ошибок.
Системы рабочих процессов позволяют задавать зависимости между задачами, планировать выполнение конвейеров и отслеживать рабочие процессы. Apache Airflow — это решение с открытым кодом для управления конвейерами данных и их планирования. Airflow представляет конвейеры данных в виде направленных ациклический графов (DAG) операций. Рабочий процесс определяется в файле Python, а Airflow управляет планированием и выполнением. Подключение Airflow Azure Databricks позволяет воспользоваться преимуществами оптимизированного двигателя Spark, предлагаемого Azure Databricks с функциями планирования Airflow.
Требования
- Интеграция Airflow с Azure Databricks требует Airflow версии 2.5.0 и более поздних версий. Примеры в этой статье тестируются с помощью Airflow версии 2.6.1.
- Airflow требует Python 3.8, 3.9, 3.10 или 3.11. Примеры в этой статье протестированы на версии Python 3.8.
- Инструкции в этой статье по установке и запуску Airflow требуют конвейера для создания виртуальной среды Python.
Операторы воздушных потоков для Databricks
DaG Airflow состоит из задач, где каждая задача выполняет оператор Airflow. Операторы airflow, поддерживающие интеграцию с Databricks, реализуются в поставщике Databricks.
Поставщик Databricks включает операторов для выполнения ряда задач в рабочей области Azure Databricks, включая импорт данных в таблицу, выполнение запросов SQL и работу с папками Databricks Git.
Поставщик Databricks реализует два оператора для запуска заданий:
- DatabricksRunNowOperator требует существующего задания Azure Databricks и использует запрос API POST /api/2.1/jobs/run-now для активации выполнения. Databricks рекомендует использовать
DatabricksRunNowOperatorтак как уменьшает дублирование определений заданий, а запуски заданий, запущенные с помощью этого оператора, можно найти в пользовательском интерфейсе заданий. - DatabricksSubmitRunOperator не требует наличия задания в Azure Databricks и использует запрос POST /api/2.1/jobs/run/submit API для отправки спецификации задания и запуска выполнения.
Чтобы создать новое задание Azure Databricks или сбросить существующее задание, поставщик Databricks реализует DatabricksCreateJobsOperator. Использует DatabricksCreateJobsOperator запросы API POST /api/2.1/jobs/create и POST/API/2.1/jobs/reset . Вы можете использовать DatabricksCreateJobsOperator его для DatabricksRunNowOperator создания и запуска задания.
Примечание.
Использование операторов Databricks для активации задания требует предоставления учетных данных в конфигурации подключения Databricks. См. статью "Создание личного маркера доступа Azure Databricks" для Airflow.
Операторы Airflow Databricks записывают URL-адрес страницы выполнения задания в журналы Airflow каждые polling_period_seconds (по умолчанию — 30 секунд). Дополнительные сведения см. на странице пакета apache-airflow-providers-databricks на веб-сайте Airflow.
Локальная установка интеграции Airflow Azure Databricks
Чтобы установить Airflow и поставщик Databricks локально для тестирования и разработки, выполните следующие действия. Другие варианты установки Airflow, включая создание рабочей установки, см. в документации по Airflow.
Откройте терминал и выполните следующие команды:
mkdir airflow
cd airflow
pipenv --python 3.8
pipenv shell
export AIRFLOW_HOME=$(pwd)
pipenv install apache-airflow
pipenv install apache-airflow-providers-databricks
mkdir dags
airflow db init
airflow users create --username admin --firstname <firstname> --lastname <lastname> --role Admin --email <email>
Замените <firstname>имя <lastname><email> пользователя и электронную почту. Вам будет предложено ввести пароль для пользователя администратора. Сохраните этот пароль, так как он требуется для входа в пользовательский интерфейс Airflow.
Сценарий выполнит указанные ниже действия.
- Создает каталог с именем
airflowи изменяет этот каталог. - Используется
pipenvдля создания и создания виртуальной среды Python. Для изоляции версий пакетов и зависимостей кода в этой среде Databricks рекомендует использовать виртуальную среду Python. Такая изоляция помогает сократить количество несовпадений между версиями пакетов и число конфликтов в зависимостях кода. - Инициализирует переменную среды с именем
AIRFLOW_HOME, заданную в путь к каталогуairflow. - Устанавливает airflow и пакеты поставщика Airflow Databricks.
airflow/dagsСоздает каталог. Airflow использует каталогdagsдля хранения определений DAG.- Инициализирует базу данных SQLite, которую Airflow использует для отслеживания метаданных. В рабочем развертывании Airflow для настройки используется стандартная база данных. База данных SQLite и конфигурация по умолчанию для развертывания Airflow инициализируются в каталоге
airflow. - Создает пользователя администратора для Airflow.
Совет
Чтобы подтвердить установку поставщика Databricks, выполните следующую команду в каталоге установки Airflow:
airflow providers list
Запуск веб-сервера и планировщика Airflow
Веб-сервер Airflow необходим для просмотра пользовательского интерфейса Airflow. Чтобы запустить веб-сервер, откройте терминал в каталоге установки Airflow и выполните следующие команды:
Примечание.
Если веб-сервер Airflow не запускается из-за конфликта портов, можно изменить порт по умолчанию в конфигурации Airflow.
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow webserver
Планировщик — это компонент Airflow, который отвечает за планирование DAG. Чтобы запустить планировщик, откройте новый терминал в каталоге установки Airflow и выполните следующие команды:
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow scheduler
Тестирование установленной версии Airflow
Чтобы проверить работоспособность установленной версии Airflow, запустите один из примеров DAG, входящих в состав Airflow:
- В окне браузера откройте
http://localhost:8080/home. Войдите в пользовательский интерфейс Airflow с именем пользователя и паролем, созданным при установке Airflow. Откроется страница DAG Airflow. - С помощью переключателя Приостановить/Возобновить DAG возобновите выполнение одного из примеров DAG, например
example_python_operator. - Активируйте пример DAG, нажав кнопку "Триггер DAG ".
- Щелкните имя DAG, чтобы просмотреть сведения, включая состояние выполнения DAG.
Создание личного маркера доступа Azure Databricks для Airflow
Airflow подключается к Databricks с помощью личного маркера доступа Azure Databricks. Чтобы создать PAT, выполните приведенные действия.
- В рабочей области Azure Databricks щелкните имя пользователя Azure Databricks в верхней строке и выберите "Параметры " в раскрывающемся списке.
- Щелкните "Разработчик".
- Рядом с маркерами доступа нажмите кнопку "Управление".
- Щелкните Generate new token (Создание нового маркера).
- (Необязательно) Введите комментарий, который поможет определить этот маркер в будущем и изменить время существования маркера по умолчанию в течение 90 дней. Чтобы создать маркер без времени существования (не рекомендуется), оставьте поле время существования (дни) пустым (пустым).
- Щелкните Создать.
- Скопируйте отображаемый маркер в безопасное расположение и нажмите кнопку "Готово".
Примечание.
Не забудьте сохранить скопированный маркер в безопасном расположении. Не делитесь скопированным маркером с другими пользователями. Если вы потеряете скопированный маркер, вы не сможете повторно создать тот же маркер. Вместо этого необходимо повторить эту процедуру, чтобы создать новый маркер. Если вы потеряете скопированный маркер или считаете, что маркер скомпрометирован, Databricks настоятельно рекомендует немедленно удалить этот маркер из рабочей области, щелкнув значок корзины (отозвать) рядом с маркером на странице маркеров доступа.
Если вы не можете создавать или использовать маркеры в рабочей области, это может быть связано с тем, что администратор рабочей области отключил маркеры или не предоставил вам разрешение на создание или использование маркеров. Ознакомьтесь с администратором рабочей области или следующими разделами:
Примечание.
В качестве рекомендации по обеспечению безопасности при проверке подлинности с помощью автоматизированных средств, систем, сценариев и приложений Databricks рекомендуется использовать личные маркеры доступа, принадлежащие субъектам-службам, а не пользователям рабочей области. Сведения о создании маркеров для субъектов-служб см. в разделе "Управление маркерами" для субъекта-службы.
Вы также можете пройти проверку подлинности в Azure Databricks с помощью маркера идентификатора Microsoft Entra. См . сведения о подключении Databricks в документации по Airflow.
Настройка подключения к Azure Databricks
Установленный экземпляр Airflow содержит подключение по умолчанию для Azure Databricks. Чтобы настроить подключение для подключения к рабочей области с помощью созданного ранее личного маркера доступа, выполните указанные ниже действия.
- В окне браузера откройте
http://localhost:8080/connection/list/. Если появится запрос на вход, введите имя пользователя и пароль администратора. - В разделе Идентификатор подключения выберите databricks_default и нажмите кнопку Изменить запись.
- Замените значение в поле "Узел" именем экземпляра рабочей области развертывания Azure Databricks, например
https://adb-123456789.cloud.databricks.com. - В поле "Пароль" введите личный маркер доступа Azure Databricks.
- Нажмите кнопку Сохранить.
Если вы используете маркер идентификатора Microsoft Entra, см . сведения о настройке проверки подлинности в документации по Databricks Connection в документации по Airflow.
Пример. Создание DAG Airflow для запуска задания Azure Databricks
В следующем примере объясняется, как создать простое развертывание Airflow, которое выполняется на локальном компьютере, и развернуть пример DAG для запуска на выполнение в Azure Databricks. В этом примере вы будете:
- Создайте новую записную книжку и добавьте код для вывода приветствия на основе настроенного параметра.
- Создайте задание Azure Databricks с одной задачей, которая запускает записную книжку.
- Настройте подключение Airflow к рабочей области Azure Databricks.
- Создайте DAG в Airflow, чтобы активировать задание записной книжки. DAG определяется в скрипте Python с помощью
DatabricksRunNowOperator. - С помощью пользовательского интерфейса Airflow активируйте DAG и отслеживайте статус выполнения.
Создание записной книжки
В этом примере используется записная книжка, содержащая две ячейки:
- Первая ячейка содержит текстовое мини-приложение служебных программ Databricks, определяющее переменную
greeting, для которой задано значение по умолчаниюworld. - Вторая ячейка выводит значение переменной
greetingс префиксомhello.
Чтобы создать записную книжку, выполните указанные ниже действия.
Перейдите в рабочую область Azure Databricks, щелкните
 "Создать" на боковой панели и выберите "Записная книжка".
"Создать" на боковой панели и выберите "Записная книжка".Присвойте записной книжке имя, например Hello Airflow, и убедитесь, что язык по умолчанию имеет значение Python.
Скопируйте приведенный ниже код Python и вставьте его в первую ячейку записной книжки.
dbutils.widgets.text("greeting", "world", "Greeting") greeting = dbutils.widgets.get("greeting")Добавьте новую ячейку под первой ячейкой и скопируйте и вставьте в нее следующий код Python:
print("hello {}".format(greeting))
Создание задания
Щелкните
 рабочие процессы на боковой панели.
рабочие процессы на боковой панели.Нажмите кнопку
 .
.В диалоговом окне "Создание задачи" откроется вкладка Задачи.
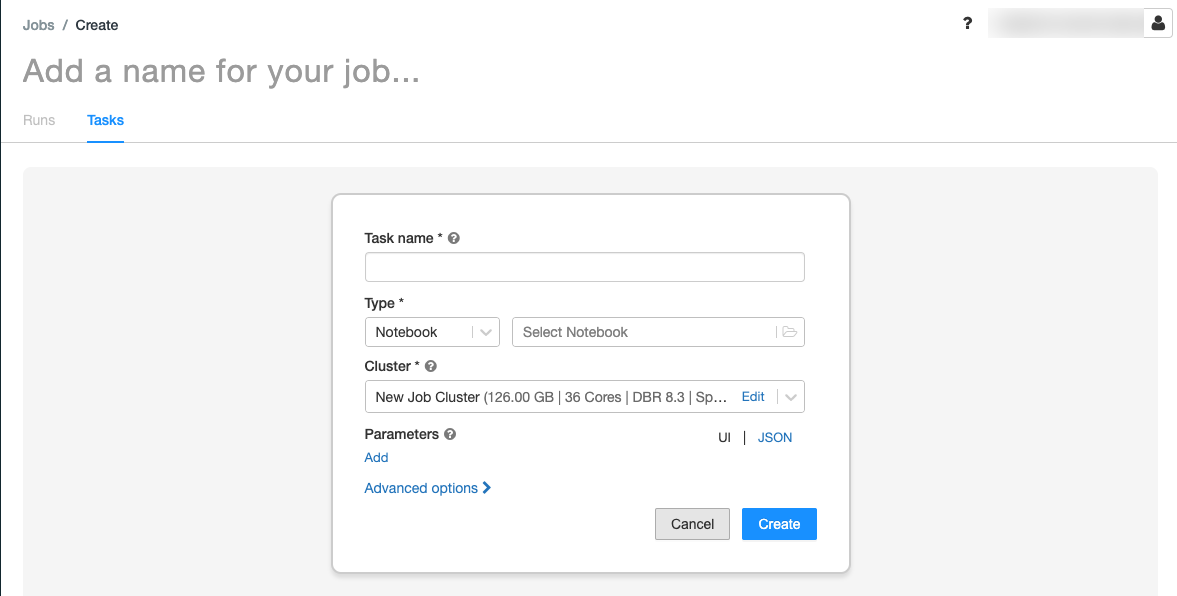
Замените Добавьте имя для задания… на имя задания.
В поле Имя задачи введите название задачи, например greeting-task.
В раскрывающемся меню "Тип" выберите "Записная книжка".
В раскрывающемся меню "Источник" выберите "Рабочая область".
Щелкните текстовое поле "Путь " и используйте браузер файлов, чтобы найти созданную записную книжку, щелкните имя записной книжки и нажмите кнопку "Подтвердить".
В разделе Параметры щелкните Добавить. В поле Ключ введите
greeting. В поле Значение введитеAirflow user.Нажмите Создать задачу.
На панели сведений о задании скопируйте значение идентификатора задания. Оно потребуется для запуска задания из Airflow.
Запуск задания
Чтобы протестировать новое задание в пользовательском интерфейсе заданий Azure Databricks, щелкните  в правом верхнем углу. По завершении выполнения можно проверить выходные данные, просмотрев сведения о выполнении задания.
в правом верхнем углу. По завершении выполнения можно проверить выходные данные, просмотрев сведения о выполнении задания.
Создание новой DAG Airflow
Направленный ациклический граф (DAG) Airflow задается в файле Python. Чтобы создать DAG для запуска примера задания записной книжки, выполните указанные ниже действия.
В текстовом редакторе или интегрированной среде разработки создайте новый файл с именем
databricks_dag.pyи следующим содержимым:from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator from airflow.utils.dates import days_ago default_args = { 'owner': 'airflow' } with DAG('databricks_dag', start_date = days_ago(2), schedule_interval = None, default_args = default_args ) as dag: opr_run_now = DatabricksRunNowOperator( task_id = 'run_now', databricks_conn_id = 'databricks_default', job_id = JOB_ID )Замените
JOB_IDзначением сохраненного ранее идентификатора задания.Сохраните файл в каталоге
airflow/dags. Airflow автоматически считывает и устанавливает файлы DAG, хранящиеся вairflow/dags/.
Установка и проверка DAG в Airflow
Чтобы активировать и проверить работоспособность DAG в пользовательском интерфейсе Airflow, выполните указанные ниже действия.
- В окне браузера откройте
http://localhost:8080/home. Появится экран DAG Airflow. - Найдите
databricks_dagи с помощью переключателя Приостановить/возобновить DAG отменить приостановку DAG. - Активируйте DAG, нажав кнопку "Триггер DAG ".
- Щелкните запуск в столбце Запуски, чтобы просмотреть его состояние и сведения о выполнении.