Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Внимание
Онлайн-таблицы находятся в общедоступной предварительной версии в следующих регионах: westus, eastus, eastus2, northeurope. westeurope Сведения о ценах см. в разделе Цены на онлайн-таблицы.
Онлайн-таблица — это копия Delta Table, хранящаяся в ориентированном на строки формате, оптимизированная для онлайн-доступа. Сетевые таблицы — это полностью бессерверные таблицы, которые обеспечивают автоматическую масштабирование пропускной способности с нагрузкой запроса и обеспечивают низкую задержку и высокий доступ к данным любого масштаба. Онлайн-таблицы предназначены для работы с такими приложениями, как Обслуживание моделей Mosaic AI, Обслуживание признаков и дополненные извлечением и генерацией (RAG), где они используются для быстрого поиска данных.
Вы также можете использовать онлайн-таблицы в запросах с помощью Lakehouse Federation. При использовании Федерации Lakehouse необходимо использовать бессерверное хранилище SQL для доступа к онлайн-таблицам. Поддерживаются только операции чтения (SELECT). Эта функция предназначена только для интерактивной работы или отладки и не должна использоваться для производственных или критически важных рабочих нагрузок.
Создание интерактивной таблицы с помощью пользовательского интерфейса Databricks — это одношаговый процесс. Просто выберите таблицу Delta в обозревателе каталогов и выберите " Создать онлайн-таблицу". Для создания и управления онлайн-таблицами можно также использовать REST API или пакет SDK Databricks. См. статью " Работа с онлайн-таблицами с помощью API".
Требования
- Рабочая область должна быть активирована для работы с Unity Catalog. Следуйте документации, чтобы создать хранилище метаданных каталога Unity, включите его в рабочей области и создайте каталог.
- Модель должна быть зарегистрирована в каталоге Unity для доступа к онлайн-таблицам.
Работа с онлайн-таблицами с помощью пользовательского интерфейса
В этом разделе описывается создание и удаление интерактивных таблиц, а также проверка состояния и активация обновлений веб-таблиц.
Создание интерактивной таблицы с помощью пользовательского интерфейса
Вы создаете онлайн-таблицу с помощью обозревателя каталогов. Сведения о необходимых разрешениях см. в разделе "Разрешения пользователей".
Чтобы создать интерактивную таблицу, исходная таблица Delta должна иметь первичный ключ. Если в таблице Delta, которую вы хотите использовать, нет первичного ключа, создайте ее, выполнив следующие инструкции: используйте существующую таблицу Delta в каталоге Unity в качестве таблицы компонентов.
В обозревателе каталогов перейдите к исходной таблице, которую требуется синхронизировать с веб-таблицей. В меню "Создать" выберите "Онлайн- таблица".
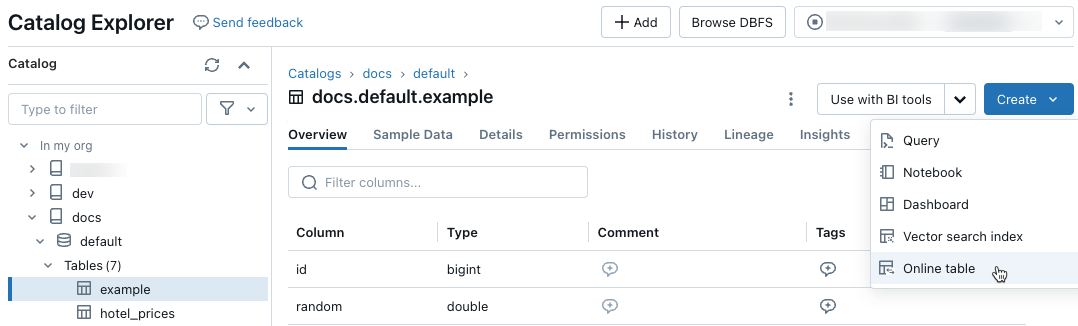
Используйте селекторы в диалоговом окне, чтобы настроить интерактивную таблицу.
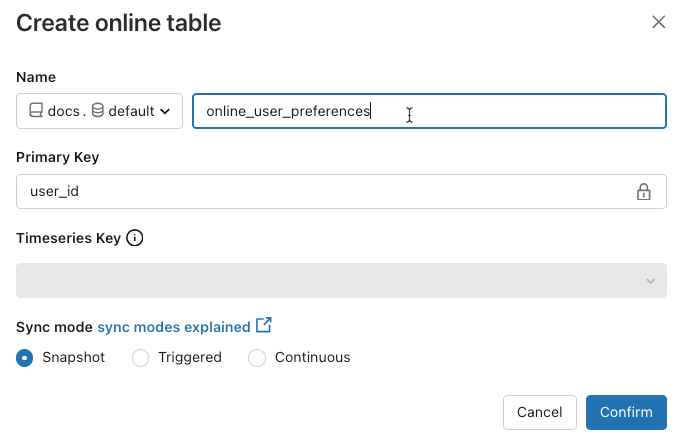
Имя: имя, используемое для интерактивной таблицы в каталоге Unity.
Первичный ключ: столбцы в исходной таблице для использования в качестве первичных ключей в интерактивной таблице.
Ключ временного ряда: (необязательно). Столбец в исходной таблице для использования в качестве ключа временного ряда. При задании параметра, таблица включает только строку с последним значением ключа временного ряда для каждого первичного ключа.
Режим синхронизации. Указывает, как конвейер синхронизации обновляет интерактивную таблицу. Выберите один из Снимок, Срабатывание, или Непрерывный.
Политика Описание Снимок Пайплайн выполняется один раз, чтобы создать моментальный снимок исходной таблицы и скопировать его в онлайн-таблицу. Последующие изменения исходной таблицы автоматически отражаются в интерактивной таблице, принимая новый снимок источника и создавая новую копию. Содержимое интерактивной таблицы обновляется атомарно. Активируемые Конвейер обработки данных запускается один раз, чтобы создать начальную копию моментального снимка исходной таблицы в онлайн-таблице. В отличие от режима синхронизации моментальных снимков, при обновлении интернет-таблицы извлекаются и применяются только изменения с момента последнего выполнения конвейера. Добавочное обновление можно активировать вручную или автоматически активировать в соответствии с расписанием. Непрерывный Трубопровод работает непрерывно. Последующие изменения исходной таблицы постепенно применяются к онлайн таблице в режиме потоковой передачи в реальном времени. Обновление вручную не требуется.
Примечание.
Для поддержки режима триггерной или непрерывной синхронизации исходная таблица должна включать канал изменений данных.
- По завершении нажмите кнопку "Подтвердить". Откроется страница таблицы в Интернете.
- Новая онлайн-таблица создается под указанными в диалоговом окне создания каталогом, схемой и именем. В обозревателе каталогов онлайн таблица обозначена
 .
.
Получите состояние и запустите обновления с помощью пользовательского интерфейса
Чтобы проверить состояние интерактивной таблицы, щелкните имя таблицы в каталоге, чтобы открыть ее. Откроется страница таблицы с открытой вкладкой "Обзор". В разделе "Прием данных" отображается состояние последнего обновления. Чтобы активировать обновление, нажмите кнопку "Синхронизировать сейчас". В разделе " Прием данных " также содержится ссылка на конвейер, который обновляет таблицу.
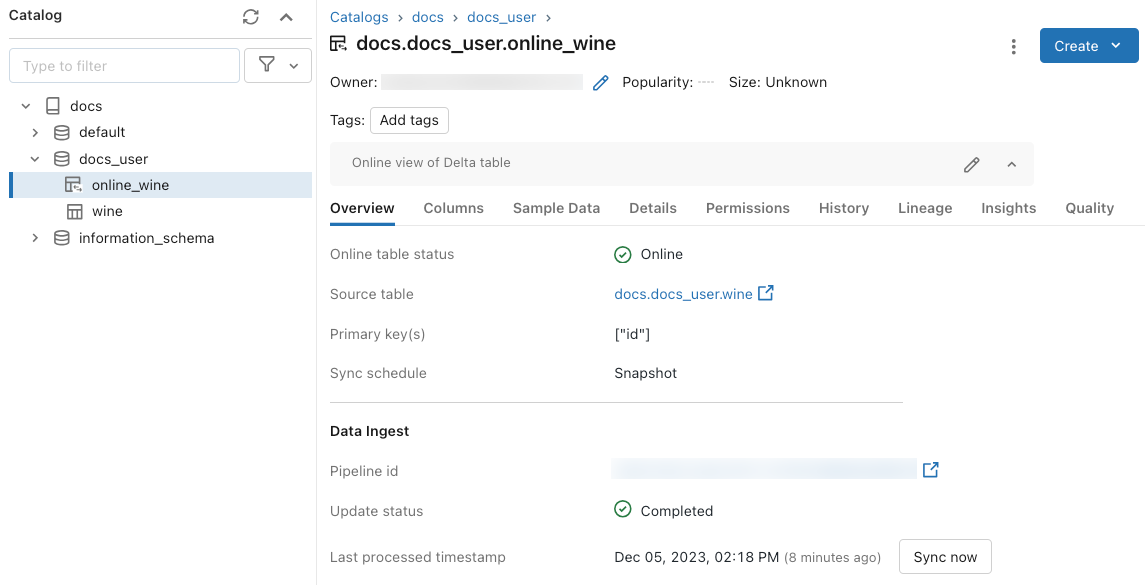
Планирование периодических обновлений
Для онлайн-таблиц с режимом синхронизации моментальных снимков или триггеров можно запланировать автоматические периодические обновления. Расписание обновления управляется конвейером, который обновляет таблицу.
- В обозревателе каталогов перейдите к интерактивной таблице.
- В разделе Прием данных щелкните ссылку на канал.
- В правом верхнем углу щелкните "Расписание" и добавьте новое расписание или обновите существующие расписания.
Удаление интерактивной таблицы с помощью пользовательского интерфейса
На странице "Онлайн-таблица" выберите "Удалить" в ![]()
Работа с онлайн-таблицами с помощью API
Вы также можете использовать пакет SDK Databricks или REST API для создания и управления онлайн-таблицами.
Справочные сведения см. в справочной документации по пакету SDK Databricks для Python или REST API.
Требования
Пакет SDK Databricks версии 0.20 или более поздней.
Создание онлайн-таблицы с помощью API
SDK Databricks для Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
REST API
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
После создания таблицы в Сети автоматически начинается синхронизация.
Получение состояния и инициирование обновления с помощью API-интерфейсов
Вы можете просмотреть состояние и спецификацию онлайн-таблицы, следуя приведенному ниже примеру. Если ваша онлайн-таблица не является непрерывной и вы хотите активировать обновление данных вручную, вы можете использовать API конвейера для этого.
Используйте идентификатор конвейера, связанный с интерактивной таблицей в спецификации веб-таблицы, и запустите новое обновление конвейера для активации обновления. Это эквивалентно нажатию кнопки "Синхронизация сейчас " в пользовательском интерфейсе таблицы в обозревателе каталогов.
SDK Databricks для Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Lakeflow Declarative Pipelines: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
REST API
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Lakeflow Declarative Pipelines: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
Удаление интерактивной таблицы с помощью API
SDK Databricks для Python
w.online_tables.delete('main.default.my_online_table')
REST API
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
Удаление онлайн-таблицы останавливает текущую синхронизацию данных и освобождает все ресурсы.
Обслуживание данных таблицы в Сети с помощью конечной точки обслуживания функций
Для моделей и приложений, размещенных за пределами Databricks, можно создать конечную точку обслуживания функций для обслуживания функций из веб-таблиц. Конечная точка предоставляет функции с низкой задержкой с помощью REST API.
Создайте спецификацию компонентов.
При создании спецификации компонентов необходимо указать исходную таблицу Delta. Это позволяет использовать спецификацию функций как в автономном режиме, так и в сетевых сценариях. Для поиска по сети конечная точка обслуживания автоматически использует интерактивную таблицу для выполнения поиска функций с низкой задержкой.
Исходная таблица Delta и онлайн таблица должны использовать один и тот же первичный ключ.
Спецификация функций можно просмотреть на вкладке "Функция " в обозревателе каталогов.
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )Создайте конечную точку обслуживания функций.
На этом шаге предполагается, что вы создали онлайн-таблицу с именем
user_preferences_online_table, которая синхронизирует данные из таблицыuser_preferencesDelta. Используйте спецификацию компонентов для создания конечной точки обслуживания компонентов. Конечная точка предоставляет данные через REST API с помощью связанной интерактивной таблицы.Примечание.
Пользователь, выполняющий эту операцию, должен быть владельцем автономной таблицы и интерактивной таблицы.
SDK Databricks для Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )API Python
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )Получение данных из конечной точки обслуживания компонентов.
Чтобы получить доступ к конечной точке API, отправьте HTTP-запрос POST в URL-адрес конечной точки. В примере показано, как это сделать с помощью API Python. Для получения информации о других языках и инструментах см. раздел "Обслуживание функций".
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
Использование онлайн-таблиц с приложениями RAG
Приложения RAG — это распространенный вариант использования для онлайн-таблиц. Вы создаете онлайн-таблицу для структурированных данных, необходимых приложению RAG, и размещаете ее на конечной точке предоставления функций. Приложение RAG использует конечную точку предоставления функций для поиска соответствующих данных из онлайн-таблицы.
Типичные шаги приведены ниже.
- Создайте конечную точку обслуживания функций.
- Создайте средство с помощью LangChain или любого аналогичного пакета, использующего конечную точку для поиска соответствующих данных.
- Используйте средство в агенте LangChain или аналогичном агенте для получения соответствующих данных.
- Создайте конечную точку обслуживания модели для размещения приложения.
Пошаговые инструкции и пример записной книжки см. в статье "Пример использования функций с структурированными приложениями RAG".
Примеры записных книжек
В следующей записной книжке показано, как публиковать функции в онлайн-таблицах для обслуживания в режиме реального времени и автоматического поиска функций.
Демонстрационная записная книжка для таблиц в Интернете
Использование онлайн-таблиц с предоставлением модели ИИ Mosaic
Вы можете использовать онлайн-таблицы для поиска функций для обслуживания модели ИИ Мозаики. При синхронизации таблицы признаков с онлайн-таблицей модели, обученные с использованием признаков из этой таблицы признаков, автоматически находят значения признаков из онлайн-таблицы во время вывода. Дополнительная настройка не требуется.
Используйте
FeatureLookupдля обучения модели.Для обучения модели используйте функции из автономной таблицы функций в наборе обучения модели, как показано в следующем примере:
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Разверните модель с помощью Mosaic AI для обслуживания моделей. Модель автоматически ищет функции из интерактивной таблицы. Дополнительные сведения см. в разделе "Обслуживание моделей" с автоматическим поиском функций .
Разрешения пользователя
Для создания интерактивной таблицы необходимо иметь следующие разрешения:
-
SELECTпривилегия на исходную таблицу. -
USE CATALOGпривилегия в целевом каталоге. -
USE SCHEMAиCREATE TABLEпривилегии на конечной схеме.
Чтобы управлять конвейером синхронизации данных онлайн-таблицы, вы должны либо быть владельцем онлайн-таблицы, либо иметь привилегию REFRESH на онлайн-таблицу. Пользователи, у которых нет USE CATALOG прав и USE SCHEMA привилегий в каталоге, не увидят таблицу в интернете в обозревателе каталогов.
Хранилище метаданных каталога Unity должно иметь модель привилегий версии 1.0.
Модель разрешений конечной точки
Уникальный принципал службы автоматически создается для функциональной службы или конечной точки вывода модели с ограниченными разрешениями, необходимыми для запроса данных из онлайн-таблиц. Этот субъект-служба позволяет конечным точкам получать доступ к данным независимо от пользователя, создавшего ресурс, и гарантирует, что конечная точка может продолжать функционировать, если создатель покидает рабочую область.
Время существования этого субъекта-службы — это время существования конечной точки. Журналы аудита могут указывать системные записи для владельца каталога Unity, предоставляющего этой служебной сущности необходимые привилегии.
Ограничения
- Для каждой исходной таблицы поддерживается только одна онлайн-таблица.
- В оперативной таблице и исходной таблице может быть не более 1000 столбцов.
- Столбцы типов данных ARRAY, MAP или STRUCT нельзя использовать в качестве первичных ключей в интерактивной таблице.
- Если столбец используется в качестве первичного ключа в интерактивной таблице, все строки в исходной таблице, где столбец содержит значения NULL, игнорируются.
- Внешние, системные и внутренние таблицы не поддерживаются в качестве исходных таблиц.
- Исходные таблицы без потока данных об изменении Delta поддерживают только режим синхронизации Snapshot.
- Таблицы Delta Sharing поддерживаются только в режиме моментального снимка.
- Имена каталогов, схем и таблиц в интерактивной таблице могут содержать только буквенно-цифровые символы и символы подчеркивания и не должны начинаться с чисел. Дефисы (
-) не допускаются. - Столбцы типа String ограничены длиной 64 КБ.
- Имена столбцов ограничены 64 символами в длину.
- Максимальный размер строки составляет 2 МБ.
- Объединенный размер всех интерактивных таблиц в хранилище метаданных каталога Unity во время общедоступной предварительной версии составляет 2 ТБ несжатых пользовательских данных.
- Максимальное количество запросов в секунду (QPS) составляет 12 000. Обратитесь к группе учетной записи Databricks, чтобы увеличить ограничение.
Устранение неполадок
Не отображается параметр "Создать онлайн-таблицу "
Причина обычно заключается в том, что тип таблицы, из которой вы пытаетесь выполнить синхронизацию (исходная таблица), не поддерживается. Убедитесь, что защищаемый вид исходной таблицы (показан на вкладке сведений обозревателя каталогов) является одним из следующих поддерживаемых вариантов.
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
Не удается выбрать режимы активации или непрерывной синхронизации при создании интерактивной таблицы
Это происходит, если в исходной таблице не включена функция потока изменений Delta, или если таблица является представлением или материализованным представлением. Чтобы использовать инкрементальный режим синхронизации, включите функцию отслеживания изменений данных в исходной таблице или используйте таблицу не в виде представления.
Обновление таблицы в Сети завершается сбоем или состояние отображается в автономном режиме
Чтобы начать устранение этой ошибки, щелкните идентификатор конвейера, который отображается на вкладке "Обзор " в интерактивной таблице в обозревателе каталогов.
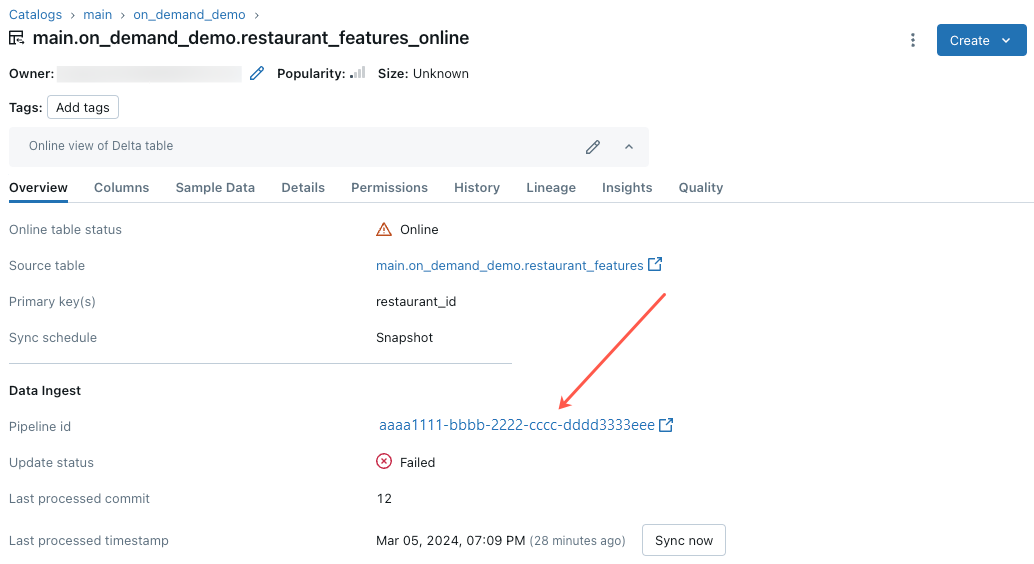
На отображаемой странице пользовательского интерфейса конвейера щелкните запись, которая говорит "Не удалось разрешить поток "__online_table".
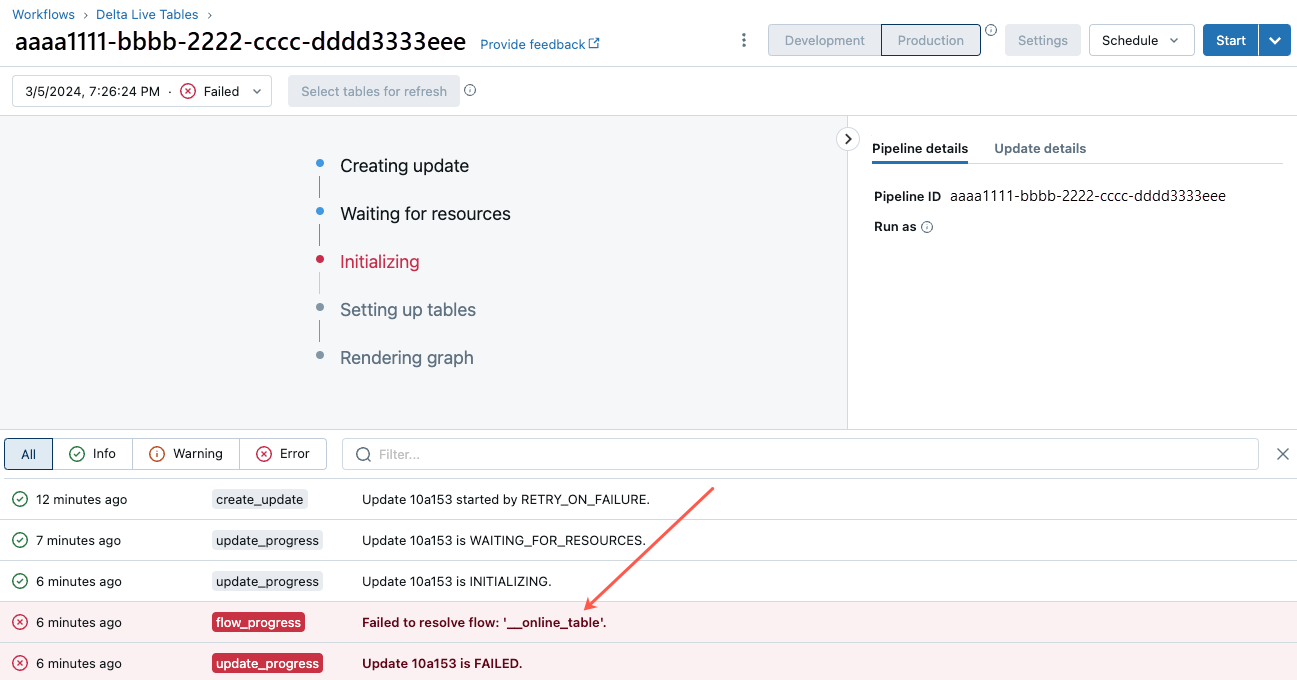
Появится всплывающее окно с подробными сведениями в разделе сведений об ошибке.
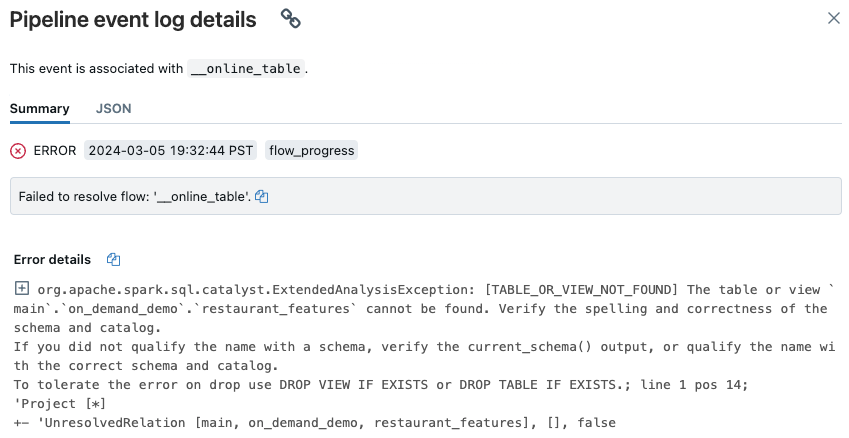
Ниже приведены распространенные причины ошибок.
Исходная таблица была удалена или удалена и заново создана с тем же именем, в то время как онлайн таблица синхронизировалась. Это особенно распространено с непрерывными онлайн-таблицами, так как они постоянно синхронизируются.
Доступ к исходной таблице невозможен с помощью бессерверных вычислений из-за параметров брандмауэра. В этом случае в разделе сведений об ошибке может появиться сообщение об ошибке "Не удалось запустить службу Декларативных конвейеров Lakeflow в кластере xxx...".
Совокупный размер онлайн-таблиц превышает ограничение на 2 ТБ (несжатый размер) в хранилище метаданных. Ограничение на 2 ТБ относится к объему несжатых данных после развёртывания таблицы Delta в строко-ориентированном формате. Размер таблицы в формате строки может быть значительно больше, чем размер таблицы Delta, показанной в обозревателе каталогов, которая ссылается на сжатый размер таблицы в формате, ориентированном на столбцы. Разница может превышать 100x в зависимости от содержимого таблицы.
Чтобы оценить несжатый и увеличенный по строкам размер Delta-таблицы, используйте следующий запрос из бессерверного SQL-склада. Запрос возвращает предполагаемый размер развернутой таблицы в байтах. Успешное выполнение этого запроса также подтверждает, что бессерверные вычисления могут получить доступ к исходной таблице.
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;