Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Azure DevOps Services | Azure DevOps Server 2022 — Azure DevOps Server 2019
С помощью накопительных схем потоков (CFD) можно отслеживать поток работы системы. Время цикла и время выполнения являются двумя основными метриками, которые используются для отслеживания. Эти метрики можно извлечь из CFD.
В этой статье показано, как использовать CFD, время цикла и время выполнения, чтобы определить проблемы в рабочем процессе и помочь вам перемещать работу через систему.
- Чтобы настроить или просмотреть накопительную схему потока, см. Просмотр и настройка накопительной схемы потока.
- Сведения о добавлении диаграммы управления опережением и циклами на панель мониторинга см. в виджетах времени цикла и времени выполнения.
Примеры диаграмм и основных метрик
Непрерывный поток CFD предоставляет диаграмму, которая наиболее предпочитаема командам, которые следуют процессу бережливого производства.
Однако многие команды объединяют бережливые практики с Scrum или другими методологиями. В результате они используют бережливые методики в пределах итерации или спринта. В этой ситуации схема приобретает немного иной вид. Он предоставляет два дополнительных и очень ценных фрагмента информации, как показано на следующей диаграмме фиксированного периода CFD.
Непрерывный поток CFD
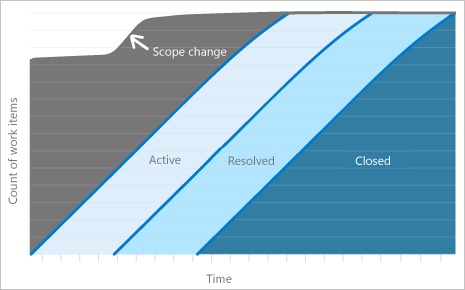
Этот фиксированный период CFS предназначен для завершенного спринта.
Верхняя строка представляет объем работ, установленный для спринта. Поскольку работа должна быть завершена к последнему дню спринта, наклон состояния 'Закрыто' указывает, идет ли команда по плану, чтобы завершить спринт. Самый простой способ представить это — как диаграмму выгорания.
На диаграмме первый шаг процесса отображается как верхняя левая область. Последний шаг процесса показан как область в правом нижнем углу.
Фиксированный период CFS для завершенного спринта
Метрики диаграммы
В CFD отображается количество рабочих элементов, сгруппированных по состоянию или столбцу с течением времени. Двумя основными метриками, которые используются для отслеживания, являются время цикла и время выполнения. Эти метрики можно извлечь из диаграммы.
Метрика
Определение
Время цикла1
Время, необходимое для прохождения через один процесс или состояние рабочего процесса. Длина измеряется с начала одного процесса до начала следующего процесса.
Время выполнения1
Для процесса непрерывного потока: время выполнения запроса (например, добавление предлагаемой истории пользователя) до завершения этого запроса (закрыто).
Для процесса спринта или фиксированного периода: время от начала работы с запросом до завершения работы (например, время от активного до закрытого состояния).
Работа в процессе
Объем работы или количество рабочих элементов, над которыми активно работают.
Область применения
Объем работы, зафиксированной в течение заданного периода времени. Эта метрика применяется только к процессам фиксированного периода.
1 Виджет CFD, использующий данные аналитики, и встроенное CFD, которые можно просмотреть из командного невыполненного объема или доски, не предоставляют дискретные значения времени ожидания и времени цикла. Однако виджеты времени выполнения заказа и времени цикла предоставляют эти значения.
Существует четко определенная корреляция между временем выполнения или временем цикла и WIP. Больше НЗР приводит к более длительному времени цикла, что ведет к увеличению времени выполнения. Противоположное также верно — меньше незавершённой работы приводит к более короткому циклу и времени выполнения. Когда команда разработчиков фокусируется на меньшем количестве элементов, они сокращают цикл и время выполнения. Эта корреляция является ключевой причиной, по которой необходимо задать ограничения WIP на доске, используемой для отслеживания работы и управления ими.
Количество рабочих элементов указывает общий объем работы в течение заданного дня. В фиксированном периоде изменение в этом счётчике указывает на изменение области за указанный период. В непрерывном потоке CFD указывает общий объем работы, которая находится в очереди и завершена для данного дня.
Классификация работы по определенным столбцам доски показывает объем работы в каждой области процесса. Это представление предоставляет сведения о том, где работа идет гладко, где есть препятствия, и где работа не выполняется вовсе. Трудно расшифровать табличное представление данных. Тем не менее, визуальный CFD помогает понять, что происходит в рабочем процессе и почему.
Определение проблем и выполнение соответствующих действий
CFD предоставляет ответы на следующие вопросы. На основе ответов можно настроить процесс для перемещения работы через систему.
Будет ли команда выполнять работу вовремя?
Этот вопрос применяется только к фиксированным периодам CFD. Вы можете понять, взглянув на кривую (или прогрессию) работы в последнем столбце доски.
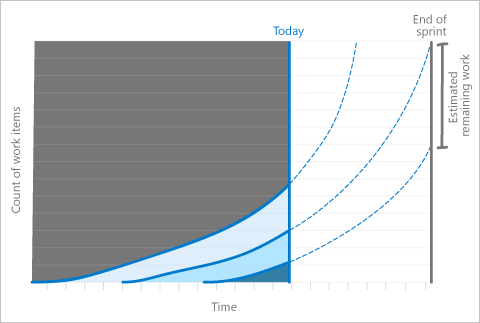
В этом сценарии можно рассмотреть возможность сокращения области работы в итерации. Это действие подходит, если ясно, что работа не завершена достаточно быстро, если она продолжается в стабильном темпе. Этот сценарий может указывать на то, что работа была недооценена и должна быть учтена в планировании следующего спринта.
Однако могут быть и другие причины, по которым работа не завершена достаточно быстро. Эти причины можно определить, просмотрев другие данные на диаграмме.
Как продвигается работа?
Работает ли команда в стабильном темпе? Один из способов это заметить — взглянуть на интервал между различными столбцами на диаграмме. Равномерно ли они расположены друг от друга от начала до конца? Кажется, что какие-либо столбцы остаются неизменными в течение нескольких дней? Или кажется, что что-нибудь выпукло?
Мура, или неравномерность, является худым термином для плоских линий и выпуклости. Mura указывает на форму отходов (Muda) в системе. Любая неравномерность в системе приводит к возникновению выпуклостей в CFD.
Мониторинг CFD для обнаружения ровных линий и выпуклостей поддерживает ключевую роль в процессе управления проектами в соответствии с Теорией ограничений. Защита самой медленной области системы называется процессом «барабан-буфер-веревка » и является частью планирования работы.
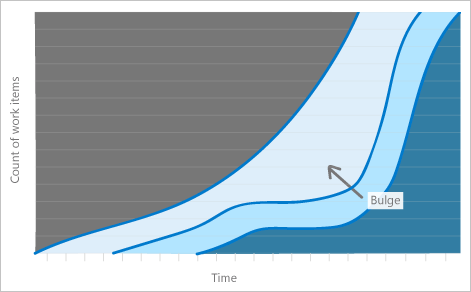
Две проблемы отображаются визуально как плоские линии и как выпуклости.
Неструктурированные линии отображаются, когда команда не обновляет состояние своих рабочих элементов с регулярной периодичностью.
Доска, используемая для отслеживания работы и управления ими, обеспечивает самый быстрый способ перехода работы из одного столбца в другой.
Неструктурированные линии также могут отображаться, когда работа в одном или нескольких процессах занимает больше времени, чем запланировано. Плоские линии появляются во многих частях системы, потому что если только одна или две части имеют проблемы, вы видите выпуклость.
Плоские линии
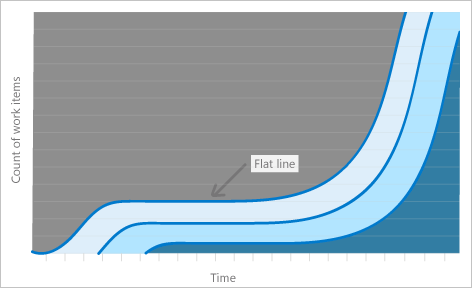
Заторы возникают, когда работа накапливается в одной части системы и не проходит через процесс.
Например, выпуклость может возникать, когда тестирование занимает много времени, а разработка — меньше. Результатом является то, что работа накапливается в состоянии разработки. Выпуклости указывают на то, что следующий шаг имеет проблему, не обязательно тот шаг, в котором выпуклость происходит.
Выпуклости
Как устранить проблемы с потоком?
Вы можете решить проблему нехватки своевременных обновлений, выполнив следующие действия:
- Проведение ежедневных совещаний
- Проведение других регулярных собраний
- Планирование ежедневного командного напоминания по электронной почте
Системные проблемы с плоской линией указывают на более сложную проблему, хотя такие проблемы редки. Горизонтальные линии указывают, что работа по всей системе остановлена. Основные причины могут включать следующие проблемы:
- Блоки на уровне процесса
- Процессы занимают много времени
- Переход на другие возможности, которые не отражаются на доске
Один из примеров системного застоя может возникнуть в расчетах CFD. Работа с функциями может занять значительно больше времени, чем работа над историями пользователей, так как функции состоят из нескольких историй. В таких ситуациях либо ожидается склон (как и в предыдущем примере), либо проблема хорошо известна, и команда уже подняла этот вопрос. Если это известная проблема, решение проблемы выходит за рамки этой статьи.
Команды могут упреждающе устранять проблемы, которые проявляются как выпуклости на CFD. Исправление, соответствующее, может зависеть от того, где происходит выпуклость. Например, предположим, что выпуклость возникает в процессе разработки. Задержка может быть вызвана тем, что тестирование занимает значительно больше времени, чем написание кода. Тестировщики также могут находить большое количество ошибок. При регулярном возвращении работы разработчикам они наследуют растущий список активных задач.
Существует два потенциально простых способа решения этой проблемы:
- Переместите разработчиков из процесса разработки в процесс тестирования, пока выпуклость не будет устранена.
- Изменение порядка работы. В частности, чередуйте работу, которую можно выполнить быстро, с работой, которая занимает больше времени.
Ищите простые решения для устранения выпуклостей.
Примечание.
Так как различные сценарии могут возникать, что приводит к неравномерной работе, важно выполнить фактический анализ проблемы. CFD способен указать вам, что имеется проблема. Он также может указать вам приблизительно, где проблема, но вам нужно исследовать вопрос, чтобы добраться до коренных причин. В этом руководстве приведены рекомендуемые действия, которые решают конкретные проблемы, но решения могут не применяться к вашей ситуации.
Изменилась ли область?
Изменения области применяются только к фиксированным периодам CFD. Верхняя строка диаграммы указывает область работы. В спринт заранее включается работа, которая должна быть выполнена в первый день. Изменения в верхней строке указывают на добавление или удаление работы.
В одном из конкретных сценариев невозможно отслеживать изменения области охвата с помощью CFD. Этот сценарий возникает при добавлении и удалении одного и того же количества рабочих элементов в тот же день. Линия остается плоской в этом случае.
Чтобы отслеживать изменения области в этом случае, выполните следующие действия:
- Сравните несколько диаграмм друг с другом.
- Отслеживайте конкретные проблемы.
- Используйте диаграмму сгорания спринта для отслеживания изменений объема.
Есть ли слишком много WIP?
Вы можете легко отслеживать доску, чтобы определить, превышаются ли ограничения на рабочие процессы (WIP). Вы также можете отслеживать уровни WIP с помощью CFD.
Большое количество незавершенной работы обычно отображается как вертикальная выпуклость. Чем дольше есть большой объем WIP, тем больше выпуклость расширяется в оваловую форму. Это поведение указывает на то, что незавершённое производство отрицательно влияет на цикл и время выполнения.
Вот хорошее практическое правило для WIP: не должно быть более двух задач в работе на одного члена команды в любой момент времени. Основная причина использования ограничения двух элементов, а не более строгого ограничения, заключается в том, что реальность часто встраивается в процесс разработки программного обеспечения.
Иногда требуется время, чтобы получить информацию от заинтересованных лиц или получить необходимое программное обеспечение. Существует любое количество причин, по которым можно остановить работу. Наличие второго рабочего элемента, на который можно переключиться, даёт некоторую свободу действий. Если оба элемента блокируются, пришло время вызвать красный флаг, чтобы получить что-то разблокированное, а не просто переключиться на еще один элемент. Как только выполняется большое количество элементов, пользователь, работающий над этими элементами, может иметь трудности с переключением контекста. Скорее всего, они забыли, что они делают, что может привести к ошибкам.
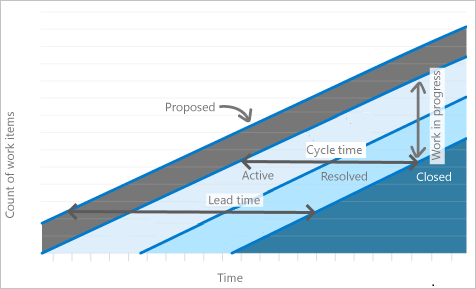
Время выполнения заказа и время цикла
На следующей схеме показано, как время выполнения отличается от времени цикла. Время выполнения начинается, когда рабочий элемент создается и заканчивается, когда рабочий элемент входит в категорию состояния "Завершено". Время цикла начинается, когда рабочий элемент сначала вводит категорию состояния "Ход выполнения" или "Разрешено". Время цикла заканчивается, когда рабочий элемент вводит категорию состояния "Завершено".
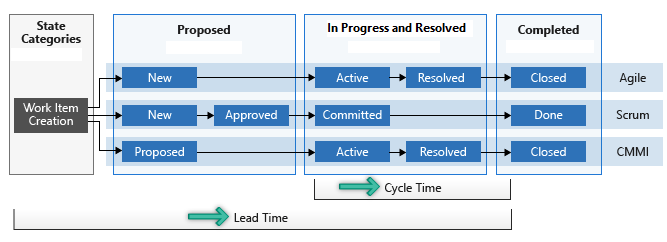
Если рабочий элемент входит в категорию состояния "Завершено", а затем активируется повторно, это влияет на время его выполнения и цикла. Любое дополнительное время, которое тратится в категории состояния 'Предлагается', 'В работе' или 'Разрешено', способствует сроку выполнения и времени цикла.
Если ваша команда использует доску для отслеживания работы и управления ими, она помогает понять, как столбцы сопоставляются с состояниями рабочего процесса. Дополнительные сведения о настройке доски см. в разделе "Управление столбцами" на доске.
Дополнительные сведения о том, как система использует категории состояний — предлагаемые, выполняемые, разрешенные и завершенные— см. в разделе "Сведения о состояниях рабочих процессов в невыполненных работах и досках".
Оценка сроков доставки на основе времени выполнения и времени цикла
Вы можете использовать ваше среднее время выполнения заказа и цикловое время, а также стандартные отклонения, чтобы оценить время доставки.
При создании рабочего элемента можно использовать среднее время выполнения команды для оценки даты завершения этого рабочего элемента. Стандартное отклонение вашей команды указывает на изменчивость оценки. Аналогичным образом можно использовать время цикла и его стандартное отклонение для оценки завершения рабочего элемента после начала работы.
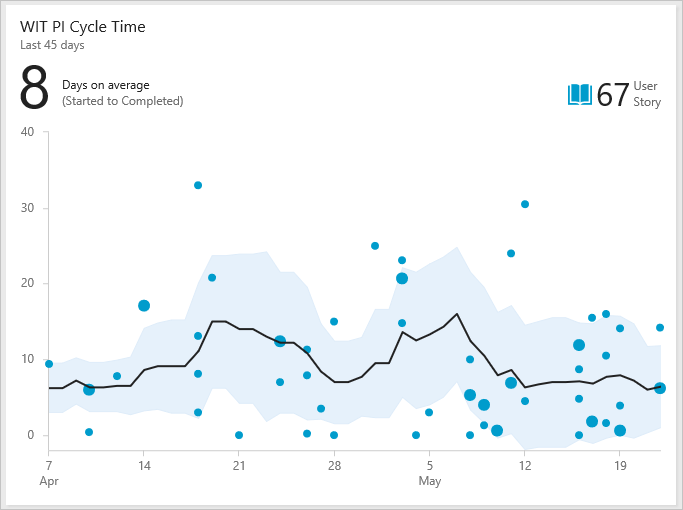
Пример виджета "Время цикла"
На следующей диаграмме среднее время цикла составляет восемь дней. Стандартное отклонение составляет шесть дней. С помощью этих данных можно оценить, что команда завершает будущие истории пользователей около 2–14 дней после начала работы. Чем уже стандартное отклонение, тем более прогнозируемы ваши оценки.
Определение проблем с процессом
Аномалии часто указывают на проблему основного процесса. Примеры включают слишком долгое время, чтобы просмотреть запросы на вытягивание или быстро не разрешать внешнюю зависимость. Просмотрите контрольную диаграмму вашей команды на предмет аномалий.
Пример виджета "Время цикла", показывающего несколько аномалий
На следующей диаграмме показано несколько выпадающих, так как для завершения нескольких ошибок потребовалось больше времени, чем среднее. Изучение того, почему эти ошибки заняли больше времени, могут помочь выявить проблемы с процессом. Устранение проблем с процессом может помочь уменьшить стандартное отклонение вашей команды и улучшить прогнозируемость вашей команды.
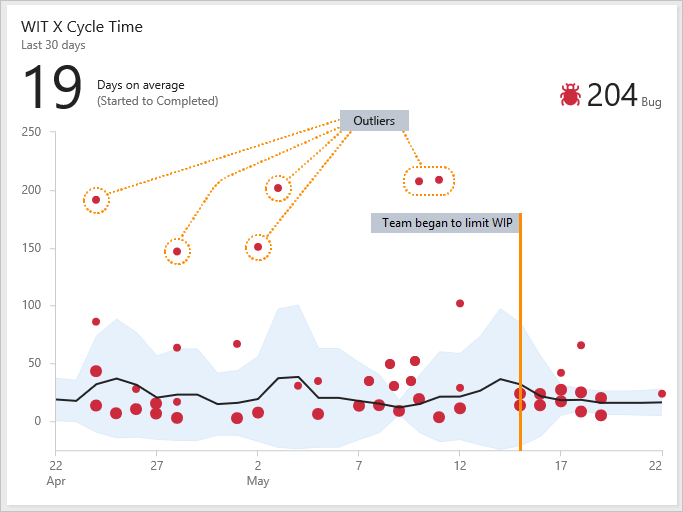
Вы также можете увидеть, как изменения в процессе влияют на время выполнения и время цикла. Например, 15 мая команда предприняла согласованные усилия, чтобы ограничить WIP и устранить устаревшие ошибки. Вы можете увидеть, что стандартное отклонение сужается после этой даты, показывая улучшенную прогнозируемость.