Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Вы создаете новый конвейер Lakeflow для оркестрации данных с помощью автозагрузчика, а затем расширяете пример конвейера, очищая данные и создавая запрос для поиска лучших 100 пользователей.
В этом руководстве вы узнаете, как использовать редактор Конвейеров Lakeflow для:
- Создайте конвейер со структурой папок по умолчанию и начните с набора примеров файлов.
- Определите ограничения качества данных с помощью ожиданий.
- Используйте функции редактора для расширения конвейера с новым преобразованием для выполнения анализа данных.
Требования
Перед началом работы с этим руководством необходимо выполнить следующие действия.
- Войдите в рабочую область Azure Databricks.
- Убедитесь, что каталог Unity включен для вашей рабочей области.
- Разрешение на создание вычислительного ресурса или доступ к вычислительному ресурсу.
- У вас есть разрешения на создание новой схемы в каталоге. Необходимые разрешения — это
ALL PRIVILEGESилиUSE CATALOGиCREATE SCHEMA. - Полный набор привилегий, необходимых для создания, запуска, обновления и просмотра конвейеров и их выходных данных, см. в статье "Управление удостоверениями, разрешениями и привилегиями для конвейеров".
Шаг 1. Создание конвейера
На этом шаге вы создадите конвейер с помощью структуры папок по умолчанию и примеров кода. Примеры кода ссылались на таблицу users в wanderbricks примере источника данных.
В рабочей области Azure Databricks щелкните
 New затем
New затем  ETL pipeline. Откроется редактор конвейера с именем конвейера по умолчанию, например
ETL pipeline. Откроется редактор конвейера с именем конвейера по умолчанию, например New Pipeline <date> <time>.(Необязательно) Выберите имя и введите описательное имя конвейера.
(Необязательно) Справа от имени щелкните каталог и схему, чтобы задать разные значения по умолчанию.
(Необязательно) В исходном файле
my_transformation, созданном для вас, выберите Python или SQL из раскрывающегося списка языков, чтобы задать язык для файла.Щелкните
 Используйте пример кода.
Используйте пример кода.Пример кода на выбранном языке отображается в исходном
my_transformationфайле в папкеtransformations. Выходные наборы данных еще не созданы, а граф конвейера справа от экрана пуст.Чтобы запустить код конвейера (код в папке), нажмите кнопку
transformations" в правой верхней части экрана.После завершения выполнения в нижней части рабочей области отображаются две новые таблицы, которые были созданы:
sample_users_<date_time>иsample_aggregation_<date_time>. Граф конвейера в правой части рабочей области теперь показывает две таблицы, в том числе то, чтоsample_usersявляется источником дляsample_aggregation. Запишите полноеsample_users_<date_time>имя таблицы; вы ссылаетесь на нее на следующем шаге.
Шаг 2. Применение проверок качества данных
На этом шаге вы добавите проверку качества данных в таблицу sample_users .
Ожидания конвейера используются для ограничения данных. В этом случае вы удаляете все записи пользователя, у которых нет допустимого адреса электронной почты, и выводит чистую таблицу как users_cleaned.
В обозревателе ресурсов конвейера слева щелкните
и выберите Преобразование.В диалоговом окне создания файла преобразования сделайте следующее:
- Выберите Python или SQL для Language. Это не обязательно соответствует предыдущему выбору.
- Присвойте файлу имя. В этом случае выберите
users_cleaned. - Для пути назначения оставьте значение по умолчанию.
- Для типа набора данных оставьте его как "Нет" или выберите "Материализованное представление". Если выбрать материализованное представление, он создает пример кода для вас.
Нажмите кнопку "Создать", чтобы создать файл кода преобразования.
В новом файле кода измените код следующим образом (используйте SQL или Python на основе выбора на предыдущем экране). Замените
sample_users_<date_time>на полное имя вашейsample_usersтаблицы из предыдущего раздела.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Нажмите кнопку "Запустить конвейер ", чтобы обновить конвейер. Теперь она должна иметь три таблицы.
Шаг 3. Анализ лучших пользователей
Затем получите 100 лучших пользователей по количеству созданных резервирований. Присоединяйте таблицу wanderbricks.bookings к материализованному представлению users_cleaned .
В браузере активов конвейера слева щелкните
и выберите "Преобразование".В диалоговом окне создания файла преобразования сделайте следующее:
- Выберите Python или SQL для Language. Это не обязательно соответствует предыдущим выбранным параметрам.
- Присвойте файлу имя. В этом случае выберите
users_and_bookings. - Для пути назначения оставьте значение по умолчанию.
- Для типа набора данных оставьте в значении Не выбрано.
Нажмите кнопку "Создать", чтобы создать файл кода преобразования.
В новом файле кода измените код следующим образом (используйте SQL или Python на основе выбора на предыдущем экране).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Нажмите кнопку "Запустить конвейер ", чтобы обновить наборы данных. После завершения выполнения вы сможете увидеть в графике конвейера четыре таблицы, включая новую таблицу
users_and_bookings.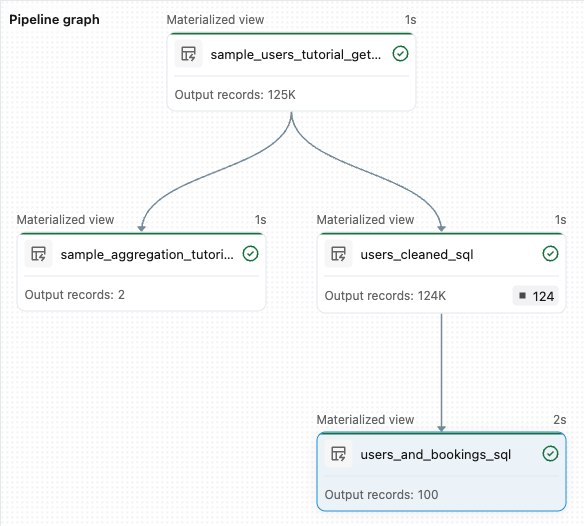
Дополнительные ресурсы
Теперь, когда вы узнали, как использовать некоторые функции редактора конвейеров Lakeflow и создали конвейер, ознакомьтесь с другими функциями, чтобы узнать больше о следующих возможностях:
Средства для работы с преобразованиями и отладкой при создании конвейеров:
- Выборочное выполнение
- Предварительные версии данных
- Интерактивный граф конвейера (граф наборов данных в конвейере)
Встроенная интеграция с декларативными пакетами автоматизации для эффективной совместной работы, управления версиями и интеграции CI/CD непосредственно из редактора: