Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается создание расширенного поколения (RAG) и то, что разработчики должны создать готовое к работе решение RAG.
Чтобы узнать о двух способах создания приложения "чат по данным", одного из лучших вариантов использования искусственного интеллекта для бизнеса, см. статью "Расширение LLM" с помощью RAG или точной настройки.
На следующей схеме показаны основные шаги RAG:
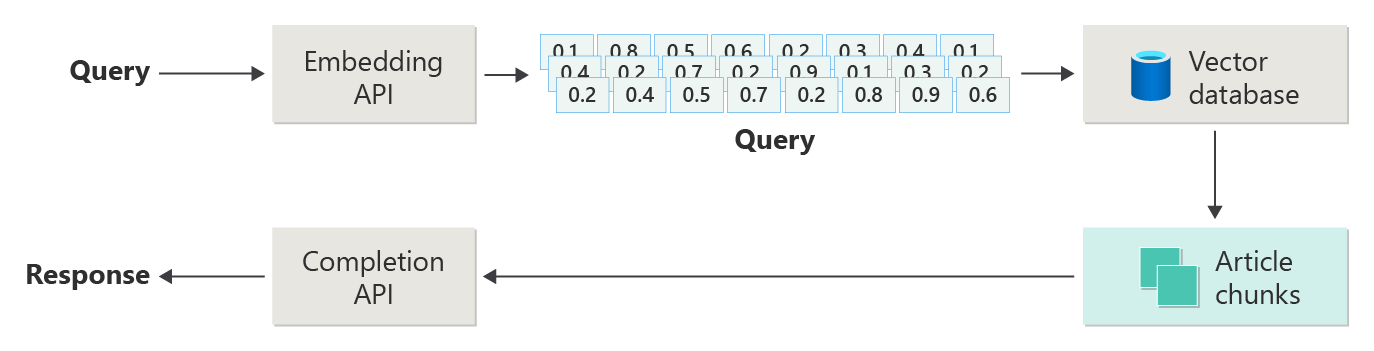
Этот процесс называется наивным RAG. Это помогает понять основные части и роли в системе чата на основе RAG.
В реальных системах RAG требуется больше предварительной обработки и последующей обработки для обработки статей, запросов и ответов. На следующей схеме показана более реалистичная настройка, называемая расширенной RAG:

Эта статья предоставляет простую платформу для понимания основных этапов в реальной системе чата на основе RAG:
- Этап приема
- Этап конвейера вывода
- Этап оценки
Прием (Ingestion)
Прием означает сохранение документов организации, чтобы быстро найти ответы для пользователей. Основной задачей является поиск и использование частей документов, которые лучше всего соответствуют каждому вопросу. Большинство систем используют векторные внедрения и совместное поиск сходства для сопоставления вопросов с содержимым. Вы получаете лучшие результаты, когда вы понимаете тип контента (например, шаблоны и формат) и упорядочиваете данные в векторной базе данных.
При настройке приема сосредоточьтесь на следующих шагах:
- Предварительная обработка и извлечение содержимого
- Стратегия фрагментирования
- Организация блокирования
- Стратегия обновления
Предварительная обработка и извлечение содержимого
Первым шагом этапа приема является предварительная обработка и извлечение содержимого из документов. Этот шаг имеет решающее значение, так как он гарантирует, что текст чист, структурирован и готов к индексации и извлечению.
Чистое и точное содержимое упрощает работу системы чата на основе RAG. Начните с фигуры и стиля документов, которые вы хотите индексировать. Соответствуют ли они шаблону набора, например документации? Если нет, какие вопросы могут ответить на эти документы?
По крайней мере настройте конвейер приема для:
- Стандартизация текстовых форматов
- Обработка специальных символов
- Удаление не связанного или старого содержимого
- Отслеживание различных версий содержимого
- Обработка содержимого с помощью вкладок, изображений или таблиц
- Извлечение метаданных
Некоторые из этих сведений, таких как метаданные, могут помочь во время извлечения и оценки, если он хранится в документе в векторной базе данных. Вы также можете объединить его с текстовым блоком, чтобы улучшить внедрение вектора блока.
Стратегия фрагментирования
Разработчик решает, как разбить большие документы на небольшие блоки. Блокирование помогает отправлять наиболее релевантный контент в LLM, чтобы он смог ответить на вопросы пользователей лучше. Кроме того, думайте о том, как вы будете использовать блоки после их получения. Попробуйте распространенные отраслевые методы и протестируйте стратегию блокирования в вашей организации.
При блокинге думайте о следующем:
- Оптимизация размера блока: выберите лучший размер блока и как разделить его по разделу, абзацу или предложению.
- Перекрывающиеся и скользящие блоки окна. Определите, следует ли разделять блоки или перекрываться. Вы также можете использовать подход к скользящему окну.
- Small2Big: если разделить по предложению, упорядочение содержимого таким образом, чтобы можно было найти рядом предложения или полный абзац. Предоставление этого дополнительного контекста LLM может помочь ему лучше ответить. Дополнительные сведения см. в следующем разделе.
Организация блокирования
В системе RAG упорядочение данных в векторной базе данных упрощает поиск нужных сведений. Ниже приведены некоторые способы настройки индексов и поиска.
- Иерархические индексы: использование слоев индексов. Сводный индекс верхнего уровня быстро находит небольшой набор вероятных блоков. Индекс второго уровня указывает на точные данные. Эта настройка ускоряет поиск, сужая параметры, прежде чем подробно искать.
- Специализированные индексы: выбор индексов, которые соответствуют вашим данным. Например, используйте индексы на основе графов, если блоки подключаются друг к другу, например в сетях ссылок или графах знаний. Используйте реляционные базы данных, если данные содержатся в таблицах и фильтруйте запросы SQL.
- Гибридные индексы: объединение различных методов индексирования. Например, сначала используйте сводный индекс, а затем индекс на основе графа для изучения соединений между блоками.
Оптимизация выравнивания
Сделайте извлеченные блоки более актуальными и точными, сопоставляя их с типами вопросов, которые они отвечают. Одним из способов является создание примера вопроса для каждого блока, показывающего, какой вопрос он лучше всего отвечает. Этот подход помогает несколькими способами:
- Улучшено сопоставление: во время извлечения система сравнивает вопрос пользователя с этими примерами вопросов, чтобы найти лучший фрагмент. Этот метод повышает релевантность результатов.
- Обучающие данные для моделей машинного обучения: эти пары вопросов и блоков помогают обучать модели машинного обучения в системе RAG. Модели учат, какие блоки отвечают на типы вопросов.
- Прямая обработка запросов: если вопрос пользователя соответствует образцу вопроса, система может быстро найти и использовать правильный блок, ускоряя ответ.
Пример вопроса каждого блока выступает в качестве метки, которая управляет алгоритмом извлечения. Поиск становится более ориентированным и осведомленным о контексте. Этот метод хорошо работает, когда блоки охватывают множество различных разделов или типов информации.
Стратегии обновления
Если организация часто обновляет документы, необходимо сохранить базу данных в актуальном состоянии, чтобы извлекатель всегда смог найти последние сведения. Компонент извлекателя является частью системы, которая выполняет поиск векторной базы данных и возвращает результаты. Ниже приведены некоторые способы хранения векторной базы данных:
инкрементальные обновления:
- Регулярные интервалы. Задайте обновления для выполнения по расписанию (например, ежедневно или еженедельно) на основе частоты изменения документов. Это действие сохраняет базу данных свежим.
- Обновления на основе триггеров: настройка автоматических обновлений при добавлении или изменении документа. Система переиндексирует только затронутые части.
Частичные обновления:
- Выборочная переиндексация: обновите только части базы данных, которые изменились, а не все. Этот метод экономит время и ресурсы, особенно для больших наборов данных.
- Разностная кодировка: храните только изменения между старыми и новыми документами, что сокращает объем данных для обработки.
Версионирование:
- Создание моментальных снимков. Сохранение версий набора документов в разное время. Это действие позволяет вернуться или восстановить более ранние версии при необходимости.
- Управление версиями документа: используйте систему управления версиями для отслеживания изменений и сохранения журнала документов.
обновления в режиме реального времени:
- Потоковая обработка: используйте потоковую обработку для обновления векторной базы данных в режиме реального времени при изменении документов.
- Динамический запрос: используйте динамические запросы для получения ответов up-to-date, иногда смешивая динамические данные с кэшируемыми результатами для скорости.
Техники оптимизации:
- Пакетная обработка: группируйте изменения и применяйте их вместе для экономии ресурсов и уменьшения затрат.
-
Гибридные подходы: сочетание различных стратегий:
- Используйте добавочные обновления для небольших изменений.
- Используйте полный переиндексирование для значительных обновлений.
- Отслеживайте и документируйте основные изменения данных.
Выберите стратегию обновления или смесь, которая соответствует вашим потребностям. Подумайте о:
- Размер корпуса документа
- Частота обновления
- Потребности в данных в режиме реального времени
- Доступные ресурсы
Просмотрите эти факторы для приложения. Каждый метод имеет компромиссы в сложности, затратах и насколько быстро отображаются обновления.
Конвейер вывода
Теперь статьи блокируются, векторизированы и хранятся в векторной базе данных. Затем сосредоточьтесь на получении лучших ответов из вашей системы.
Чтобы получить точные и быстрые результаты, подумайте об этих ключевых проблемах:
- Понятен ли вопрос пользователя и, скорее всего, получить правильный ответ?
- Нарушает ли вопрос какие-либо правила компании?
- Можно ли переписать вопрос, чтобы помочь системе найти лучшие совпадения?
- Совпадают ли результаты из базы данных с вопросом?
- Следует ли изменить результаты перед отправкой их в LLM, чтобы убедиться, что ответ релевантн?
- Полностью ли ответ LLM отвечает на вопрос пользователя?
- Соответствует ли ответ правилам вашей организации?
Весь конвейер вывода работает в режиме реального времени. Нет единого правильного способа настройки предварительной обработки и последующей обработки. Вы используете сочетание вызовов кода и LLM. Одним из самых больших компромиссов является балансировка точности и соответствия стоимости и скорости.
Рассмотрим стратегии для каждого этапа конвейера вывода.
Шаги предварительной обработки запросов
Предварительная обработка запроса начинается сразу после отправки пользователем вопроса:

Эти шаги помогут убедиться, что вопрос пользователя соответствует вашей системе и готов найти лучшие фрагменты статей с помощью косинусного сходства или поиска ближайшего соседа.
Проверка политики: используйте логику для обнаружения и удаления нежелательного содержимого, например личных данных, плохого языка или попыток нарушения правил безопасности (называется "тюрьма").
Перезапись запросов: при необходимости измените вопрос— разверните акронимы, удалите сленг или переразместите его, чтобы сосредоточиться на больших идеях (запрос на шаг назад).
Специальная версия запроса на шаг назад — это гипотетические внедрения документов (HyDE). HyDE имеет ответ LLM на вопрос, делает внедрение из этого ответа, а затем выполняет поиск векторной базы данных с ним.
Подзапросы
Вложенные запросы разбивают длинный или сложный вопрос на более мелкие, простые вопросы. Система отвечает на каждый маленький вопрос, а затем объединяет ответы.
Например, если кто-то спрашивает: "Кто сделал более важный вклад в современную физику, Альберт Эйнштейн или Нилс Бор?" Вы можете разделить его на:
- Подзапрос 1: "Что альберт Эйнштейн способствовал современной физике?"
- Подзапрос 2: "Что Нилс Бор способствовал современной физике?"
Ответы могут включать:
- Для Эйнштейна: теория относительности, фотоэлектрический эффект и E=mc^2.
- Для Бора: модель атома водорода, работа над квантовой механикой и принципом взаимодополняемости.
Затем можно задать следующие вопросы:
- Подзапрос 3: "Как теории Эйнштейна изменили современную физику?"
- Подзапрос 4: "Как теории Бора изменили современную физику?"
Эти дальнейшие действия смотрят на эффект каждого ученого, например:
- Как работа Эйнштейна привела к новым идеям в космологии и квантовой теории
- Как работа Бора помогла нам понять атомы и квантовые механики
Система объединяет ответы, чтобы дать полный ответ на исходный вопрос. Этот метод упрощает ответы на сложные вопросы, разбив их на четкие, небольшие части.
Маршрутизатор запросов
Иногда содержимое находится в нескольких базах данных или системах поиска. В этих случаях используйте маршрутизатор запросов. Маршрутизатор запросов выбирает лучшую базу данных или индекс, чтобы ответить на каждый вопрос.
Маршрутизатор запросов работает после того, как пользователь задает вопрос, но прежде чем система ищет ответы.
Вот как работает маршрутизатор запросов:
- Анализ запросов: LLM или другое средство рассматривает вопрос, чтобы выяснить, какой ответ необходим.
- Выбор индекса: маршрутизатор выбирает один или несколько индексов, которые соответствуют вопросу. Некоторые индексы лучше подходят для фактов, другие для мнений или специальных тем.
- Диспетчер запросов: маршрутизатор отправляет вопрос выбранному индексу или индексам.
- Агрегирование результатов: система собирает и объединяет ответы из индексов.
- Создание ответов: система создает четкий ответ с помощью найденных сведений.
Используйте разные индексы или поисковые системы для:
- Специализация типа данных: некоторые индексы сосредоточены на новостях, других в академических документах или на специальных базах данных, таких как медицинская или юридическая информация.
- Оптимизация типов запросов: некоторые индексы быстро выполняются для простых фактов (например, дат), а другие обрабатывают сложные или экспертные вопросы.
- Алгоритмические различия: различные поисковые системы используют различные методы, такие как векторный поиск, поиск по ключевым словам или расширенный семантический поиск.
Например, в системе медицинских консультаций может быть следующее:
- Индекс исследования для технических сведений
- Индекс примера для реальных примеров
- Общий индекс работоспособности для основных вопросов
Если кто-то спрашивает о влиянии нового препарата, маршрутизатор отправляет вопрос в исследовательский индекс бумаги. Если вопрос относится к общим симптомам, он использует общий индекс работоспособности для простого ответа.
Этапы обработки после извлечения
Обработка после получения происходит после того, как система находит блоки содержимого в векторной базе данных:

Затем проверьте, полезны ли эти блоки для запроса LLM перед отправкой в LLM.
Имейте в виду следующее:
- Дополнительные сведения могут скрывать самые важные сведения.
- Неуместная информация может сделать ответ хуже.
Следите за иглой в проблеме сена : LLMs часто обращают больше внимания на начало и конец запроса, чем середина.
Кроме того, помните максимальное окно контекста LLM и количество маркеров, необходимых для длинных запросов, особенно в масштабе.
Чтобы устранить эти проблемы, используйте конвейер обработки после извлечения, выполнив следующие действия:
- Результаты фильтрации: сохраняйте только блоки, соответствующие запросу. Игнорируйте остальные при создании запроса LLM.
- Повторное ранжирование: поместите наиболее релевантные блоки в начало и конец запроса.
- Сжатие запроса: используйте небольшую, дешевле модель для суммирования и объединения блоков в один запрос перед отправкой в LLM.
Этапы обработки после завершения
Обработка после завершения выполняется после вопроса пользователя, а все фрагменты содержимого отправляются в LLM:

После того как LLM дает ответ, проверьте его точность. Конвейер обработки после завершения может включать:
- Проверка фактов: ищите заявления в ответе, которые утверждают, что это факты, а затем проверьте, верно ли они. Если проверка фактов завершается ошибкой, можно снова попросить LLM или отобразить сообщение об ошибке.
- Проверка политики. Убедитесь, что ответ не содержит вредного содержимого для пользователя или вашей организации.
Оценка
Оценка такой системы является более сложной, чем выполнение регулярных модульных тестов или тестов интеграции. Подумайте об этих вопросах:
- Довольны ли пользователи ответами?
- Точны ли ответы?
- Как собирать отзывы пользователей?
- Существуют ли правила о том, какие данные можно собирать?
- Вы можете увидеть каждый шаг системы, когда ответы неправы?
- Вы храните подробные журналы для анализа первопричин?
- Как обновить систему, не делая вещи хуже?
Запись и выполнение отзывов от пользователей
Обратитесь к группе конфиденциальности вашей организации для разработки средств отслеживания отзывов, системных данных и ведения журнала для судебной экспертизы и анализа первопричин сеанса запроса.
Следующим шагом является создание конвейера оценки. Конвейер оценки упрощает и быстрее просматривать отзывы и узнать, почему ИИ дал определенные ответы. Проверьте каждый ответ, чтобы узнать, как ИИ создал его, если использовались правильные фрагменты содержимого, и как документы были разделены.
Кроме того, найдите дополнительные шаги предварительной обработки или последующей обработки, которые могут улучшить результаты. Эта закрытая проверка часто находит пробелы в содержимом, особенно если для вопроса пользователя нет хорошей документации.
Вам нужен конвейер оценки для обработки этих задач в масштабе. Хороший конвейер использует пользовательские средства для измерения качества ответа. Это помогает понять, почему ИИ дал конкретный ответ, какие документы, которые он использовал, и насколько хорошо работает конвейер вывода.
Золотой набор данных
Один из способов проверить, насколько хорошо работает система чата RAG, — использовать золотой набор данных. Золотой набор данных — это набор вопросов с утвержденными ответами, полезными метаданными (например, типом темы и вопроса), ссылками на исходные документы и различными способами, которыми пользователи могут задавать то же самое.
Золотой набор данных показывает "лучший сценарий". Разработчики используют его, чтобы узнать, насколько хорошо работает система и выполнять тесты при добавлении новых функций или обновлений.
Оценка вреда
Моделирование вреда помогает выявить возможные риски в продукте и спланировать способы их сокращения.
Средство оценки вреда должно включать следующие ключевые функции:
- Идентификация заинтересованных лиц: помогает вам перечислить и сгруппировать всех, затронутых технологией, включая прямых пользователей, людей, пострадавших косвенно, будущих поколений и даже окружающей среды.
- Категории и описания вреда: перечисляет возможные последствия, такие как потеря конфиденциальности, эмоциональный стресс или экономический вред. Поможет вам ознакомиться с примерами и поможет вам подумать о ожидаемых и непредвиденных проблемах.
- Оценки серьезности и вероятности: помогает судить о том, насколько серьезно и вероятно каждый вред, поэтому вы можете решить, что сначала исправить. Вы можете использовать данные для поддержки ваших вариантов.
- Стратегии устранения рисков: предлагает способы снижения рисков, таких как изменение системы проектирования, добавление гарантий или использование других технологий.
- Механизмы обратной связи: позволяет собирать отзывы от заинтересованных лиц, чтобы вы могли продолжать улучшать процесс по мере получения дополнительных сведений.
- Документация и отчеты. Позволяет легко создавать отчеты, которые показывают, что вы нашли и что сделали для снижения рисков.
Эти функции помогают находить и устранять риски, а также помогают создавать более этические и ответственные ИИ, думая обо всех возможных последствиях с самого начала.
Дополнительные сведения см. в следующих статьях:
Тестирование и проверка гарантий
Red-teaming является ключевым — это означает, чтобы действовать как злоумышленник, чтобы найти слабые места в системе. Этот шаг особенно важен для прекращения взлома тюрьмы. Советы по планированию и управлению красной командой для ответственного искусственного интеллекта см. в статье "Планирование красной команды" для крупных языковых моделей (LLM) и их приложений.
Разработчики должны протестировать системы RAG в различных сценариях, чтобы убедиться, что они работают. Этот шаг делает систему сильнее, а также помогает точно настроить ответы на соблюдение этических стандартов и правил.
Окончательные рекомендации по проектированию приложений
Ниже приведены некоторые ключевые моменты, которые следует помнить из этой статьи, которые помогут вам разработать приложение:
- Непредсказуемость создания искусственного интеллекта
- Изменение запроса пользователя и их влияние на время и стоимость
- Параллельные запросы LLM для повышения производительности
Чтобы создать созданное приложение ИИ, ознакомьтесь с чатом с помощью собственного примера данных для Python. Это руководство также доступно для .NET, Javaи JavaScript.