Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Автомасштабирование Lakebase находится в бета-версии в следующих регионах: eastus2, westeurope, westus.
Автомасштабирование Lakebase — это последняя версия Lakebase с автомасштабированием вычислений, масштабированием до нуля, ветвлением и мгновенным восстановлением. Сравнение функций с Lakebase Provisioned см. в разделе выбора между версиями.
Начните работать с Lakebase Postgres за считанные минуты. Создайте первый проект, подключитесь к базе данных и изучите ключевые функции, включая интеграцию каталога Unity.
Создание первого проекта
Откройте приложение Lakebase из переключателя приложений.
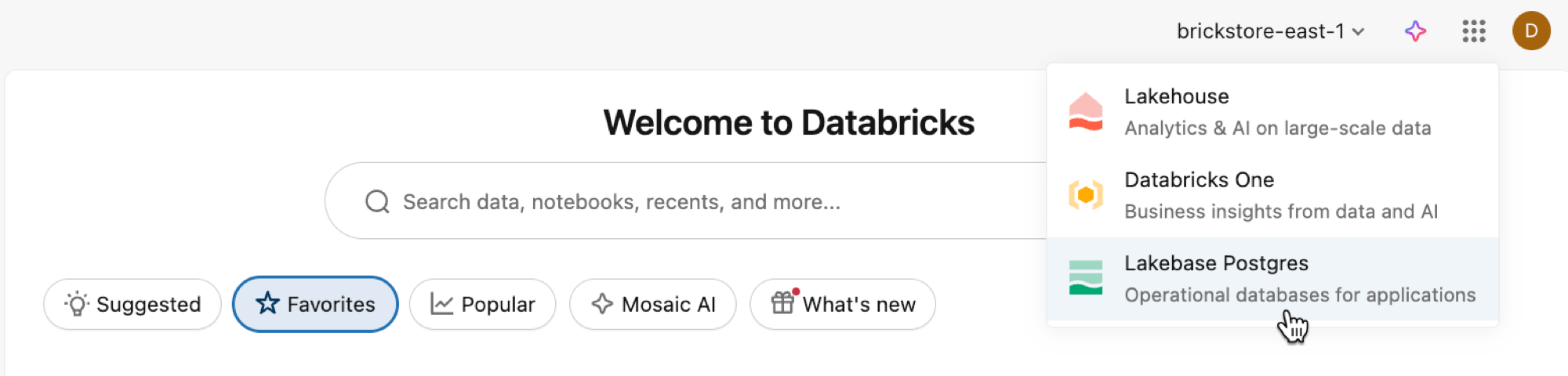
Выберите автомасштабирование , чтобы получить доступ к пользовательскому интерфейсу Автомасштабирования Lakebase.
Щелкните Создать проект. Присвойте проекту имя и выберите версию Postgres. Проект создается с одной production ветвью, базой данных по умолчанию databricks_postgres и вычислительными ресурсами, настроенными для ветви.
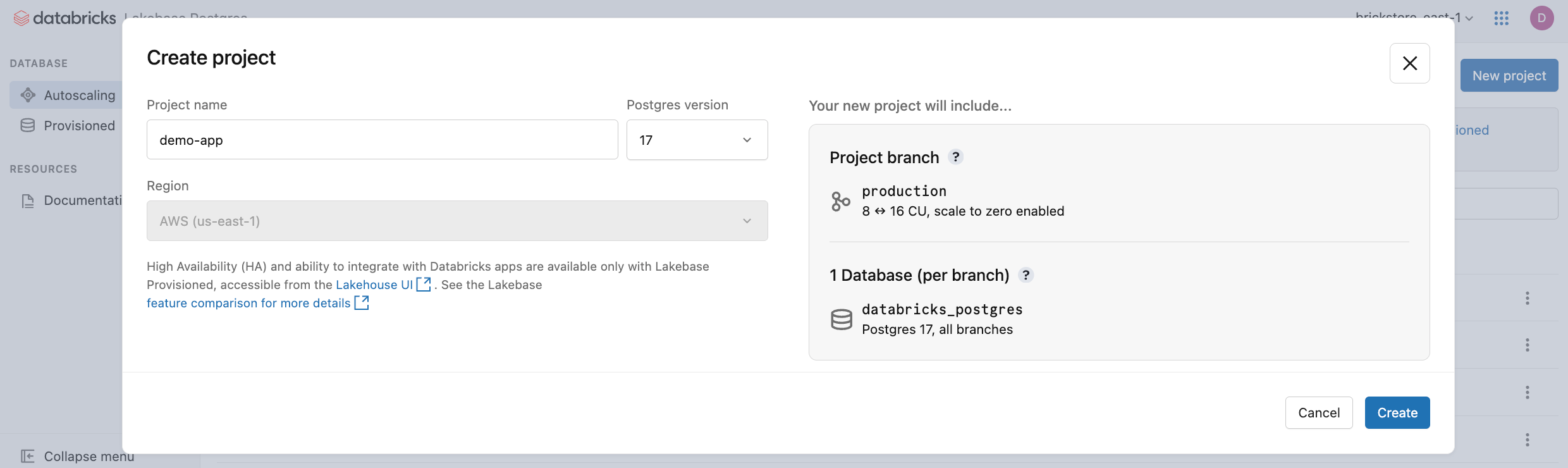
Для активации вычислительных ресурсов может потребоваться несколько монентов. Вычисления для production ветви всегда подключены по умолчанию (масштабирование к нулю отключено), но при необходимости этот параметр можно настроить.
Регион проекта автоматически устанавливается в регион рабочей области. Подробные параметры конфигурации см. в разделе "Создание проекта".
Подключение к базе данных
В проекте выберите рабочую ветвь и нажмите кнопку "Подключить". Вы можете подключиться, используя идентификацию Databricks с аутентификацией по OAuth, или создать встроенную роль пароля Postgres. Строки подключения работают со стандартными клиентами Postgres, такими как psqlpgAdmin или любым средством, совместимым с Postgres.
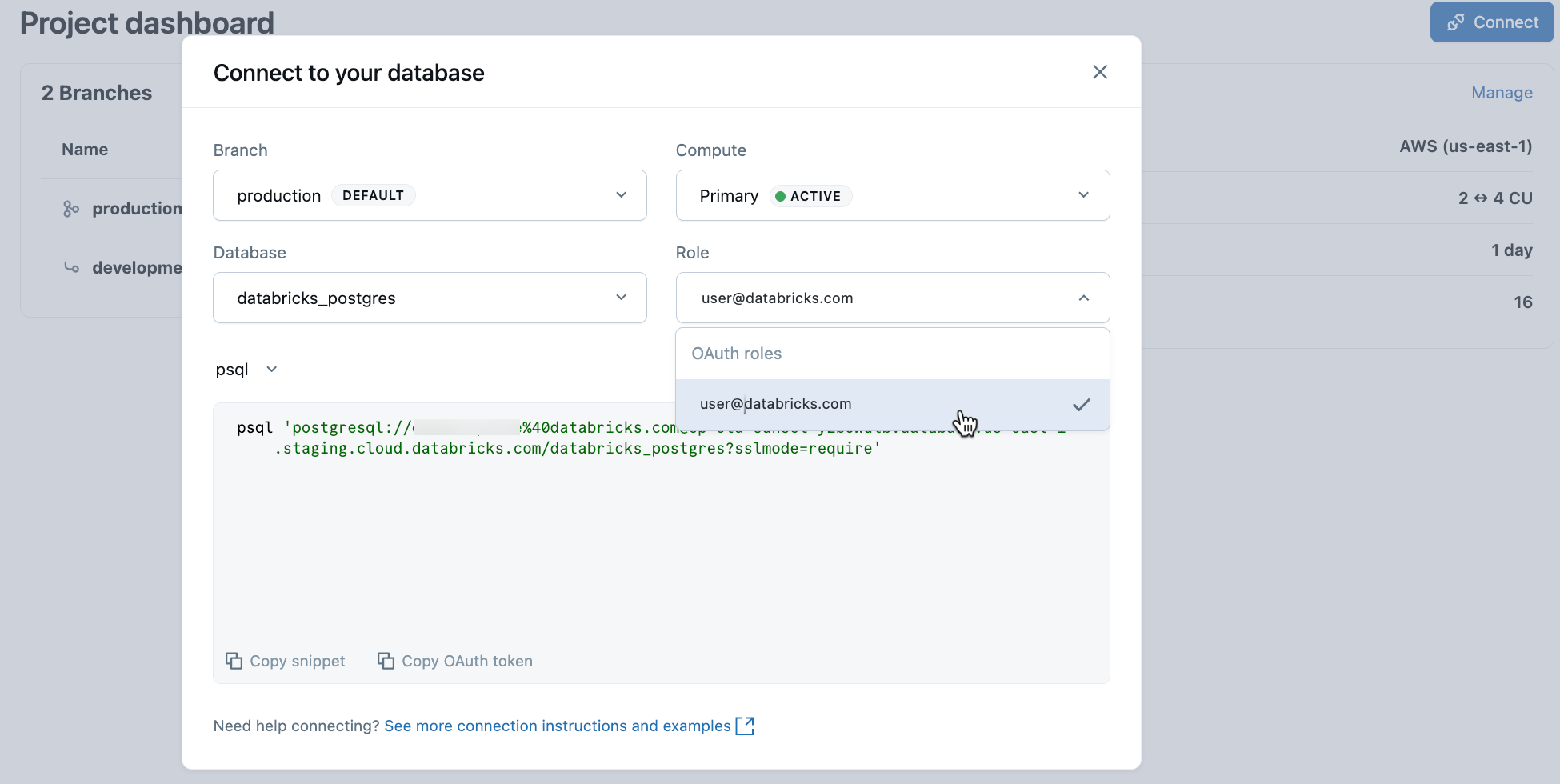
При создании проекта автоматически создается роль Postgres для вашей учетной записи Databricks (например, user@databricks.com). Эта роль принадлежит базе данных по умолчанию databricks_postgres и является членом databricks_superuser, предоставляя ей широкие привилегии для управления объектами базы данных.
Чтобы подключиться с помощью удостоверения Databricks с OAuth, скопируйте psql фрагмент подключения из диалогового окна подключения.
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
После ввода команды psql подключения в терминале вам будет предложено предоставить токен OAuth. Получите маркер, щелкнув параметр "Копировать маркер OAuth " в диалоговом окне подключения.
Сведения о подключении и параметры проверки подлинности см. в Кратком руководстве.
Создание первой таблицы
Редактор SQL Lakebase идет предварительно загружен примерами SQL, чтобы помочь вам приступить к работе. В проекте выберите рабочую ветвь, откройте редактор SQL и запустите предоставленные инструкции, чтобы создать таблицу playing_with_lakebase и вставить примеры данных. Вы также можете использовать редактор таблиц для управления визуальными данными или подключиться к внешним клиентам Postgres.
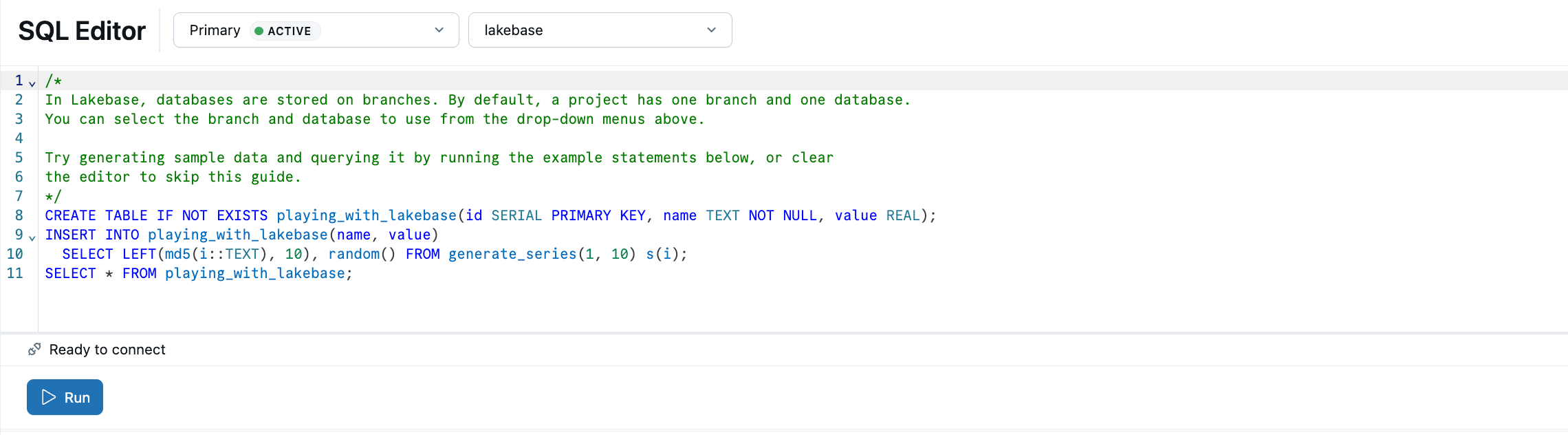
Дополнительные сведения о параметрах запроса: Редактор SQL | Редактор таблиц | клиенты PostgreSQL
Регистрация в каталоге Unity
Теперь, когда вы создали таблицу в рабочей ветви, зарегистрируйте базу данных в каталоге Unity, чтобы запросить данные из редактора SQL Databricks.
- Используйте переключатель приложений для перехода в Lakehouse.
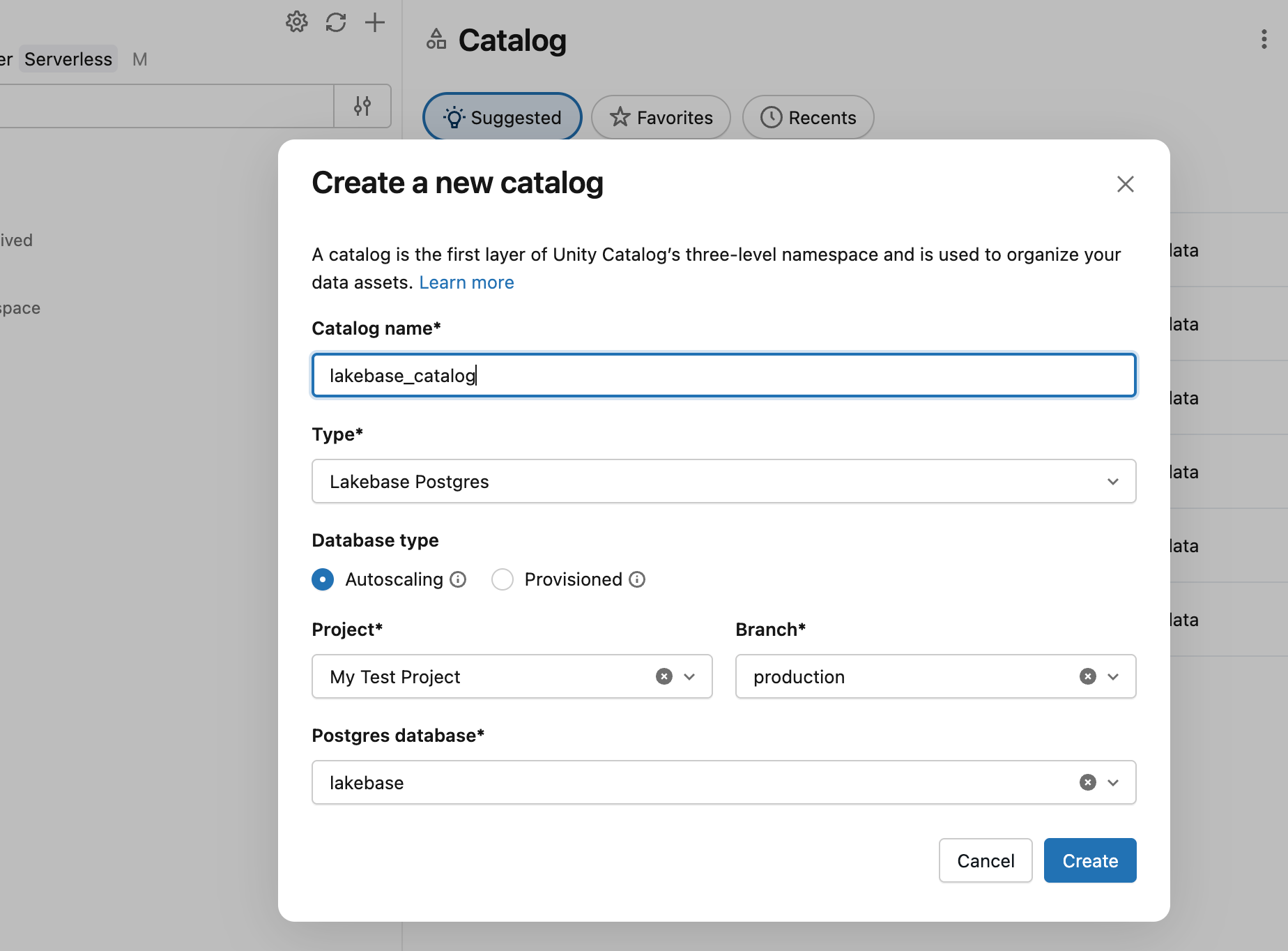
- В обозревателе каталогов щелкните значок плюса и создайте каталог.
- Введите имя каталога (например,
lakebase_catalog). - Выберите Lakebase Postgres в качестве типа каталога и включите параметр автомасштабирования .
- Выберите проект,
productionветвь иdatabricks_postgresбазу данных. - Нажмите кнопку "Создать".
Теперь вы можете запросить только что созданную таблицу playing_with_lakebase из редактора SQL Databricks с помощью хранилища SQL:
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
Это позволяет выполнять федеративные запросы, объединяющие данные транзакций Lakebase с аналитикой lakehouse. Дополнительные сведения см. в разделе "Регистрация в каталоге Unity".
Синхронизация данных с обратным ETL
Вы только что узнали, как выполнять запросы к данным Lakebase в каталоге Unity. Lakebase также работает в обратном направлении: перенос отобранных аналитических данных из каталога Unity в базу данных Lakebase. Это полезно при обогащении данных, функций машинного обучения или агрегированных метрик, вычисляемых в lakehouse, которые должны обслуживаться приложениями с низкой задержкой транзакционных запросов.
Сначала создайте таблицу в каталоге Unity, представляющую аналитические данные. Откройте хранилище SQL или записную книжку и выполните следующую команду:
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Теперь синхронизируйте эту таблицу с базой данных Lakebase:
- В обозревателе каталогов Lakehouse перейдите к main>default>user_segments.
- Нажмите кнопку "Создать>синхронизированную таблицу".
- Настройте синхронизацию:
-
Имя таблицы: Введите
user_segments_synced. - Тип базы данных: Выберите Lakebase Serverless (Autoscaling).
- Режим синхронизации: выберите моментальный снимок для одноразовой синхронизации данных.
- Выберите проект, рабочую
databricks_postgresветвь и базу данных.
-
Имя таблицы: Введите
- Нажмите кнопку "Создать".
После завершения синхронизации таблица появится в базе данных Lakebase. Процесс синхронизации создает схему default в Postgres для сопоставления схемы каталога Unity, поэтому main.default.user_segments_synced становится default.user_segments_synced. Вернитесь к Lakebase с помощью переключателя приложений и запросите его в редакторе SQL Lakebase:
SELECT * FROM "default"."user_segments_synced" WHERE "engagement" = 'high';
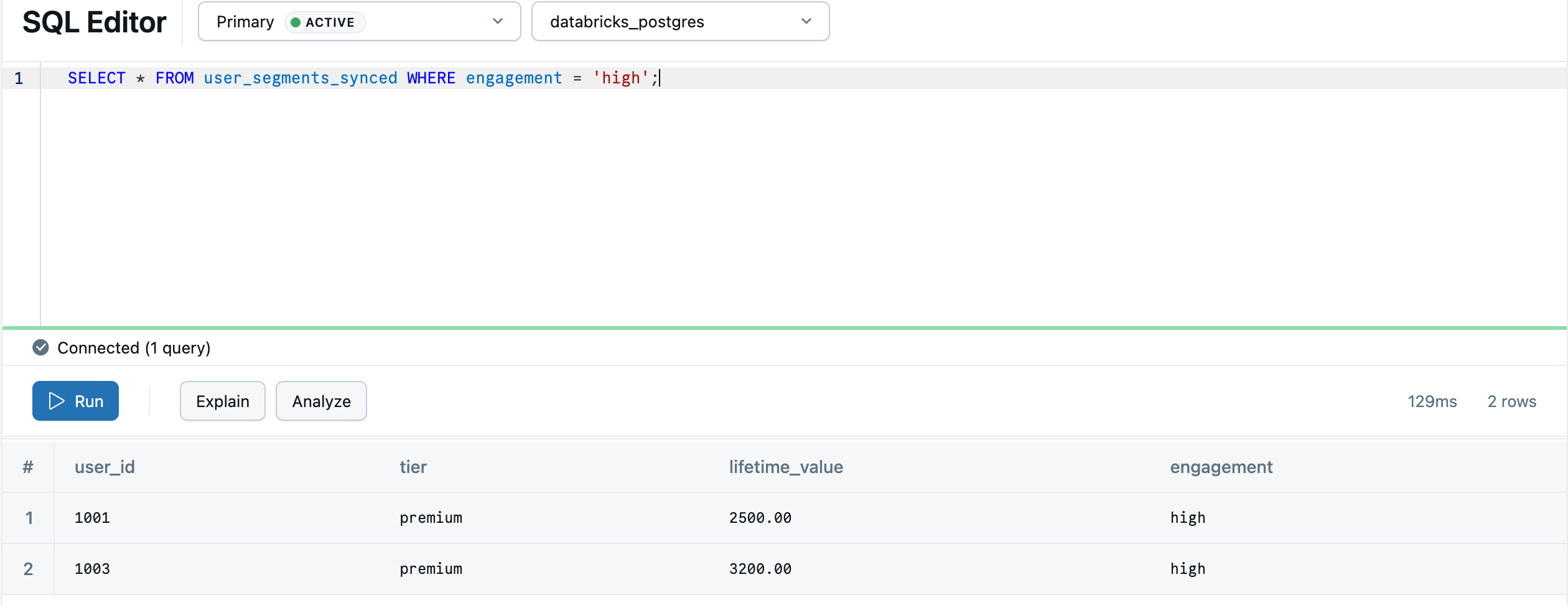
Аналитика lakehouse теперь доступна для обслуживания в режиме реального времени в вашей транзакционной базе данных. Сведения о непрерывной синхронизации, расширенных конфигурациях и сопоставлениях типов данных см. в разделе "Обратный ETL".