Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Автомасштабирование Lakebase — это последняя версия Lakebase с автомасштабированием вычислений, масштабированием до нуля, ветвлением и мгновенным восстановлением. Сведения о поддерживаемых регионах см. в разделе "Доступность регионов". Если вы являетесь пользователем Lakebase Provisioned, см. Lakebase Provisioned.
Высокая доступность связывает первичный вычислительный узел для чтения и записи с одним или несколькими вторичными вычислительными узлами, распределенными между зонами доступности. Когда первичный экземпляр становится недоступным, вторичный вычислительный экземпляр автоматически продвигается, и приложение продолжает выполнять последнюю зафиксированную транзакцию. Строка подключения остается неизменной.
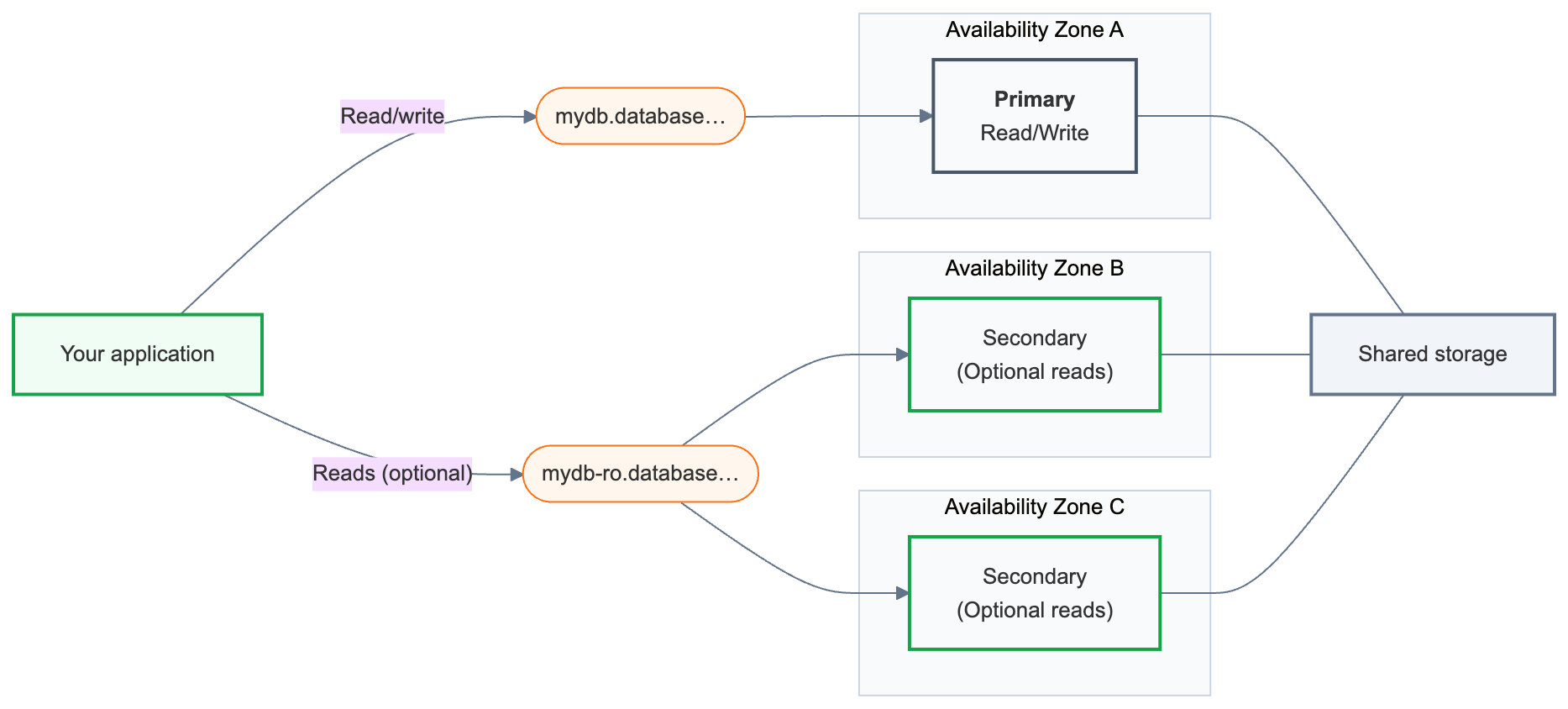
Принцип работы высокого уровня доступности
Конечная точка Lakebase — это адрес базы данных, к которому подключается приложение. Конечная точка высокой доступности предоставляет две строки подключения:
-
Основное (
{endpoint-id}.database.{region}.databricks.com) — основное подключение для чтения и записи. Используйте это в каждом приложении, которое подключается к базе данных. После отработки отказа система автоматически перенаправляет на новый основной вычислительный ресурс. -
Вторичная (
{endpoint-id}-ro.database.{region}.databricks.com) — доступна только в том случае, если разрешен доступ к вычислительным экземплярам только для чтения . Вторичные вычислительные экземпляры существуют в первую очередь как резервные экземпляры для отработки отказа; предоставление доступа на чтение позволяет дополнительно распределять запросы на чтение между ними.
Обе строки подключения доступны в диалоговом окне "Подключение " в конечной точке.
За этими строками подключения конечная точка высокой доступности всегда имеет ровно один первичный вычислительный экземпляр и один до трех вторичных вычислительных экземпляров. Основной обрабатывает весь трафик чтения и записи. Вторичные экземпляры вычислений работают в разных зонах доступности и становятся основными в случае сбоя.
Каждый вторичный вычислительный экземпляр имеет параметр Access , определяющий, обслуживает ли он также трафик чтения:
| Вторичный доступ | Что это делает |
|---|---|
| только для чтения | Вторичный вычислительный экземпляр используется для чтения через -ro строку подключения и может быть переведен в статус основного экземпляра по мере необходимости |
| Отключен | Вторичный вычислительный экземпляр активен и готов к переходу на резервный узел, но не обслуживает запросы на чтение. |
Вы управляете этим с помощью параметра "Разрешить доступ к экземплярам вычислений с доступом только для чтения" на конечной точке, к которой можно получить доступ через панель "Редактировать вычисления." При включении все вторичные вычислительные экземпляры обрабатывают запросы на чтение; при отключении они находятся в режиме ожидания для переключения при сбое. В обоих случаях вычислительное оборудование уже выделено и работает: промоция не требует новой подготовки, поэтому резервная емкость на случай отказа зарезервирована независимо от спроса в зоне доступности.
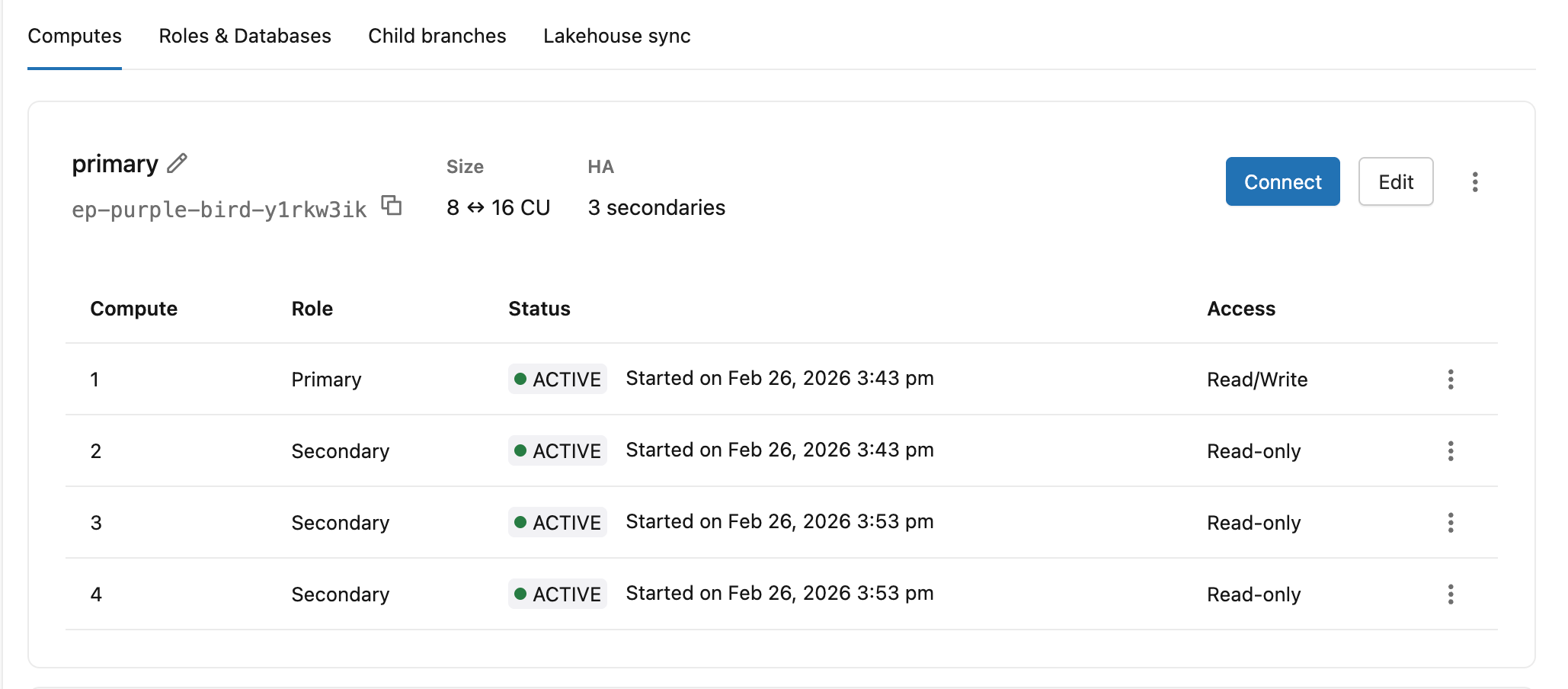
На вкладке "Вычисления" показана роль каждого вычислительного экземпляра (первичная или вторичная), уровень состояния и доступа .
Распределение AZ
Lakebase распределяет первичные и вторичные вычислительные экземпляры между зонами доступности, что снижает риск того, что один сбой AZ влияет как на первичный, так и на все вторичные вычислительные экземпляры.
Автомасштабирование в высокой доступности
Все вычислительные экземпляры в конфигурации высокой доступности используют одинаковый диапазон автомасштабирования. Максимальная разница между минимальным и максимальным CU составляет 16 CU, как и ограничение для автономных вычислительных экземпляров.
Вторичные вычислительные экземпляры всегда масштабируются не менее чем до размера вычислительных единиц (CU) основного экземпляра, обеспечивая согласованность емкости базы данных после переключения при отказе.
Масштабирование до нуля недоступно для вычислительных экземпляров в конфигурации высокой доступности. Вы можете вручную приостановить все вычислительные экземпляры, но конечная точка будет недоступна во время приостановки.
Вторичные вычислительные экземпляры по сравнению с автономными репликами чтения
Вторичные вычислительные ресурсы и автономные реплики баз данных для чтения — это разные функции, которые могут сосуществовать на одной ветви.
| Второстепенные вычислительные экземпляры | Автономные реплики данных | |
|---|---|---|
| Purpose | Автоматическое переключение при отказе + перенос чтения по запросу | Только чтение разгрузки |
| Добавлено через | Настройка высокого уровня доступности | Добавить Read Replica |
| Участвует в переключении при отказе | Да | Нет |
| Строка соединения |
-ro на основной конечной точке |
Собственная отдельная конечная точка |
| Размеры | Совместное использование с главным (уровень конечной точки) | Размер определяется независимо |
Если требуется как высокий уровень доступности, так и дополнительная производительность чтения помимо возможностей вторичных вычислительных экземпляров, можно объединить обе функции в одной ветви. См. реплики чтения.
Поведение отработки отказа
автоматическое переключение при отказе
Lakebase постоянно отслеживает работоспособность первичных вычислений. Если основной узел становится недоступным, переключение при отказе активируется автоматически.
Резервирование сохраняет все зафиксированные транзакции.
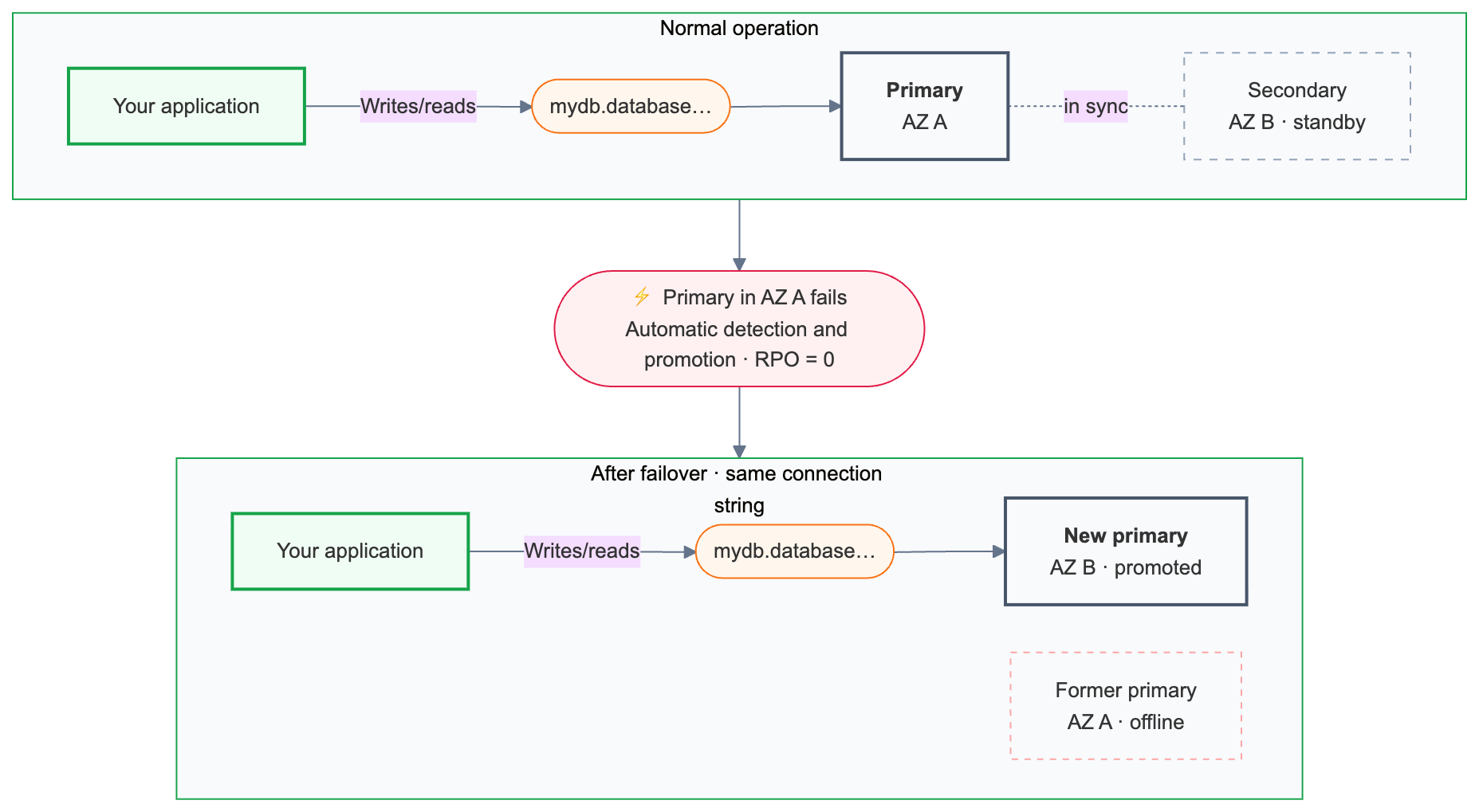
После отработки отказа основная строка подключения ({endpoint-id}.database.{region}.databricks.com) автоматически направляется в вновь созданный вычислительный экземпляр. Приложения не должны изменять конфигурацию подключения, но существующие подключения завершаются во время переключения и должны выполнить повторное подключение. Приложения с логикой повторных попыток обрабатывают это автоматически.
Отработка отказа с включенным доступом только для чтения
Если включена функция разрешить доступ к экземплярам вычислений только для чтения и происходит отработка отказа, то повышенный вторичный экземпляр становится новым основным и перестает выполнять чтение. Если у вас есть два или более доступных для чтения вторичных файлов, трафик чтения в строке -ro подключения продолжается в сниженной емкости до тех пор, пока не будет подготовлена замена. Если у вас есть только один, чтение будет полностью прервано до тех пор, пока замена не будет готова.
Строки подключения
В диалоговом окне "Подключение" отображаются обе строки подключения с текущим состоянием вычислений:
| Опция вычислений в диалоговом окне "Подключение" | Строка соединения | Используется для |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
Все записи; операции чтения, которые должны попасть в текущий основной узел |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
Считывать разгрузку на вторичные вычислительные экземпляры (доступно только в том случае, если разрешен доступ к вычислительным экземплярам только для чтения ) |
Основная строка подключения всегда ведет к текущему основному узлу, даже после переключения после сбоя.
Каждый вычислительный экземпляр также имеет собственную строку прямого подключения, доступную на вкладке "Вычисления " через меню действий (⋮) для каждой строки. Прямые подключения предназначены для устранения неполадок отдельных вычислительных экземпляров, а не для использования приложения. Строки прямого подключения относятся к отдельным вычислительным операциям и могут изменяться при добавлении, удалении или переходе вторичных файлов в основное состояние.
Ограничения высокого уровня доступности
| Ограничение | Ценность |
|---|---|
| Вычислительные операции | 2, 3 или 4 (1 первичный + 1–3 вторичных вычислительных экземпляров) |
| Диапазон автомасштабирования (максимум – мин) | ≤ 16 CU между минимальным и максимальным |
| Сведение к нулю | Недоступно для вычислительных экземпляров в конфигурации высокой доступности |
Лучшие практики
Следующие практики помогают приложению оставаться устойчивым и доступным во время событий аварийных переключений.
| Практика | Сведения |
|---|---|
| Реализация логики повторных попыток подключения | Активные подключения завершаются во время переключения на резервный канал. Подключения к неисправному основному источнику могут зависать до истечения времени ожидания— настройте время ожидания TCP или время ожидания подключения в драйвере, чтобы быстро обнаружить сбой. Подключения к дополнительному повышению активно завершаются, возвращая ошибку немедленно. Приложения с логикой повторных попыток повторно подключались автоматически в течение нескольких секунд. |
| Настройка вторичного счетчика для варианта использования | Каждый вторичный вычислительный экземпляр представляет собой предварительно выделенные аппаратные ресурсы, зарезервированные для отказоустойчивости. Сокращение количества вторичных экземпляров означает уменьшение мощностей для отработки отказов и меньше покрытых зон доступности. Один вторичный вычислительный экземпляр обеспечивает резервирование. Если включить доступные для чтения вторичные файлы, настройте два или более. При наличии только одного, операции чтения полностью прерываются во время переключения на резерв до тех пор, пока замена не будет завершена. |
| Избегайте перегрузки вторичных вычислительных экземпляров | Служба может перезапустить вторичный вычислительный экземпляр, перегруженный или отстающий. Отслеживайте количество запросов и количество подключений, а также увеличьте размер cu, если наблюдается высокая загрузка. |
Дальнейшие действия
- Управление высоким уровнем доступности для включения и настройки высокой доступности
- Автомасштабирование для подробных сведений о размерах и диапазонах автомасштабирования CU
- Строки подключения для полной ссылки на строку подключения