Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Автомасштабирование Lakebase находится в бета-версии в следующих регионах: eastus2westeuropewestus.
Автомасштабирование Lakebase — это последняя версия Lakebase с автомасштабированием вычислений, масштабированием до нуля, ветвлением и мгновенным восстановлением. Сравнение функций с Lakebase Provisioned см. в разделе выбора между версиями.
Проект — это контейнер верхнего уровня для ресурсов Lakebase, включая ветви, вычислительные ресурсы, базы данных и роли. На этой странице объясняется, как создавать проекты, понимать их структуру, настраивать параметры и управлять их жизненным циклом.
Если вы не знакомы с Lakebase, начните с начала создания первого проекта.
Общие сведения о проектах
Структура проекта
Понимание структуры проекта Lakebase помогает эффективно упорядочивать ресурсы и управлять ими. Проект — это контейнер верхнего уровня для баз данных, ветвей, вычислений и связанных ресурсов. Каждый проект включает параметры для вычислений по умолчанию, восстановления окон и обновлений, которые применяются ко всем ветвям проекта.
На верхнем уровне проект содержит одну или несколько ветвей. В рамках проекта можно создавать ветви для различных сред, таких как разработка, тестирование, промежуточное развертывание и рабочая среда. Каждая ветвь содержит собственные вычислительные ресурсы, роли и базы данных.
Project
└── Branches (main, development, staging, etc.)
├── Computes (R/W compute)
├── Roles (Postgres roles)
└── Databases (Postgres databases)
Ветви
Данные находятся в ветвях. Каждый проект Lakebase создается с корневой ветвью под названием production, которая не может быть удалена. Хотя вы можете создать дополнительные ветви и назначить другую ветвь в качестве ветви по умолчанию, корневая ветвь не может быть удалена.
Дочерние ветви можно создавать из любой ветви проекта. При создании дочерней ветви она наследует все базы данных, роли и данные из родительской ветви на момент создания. Последующие изменения в родительской ветви не автоматически распространяются в дочернюю ветвь, обеспечивая изолированную разработку, тестирование или экспериментирование.
Каждая ветвь может содержать несколько баз данных и ролей. Дополнительные сведения: управление ветвями
Вычисляет
Вычисление — это виртуализированный вычислительный ресурс, включающий виртуальный ЦП и память для запуска Postgres. При создании проекта для ветви по умолчанию проекта создается основное вычисление R/W (чтение и запись). Каждая ветвь имеет один первичный вычислительный узел R/W. Чтобы подключиться к базе данных, размещенной в ветви, необходимо подключиться через вычислительные ресурсы R/W, связанные с ветвью.
Помимо основного вычислительного узла R/W, вы можете добавить один или несколько вычислительных узлов с репликами только для чтения в любой узел. Реплики чтения позволяют переносить нагрузки на чтение с главного вычислительного ресурса для таких вариантов использования, как горизонтальное масштабирование операций чтения, аналитика и запросы для отчетности, а также доступ только для чтения для пользователей или приложений. Дополнительные сведения. Управление вычислениями, чтение реплик
Роли
Роли — это роли Postgres. Роль является необходимой для создания и доступа к базе данных. Роль принадлежит ветви. При создании проекта роль Postgres автоматически создается для удостоверения Databricks (например, user@databricks.com), и эта роль является владельцем базы данных по умолчанию databricks_postgres. Любая роль, созданная в пользовательском интерфейсе Lakebase, создается с databricks_superuser привилегиями. Существует ограничение в 500 ролей на ветвь. Дополнительные сведения: управление ролями
Баз данных
База данных — это контейнер для объектов SQL, таких как схемы, таблицы, представления, функции и индексы. В Lakebase база данных принадлежит ветви. Ветвь по умолчанию вашего проекта создается с базой данных, названной databricks_postgres. Существует ограничение в 500 баз данных на ветвь. Дополнительные сведения: управление базами данных
Схемы
Все базы данных в Lakebase создаются со схемой public , которая является поведением по умолчанию для любого стандартного экземпляра Postgres. Объекты SQL создаются в схеме public по умолчанию.
Ограничения проекта
Lakebase Postgres применяет следующие ограничения для проектов:
| Resource | Лимит |
|---|---|
| Максимальное число одновременных активных вычислений | 20 |
| Максимальное количество ветвей на проект | 500 |
| Максимальное количество ролей Postgres на ветвь | 500 |
| Максимальное количество баз данных Postgres на ветвь | 500 |
| Максимальный размер логических данных на ветвь | 8 ТБ |
| Максимальное количество проектов на рабочую область | 1000 |
| Максимальное число защищенных ветвей | 1 |
| Максимальное число корневых ветвей | 3 |
| Максимальное число неархивированных ветвей | 10 |
| Максимальное количество моментальных снимков | 10 |
| Максимальный период хранения истории | 35 дней |
| Минимальный масштаб до нулевого времени | 60 секунд |
Параллельно активное ограничение вычислений
Одновременно активный предел вычислительных ресурсов ограничивает количество вычислений, которые могут выполняться одновременно, чтобы предотвратить исчерпание ресурсов. Это ограничение защищает от случайных всплесков ресурсов, таких как запуск нескольких вычислительных конечных точек одновременно. Ограничение по умолчанию — 20 одновременных активных вычислений на каждый проект.
Важно: Ветвь по умолчанию освобождается от этого ограничения, обеспечивая доступность в любое время.
При превышении предела дополнительные вычисления, превышающие предел, остаются приостановленными, и при попытке подключения к ним возникает ошибка. Чтобы устранить эту проблему:
- Приостанавливайте другие активные вычисления и повторите попытку.
- Если эта ошибка возникает часто, обратитесь в службу поддержки Databricks, чтобы запросить увеличение ограничения.
Замечание
Вычисления с включенной поддержкой масштабирования до нуля автоматически приостанавливаются после периода бездействия, помогая оставаться в пределах ограничения на количество одновременно активных вычислений.
Доступность
Доступность облака и региона
Автомасштабирование в Lakebase Postgres доступно в AWS и Azure.
Регионы AWS:
-
us-east-1(Восточная часть США - Штат Вирджиния) -
us-east-2(Восточная часть США - Огайо) -
eu-central-1(Европа - Франкфурт) -
eu-west-1(Европа - Ирландия) -
eu-west-2(Европа - Лондон) -
ap-south-1(Азиатско-Тихоокеанский регион — Мумбаи) -
ap-southeast-1(Азиатско-Тихоокеанский регион — Сингапур) -
ap-southeast-2(Азиатско-Тихоокеанский регион — Сидней)
Регионы Azure (бета-версия):
-
eastus2(Восток США 2) -
westeurope(Западная Европа) -
westus(Западная часть США)
Проект Lakebase создается в вашем регионе рабочей области Databricks.
Поддержка версий Postgres
Автомасштабирование Lakebase Postgres поддерживает Postgres 16 и Postgres 17.
Создание проектов и управление ими
Создание проекта
Вы можете создать несколько проектов в Lakebase Postgres для обеспечения полной изоляции приложений или клиентов, обеспечивая чистое разделение данных и ресурсов.
Чтобы создать проект, выполните приведенные далее действия.
Пользовательский интерфейс
- Щелкните переключатель приложений в правом верхнем углу, чтобы открыть приложение Lakebase.
- Щелкните Создать проект.
- Настройте параметры проекта:
-
Имя проекта: введите описательное имя проекта. Распространенные шаблоны именования включают именование после приложения (например,
my-analytics-app) или клиента, обслуживаемого проектом (например,acme-corp-db). - Версия Postgres: выберите версию Postgres, которую вы хотите использовать.
-
Имя проекта: введите описательное имя проекта. Распространенные шаблоны именования включают именование после приложения (например,
В диалоговом окне "Создание проекта " показаны параметры конфигурации проекта.
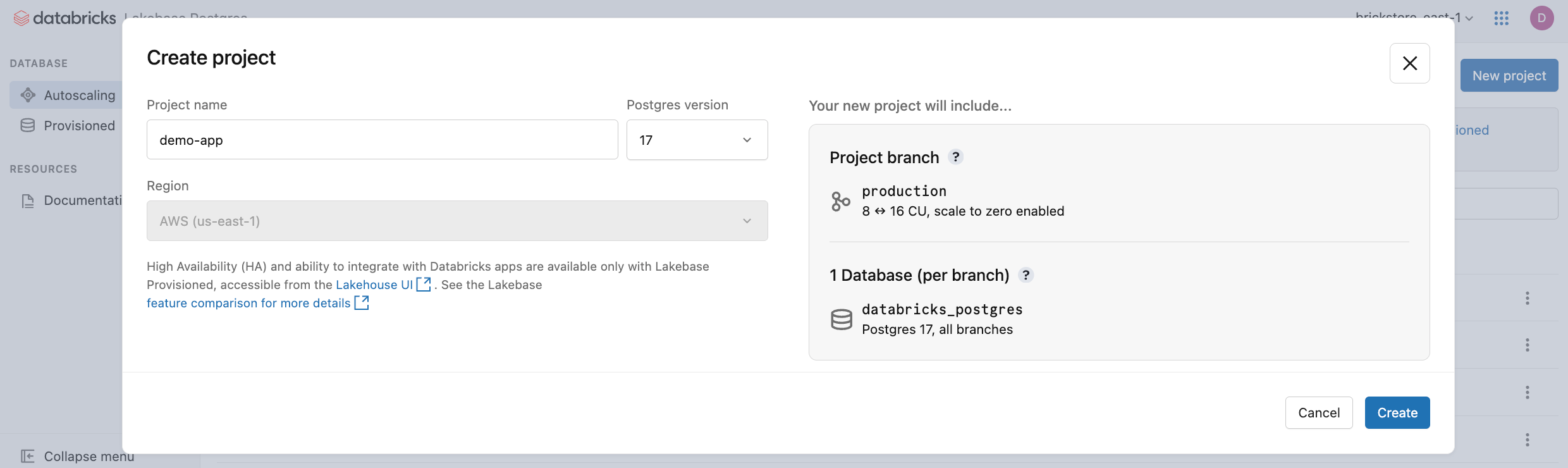
Регион для проекта Lakebase установлен в регион рабочей области Databricks и не может быть изменен.
Пакет SDK для Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec
# Initialize the Workspace client
w = WorkspaceClient()
# Create a project with a custom project ID
operation = w.postgres.create_project(
project=Project(
spec=ProjectSpec(
display_name="My Application",
pg_version="17"
)
),
project_id="my-app"
)
# Wait for operation to complete
result = operation.wait()
print(f"Created project: {result.name}")
print(f"Display name: {result.status.display_name}")
print(f"Postgres version: {result.status.pg_version}")
пакет SDK для Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
// Initialize the Workspace client
WorkspaceClient w = new WorkspaceClient();
// Create a project with a custom project ID
CreateProjectOperation operation = w.postgres().createProject(
new CreateProjectRequest()
.setProjectId("my-app")
.setProject(new Project()
.setSpec(new ProjectSpec()
.setDisplayName("My Application")
.setPgVersion(17L)))
);
// Wait for operation to complete
Project result = operation.waitForCompletion();
System.out.println("Created project: " + result.getName());
System.out.println("Display name: " + result.getStatus().getDisplayName());
System.out.println("Postgres version: " + result.getStatus().getPgVersion());
интерфейс командной строки (CLI)
# Create a project with a custom project ID
databricks postgres create-project \
--project-id my-app \
--json '{
"spec": {
"display_name": "My Application",
"pg_version": "17"
}
}'
завиток
Создайте проект с пользовательским идентификатором проекта. Указывается project_id в качестве параметра запроса и становится частью имени ресурса проекта (например, projects/my-app).
curl -X POST "$WORKSPACE/api/2.0/postgres/projects?project_id=my-app" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Application",
"pg_version": "17"
}
}' | jq
Это длительная операция. Ответ содержит имя операции, которое можно использовать для проверки состояния. Операция обычно завершается в течение нескольких секунд.
Параметр project_id является обязательным.
Новый проект включает следующие ресурсы по умолчанию:
productionОдна ветвь (ветвь по умолчанию)Одно основное вычисление для чтения и записи, связанное с ветвью со следующими параметрами по умолчанию:
Branch Единицы вычислений (CU) RAM Autoscaling Масштабирование до нуля production8 – 32 CU 16 – 64 ГБ Enabled Disabled При создании проекта
productionветвь создается с вычислительными ресурсами, у которых по умолчанию отключено масштабирование до нуля, то есть вычислительные ресурсы остаются активными все время. При необходимости можно включить масштабирование до нуля для этого вычисления.База данных Postgres (с именем
databricks_postgres)Роль Postgres для идентичности Databricks (например,
user@databricks.com)
Сведения об изменении параметров вычислений для существующего проекта см. в разделе "Настройка параметров проекта". Сведения об изменении параметров вычислений по умолчанию для новых проектов см. в разделе " Вычисления по умолчанию " в разделе "Настройка параметров проекта".
Получение сведений о проекте
Получение сведений для конкретного проекта.
Пользовательский интерфейс
- Щелкните переключатель приложений в правом верхнем углу, чтобы открыть приложение Lakebase.
- Выберите проект из списка проектов, чтобы просмотреть его сведения.
Пакет SDK для Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get project details
project = w.postgres.get_project(name="projects/my-project")
print(f"Project: {project.name}")
print(f"Display name: {project.status.display_name}")
print(f"Postgres version: {project.status.pg_version}")
пакет SDK для Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Project;
WorkspaceClient w = new WorkspaceClient();
// Get project details
Project project = w.postgres().getProject("projects/my-project");
System.out.println("Project: " + project.getName());
System.out.println("Display name: " + project.getStatus().getDisplayName());
System.out.println("Postgres version: " + project.getStatus().getPgVersion());
интерфейс командной строки (CLI)
# Get project details
databricks postgres get-project projects/my-project
завиток
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Ответ включает:
-
name: имя ресурса (projects/my-project) -
status: конфигурация проекта и текущее состояние (display_name, pg_version, состояние и т. д.)
Примечание. Поле spec не заполняется для GET операций. Все свойства ресурса возвращаются в status поле.
Список проектов
Список всех проектов в вашей рабочей области.
Пользовательский интерфейс
- Щелкните переключатель приложений в правом верхнем углу, чтобы открыть приложение Lakebase.
- В списке проектов отображаются все проекты, к которых у вас есть доступ.
Пакет SDK для Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all projects
projects = w.postgres.list_projects()
for project in projects:
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
print(f" Postgres version: {project.status.pg_version}")
пакет SDK для Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all projects
for (Project project : w.postgres().listProjects(new ListProjectsRequest())) {
System.out.println("Project: " + project.getName());
System.out.println(" Display name: " + project.getStatus().getDisplayName());
System.out.println(" Postgres version: " + project.getStatus().getPgVersion());
}
интерфейс командной строки (CLI)
# List all projects
databricks postgres list-projects
завиток
curl -X GET "$WORKSPACE/api/2.0/postgres/projects" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Формат ответа:
{
"projects": [
{
"name": "projects/my-project",
"status": {
"display_name": "My Project",
"pg_version": "17",
"state": "READY"
}
}
]
}
Настройка параметров проекта
После создания проекта можно изменить различные параметры на панели мониторинга проекта, перейдя к параметрам:
Общие параметры
Имя проекта можно обновить. Не удается изменить идентификатор проекта.
Пользовательский интерфейс
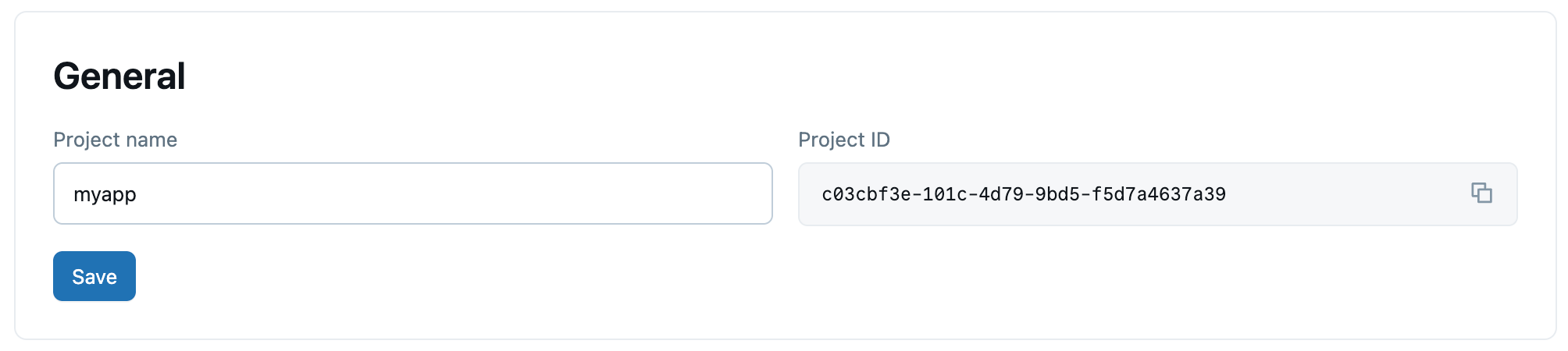
интерфейс командной строки (CLI)
# Update project display name
databricks postgres update-project projects/my-project spec.display_name \
--json '{
"spec": {
"display_name": "My Updated Project Name"
}
}'
завиток
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.display_name" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Updated Project Name"
}
}' | jq
Это длительная операция. Ответ содержит имя операции, которое можно использовать для проверки состояния.
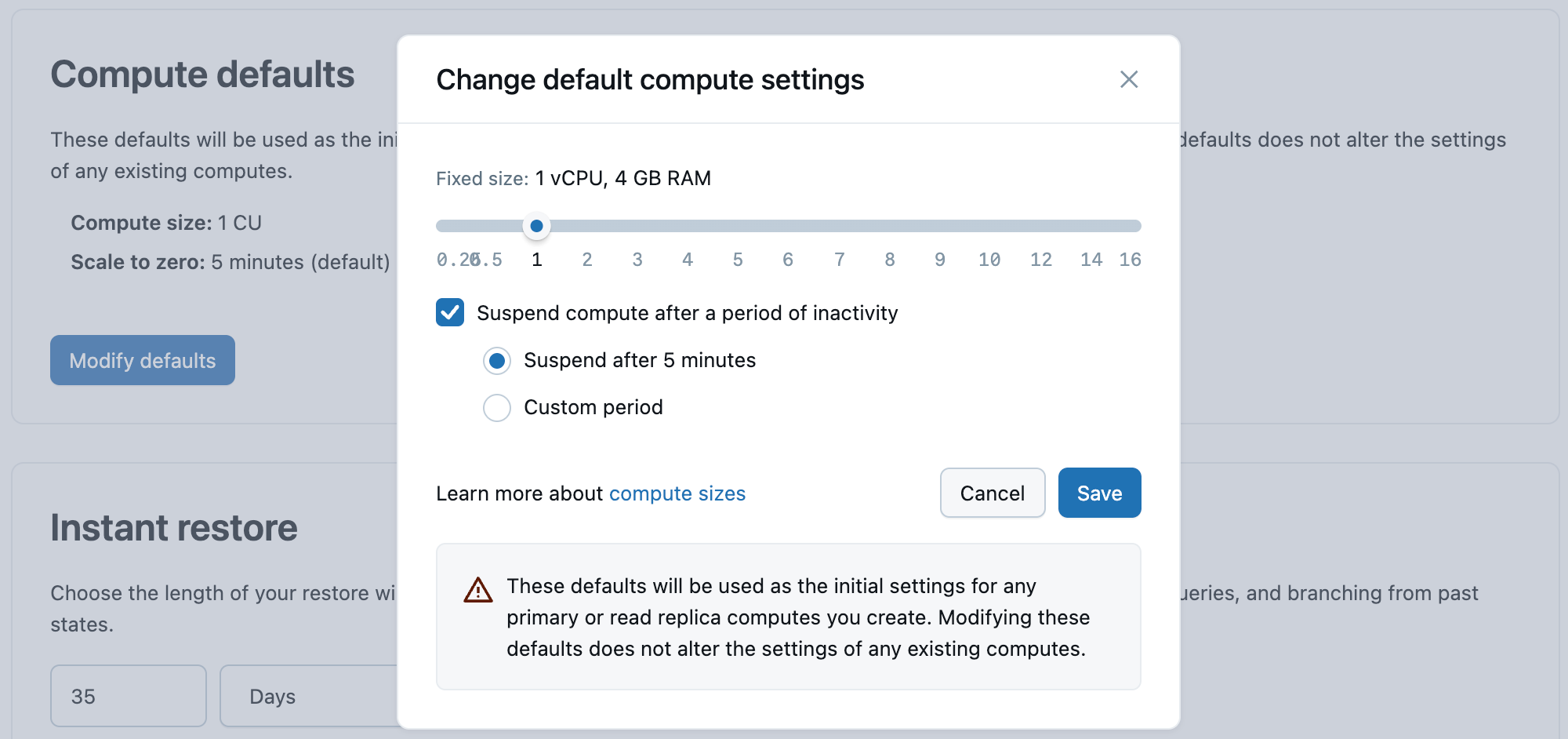
Настройки по умолчанию для вычислений
Задайте начальные параметры для основных вычислений, в том числе:
- Размер вычислительных ресурсов (измеряется в единицах вычислений)
- Масштабирование до нуля времени ожидания (по умолчанию — 5 минут)
Эти параметры используются при создании новых первичных вычислений.
Замечание
Сведения об изменении параметров для существующих вычислений см. в разделе "Управление вычислениями".
Lakebase Postgres поддерживает размеры вычислительных ресурсов с 0,5 CU до 112 CU. Автомасштабирование доступно для вычислительных мощностей до 32 CU (0,5, а затем с целочисленными приростами: 1, 2, 3... 16, затем 24, 28, 32). Более крупные вычисления фиксированного размера доступны от 36 CU до 112 CU (36, 40, 44, 48, 52, 56, 60, 64, 72, 80, 88, 96, 104, 112). Каждая единица вычислений (CU) предоставляет 2 ГБ ОЗУ.
Замечание
Lakebase Provisioned vs Autoscaling: в Lakebase Provisioned каждая единица вычислений выделяет около 16 ГБ ОЗУ. В Автомасштабировании Lakebase каждая единица вычислений выделяет 2 ГБ ОЗУ. Это изменение обеспечивает более детализированные параметры масштабирования и управление затратами.
Репрезентативные размеры:
| Единицы вычислений | RAM |
|---|---|
| 0.5 CU | 1 ГБ |
| 1 единица емкости | 2 ГБ |
| 4 CU | 8 ГБ |
| 16 вычислительных единиц (CU) | 32 Гб |
| 32 вычислительных блока (CU) | 64 ГБ |
| 64 вычислительных единицы | 128 ГБ |
| 112 CU | 224 ГБ |
- Чтобы включить автомасштабирование, задайте диапазон размера вычислений с помощью ползунка. Автоматическое масштабирование динамически настраивает вычислительные ресурсы на основе спроса на рабочую нагрузку. Дополнительные сведения: автомасштабирование
- Настройте параметр масштабирования до нуля, чтобы увеличить или уменьшить объем неактивного времени вычислений до приостановки вычислений. Вы также можете отключить масштабирование до нуля для всегда активного вычисления. Дополнительные сведения: масштабирование до нуля
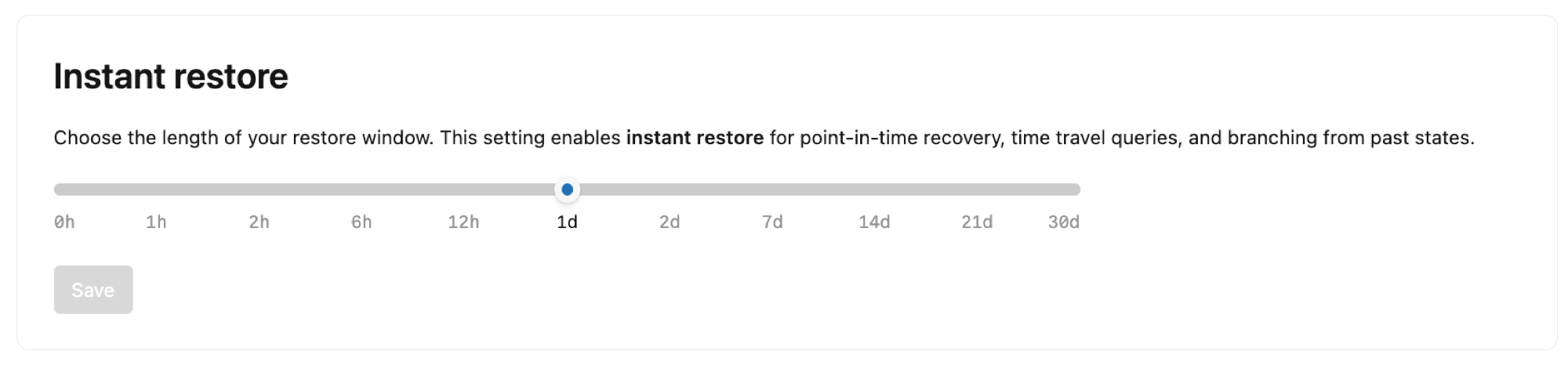
Мгновенное восстановление
Настройте длину окна восстановления для проекта. По умолчанию Lakebase сохраняет журнал изменений для корневых ветвей в проекте, что позволяет восстановить потерянные данные на определенный момент времени, запрашивать данные в определенный момент времени для изучения проблем с данными и ветвления из прошлых состояний для рабочих процессов разработки.
Окно восстановления можно задать от 2 дней до 35 дней. Обратите внимание, что:
- Расширение окна восстановления увеличивает объем хранилища
- Параметр окна восстановления влияет на все ветви проекта
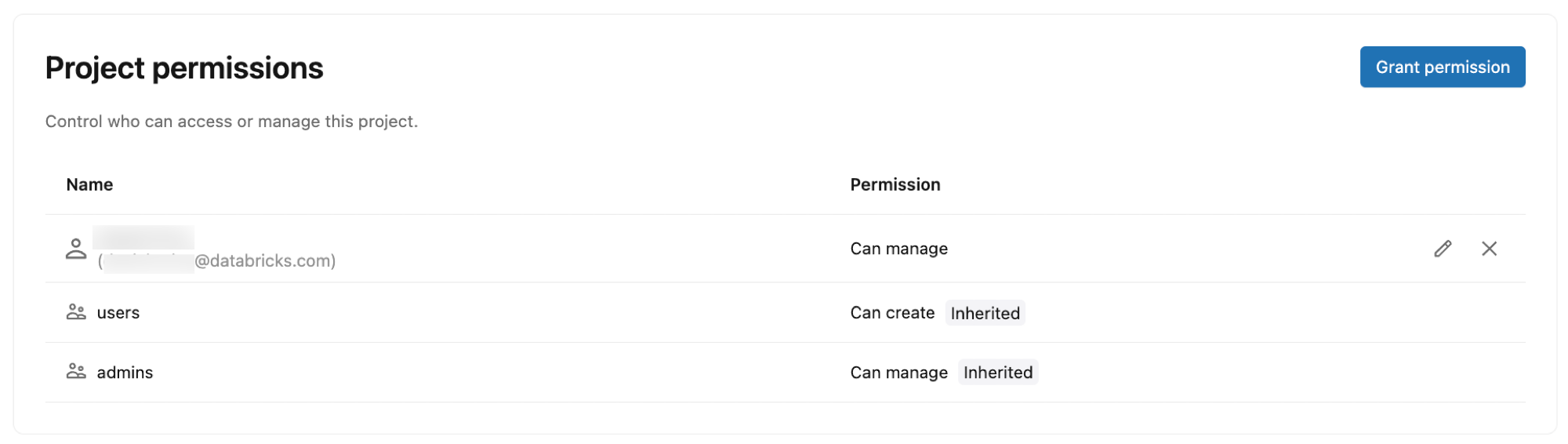
Разрешения проекта
Управляйте доступом к проекту Lakebase и контролируйте его, предоставляя разрешения идентификаторам, группам и служебным учетным записям Azure Databricks. Разрешения проекта определяют, какие действия пользователи могут выполнять в проекте, например создание ветвей, управление вычислениями и просмотр сведений о подключении.
Типы разрешений:
- CAN CREATE: Просмотр и создание ресурсов проекта
- CAN USE: использование и просмотр ресурсов проекта (список, просмотр, подключение и выполнение определенных операций с ветками) без создания или удаления проектов или веток
- CAN MANAGE: Полный контроль над конфигурацией и ресурсами проекта
Разрешения по умолчанию:
При создании проекта автоматически назначаются следующие разрешения:
- Владелец проекта (пользователь, создавший проект): CAN MANAGE (полный контроль)
- Пользователи рабочей области: CAN CREATE (может просматривать и создавать проекты)
- Администраторы рабочей области: CAN MANAGE (полный контроль)
Чтобы предоставить доступ другим пользователям, см. статью "Управление разрешениями проекта".
Замечание
Разрешения проекта и доступ к базе данных разделены
Разрешения проекта управляют действиями платформы Lakebase, а доступ к базе данных контролируется ролями Postgres и связанными с ними разрешениями. См. статью "Создание ролей Postgres " и "Управление разрешениями базы данных".
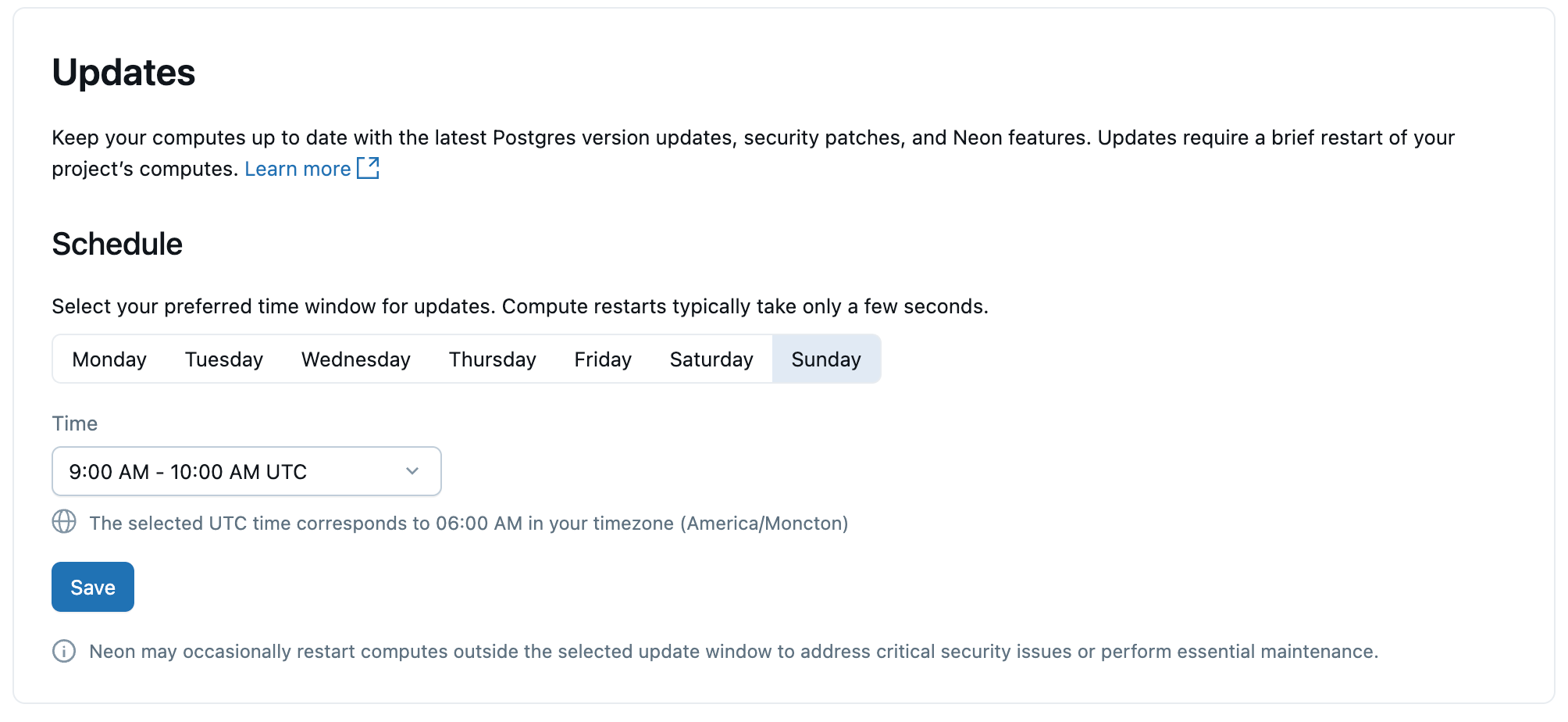
Обновления
Чтобы обеспечить актуальность вычислительных ресурсов Lakebase и экземпляров Postgres, Lakebase автоматически применяет запланированные обновления, в том числе дополнительных обновлений, исправлений для системы безопасности и функций платформы Postgres. Обновления применяются к вычислениям в проекте и требуют краткого перезапуска вычислений, который занимает несколько секунд.
Обновления применяются автоматически, но вы можете задать предпочтительный день и время обновления. Перезапуск происходит в течение выбранного периода времени.
Подробные сведения об обновлениях см. в разделе "Управление обновлениями".
Удаление проекта
Удаление проекта — это постоянное действие, которое также удаляет все вычислительные ресурсы, ветви, базы данных, роли и данные, принадлежащие проекту.
Это важно
Это действие не может быть отменено. Будьте осторожны при удалении проекта, так как это удаляет все связанные ветви и данные.
Перед удалением
Databricks рекомендует удалить все связанные каталоги каталогов Unity и синхронизированные таблицы перед удалением проекта. В противном случае попытка просмотреть каталоги или запустить запросы SQL, ссылающиеся на них, приводят к ошибкам.
Если вы не являетесь владельцем таблиц или каталогов, перед удалением необходимо переназначить их владение на себя.
Замечание
В Lakebase Autoscaling любой идентификатор Databricks с доступом к рабочей области, в которой был создан проект, может удалять проекты.
Удаление проекта
Удаление проекта:
Пользовательский интерфейс
- Перейдите к параметрам проекта в приложении Lakebase.
- В разделе "Удалить проект " нажмите кнопку "Удалить " и введите имя проекта, чтобы подтвердить удаление.
Пакет SDK для Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete a project
operation = w.postgres.delete_project(name="projects/my-project")
print(f"Delete operation started: {operation.name}")
Это длительная операция. Проект и все его ресурсы (ветви, конечные точки, базы данных, роли, данные) будут удалены.
пакет SDK для Java
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete a project
w.postgres().deleteProject("projects/my-project");
System.out.println("Delete operation started");
Это длительная операция. Проект и все его ресурсы (ветви, конечные точки, базы данных, роли, данные) будут удалены.
интерфейс командной строки (CLI)
# Delete a project
databricks postgres delete-project projects/my-project
Эта команда выполняется немедленно. Проект и все его ресурсы будут удалены.
завиток
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Это длительная операция. Ответ содержит имя операции, которое можно использовать для проверки состояния удаления.