Создание конечных точек обслуживания пользовательских моделей
В этой статье описывается создание конечных точек обслуживания моделей, которые служат пользовательским моделям с помощью Службы моделей Databricks.
Служба моделей предоставляет следующие параметры для создания конечной точки:
- Пользовательский интерфейс обслуживания
- REST API
- Пакет SDK для развертываний MLflow
Сведения о создании конечных точек, которые служат моделями основы создания ИИ, см. в разделе "Создание модели создания модели искусственного интеллекта" для обслуживания конечных точек.
Требования
- Рабочая область должна находиться в поддерживаемом регионе.
- Если вы используете пользовательские библиотеки или библиотеки с частного зеркального сервера с моделью, ознакомьтесь с помощью пользовательских библиотек Python с моделью, прежде чем создавать конечную точку модели.
- Для создания конечных точек с помощью пакета SDK для развертываний MLflow необходимо установить клиент развертывания MLflow. Чтобы установить его, выполните следующую команду:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Управление доступом
Сведения о параметрах управления доступом для конечных точек обслуживания моделей для управления конечными точками см. в статье "Управление разрешениями" в конечной точке обслуживания модели.
Можно также добавить переменные среды для хранения учетных данных для обслуживания модели. См. раздел "Настройка доступа к ресурсам из конечных точек обслуживания модели"
Создание конечной точки
Обслуживающий пользовательский интерфейс
Вы можете создать конечную точку для модели, обслуживаемой с помощью пользовательского интерфейса обслуживания .
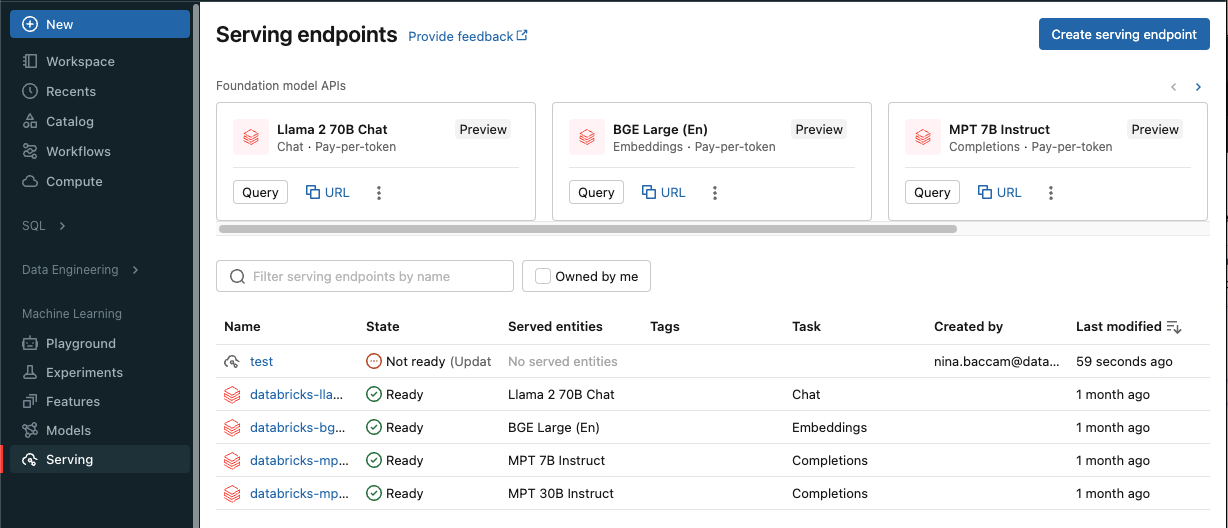
Щелкните "Служить " на боковой панели, чтобы отобразить пользовательский интерфейс обслуживания.
Нажмите кнопку "Создать конечную точку обслуживания".
Для моделей, зарегистрированных в реестре моделей рабочей области или моделях в каталоге Unity:
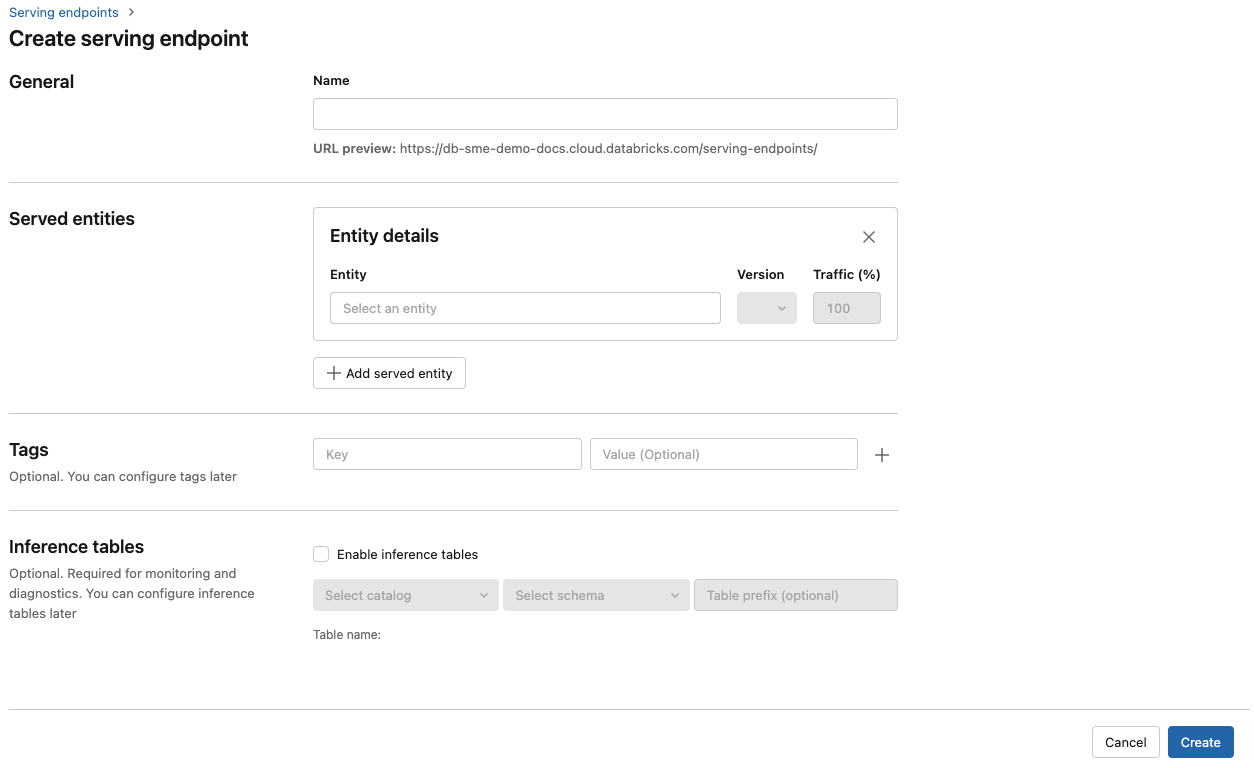
В поле "Имя" укажите имя конечной точки.
В разделе "Обслуживаемые сущности "
- Щелкните поле "Сущность", чтобы открыть форму "Выбор обслуживаемой сущности".
- Выберите тип модели, которую вы хотите обслуживать. Форма динамически обновляется на основе выбранного фрагмента.
- Выберите нужную модель и версию модели.
- Выберите процент трафика для маршрутизации в обслуживаемую модель.
- Выберите используемый размер вычислительных ресурсов. Вы можете использовать вычислительные ресурсы ЦП или GPU для рабочих нагрузок. Дополнительные сведения о доступных вычислительных ресурсах GPU см. в разделе "Типы рабочих нагрузок GPU".
- В разделе "Горизонтальное масштабирование вычислений" выберите размер горизонтального масштабирования вычислений, соответствующий количеству запросов, которые эта обслуживаемая модель может обрабатывать одновременно. Это число должно быть примерно равно времени выполнения модели QPS x.
- Доступные размеры: небольшие для 0-4 запросов, средних 8-16 запросов и больших для 16-64 запросов.
- Укажите, следует ли масштабировать конечную точку до нуля, если она не используется.
Нажмите кнопку Создать. Откроется страница "Обслуживание конечных точек" с состоянием конечной точки обслуживания, отображаемой как "Не готово".
REST API
Конечные точки можно создать с помощью REST API. Дополнительные сведения о параметрах конфигурации конечной точки см. в разделе POST /api/2.0/service-endpoints .
В следующем примере создается конечная точка, которая служит первой версией ads1 модели, зарегистрированной в реестре моделей. Чтобы указать модель из каталога Unity, укажите полное имя модели, включая родительский каталог и схему, catalog.schema.example-modelнапример.
POST /api/2.0/serving-endpoints
{
"name": "workspace-model-endpoint",
"config":{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
},
{
"entity_name": "my-ads-model",
"entity_version": "4",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":{
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
},
{
"served_model_name": "my-ads-model-4",
"traffic_percentage": 20
}
]
}
},
"tags": [
{
"key": "team",
"value": "data science"
}
]
}
Далее представлен пример ответа. Состояние конечной точки config_update — NOT_UPDATING это состояние, и обслуживаемая READY модель находится в состоянии.
{
"name": "workspace-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "my-ads-model-3",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
Пакет SDK для развертываний MLflow
Развертывания MLflow предоставляют API для задач создания, обновления и удаления. API для этих задач принимают те же параметры, что и REST API для обслуживания конечных точек. Дополнительные сведения о параметрах конфигурации конечной точки см. в разделе POST /api/2.0/service-endpoints .
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="workspace-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
}
}
)
Кроме того, вы можете сделать следующее:
- Настройте конечную точку для обслуживания нескольких моделей.
- Настройте конечную точку для оптимизации маршрутов.
- Настройте конечную точку для доступа к внешним ресурсам с помощью секретов Databricks.
- Включите таблицы вывода, чтобы автоматически записывать входящие запросы и исходящие ответы на конечные точки обслуживания модели.
Типы рабочих нагрузок GPU
Развертывание GPU совместимо со следующими версиями пакетов:
- Pytorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 и более поздних версий
Чтобы развернуть модели с помощью GPU, включите workload_type поле в конфигурацию конечной точки во время создания конечной точки или в качестве обновления конфигурации конечной точки с помощью API. Чтобы настроить конечную точку для рабочих нагрузок GPU с помощью пользовательского интерфейса обслуживания , выберите нужный тип GPU в раскрывающемся списке "Тип вычислений".
{
"served_entities": [{
"name": "ads1",
"entity_version": "2",
"workload_type": "GPU_LARGE",
"workload_size": "Small",
"scale_to_zero_enabled": false,
}]
}
В следующей таблице перечислены поддерживаемые типы рабочих нагрузок GPU.
| Тип рабочей нагрузки GPU | Экземпляр GPU | Память GPU |
|---|---|---|
GPU_SMALL |
1xT4 | 16 ГБ |
GPU_LARGE |
1xA100 | 80ГБ |
GPU_LARGE_2 |
2xA100 | 160ГБ |
Изменение конечной точки пользовательской модели
После включения пользовательской конечной точки модели можно обновить конфигурацию вычислений по мере необходимости. Эта конфигурация особенно полезна, если требуются дополнительные ресурсы для модели. Размер рабочей нагрузки и конфигурация вычислений играют ключевую роль в выборе ресурсов, выделяемых для обслуживания модели.
Пока новая конфигурация не будет готова, старая конфигурация будет обслуживать трафик прогнозирования. Пока выполняется обновление, еще одно обновление невозможно сделать. Однако вы можете отменить обновление в ходе выполнения из пользовательского интерфейса обслуживания.
Обслуживающий пользовательский интерфейс
После включения конечной точки модели выберите "Изменить конечную точку ", чтобы изменить конфигурацию вычислений конечной точки.
Доступны следующие действия:
- Выберите один из нескольких размеров рабочей нагрузки, а автомасштабирование автоматически настраивается в пределах размера рабочей нагрузки.
- Укажите, следует ли масштабировать конечную точку до нуля, если она не используется.
- Измените процент трафика для маршрутизации в обслуживаемую модель.
Вы можете отменить обновление конфигурации хода выполнения, нажав кнопку "Отменить обновление " в правом верхнем углу страницы сведений конечной точки. Эта функция доступна только в пользовательском интерфейсе обслуживания.
REST API
Ниже приведен пример обновления конфигурации конечной точки с помощью REST API. См. раздел PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "workspace-model-endpoint",
"config":{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
Пакет SDK для развертываний MLflow
Пакет SDK для развертываний MLflow использует те же параметры, что и REST API, см. в статье PUT /api/2.0/service-endpoints/{name}/config для сведений о схеме запроса и ответа.
В следующем примере кода используется модель из реестра моделей каталога Unity:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Оценка конечной точки модели
Чтобы оценить модель, отправьте запросы в конечную точку обслуживания модели.
- См. сведения о конечных точках обслуживания запросов для пользовательских моделей.
- См. статью "Базовые модели запросов".
Дополнительные ресурсы
- Управление конечными точками обслуживания моделей.
- Запрос конечных точек обслуживания для пользовательских моделей.
- Модели базы запросов.
- Внешние модели в мозаичной модели ИИ, обслуживающие модели.
- Таблицы вывода для моделей мониторинга и отладки.
- Если вы предпочитаете использовать Python, можно использовать пакет SDK для Python в режиме реального времени.
Примеры записных книжек
Следующие записные книжки включают различные зарегистрированные модели Databricks, которые можно использовать для получения и запуска с конечными точками обслуживания моделей.
Примеры модели можно импортировать в рабочую область, следуя указаниям в разделе Импорт записной книжки. После выбора и создания модели из одного из примеров зарегистрируйте ее в реестре моделей MLflow, а затем выполните действия по рабочему процессу пользовательского интерфейса для обслуживания модели.
Обучение и регистрация модели scikit-learn для записной книжки обслуживания модели
Обучение и регистрация модели HuggingFace для модели, обслуживающей записную книжку
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по