Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
В этой статье рассматриваются параметры вычислительных ресурсов записной книжки. Записную книжку можно запустить на универсальном вычислительном ресурсе, использовать бессерверные вычисления или для команд SQL использовать хранилище SQL, тип ресурсов, оптимизированных для аналитики SQL. Дополнительные сведения о типах вычислений см. в разделе .
Бессерверные вычисления для записных книжек
Бессерверные вычислительные ресурсы позволяют быстро подключать записную книжку к вычислительным ресурсам по запросу.
Чтобы подключиться к бессерверным вычислениям,
Дополнительные сведения см. в разделе "Бессерверные вычисления" для записных книжек.
Автоматическое восстановление сеанса для безсерверных нотбуков
Прекращение работы бессерверных вычислений может привести к потере выполняющейся работы, например значений переменных Python, в записных книжках. Чтобы избежать этого, включите автоматическое восстановление сеансов для бессерверных записных книжек.
- Щелкните имя пользователя в правом верхнем углу рабочей области, а затем щелкните "Параметры " в раскрывающемся списке.
- На боковой панели "Параметры" выберите "Разработчик".
- В разделе «Экспериментальные функции» включите настройку автоматического восстановления сеансов для бессерверных записных книжек.
Включение этого параметра позволяет Databricks создавать моментальные снимки состояния памяти бессерверной записной книжки перед завершением простоя. Когда вы вернётесь в ноутбук после разрыва связи в состоянии бездействия, в верхней части страницы появится баннер. Нажмите кнопку "Повторно подключиться", чтобы восстановить рабочее состояние.
При повторном подключении Databricks восстанавливает всю рабочую среду, в том числе:
- Переменные, функции и определения классов Python: Python-составляющая вашей записной книжки сохраняется, поэтому вам не нужно повторно импортировать или повторно объявлять.
- Кадры данных Spark, кэшированные и временные представления: данные, загруженные, преобразованные или кэшированные (включая временные представления), сохраняются, поэтому вы избегаете дорогостоящей перезагрузки или повторной компиляции.
- Состояние сеанса Spark: все параметры конфигурации уровня Spark, временные представления, изменения каталога и определяемые пользователем функции сохраняются, поэтому их не нужно сбрасывать.
Эта функция имеет ограничения и не поддерживает восстановление следующих компонентов:
- Состояния Spark старше 4 дней
- Состояния Spark размером более 50 МБ
- Данные, связанные со скриптами SQL
- Дескрипторы файлов
- Блокировки и другие примитивы параллелизма
- Сетевые подключения
Присоедините ноутбук к вычислительному ресурсу общего назначения
Чтобы подключить записную книжку к вычислительному ресурсу общего назначения, вам потребуется РАЗРЕШЕНИЕ CAN ATTACH TO на вычислительном ресурсе.
Внимание
Если записная книжка подключена к вычислительному ресурсу, любой пользователь с разрешением CAN RUN в записной книжке имеет неявное разрешение на доступ к вычислительному ресурсу.
Чтобы подключить записную книжку к вычислительному ресурсу, щелкните селектор вычислений на панели инструментов записной книжки и выберите ресурс в раскрывающемся меню.
В меню отображается выбор всех целевых вычислительных ресурсов и хранилищ SQL, которые вы использовали недавно или в настоящее время запущены.
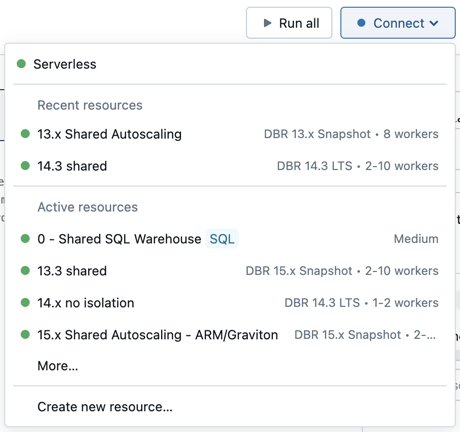
Чтобы выбрать все доступные вычислительные ресурсы, щелкните Дополнительно.... Выберите из доступных общих вычислительных ресурсов или хранилищ SQL.
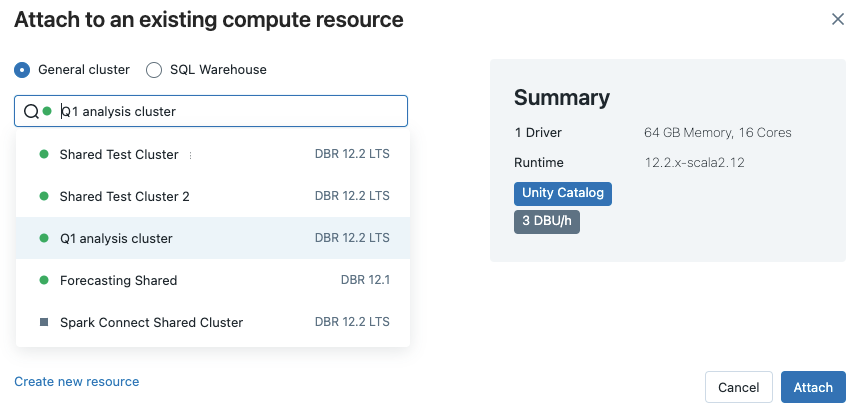
Вы также можете создать новый универсальный вычислительный ресурс, выбрав пункт Создать новый ресурс... в раскрывающемся меню.
Внимание
В подключенной записной книжке определены следующие переменные Apache Spark.
| Класс | Имя переменной |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Не создавайте SparkSession, SparkContext или SQLContext. Это приведет к несоответствующему поведению.
Использование записной книжки с хранилищем SQL
При присоединении записной книжки к хранилищу SQL можно запускать ячейки SQL и Markdown. При выполнении ячейки на любом другом языке (например, Python или R) возникает ошибка. Ячейки SQL, выполняемые в хранилище SQL, отображаются в журнале запросов хранилища SQL. Пользователь, который выполнил запрос, может просмотреть профиль запроса из записной книжки, щелкнув время в нижней части выходных данных.
Записные книжки, подключенные к хранилищам SQL, поддерживают сеансы хранилища SQL, которые позволяют определять переменные, создавать временные представления и сохранять состояние в нескольких запусках запросов. Это позволяет создавать логику SQL итеративно без необходимости одновременно выполнять все инструкции. Ознакомьтесь с разделом "Что такое сеансы хранилища SQL?".
Для запуска записной книжки требуется pro или бессерверное хранилище SQL. У вас должен быть доступ к рабочей области и хранилищу SQL.
Чтобы подключить записную книжку к хранилищу SQL, сделайте следующее:
Щелкните селектор вычислений на панели инструментов записной книжки. В раскрывающемся меню отображаются вычислительные ресурсы, которые в настоящее время запущены или которые недавно использовались. Хранилища SQL помечаются с
 помощью .
помощью .В меню выберите хранилище SQL.
Чтобы просмотреть все доступные хранилища SQL, выберите Больше… из раскрывающегося меню. Откроется диалоговое окно с доступными вычислительными ресурсами для записной книжки. Выберите хранилище SQL, выберите хранилище, которое вы хотите использовать, и щелкните Подключить.
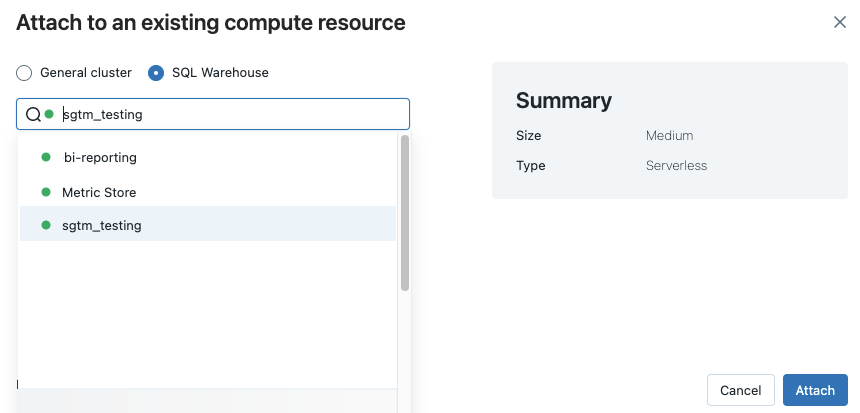
Вы также можете выбрать хранилище SQL в качестве вычислительного ресурса для записной книжки SQL при создании рабочего процесса или запланированного задания.
Ограничения хранилища SQL
Дополнительные сведения см. в известных ограничениях Databricks Notebook.