Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье показано, как оценить ответы приложения чата по набору правильных или идеальных ответов (известных как земная истина). Всякий раз, когда вы изменяете приложение чата таким образом, чтобы повлиять на ответы, выполните оценку для сравнения изменений. Это демонстрационное приложение предлагает средства, которые можно использовать сегодня, чтобы упростить выполнение вычислений.
Следуя инструкциям в этой статье, вы:
- Используйте предоставленные примеры запросов, адаптированные к домену субъекта. Эти запросы уже находятся в репозитории.
- Создайте примеры вопросов пользователей и эталонные ответы на основе ваших документов.
- Проводите оценки, используя пример запроса и сгенерированные пользователями вопросы.
- Просмотрите анализ ответов.
Примечание.
В этой статье используется один или несколько шаблонов приложений ИИ в качестве основы для примеров и рекомендаций в этой статье. Шаблоны приложений искусственного интеллекта предоставляют вам хорошо поддерживаемые эталонные реализации, которые легко развертываться. Они помогают обеспечить высококачественную отправную точку для приложений ИИ.
Обзор архитектуры
Ключевые компоненты архитектуры:
- Размещенное в Azure приложение для чата: приложение для чата работает в службе приложений Azure.
- Протокол чата Microsoft AI: протокол предоставляет стандартные контракты API для решений и языков ИИ. Приложение чата соответствует протоколу Microsoft AI Chat, что позволяет приложению оценки выполняться с любым приложением чата, соответствующим протоколу.
- Поиск с использованием ИИ Azure: Чат-приложение использует Поиск с использованием ИИ Azure для хранения данных из ваших собственных документов.
- Генератор образцов вопросов: Этот инструмент может генерировать множество вопросов для каждого документа вместе с эталонным ответом. Чем больше вопросов есть, тем дольше оценки.
- оценщик: средство запускает примеры вопросов и побуждает приложение чата отреагировать, а затем возвращает результаты.
- средство проверки: средство проверяет результаты оценки.
- инструмент Diff: средство сравнивает ответы между оценками.
При развертывании этой оценки в Azure для модели GPT-4 создается конечная точка службы Azure OpenAI с собственной емкостью . При оценке приложений чата важно, чтобы оценщик имел собственный ресурс Azure OpenAI, используя GPT-4 с собственной емкостью.
Предварительные требования
Подписка Azure. Создать бесплатно
Развертывание приложения чата.
Эти приложения чата загружают данные в ресурс поиска ИИ Azure. Этот ресурс необходим для работы приложения оценки. Не выполните раздел "Очистка ресурсов " предыдущей процедуры.
Вам понадобятся следующие сведения о ресурсах Azure из этого развертывания, которые в этой статье называются приложением чата.
- URI API чата: конечная точка серверной части службы, показанная в конце
azd upпроцесса. - Поиск по искусственному интеллекту Azure. Требуются следующие значения:
- Имя ресурса: имя ресурса Поиск с использованием ИИ Azure, указанное как
Search serviceв ходе процессаazd up. - Имя индекса: имя индекса поиска ИИ Azure, в котором хранятся документы. Имя индекса можно найти на портале Azure для службы поиска.
- Имя ресурса: имя ресурса Поиск с использованием ИИ Azure, указанное как
URL-адрес Chat API позволяет оценкам отправлять запросы через ваше бэкенд-приложение. Сведения о службе Поиск с использованием ИИ Azure позволяют скриптам оценки использовать то же развертывание, что и серверная часть, в которое загружены документы.
После сбора этих сведений вам не нужно снова использовать среду разработки приложений чата . В этой статье несколько раз упоминается приложение чата, чтобы показать, как его использует приложение оценки. Не удаляйте ресурсы приложения чата , пока не завершите все действия, описанные в этой статье.
- URI API чата: конечная точка серверной части службы, показанная в конце
Среда контейнера разработки доступна со всеми зависимостями, необходимыми для выполнения этой статьи. Контейнер разработки можно запустить в GitHub Codespaces (в браузере) или локально с помощью Visual Studio Code.
- учетная запись GitHub;
Открытие среды разработки
Следуйте этим инструкциям, чтобы настроить предварительно настроенную среду разработки со всеми необходимыми зависимостями для выполнения этой статьи. Упорядочение рабочей области монитора, чтобы вы могли просматривать эту документацию и среду разработки одновременно.
Эта статья была протестирована с использованием региона switzerlandnorth для оценочного развертывания.
GitHub Codespaces запускает контейнер разработки под управлением GitHub, используя Visual Studio Code для браузера в качестве пользовательского интерфейса. Используйте пространства Кода GitHub для самой простой среды разработки. Он поставляется с правильными средствами разработчика и зависимостями, предварительно установленными для выполнения этой статьи.
Внимание
Все учетные записи GitHub могут использовать GitHub Codespaces бесплатно до 60 часов в месяц, используя два экземпляра с двумя процессорными ядрами. Дополнительные сведения см. в GitHub Codespaces: ежемесячно включенные объем хранилища и часы использования ядра.
Запустите процесс создания нового GitHub Codespace на ветви
mainв репозитории GitHub Azure-Samples/ai-rag-chat-evaluator.Чтобы отобразить среду разработки и документацию, доступные одновременно, щелкните правой кнопкой мыши следующую кнопку и выберите Открыть ссылку в новом окне.

На странице Создание пространства кода просмотрите параметры конфигурации пространства кода, а затем выберите Создать новое пространство кода.
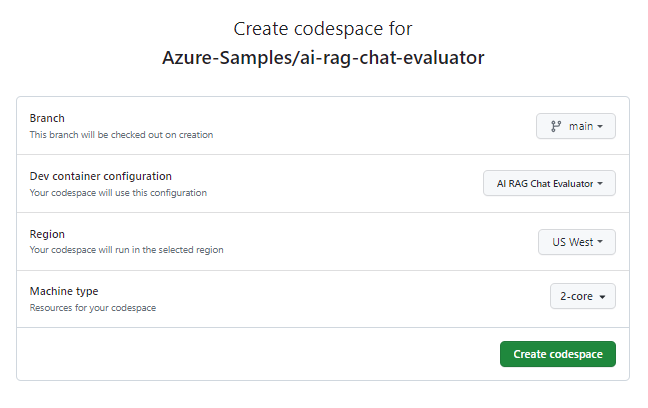
Дождитесь запуска кодспейса. Этот процесс запуска может занять несколько минут.
В терминале в нижней части экрана войдите в Azure с помощью Интерфейса командной строки разработчика Azure:
azd auth login --use-device-codeСкопируйте код из терминала и вставьте его в браузер. Следуйте инструкциям по проверке подлинности с помощью учетной записи Azure.
Подготовьте необходимый ресурс Azure, Службу Azure OpenAI для приложения для оценки:
azd upЭта команда
AZDне развертывает приложение для оценки, но создает ресурс Azure OpenAI с обязательным развертываниемGPT-4для выполнения вычислений в локальной среде разработки.
Остальные задачи в этой статье выполняются в контексте этого контейнера разработки.
Имя репозитория GitHub отображается в строке поиска. Этот визуальный индикатор помогает различать приложение оценки от приложения чата. В этой статье репозиторий ai-rag-chat-evaluator называется приложением для оценки .

Подготовка значений среды и сведений о конфигурации
Обновите значения среды и сведения о конфигурации, используя информацию, собранную во время подготовки требований для приложения оценок.
Создайте файл
.envна основе.env.sample.cp .env.sample .envВыполните эту команду, чтобы получить необходимые значения для
AZURE_OPENAI_EVAL_DEPLOYMENTиAZURE_OPENAI_SERVICEиз развернутой группы ресурсов. Вставьте эти значения в файл.env.azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICEДобавьте следующие значения из приложения чата для своего экземпляра службы поиска ИИ Azure в файл
.env, который вы собрали в разделе Предварительные требования.AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
Использование протокола чата Microsoft AI для сведений о конфигурации
Приложение чата и приложение оценки реализуют спецификацию протокола Microsoft AI Chat, открытый исходный код, облачный и не зависящий от языка конечный API ИИ, используемый для обработки и оценки. Если клиентские и средние конечные точки соответствуют данной спецификации API, вы можете последовательно работать с и проводить оценки на серверных системах ИИ.
Создайте файл с именем
my_config.jsonи скопируйте в него следующее содержимое:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }Скрипт оценки создает папку
my_results.Объект
overridesсодержит все параметры конфигурации, необходимые для приложения. Каждое приложение определяет собственный набор свойств параметров.Используйте следующую таблицу, чтобы понять смысл свойств параметров, которые отправляются в приложение чата.
Свойство настройки Описание semantic_rankerСледует ли использовать семантический рангировщик, модель, которая повторно выполняет результаты поиска на основе семантического сходства с запросом пользователя. Мы отключаем его для этого руководства, чтобы сократить затраты. retrieval_modeИспользуемый режим извлечения. Значение по умолчанию — hybrid.temperatureПараметр температуры для модели. Значение по умолчанию — 0.3.topКоличество возвращаемых результатов поиска. Значение по умолчанию — 3.prompt_templateПереопределение промпта, используемого для генерации ответа на основе вопроса и результатов поиска. seedНачальное значение для любых запросов к моделям GPT. Задание начального значения приводит к более согласованным результатам в оценках. Измените значение
target_urlна значение URI приложения чата, которое вы собрали в разделе Предварительные требования. Приложение чата должно соответствовать протоколу чата. Универсальный код ресурса (URI) имеет следующий формат:https://CHAT-APP-URL/chat. Убедитесь, что протокол иchatмаршрут являются частью URI.
Создание примера данных
Чтобы оценить новые ответы, их необходимо сравнить с эталонным ответом, который является идеальным для конкретного вопроса. Создайте вопросы и ответы из документов, хранящихся в службе "Поиск ИИ Azure" для приложения чата.
Скопируйте папку
example_inputв новую папку с именемmy_input.В терминале выполните следующую команду, чтобы создать примеры данных:
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
Пары вопросов и ответов создаются и хранятся в my_input/qa.jsonl (в формате JSONL) в качестве входных данных для вычислителя, используемого на следующем шаге. Для оценки производительности вы создадите больше пар вопросов и ответов. Для этого набора данных генерируется более 200 элементов.
Примечание.
Для источника генерируется только несколько вопросов и ответов, чтобы вы могли быстро завершить этот процесс. Она не должна быть рабочей оценкой, которая должна иметь больше вопросов и ответов на источник.
Запустите первую оценку с уточненным запросом
Измените свойства файла конфигурации
my_config.json.Свойство Новое значение results_dirmy_results/experiment_refinedprompt_template<READFILE>my_input/prompt_refined.txtУточнённый запрос чётко указывает предметную область.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers, ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information, return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by a colon and the actual information. Always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].В терминале выполните следующую команду, чтобы выполнить оценку:
python -m evaltools evaluate --config=my_config.json --numquestions=14Этот скрипт создал новую папку эксперимента в
my_results/с оценкой. Папка содержит результаты оценки.Имя файла Описание config.jsonКопия файла конфигурации, используемого для оценки. evaluate_parameters.jsonПараметры, используемые для оценки. Аналогично config.json, но включает другие метаданные, такие как метка времени.eval_results.jsonlКаждый вопрос и ответ, а также метрики GPT для каждой пары вопросов и ответов. summary.jsonОбщие результаты, например средние метрики GPT.
Запустите вторую оценку с слабым подсказкой
Измените свойства файла конфигурации
my_config.json.Свойство Новое значение results_dirmy_results/experiment_weakprompt_template<READFILE>my_input/prompt_weak.txtЭтот слабый запрос не имеет контекста в предметной области.
You are a helpful assistant.В терминале выполните следующую команду, чтобы выполнить оценку:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Запустите третье испытание с определенной температурой
Используйте запрос, который оставляет больше пространства для творчества.
Измените свойства файла конфигурации
my_config.json.Существующий Свойство Новое значение Существующий results_dirmy_results/experiment_ignoresources_temp09Существующий prompt_template<READFILE>my_input/prompt_ignoresources.txtНовый temperature0.9Значение по умолчанию
temperature— 0.7. Чем выше температура, тем более творческие ответы.Запрос
ignoreявляется коротким.Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!Объект конфигурации должен выглядеть, как в следующем примере, за исключением того, что вы заменили
results_dirна ваш путь.{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }В терминале выполните следующую команду, чтобы выполнить оценку:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Проверить результаты оценки
Вы выполнили три оценки на основе различных запросов и параметров приложения. Результаты хранятся в папке my_results . Проверьте, как результаты отличаются в зависимости от параметров.
Используйте средство проверки, чтобы просмотреть результаты оценки.
python -m evaltools summary my_resultsРезультаты выглядят примерно так:

Каждое значение возвращается в виде числа и процента.
Используйте следующую таблицу, чтобы понять смысл значений.
значение Описание Заземленность Проверяет, насколько хорошо ответы модели основаны на фактических, проверяемых данных. Ответ считается обоснованным, если это фактически точно и отражает реальность. Релевантность Измеряет, насколько точно ответы модели соответствуют контексту или запросу. Соответствующий ответ напрямую обращается к запросу или инструкции пользователя. Согласованность Проверяет, насколько логически согласованы ответы модели. Последовательный ответ поддерживает логический поток и не противоречит самому себе. Цитирование Указывает, был ли ответ возвращен в формате, запрошенном в запросе. Длина Измеряет длину ответа. Результаты должны указывать на то, что все три оценки имеют высокую релевантность, в то время как
experiment_ignoresources_temp09имеет самую низкую релевантность.Выберите папку, чтобы просмотреть конфигурацию для оценки.
Введите CTRL + C, чтобы выйти из приложения и вернуться в терминал.
Сравнение ответов
Сравните ответы, полученные в ходе оценок.
Выберите две оценки для сравнения, а затем используйте один и тот же инструмент проверки для сравнения ответов.
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Проверка результатов. Результаты могут отличаться.

Введите CTRL + C, чтобы выйти из приложения и вернуться в терминал.
Рекомендации по дальнейшей оценке
- Измените подсказки в
my_input, чтобы настроить ответы с учётом таких параметров, как предметная область, длина и другие факторы. - Измените
my_config.jsonфайл, чтобы изменить такие параметры, какtemperature, иsemantic_rankerповторно запустить эксперименты. - Сравните различные ответы, чтобы понять, как запрос и вопрос влияют на качество ответа.
- Создайте отдельный набор вопросов и правильных ответов для каждого документа в индексе поиска Azure AI. Затем повторно запустите оценки, чтобы узнать, как отличаются ответы.
- Измените запросы, чтобы указать более короткие или более длинные ответы, добавив требование в конец запроса. Примером является
Please answer in about 3 sentences.
Очистка ресурсов и зависимостей
В следующих шагах описан процесс очистки используемых ресурсов.
Очистка ресурсов Azure
Ресурсы Azure, созданные в этой статье, оплачиваются в рамках вашей подписки Azure. Если вы не ожидаете, что эти ресурсы потребуются в будущем, удалите их, чтобы избежать дополнительных расходов.
Чтобы удалить ресурсы Azure и удалить исходный код, выполните следующую команду Azure Developer CLI:
azd down --purge
Очистка GitHub Codespaces и Visual Studio Code
Удаление среды GitHub Codespaces гарантирует, что вы можете максимально увеличить объем бесплатных прав на базовые часы, которые вы получаете для вашей учетной записи.
Внимание
Дополнительные сведения о правах вашей учетной записи GitHub см. в статье Ежемесячно включенные объем хранилища и часы использования ядер в GitHub Codespaces.
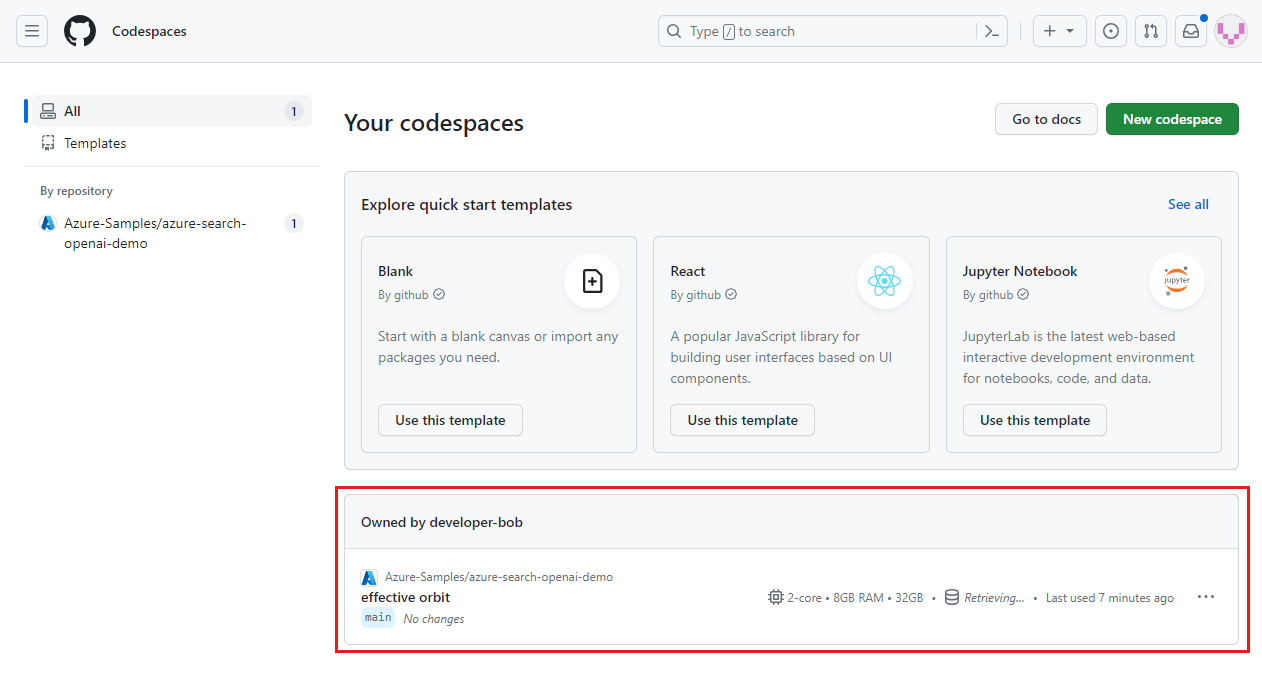
Войдите на панель мониторингаGitHub Codespaces.
Найдите ваши запущенные Codespaces, полученные из репозитория Azure-Samples/ai-rag-chat-evaluator на GitHub.
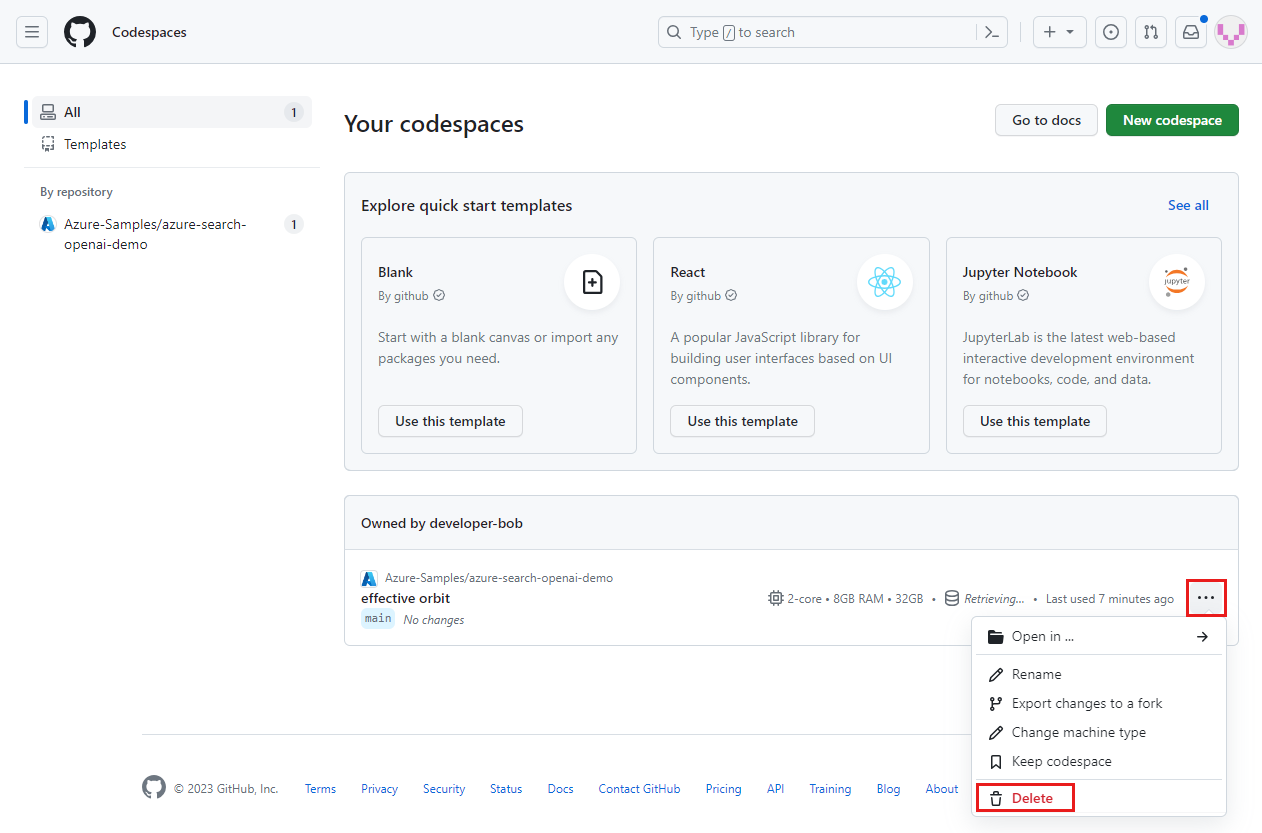
Откройте контекстное меню для пространства кода, а затем выберите Удалить.
Вернитесь в статью о приложении чата, чтобы очистить эти ресурсы.
Связанное содержимое
- См. репозиторий оценок .
- Смотрите репозиторий GitHub корпоративного чата .
- Создайте чат-приложение с архитектурой решения Azure OpenAI, основанной на лучших практиках.
- Узнайте о управлении доступом в приложениях генеративного ИИ с Поиск с использованием ИИ Azure.
- Создайте корпоративное решение Azure OpenAI готовое для использования на предприятии, с помощьюсистемы управления API Azure.
- См. Поиск с использованием ИИ Azure: превосходящий векторный поиск благодаря гибридным возможностям извлечения и ранжирования.