Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Shiny — это пакет R, доступный в CRAN и используемый для создания интерактивных приложений и панелей мониторинга R. Вы можете использовать Shiny в RStudio Server, размещенном на кластерах Azure Databricks. Вы также можете разрабатывать, размещать и совместно использовать приложения Shiny непосредственно из записной книжки Azure Databricks.
Чтобы приступить к работе с Shiny, ознакомьтесь с учебниками Shiny
В этой статье описывается, как запускать приложения Shiny в Azure Databricks и использовать Apache Spark в приложениях Shiny.
Shiny в записных книжках R
Начните работу с Shiny в R-ноутбуках
Пакет Shiny входит в состав Databricks Runtime. Вы можете в интерактивном режиме разрабатывать и тестировать приложения Shiny в записных книжках Azure Databricks для R, которые аналогичны размещенному приложению RStudio.
Выполните следующие действия, чтобы приступить к работе:
Создайте записную книжку R.
Импортируйте пакет Shiny и выполните пример приложения
01_helloследующим образом:library(shiny) runExample("01_hello")Когда приложение будет готово, в выходных данных будет указан URL-адрес приложения Shiny в виде ссылки для перехода, которая позволяет открыть новую вкладку. Сведения о предоставлении общего доступа к этому приложению другим пользователям см. в разделе Отправка URL-адреса приложения Shiny.

Примечание.
- Сообщения журнала отображаются в результатах команды аналогично сообщению журнала по умолчанию (
Listening on http://0.0.0.0:5150), показанному в примере. - Чтобы завершить работу приложения Shiny, нажмите кнопку Отмена.
- Приложение Shiny использует процесс R записной книжки. Если окончательно удалить записную книжку из кластера или отменить ячейку, в которой работает приложение, приложение Shiny завершит работу. Во время выполнения приложения Shiny нельзя выполнять другие ячейки.
Запуск приложений Shiny из папок Databricks Git
Вы можете запускать приложения Shiny, которые регистрируются в папках Databricks Git.
Запустите приложение.
library(shiny) runApp("006-tabsets")
Запуск приложений Shiny из файлов
Если код приложения Shiny является частью проекта, управляемого системой управления версиями, его можно запустить в записной книжке.
Примечание.
Необходимо использовать абсолютный путь или задать рабочий каталог с setwd().
Извлеките код из репозитория, используя примерно такой код:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Чтобы запустить приложение, введите код, аналогичный приведенному ниже, в другой ячейке:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Отправка URL-адреса приложения Shiny
URL-адрес приложения Shiny, созданный при запуске приложения, можно отправить другим пользователям. Любой пользователь Azure Databricks с разрешением CAN ATTACH TO в кластере может просматривать и взаимодействовать с приложением до тех пор, пока приложение и кластер запущены.
Если кластер, в котором работает приложение, завершает работу, приложение становится недоступным. Вы можете отключить автоматическое завершение работы в параметрах кластера.
Если присоединить и запустить записную книжку, в которой размещено приложение Shiny, в другом кластере, URL-адрес изменится. Кроме того, если перезапустить приложения в том же кластере, Shiny может выбрать другой случайный порт. Чтобы обеспечить стабильный URL-адрес, можно задать параметр shiny.port или при перезапуске приложения в том же кластере, можно указать аргумент port.
Shiny на размещенном экземпляре RStudio Server
Требования
Внимание
Если вы используете RStudio Server Pro, необходимо отключить аутентификацию через прокси-сервер.
Убедитесь, что auth-proxy=1 отсутствует в /etc/rstudio/rserver.conf.
Начало работы с Shiny на размещенном сервере RStudio
Откройте RStudio в Azure Databricks.
В RStudio импортируйте пакет Shiny и выполните пример приложения
01_helloследующим образом:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Откроется новое окно, отображающее приложение Shiny.
Запуск приложения Shiny из скрипта R
Чтобы запустить приложение Shiny из скрипта R, откройте скрипт R в редакторе RStudio и нажмите кнопку Run App (Запустить приложение) в правом верхнем углу.
Использование Apache Spark в приложениях Shiny
Вы можете использовать Apache Spark в приложениях Shiny с помощью Spark или sparklyr.
Использование SparkR с Shiny в записной книжке
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Использование sparklyr с Shiny в записной книжке
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
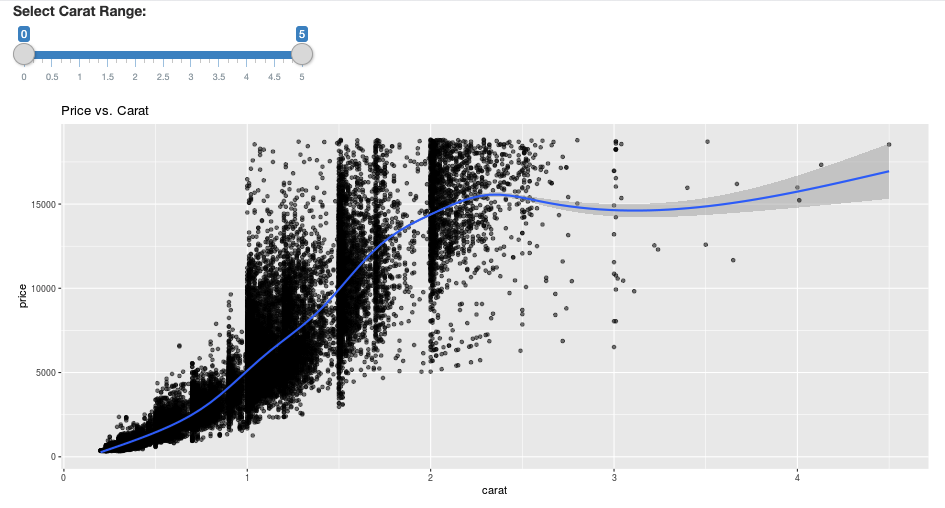
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
Вопросы и ответы
- Почему мое приложение Shiny становится неактивно через некоторое время?
- Почему моё окно просмотрщика Shiny пропадает спустя некоторое время?
- Почему задания Spark с длительным выполнением не возвращают результат?
- Как избежать тайм-аута?
- Приложение аварийно завершается сразу после запуска, но код правилен. Что происходит?
- Сколько подключений можно принять для одной ссылки на приложение Shiny во время разработки?
- Можно ли использовать версию пакета Shiny, отличающуюся от версии, установленной в Databricks Runtime?
- Как разработать приложение Shiny, которое можно опубликовать на сервере Shiny и которое сможет обращаться к данным в Azure Databricks?
- Можно ли разрабатывать приложения Shiny в записной книжке Azure Databricks?
- Как сохранить приложения Shiny, разработанные на размещенном экземпляре RStudio Server?
Почему мое приложение Shiny становится неактивно через некоторое время?
Если вы не взаимодействуете с приложением Shiny, подключение к приложению закрывается через 4 минуты.
Чтобы повторно подключиться, обновите страницу приложения Shiny. Это сбросит состояние панели мониторинга.
Почему мое окно просмотра Shiny исчезает через некоторое время?
Если окно средства просмотра Shiny исчезает после простоя в течение нескольких минут, это связано с тем же тайм-аутом, что и в случае "заморозки экрана".
Почему задания Spark с длительным выполнением не возвращают результат?
Это связано с тайм-аутом простоя. Любое задание Spark, выполняемое дольше указанного ранее времени ожидания, не может вывести результат, так как подключение закрывается перед возвратом задания.
Как избежать тайм-аута?
В запросе на функцию предлагается обходное решение: отправка клиентом сообщения о сохранении активности, чтобы предотвратить время ожидания TCP на некоторых подсистемах балансировки нагрузки на Github. Обходной путь отправляет пульсы, чтобы сохранить подключение WebSocket живым при простое приложение. Но если приложение долго не отвечает из-за длительных вычислений, такое решение не работает.
Shiny не поддерживает длительное выполнение задач. В записи блога Shiny рекомендуется использовать обещания и фьючерсы для асинхронного выполнения длительных задач и предотвращения блокировки приложения. Ниже приведен пример использования пакетов пульса для поддержания работы приложения Shiny и длительного выполнения задания Spark в конструкции
future.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages('future') install.packages('promises') library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)С момента начальной загрузки страницы существует жесткое ограничение в 12 часов, после чего любое подключение, даже если активно, будет завершено. Для повторного подключения в этих случаях необходимо обновить приложение Shiny. Однако базовое подключение WebSocket может закрыться в любое время различными факторами, включая нестабильность сети или режим спящего режима компьютера. Databricks рекомендует переписать приложения Shiny таким образом, что они не требуют длительного подключения и не полагаются на состояние сеанса.
Приложение аварийно завершается сразу после запуска, но код правилен. Что происходит?
Существует ограничение на 50 МБ на общий объем данных, которые можно отобразить в приложении Shiny в Azure Databricks. Если общий размер данных приложения превышает этот предел, он завершится сбоем сразу после запуска. Чтобы избежать этого, Databricks рекомендует уменьшить размер данных, например путем уменьшения объема отображаемых данных или уменьшения разрешения изображений.
Сколько подключений можно принять для одной ссылки на приложение Shiny во время разработки?
В Databricks рекомендуется использовать не больше 20.
Можно ли использовать версию пакета Shiny, отличающуюся от версии, установленной в Databricks Runtime?
Да. См. статью Исправление версии пакетов R.
Как разработать приложение Shiny, которое можно опубликовать на сервере Shiny и которое сможет обращаться к данным в Azure Databricks?
Хотя вы можете получить доступ к данным естественно с помощью SparkR или sparklyr во время разработки и тестирования в Azure Databricks, после публикации приложения Shiny в автономной службе размещения он не может напрямую получить доступ к данным и таблицам в Azure Databricks.
Чтобы приложение работало вне Azure Databricks, необходимо переписать функции доступа к данным. Возможны несколько вариантов:
- Использование JDBC/ODBC для отправки запросов в кластер Azure Databricks.
- Использование Databricks Connect.
- Прямой доступ к данным в объектном хранилище.
Databricks рекомендует совместно с командой по решениям Azure Databricks подобрать оптимальный подход для ваших существующих данных и архитектуры аналитики.
Можно ли разрабатывать приложения Shiny в записной книжке Azure Databricks?
Да, вы можете разрабатывать приложения Shiny в записной книжке Azure Databricks.
Как сохранить приложения Shiny, разработанные на размещенном экземпляре RStudio Server?
Вы можете сохранить код приложения в DBFS или проверить код в элементе управления версиями.