Расширение крупной языковой модели с помощью расширенного создания и точной настройки
В статьях в этой серии рассматриваются модели извлечения знаний, используемые LLM для создания ответов. По умолчанию большая языковая модель (LLM) имеет доступ только к данным обучения. Однако модель можно расширить, чтобы включить данные в режиме реального времени или частные данные. В этой статье рассматривается один из двух механизмов расширения модели.
Первый механизм — извлечение дополненного поколения (RAG), который является формой предварительной обработки, которая объединяет семантический поиск с контекстной примычкой (рассматривается в другой статье).
Второй механизм является тонкой настройкой, которая относится к процессу дальнейшего обучения модели на определенном наборе данных после первоначального, широкого обучения, с целью адаптации его к более эффективному выполнению задач или пониманию концепций, связанных с этим набором данных. Этот процесс помогает модели специализироваться или повысить ее точность и эффективность в обработке определенных типов входных или доменов.
В следующих разделах подробно описаны два механизма.
Общие сведения о RAG
RAG часто используется для включения сценария "чат по моим данным", где компании, имеющие большой корпус текстового содержимого (внутренние документы, документация и т. д.) и хотят использовать этот корпус в качестве основы для ответов на запросы пользователей.
На высоком уровне создается запись базы данных для каждого документа (или часть документа, называемого блоком). Блок индексируется на его внедрение, вектор (массив) чисел, представляющих аспекты документа. Когда пользователь отправляет запрос, выполняется поиск базы данных для аналогичных документов, а затем отправка запроса и документов в LLM для создания ответа.
Примечание.
Термин retrieval-дополненного поколения (RAG) аккоммодативно. Процесс реализации системы чата на основе RAG, описанной в этой статье, можно применить, есть ли желание использовать внешние данные для использования в поддерживаемой емкости (RAG) или использоваться в качестве центрального элемента ответа (RCG). Это нюансное различие не рассматривается в большинстве чтений, связанных с RAG.
Создание индекса векторных документов
Первым шагом к созданию системы чата на основе RAG является создание векторного хранилища данных, содержащего векторное внедрение документа (или часть документа). Рассмотрим следующую схему, которая описывает основные шаги по созданию векторизованного индекса документов.

Эта схема представляет конвейер данных, который отвечает за прием, обработку и управление данными, используемыми системой. Это включает предварительную обработку данных для хранения в векторной базы данных и обеспечение правильности данных, которые передаются в LLM.
Весь процесс определяется понятием внедрения, которое представляет собой числовое представление данных (обычно слова, фразы, предложения или даже целые документы), которое фиксирует семантические свойства входных данных таким образом, что может обрабатываться моделями машинного обучения.
Чтобы создать внедрение, вы отправляете фрагмент содержимого (предложения, абзацы или целые документы) в API внедрения Azure OpenAI. То, что возвращается из API внедрения, является вектором. Каждое значение в векторе представляет некоторые характеристики (измерение) содержимого. Измерения могут включать темы, семантические значения, синтаксис и грамматику, использование слов и фраз, контекстные отношения, стиль и тон и т. д. Вместе все значения вектора представляют размерное пространство содержимого. Другими словами, если вы можете думать о трехмерном представлении вектора с тремя значениями, данный вектор живет в определенной области x, y, z плоскости. Что делать, если вы 1000 (или более) значений? Хотя людям не удается нарисовать граф измерения 1000 на листе бумаги, чтобы сделать его более понятным, компьютеры не имеют проблем понять, что степень размерного пространства.
На следующем шаге схемы показано хранение вектора вместе с самим содержимым (или указателем на расположение содержимого) и другими метаданными в векторной базе данных. Векторная база данных похожа на любой тип базы данных с двумя различиями:
- Векторные базы данных используют вектор в качестве индекса для поиска данных.
- Векторные базы данных реализуют алгоритм, называемый cosine аналогичный поиск, также известный как ближайший сосед, который использует векторы, которые наиболее тесно соответствуют критериям поиска.
Благодаря корпусу документов, хранящихся в векторной базе данных, разработчики могут создать компонент извлекателя, который извлекает документы, соответствующие запросу пользователя из базы данных, чтобы предоставить LLM с тем, что он должен ответить на запрос пользователя.
Ответы на запросы с документами
Система RAG сначала использует семантический поиск для поиска статей, которые могут оказаться полезными для LLM при создании ответа. Следующий шаг — отправить соответствующие статьи вместе с исходным запросом пользователя в LLM, чтобы создать ответ.
Рассмотрим следующую схему как простую реализацию RAG (иногда называемую "наивной RAG").
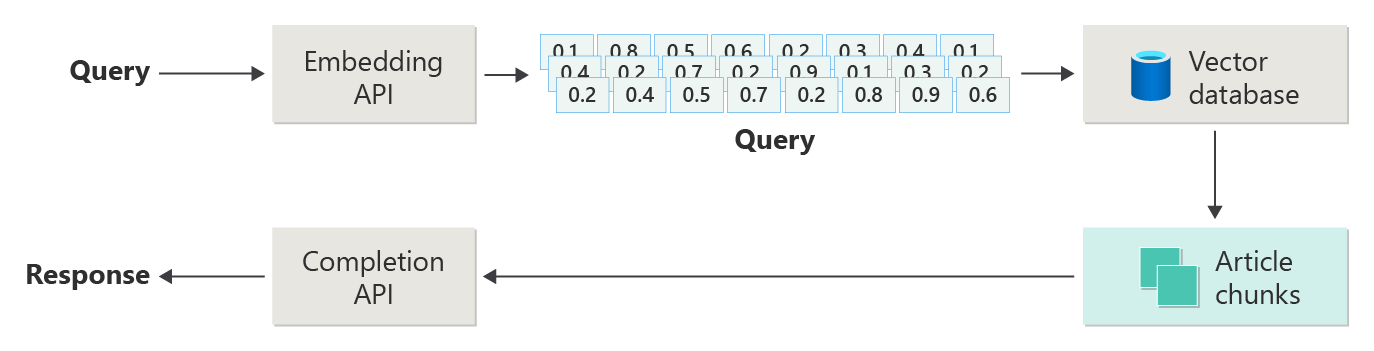
На схеме пользователь отправляет запрос. Первым шагом является создание внедрения запроса пользователя на возврат вектора. Следующим шагом является поиск векторной базы данных для этих документов (или частей документов), которые являются совпадением "ближайшего соседа".
Косинус сходства — это мера, используемая для определения того, насколько похожи два вектора, по существу оценивая косинус угла между ними. Косинус сходство близко к 1 указывает на высокую степень сходства (небольшой угол), в то время как сходство вблизи -1 указывает на непохожесть (угол приближается к 180 градусов). Эта метрика имеет решающее значение для таких задач, как сходство документов, где цель заключается в поиске документов с аналогичным содержимым или значением.
Алгоритмы ближайшего соседа работают путем поиска ближайших векторов (соседей ) к заданной точке в векторном пространстве. В алгоритме k-ближайших соседей (KNN) "k" относится к числу ближайших соседей, которые следует рассмотреть. Этот подход широко используется в классификации и регрессии, где алгоритм прогнозирует метку новой точки данных на основе большинства меток его ближайших соседей "k" в обучаемом наборе. Сходство KNN и косинус часто используются в системах, таких как подсистемы рекомендаций, где цель заключается в поиске элементов, наиболее похожих на предпочтения пользователя, представленных в виде векторов в пространстве внедрения.
Вы берете лучшие результаты из этого поиска и отправляете соответствующее содержимое вместе с запросом пользователя, чтобы создать ответ, который (надеюсь) сообщается соответствующим содержимым.
Проблемы и рекомендации
Реализация системы RAG поставляется с набором проблем. Конфиденциальность данных является первостепенной задачей, так как система должна ответственно обрабатывать пользовательские данные, особенно при получении и обработке информации из внешних источников. Вычислительные требования также могут быть значительными, так как извлечение и генеривные процессы являются ресурсоемкими. Обеспечение точности и релевантности ответов при управлении предвзятостью, присутствующих в данных или модели, является еще одним важным фактором. Разработчики должны тщательно перемещаться по этим задачам, чтобы создавать эффективные, этические и ценные системы RAG.
В следующей статье этой серии, создание расширенных систем расширенного создания добавок для получения дополнительных сведений о создании данных и конвейеров вывода для включения системы RAG, готовой к работе.
Если вы хотите начать экспериментировать с созданием решения для создания решения для создания искусственного интеллекта немедленно, рекомендуется ознакомиться с тем, как приступить к работе с чатом с помощью собственного примера данных для Python. В .NET, Java и JavaScript также доступны версии учебника.
Настройка модели
В контексте LLM в контексте LLM рассматривается процесс настройки параметров модели в наборе данных для конкретного домена после первоначального обучения на большом, разнообразном наборе данных.
LLM обучены (предварительно обучены) для широкого набора данных, захвата структуры языка, контекста и широкого спектра знаний. На этом этапе предполагается обучение шаблонов общего языка. Тонкой настройке добавляется больше обучения в предварительно обученную модель на основе меньшего определенного набора данных. Этот этап дополнительного обучения направлен на адаптацию модели для улучшения выполнения конкретных задач или понимания конкретных доменов, повышения точности и релевантности для этих специализированных приложений. Во время тонкой настройки вес модели корректируется, чтобы лучше предсказать или понять нюансы этого небольшого набора данных.
Ниже приведены некоторые рекомендации.
- Специализация: тонкой настройке модели настраивается для конкретных задач, таких как анализ юридических документов, интерпретация медицинского текста или взаимодействие с обслуживанием клиентов. Это делает модель более эффективной в этих областях.
- Эффективность. Это более эффективно для точной настройки предварительно обученной модели для конкретной задачи, чем обучение модели с нуля, так как для точной настройки требуется меньше данных и вычислительных ресурсов.
- Адаптация. Настройка позволяет адаптироваться к новым задачам или доменам, которые не были частью исходных обучающих данных, что делает LLM универсальными средствами для различных приложений.
- Улучшенная производительность: для задач, которые значительно отличаются от данных, на основе которых модель изначально была обучена, то настройка может привести к повышению производительности, так как она настраивает модель для понимания конкретного языка, стиля или терминологии, используемой в новом домене.
- Персонализация. В некоторых приложениях тонкой настройкой можно персонализировать ответы или прогнозы модели в соответствии с конкретными потребностями или предпочтениями пользователя или организации. Однако при тонкой настройке также представлены некоторые недостатки и ограничения. Понимание этих способов может помочь решить, когда следует выбирать точное изменение и альтернативные варианты, такие как получение дополненного поколения (RAG).
- Требование к данным. Для тонкой настройки требуется достаточно большой и высококачественный набор данных, характерный для целевой задачи или домена. Сбор и обработка этого набора данных могут быть сложными и ресурсоемкими.
- Риск переполнения: существует риск переполнения, особенно с небольшим набором данных. Переполнение делает модель хорошо работает над обучаемыми данными, но плохо на новых, невидимых данных, уменьшая его обобщенность.
- Затраты и ресурсы. В то время как менее ресурсоемким, чем обучение с нуля, тонкой настройке по-прежнему требуются вычислительные ресурсы, особенно для больших моделей и наборов данных, которые могут быть запрещены для некоторых пользователей или проектов.
- Обслуживание и обновление: настроенные модели могут потребовать регулярных обновлений, чтобы оставаться эффективными в качестве изменений информации для конкретного домена с течением времени. Для текущего обслуживания требуются дополнительные ресурсы и данные.
- Смещение модели: так как модель настраивается для конкретных задач, она может потерять некоторые из его общего распознавания речи и универсальности, что приводит к явлению, известному как смещение модели.
Настройка модели с помощью точной настройки объясняет, как настроить модель. На высоком уровне вы предоставляете набор данных JSON потенциальных вопросов и предпочтительные ответы. В документации предполагается, что есть заметные улучшения, предоставляя 50–100 пар вопросов и ответов, но правильное число значительно зависит от варианта использования.
Точное изменение и получение дополненного поколения
На поверхности может показаться, что существует довольно много перекрытия между тонкой настройкой и получением дополненного поколения. Выбор между точной настройкой и развертыванием дополненного поколения зависит от конкретных требований вашей задачи, включая ожидания производительности, доступность ресурсов и потребность в специфике домена и обобщенности.
При желании точной настройки по сравнению с получением дополненного поколения:
- Производительность для конкретных задач — более предпочтительнее, если высокая производительность для конкретной задачи является критической, и существуют достаточные данные, относящиеся к домену, для эффективного обучения модели без значительных избыточных рисков.
- Управление данными . Если у вас есть собственные или высоко специализированные данные, которые значительно отличаются от данных, на основе базовой модели было обучено, то вы можете включить эти уникальные знания в модель.
- Ограниченные потребности в обновлениях в режиме реального времени. Если задача не требует постоянно обновлять модель с последними сведениями, то более эффективная настройка может быть более эффективной, так как модели RAG обычно нуждаются в доступе к актуальным внешним базам данных или Интернету для извлечения последних данных.
При желании получить дополненное поколение по сравнению с тонкой настройкой:
- Динамическое или развивающееся содержимое — RAG лучше подходит для задач, в которых имеется самая текущая информация является критической. Так как модели RAG могут извлекать данные из внешних источников в режиме реального времени, они лучше подходят для приложений, таких как создание новостей или ответы на вопросы о последних событиях.
- Обобщение по специализации . Если цель заключается в поддержании высокой производительности в широком спектре тем, а не в узком домене, RAG может быть предпочтительнее. Он использует внешние база знаний, позволяя ему создавать ответы в различных доменах без риска переподбора в определенный набор данных.
- Ограничения ресурсов. Для организаций с ограниченными ресурсами для сбора данных и обучения моделей, использование подхода RAG может предложить экономически эффективную альтернативу тонкой настройке, особенно если базовая модель уже выполняет достаточно хорошо для нужных задач.
Окончательные рекомендации, которые могут повлиять на решения по проектированию приложений
Ниже приведен краткий список вещей, которые следует рассмотреть и другие варианты из этой статьи, которые влияют на решения по проектированию приложений:
- Выберите между точной настройкой и получением дополненного поколения на основе конкретных потребностей вашего приложения. Улучшенная настройка может обеспечить более высокую производительность для специализированных задач, в то время как RAG может обеспечить гибкость и актуальное содержимое для динамических приложений.