Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Databricks Feature Service делает данные на платформе Databricks доступными для моделей или приложений, развернутых за пределами Azure Databricks. Точки доступа для обслуживания функций автоматически масштабируются, чтобы адаптироваться к трафику в режиме реального времени и обеспечивать высокодоступную и с низкой задержкой службу для подачи функций. На этой странице описывается настройка и использование службы компонентов. Пошаговое руководство см. в разделе "Пример: развертывание и запрос конечной точки обслуживания компонентов".
При использовании службы модели для обслуживания модели, созданной с помощью функций Databricks, модель автоматически ищет и преобразует функции для запросов вывода. С помощью Службы функций Databricks можно обслуживать структурированные данные для приложений расширенного создания (RAG), а также функции, необходимые для других приложений, таких как модели, обслуживаемые за пределами Databricks или любого другого приложения, для которых требуются функции на основе данных в каталоге Unity.
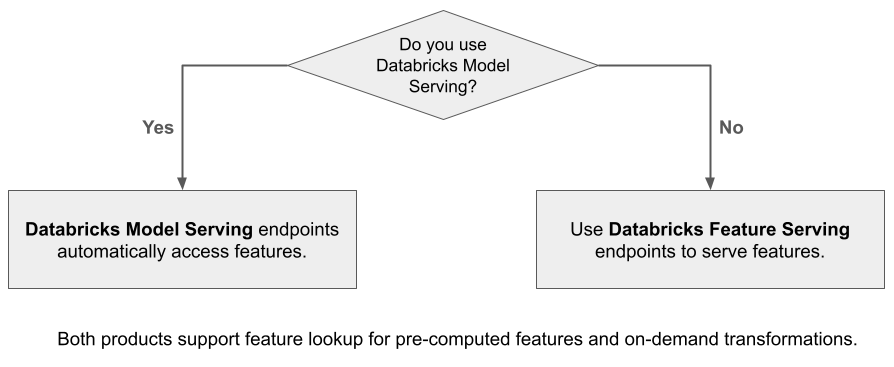
Зачем использовать обслуживание компонентов?
Служба Databricks Feature Serving предоставляет единый интерфейс для предоставления заранее материализованных функций и функций по запросу. Он также включает следующие преимущества:
- Простота. Databricks обрабатывает инфраструктуру. При одном вызове API Databricks создает рабочую среду обслуживания.
- Высокий уровень доступности и масштабируемость. Конечные точки сервиса функций автоматически масштабируются в увеличенное и уменьшенное состояние, чтобы адаптироваться к объему запросов на обслуживание.
- Безопасность. Конечные точки развертываются в защищенной сетевой границе и используют выделенные вычислительные ресурсы, завершающиеся при удалении или масштабировании конечной точки до нуля.
Требования
- Databricks Runtime 14.2 ML или более поздней версии.
- Чтобы использовать API Python, для Feature Serving требуется
databricks-feature-engineeringверсии 0.1.2 или более поздней, встроенной в Databricks Runtime 14.2 ML. Для более ранних версий Databricks Runtime ML установите необходимую версию вручную, используя%pip install databricks-feature-engineering>=0.1.2. Если вы используете записную книжку Databricks, необходимо перезапустить ядро Python, выполнив следующую команду в новой ячейке:dbutils.library.restartPython(). - Чтобы использовать SDK Databricks, для Feature Serving требуется
databricks-sdkверсия 0.18.0 или более поздняя. Чтобы вручную установить требуемую версию, используйте%pip install databricks-sdk>=0.18.0. Если вы используете записную книжку Databricks, необходимо перезапустить ядро Python, выполнив следующую команду в новой ячейке:dbutils.library.restartPython().
Служба функций Databricks предоставляет пользовательский интерфейс и несколько программных параметров для создания, обновления, запроса и удаления конечных точек. В этой статье приведены инструкции по каждому из следующих параметров:
- Пользовательский интерфейс Databricks
- REST API
- API Python
- Databricks SDK
Чтобы использовать REST API или пакет SDK для развертываний MLflow, необходимо иметь токен API Databricks.
Внимание
В качестве передовой практики безопасности для эксплуатационных сценариев Databricks рекомендует использовать машино-машинные OAuth токены для аутентификации в ходе производственных процессов.
Для тестирования и разработки Databricks рекомендует использовать личный маркер доступа, принадлежащий субъектам-службам , а не пользователям рабочей области. Сведения о создании маркеров для субъектов-служб см. в разделе "Управление маркерами" для субъекта-службы.
Проверка подлинности для предоставления функций
Сведения о проверке подлинности см. в разделе Authorize access to Azure Databricks resources.
Создайте FeatureSpec
A FeatureSpec — это задаваемый пользователем набор функций и характеристик. Функции и возможности можно объединить в FeatureSpec.
FeatureSpecs хранятся и управляются каталогом Unity и отображаются в обозревателе каталогов.
Таблицы, указанные в приложении, FeatureSpec должны быть опубликованы в интернет-магазине компонентов или стороннем интернет-магазине. См. сведения о хранилищах компонентов Databricks Online.
Для создания databricks-feature-engineeringпакета необходимо использовать FeatureSpec пакет.
Сначала определите функцию:
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def difference(num_1: float, num_2: float) -> float:
"""
A function that accepts two floating point numbers, subtracts the second one
from the first, and returns the result as a float.
Args:
num_1 (float): The first number.
num_2 (float): The second number.
Returns:
float: The resulting difference of the two input numbers.
"""
return num_1 - num_2
client.create_python_function(
func=difference,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
Затем можно использовать функцию в :FeatureSpec
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates num_1 - num_2.
input_bindings={"num_1": "ytd_spend", "num_2": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Указание значений по умолчанию
Чтобы указать значения по умолчанию для функций, используйте default_values параметр в файле FeatureLookup. См. следующий пример.
feature_lookups = [
FeatureLookup(
table_name="ml.recommender_system.customer_features",
feature_names=[
"membership_tier",
"age",
"page_views_count_30days",
],
lookup_key="customer_id",
default_values={
"age": 18,
"membership_tier": "bronze"
},
),
]
Если столбцы компонентов переименованы с помощью rename_outputs параметра, default_values необходимо использовать переименованные имена компонентов.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
Создание конечной точки
FeatureSpec определяет конечную точку. Для получения дополнительных сведений см. создание настраиваемых конечных точек обслуживания моделей, документацию по Python API или документацию Databricks SDK.
Примечание.
Для рабочих нагрузок, которые чувствительны к задержке или требуют высокого количества запросов в секунду, обслуживание модели предлагает оптимизацию маршрутов на пользовательских конечных точках обслуживания, см. Оптимизация маршрутов на конечных точках обслуживания.
SDK Databricks — Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
API Python
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
REST API
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Чтобы перейти к конечной точке обслуживания, щелкните Обслуживание в левой боковой панели пользовательского интерфейса Databricks. Когда состояние готово, конечная точка готова реагировать на запросы. Дополнительные сведения о службе моделей см. в разделе "Обслуживание моделей".
Сохраните дополненный DataFrame в таблице прогнозов
Для конечных точек, созданных начиная с февраля 2025 года, вы можете настроить конечную точку обслуживания модели для регистрации дополненного кадра данных, содержащего найденные значения признаков и возвращаемые значения функций. Кадр данных сохраняется в таблице вывода для обслуживаемой модели.
Инструкции по настройке этой конфигурации см. в разделе "Журналы поиска функции в DataFrames для вычислительных таблиц".
Сведения о таблицах вывода см. в статье "Мониторинг обслуживаемых моделей с помощью таблиц вывода с поддержкой шлюза ИИ Unity".
Получение конечной точки
Пакет SDK Databricks или API Python можно использовать для получения метаданных и состояния конечной точки.
SDK Databricks — Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
API Python
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Получение схемы конечной точки
Пакет SDK Databricks или REST API можно использовать для получения схемы конечной точки. Дополнительные сведения о схеме конечной точки см. в разделе «Схема конечной точки обслуживания модели».
SDK Databricks — Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
# Create endpoint
endpoint = workspace.serving_endpoints.get_open_api(name="customer-features")
REST API
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Запрос конечной точки
Для запроса конечной точки можно использовать REST API, пакет SDK для развертываний MLflow или пользовательский интерфейс обслуживания.
В следующем коде показано, как настроить учетные данные и создать клиент при использовании пакета SDK для развертываний MLflow.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Примечание.
В качестве рекомендации по обеспечению безопасности при аутентификации с использованием автоматизированных инструментов, систем, скриптов и приложений Databricks рекомендует использовать токены личного доступа, принадлежащие служебным принципалам, а не пользователям рабочей области. Сведения о создании маркеров для субъектов-служб см. в разделе "Управление маркерами" для субъекта-службы.
Запрос конечной точки с помощью API
В этом разделе приведены примеры запроса конечной точки с помощью REST API или пакета SDK для развертываний MLflow.
Пакет SDK для развертываний MLflow
Внимание
В следующем примере используется predict() API из пакета SDK для развертываний MLflow. Этот API является экспериментальным, а определение API может измениться.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
REST API
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
Запрос конечной точки с помощью пользовательского интерфейса
Вы можете запросить конечную точку обслуживания непосредственно из пользовательского интерфейса обслуживания. Пользовательский интерфейс содержит созданные примеры кода, которые можно использовать для запроса конечной точки.
В левой боковой панели рабочей области Azure Databricks щелкните Serving.
Щелкните конечную точку, которую вы хотите запросить.
В правом верхнем углу экрана щелкните конечную точку запроса.
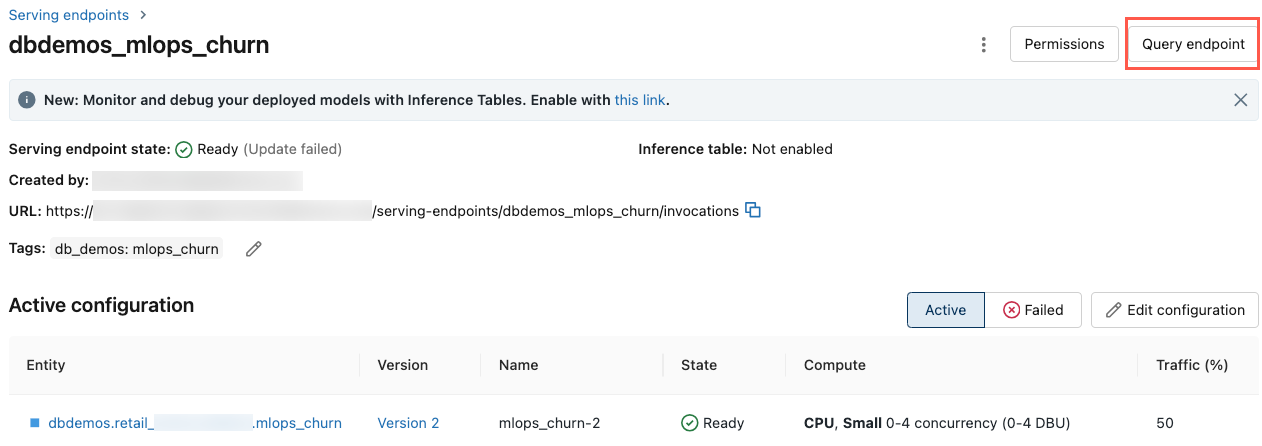
В поле "Запрос" введите текст запроса в формате JSON.
Нажмите кнопку "Отправить запрос".
// Example of a request body.
{
"dataframe_records": [
{ "user_id": 1, "ytd_spend": 598 },
{ "user_id": 2, "ytd_spend": 280 }
]
}
Диалоговое окно Конечная точка запроса содержит сгенерированный пример кода на curl, Python и SQL. Щелкните вкладки, чтобы просмотреть и скопировать пример кода.
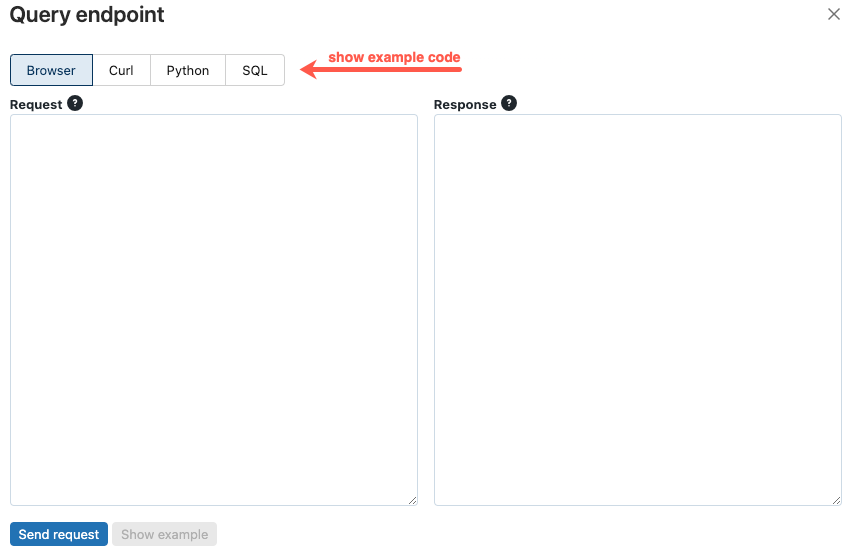
Чтобы скопировать код, щелкните значок копирования в правом верхнем углу текстового поля.
Обновление конечной точки
Внимание
Чтобы изменить конфигурацию конечной точки сервиса Feature Serving (например, изменить размер FeatureSpec или рабочей нагрузки), всегда используйте интерфейсы API обновления, описанные в этом разделе. Не удаляйте и не создавайте конечную точку заново для применения изменений. Удаление живой конечной точки приводит к немедленному простою и прерывает все приложения, запрашивающие её.
Конечную точку можно обновить с помощью REST API, пакета SDK Databricks или пользовательского интерфейса обслуживания.
Обновление конечной точки с помощью API
SDK Databricks — Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
REST API
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Обновление конечной точки с помощью пользовательского интерфейса
Выполните следующие действия, чтобы использовать пользовательский интерфейс обслуживания:
- В левой боковой панели рабочей области Azure Databricks щелкните Serving.
- В таблице щелкните имя конечной точки, которую нужно обновить. Откроется экран конечной точки.
- В правом верхнем углу экрана нажмите кнопку "Изменить конечную точку".
- В диалоговом окне "Изменение обслуживания конечной точки " измените параметры конечной точки по мере необходимости.
- Нажмите кнопку "Обновить", чтобы сохранить изменения.

Удаление конечной точки
Предупреждение
Это действие необратимо. Удаление конечной точки обслуживания компонентов приводит к немедленному простою для любых приложений, запрашивающих его. Если вы хотите изменить конфигурацию конечной точки, используйте обновление конечной точки вместо удаления и повторного создания конечной точки.
Конечную точку можно удалить с помощью REST API, пакета SDK Databricks, API Python или пользовательского интерфейса обслуживания.
Удаление конечной точки с помощью API
SDK Databricks — Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.delete(name="customer-features")
API Python
fe.delete_feature_serving_endpoint(name="customer-features")
REST API
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Удаление конечной точки с помощью пользовательского интерфейса
Выполните следующие действия, чтобы удалить конечную точку с помощью пользовательского интерфейса обслуживания:
- В левой боковой панели рабочей области Azure Databricks щелкните Serving.
- В таблице щелкните имя конечной точки, которую вы хотите удалить. Откроется экран конечной точки.
- В правом верхнем углу экрана щелкните
 и выберите пункт "Удалить".
и выберите пункт "Удалить".

Мониторинг работоспособности конечной точки
Сведения о журналах и метриках, доступных для конечных точек обслуживания компонентов, см. в разделе "Мониторинг качества модели" и работоспособности конечных точек.
Управление доступом
Сведения о разрешениях для конечных точек обслуживания компонентов см. в разделе "Управление разрешениями" в конечной точке обслуживания модели.
Пример записной книжки
В этой записной книжке показано, как использовать пакет SDK Databricks для создания конечной точки обслуживания компонентов с помощью Хранилища компонентов Databricks Online.