Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Конвейер может содержать несколько потоков, которые почти идентичны, отличаясь только несколькими параметрами. Определение этих потоков явно подвержено ошибкам, избыточности и трудно поддерживать. Метапрограммирование с помощью Python внутренних функций динамически создает повторяющиеся потоки с каждым вызовом, предоставляющим другой набор параметров.
Обзор метапрограммирования
В конвейерах Lakeflow метапрограммирование использует внутренние функции Python. Так как эти функции лениво оцениваются средой выполнения конвейера, вы можете заключить @dp.table декораторы внутрь функции-фабрики и вызывать эту фабрику несколько раз с различными аргументами. Каждый вызов регистрирует новый поток без дублирования кода.
Дополнительные сведения об использовании циклов for с конвейерами Lakeflow см. в разделе «Создание таблиц в цикле for».
Пример: время отклика пожарной службы
В следующем примере используется встроенный набор данных пожарной службы для поиска районов с самым быстрым временем реагирования на чрезвычайные ситуации для каждого типа вызова. Без метапрограммирования необходимо написать почти идентичные определения таблиц для каждого типа вызова (оповещения, структура пожара, медицинский инцидент). С метапрограммированием одна функция фабрики создает все из них.
Шаг 1. Определите таблицу для приема необработанных данных
import functools
from pyspark import pipelines as dp
from pyspark.sql.functions import *
@dp.table(
name="raw_fire_department",
comment="raw table for fire department response"
)
@dp.expect_or_drop("valid_received", "received IS NOT NULL")
@dp.expect_or_drop("valid_response", "responded IS NOT NULL")
@dp.expect_or_drop("valid_neighborhood", "neighborhood != 'None'")
def get_raw_fire_department():
return (
spark.read.format('csv')
.option('header', 'true')
.option('multiline', 'true')
.load('/databricks-datasets/timeseries/Fires/Fire_Department_Calls_for_Service.csv')
.withColumnRenamed('Call Type', 'call_type')
.withColumnRenamed('Received DtTm', 'received')
.withColumnRenamed('Response DtTm', 'responded')
.withColumnRenamed('Neighborhooods - Analysis Boundaries', 'neighborhood')
.select('call_type', 'received', 'responded', 'neighborhood')
)
Шаг 2: Определите функцию создания потоков
Фабричная функция generate_tables регистрирует две таблицы для каждого типа вызова: отфильтрованную таблицу вызовов и таблицу с ранжированным временем отклика. Оба создаются как внутренние функции, декорированные с помощью @dp.table.
all_tables = []
def generate_tables(call_table, response_table, filter):
@dp.table(
name=call_table,
comment="top level tables by call type"
)
def create_call_table():
return spark.sql("""
SELECT
unix_timestamp(received,'M/d/yyyy h:m:s a') as ts_received,
unix_timestamp(responded,'M/d/yyyy h:m:s a') as ts_responded,
neighborhood
FROM raw_fire_department
WHERE call_type = '{filter}'
""".format(filter=filter))
@dp.table(
name=response_table,
comment="top 10 neighborhoods with fastest response time"
)
def create_response_table():
return spark.sql("""
SELECT
neighborhood,
AVG((ts_received - ts_responded)) as response_time
FROM {call_table}
GROUP BY 1
ORDER BY response_time
LIMIT 10
""".format(call_table=call_table))
all_tables.append(response_table)
Шаг 3. Вызов фабрики и определение сводной таблицы
Вызовите фабрику один раз для каждого типа вызова, а затем определите сводную таблицу, которая объединяет результаты для поиска районов, которые отображаются чаще всего во всех категориях.
generate_tables("alarms_table", "alarms_response", "Alarms")
generate_tables("fire_table", "fire_response", "Structure Fire")
generate_tables("medical_table", "medical_response", "Medical Incident")
@dp.table(
name="best_neighborhoods",
comment="which neighbor appears in the best response time list the most"
)
def summary():
target_tables = [dp.read(t) for t in all_tables]
unioned = functools.reduce(lambda x, y: x.union(y), target_tables)
return (
unioned.groupBy(col("neighborhood"))
.agg(count("*").alias("score"))
.orderBy(desc("score"))
)
После запуска этого конвейера вы создадите набор аналогичных таблиц, например этот граф:
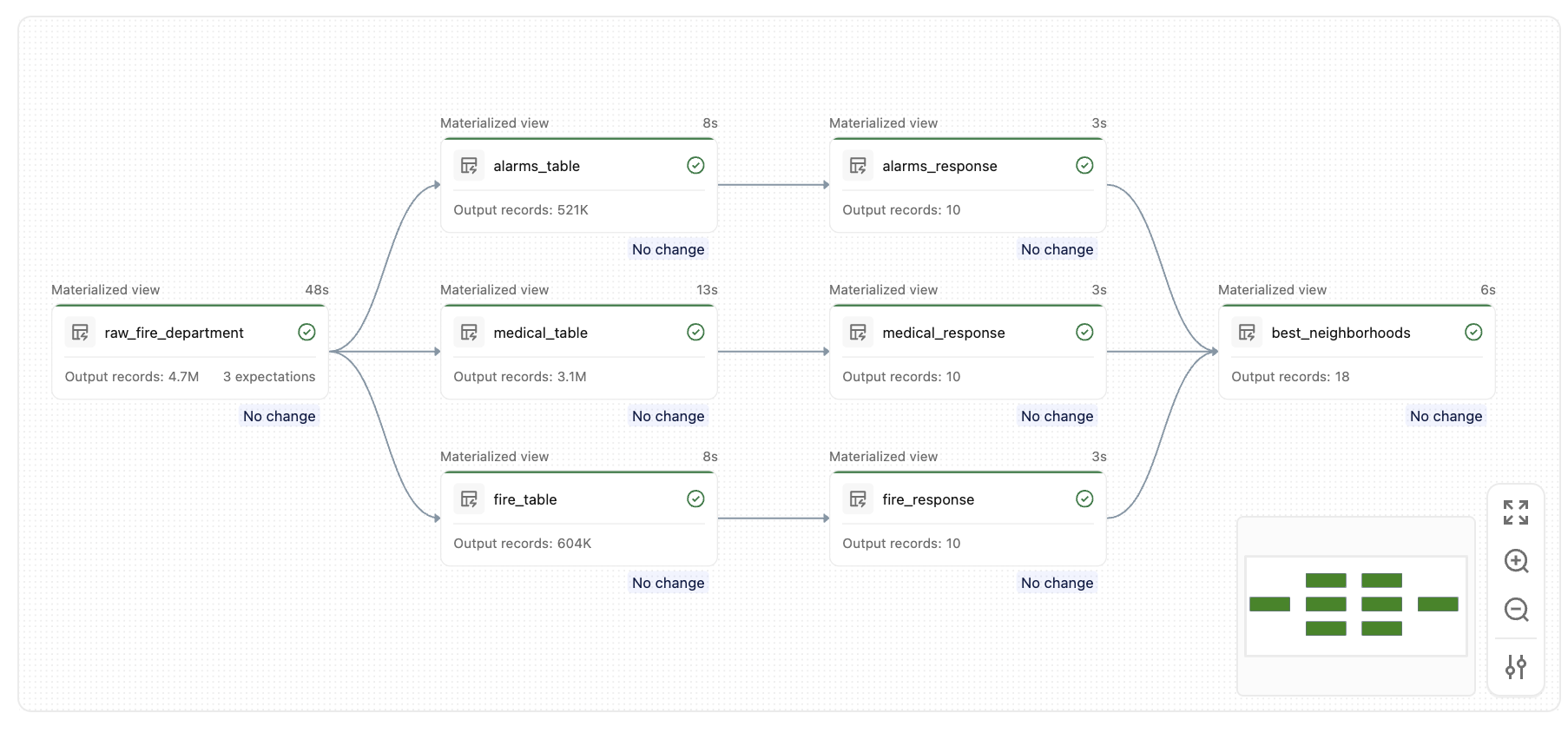
Основные понятия
-
Внутренние функции регистрируются лениво: декоратор
@dp.tableне запускает функцию немедленно. Он регистрирует функцию в среде выполнения выполняющегося конвейера, которая выстраивает полный граф потока данных перед началом выполнения. -
Закрытия захватывают параметры: каждая внутренняя функция захватывает параметры, переданные фабрике (
call_table,response_table,filter), поэтому каждый зарегистрированный поток использует собственный изолированный набор значений. -
Динамические списки таблиц: использование списка, например
all_tablesдля отслеживания программно созданных имен таблиц, упрощает их ссылку позже (например, в союзе или присоединении).