Архитектура обеспечения непрерывности бизнес-процессов в Azure HDInsight
В статье приведены несколько примеров архитектуры обеспечения непрерывности бизнес-процессов, которые можно использовать для Azure HDInsight. Устойчивость к ограничению функциональных возможностей в аварийной ситуации — это бизнес-решение, которое варьируется в зависимости от приложения. Решение может применяться для некоторых приложений, которые будут недоступны или частично доступны с ограниченной функциональностью или отложенной обработкой в течение определенного периода. Для других приложений любое ограничение функциональности может быть неприемлемым.
Примечание.
Варианты архитектуры, представленные в этой статье, не являются исчерпывающими. Вам следует разработать собственные уникальные варианты архитектуры после объективного определения ожидаемого периода непрерывности бизнес-процессов, сложности эксплуатации и стоимости владения.
Apache Hive и Interactive Query
Для обеспечения непрерывности бизнес-процессов в кластерах HDInsight и Interactive Query рекомендуется использовать репликацию Hive версии 2. Постоянные разделы автономного кластера Hive, которые необходимо реплицировать, — это уровень хранения и хранилище метаданных Hive. Кластеры Hive в многопользовательском сценарии с корпоративным пакетом безопасности нуждаются в доменных службах Microsoft Entra и хранилище метаданных Ranger.
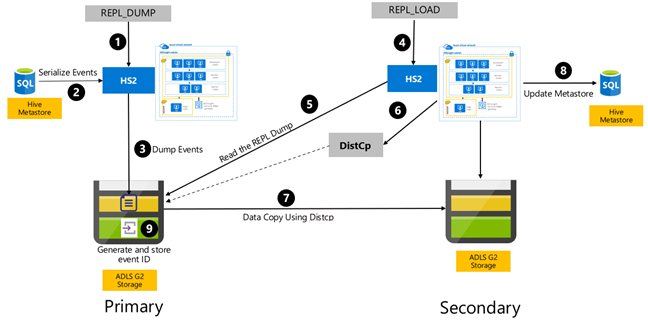
Репликация Hive на основе событий настраивается между основным и дополнительным кластерами. Этот процесс состоит из двух отдельных фаз — начальная загрузка и инкрементные запуски.
При начальной загрузке выполняется репликация всего хранилища метаданных Hive, включая сведения о хранилище метаданных Hive, от основного до дополнительного.
Инкрементные запуски выполняются автоматически в основном кластере, а события, сгенерированные при инкрементных запусках, воспроизводятся в дополнительном кластере. Дополнительный кластер перехватывает события, сгенерированные в основном кластере, обеспечивая согласованность дополнительного кластера с событиями основного кластера после выполнения репликации.
Дополнительный кластер необходим только в процессе репликации для запуска распределенной копии, DistCp однако хранилище и метахранилища должны быть постоянными. Можно выбрать запуск сценария дополнительного кластера по запросу перед репликацией, запустить на нем сценарий репликации и удалить его после успешной репликации.
Как правило, дополнительный кластер доступен только для чтения. Можно разрешить операции чтения и записи для дополнительного кластера, но это усложняет процесс из-за репликации изменений из дополнительного кластера в основной.
RPO и RTO для репликации Hive на основе событий
RPO: потери данных ограничиваются до последнего успешного события инкрементной репликации из основного в дополнительный кластер.
RTO: время между отказом и возобновлением вышестоящей и подчиненной транзакций с дополнительным кластером.
Варианты архитектуры кластеров Hive и Interactive Query
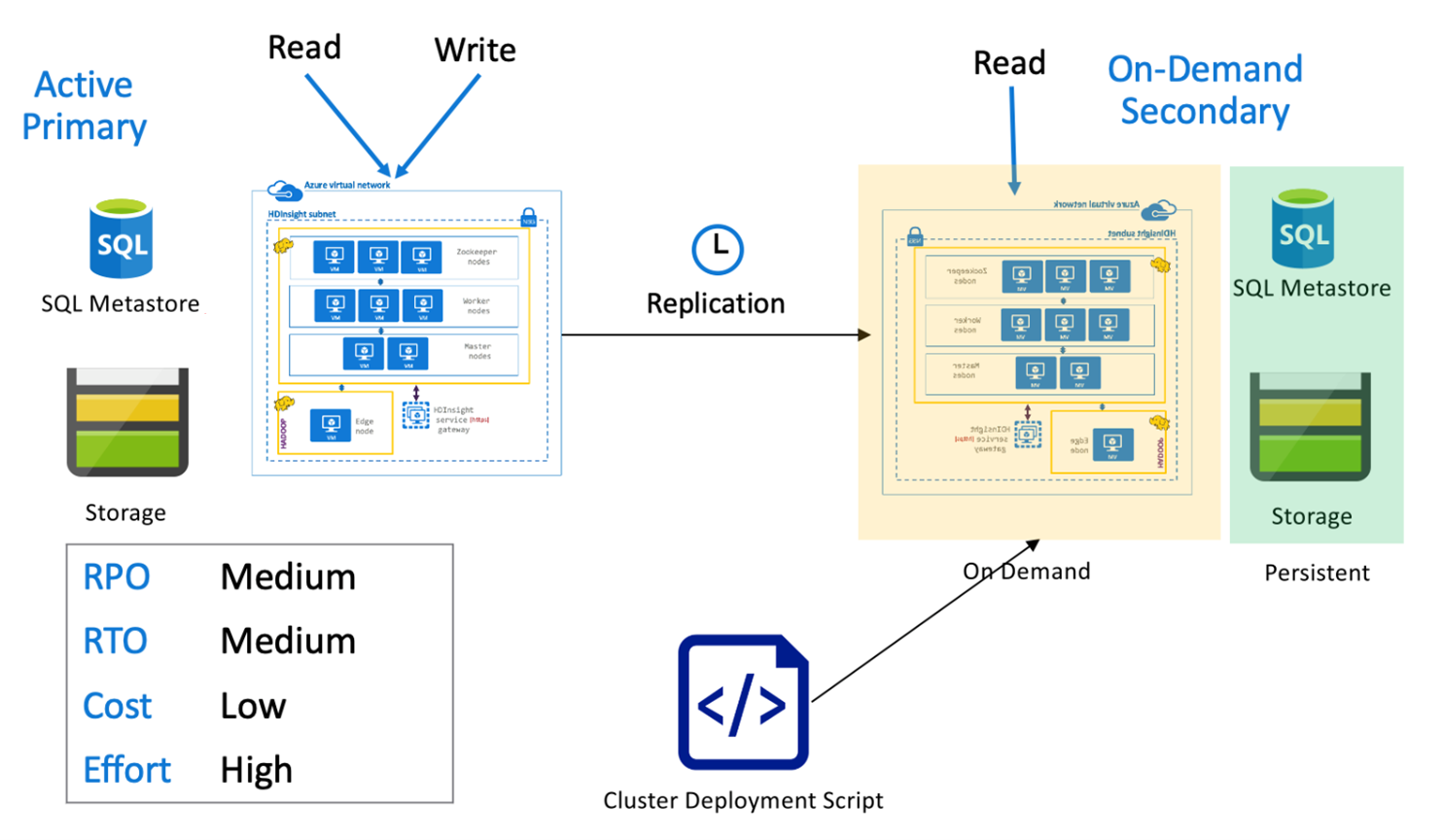
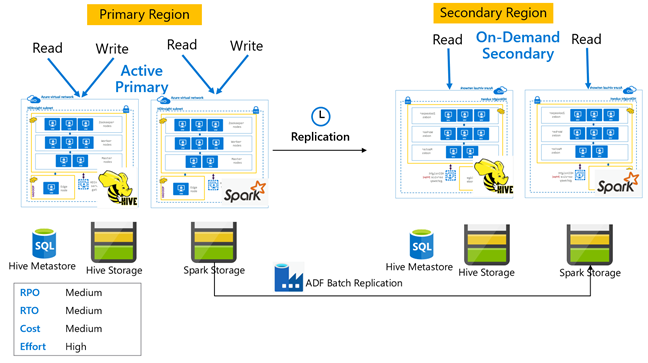
Активный основной кластер Hive с дополнительным кластером по запросу
В варианте архитектуры "активный основной кластер с дополнительным кластером по запросу" приложения записывают данные в активный основной регион, при этом в процессе нормального функционирования в дополнительном регионе не создается кластер. Хранилище метаданных SQL и хранилище в дополнительном регионе являются постоянными, а кластер HDInsight создается по сценарию и развертывается только по запросу до запуска запланированной репликации Hive.
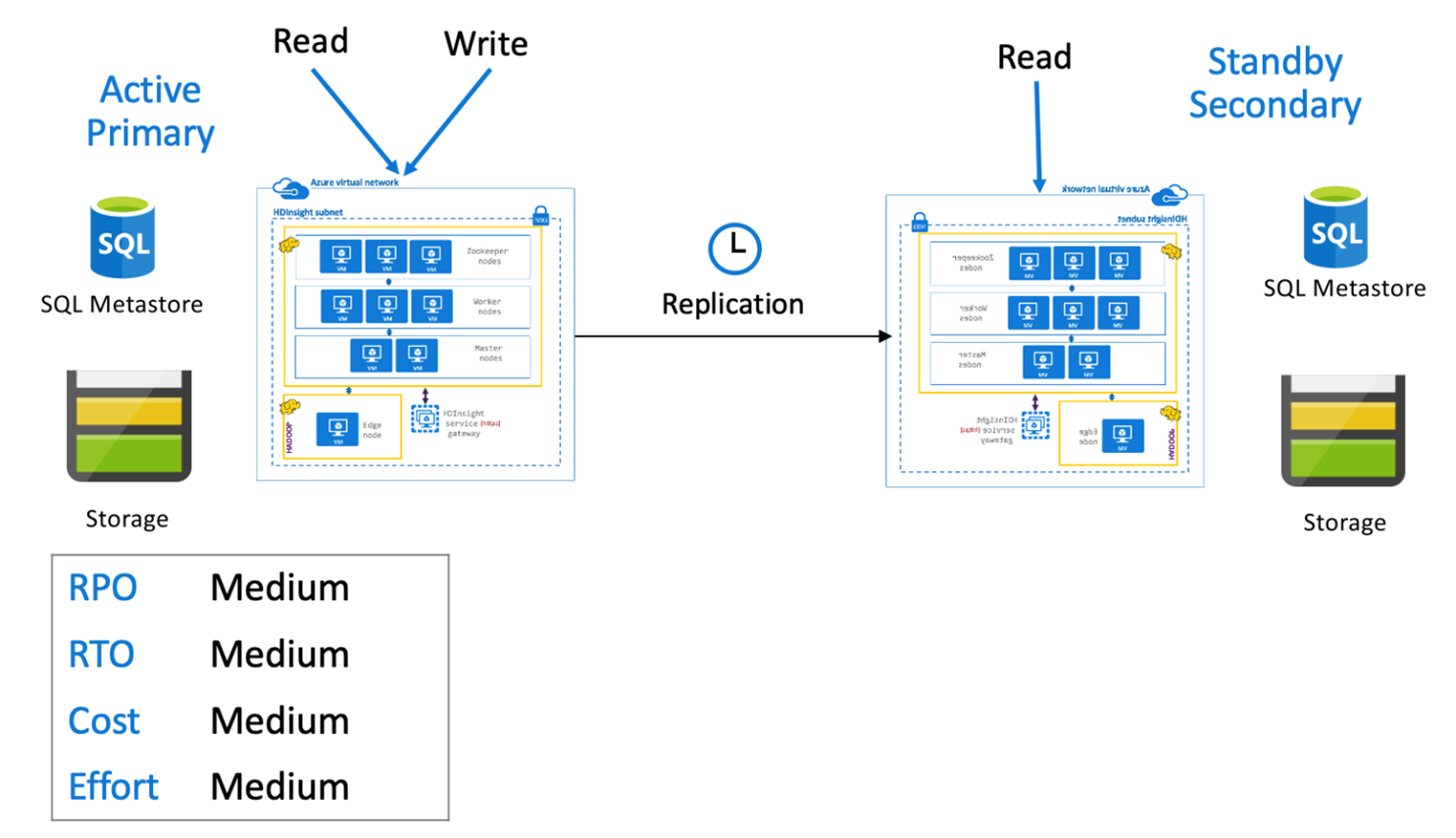
Активный основной кластер Hive с резервным дополнительным кластером
В варианте активный основной кластер с резервным дополнительным кластером приложения записывают данные в активный основной регион, при этом в процессе нормального функционирования резервный дополнительный кластер уменьшенного объема действует в режиме только для чтения. В режиме нормального функционирования можно перенести операции чтения, относящиеся к региону, в дополнительный кластер.
Дополнительные сведения о репликации Hive и примерах кода см. в статье Репликация Apache Hive в кластерах Azure HDInsight.
Apache Spark
Рабочие нагрузки Spark могут включать или не включать компонент Hive. Чтобы обеспечить чтение и запись данных из Hive для рабочих нагрузок SQL Spark, кластеры HDInsight Spark совместно используют настраиваемые метахранилища из кластеров Hive и Interactive Query в одном регионе. В таких сценариях репликация между регионами для рабочих нагрузок Spark также должна сопровождаться репликацией метахранилищ Hive и хранилища. Сценарии отработки отказа, представленные в этом разделе, относятся к обоим вариантам.
- Настройка SQL Spark для таблиц ACID, использующих Hive Warehouse Connector (HWC) с помощью кластера Interactive Query в HDInsight.
- Рабочая нагрузка SQL Spark в таблицах без ACID с помощью кластера HDInsight Hadoop.
В сценариях, в которых Spark работает в автономном режиме, курируемые данные и хранимые Jar-файлы Spark (для заданий Livy) необходимо регулярно реплицировать из основного региона в дополнительный с помощью команды DistCP Фабрики данных Azure.
Рекомендуем использовать системы управления версиями для хранения записных книжек и библиотек Spark, где их можно с легкостью развернуть в основных или дополнительных кластерах. Убедитесь, что решения с записными книжками и без них подготовлены к загрузке подключений корректных данных в основной или дополнительной рабочей области.
Если имеются клиентские библиотеки, не относящиеся к ресурсам, которые HDInsight предоставляет изначально, их необходимо отслеживать и периодически загружать в резервный дополнительный кластер.
RPO и RTO для репликации Apache Spark
RPO: потери данных ограничиваются до последней успешной инкрементной репликации (Spark и Hive) из основного в дополнительный кластер.
RTO: время между отказом и возобновлением вышестоящей и подчиненной транзакций с дополнительным кластером.
Варианты архитектуры Apache Spark
Активный основной кластер Spark с дополнительным кластером по запросу
Приложения выполняют чтение и запись в кластеры Spark и Hive в основном регионе, при этом в процессе нормального функционирования в дополнительном регионе не подготавливаются кластеры. Хранилище метаданных SQL, хранилище Hive и хранилище Spark в дополнительном регионе являются постоянными. Кластеры Spark и Hive создаются по сценарию и развертываются по требованию. Репликация Hive используется для репликации хранилища Hive и метахранилищ Hive, при этом команду DistCP Фабрики данных Azure можно использовать для копирования автономного хранилища Spark. Кластеры Hive необходимо развертывать перед каждым запуском репликации Hive из-за зависимости вычислений DistCp.
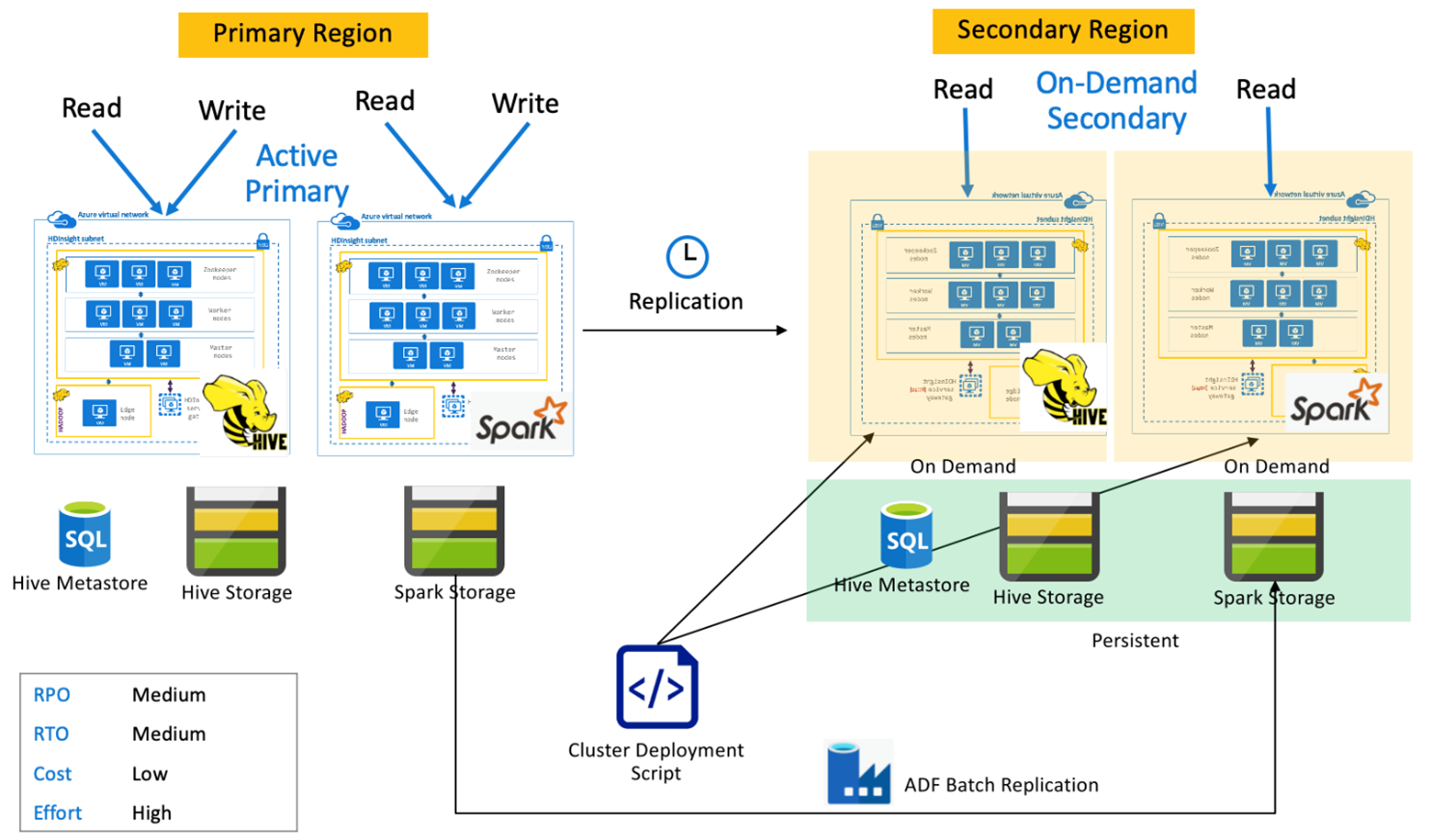
Активный основной кластер Spark с резервным дополнительным кластером
Приложения выполняют операции чтения и записи в кластерах Spark и Hive в основном регионе, при этом в процессе нормального функционирования кластеры Hive и Spark уменьшенного объема действуют в режиме только для чтения в дополнительном регионе. В режиме нормального функционирования можно перенести операции чтения Hive и Spark, относящиеся к региону, в дополнительный кластер.
Apache HBase
Экспорт HBase и репликация HBase — это распространенные способы обеспечения непрерывности бизнес-процессов между кластерами HDInsight HBase.
Экспорт HBase — это процесс пакетной репликации, использующий служебную программу экспорта HBase для экспорта таблиц из основного кластера HBase в базовое хранилище Azure Data Lake Storage 2-го поколения. После этого можно получить доступ к экспортированным данным из дополнительного кластера HBase и импортировать их в таблицы, которые уже должны быть созданы в дополнительном кластере. Хотя при экспорте HBase действительно предлагается детализация на уровне таблицы, в ситуациях инкрементного обновления модуль автоматизации экспорта управляет диапазоном инкрементных записей, включаемых в каждый запуск. Дополнительные сведения см. в статье Резервное копирование и репликация для HDInsight HBase.
Функция репликации HBase использует полностью автоматизированную репликацию между кластерами HBase почти в реальном времени. Репликация выполняется на уровне таблицы. Репликация может выполняться для всех или для конкретных таблиц. В итоге, репликация HBase является согласованной, а это означает, что недавние изменения в таблице в основном регионе могут быть недоступны для всех баз дополнительных регионов сразу. Со временем дополнительные регионы гарантированно будут согласованы с основным регионом. Репликацию HBase можно настроить между двумя или несколькими кластерами HDInsight HBase в случаях, описанных ниже.
- Основной и дополнительный кластеры находятся в одной виртуальной сети.
- Основной и дополнительный кластеры находятся в разных одноранговых виртуальных сетях в одном регионе.
- Основной и дополнительный кластеры находятся в разных одноранговых виртуальных сетях в разных регионах.
Дополнительные сведения см. в статье Настройка репликации кластеров Apache HBase в виртуальных сетях Azure.
Существует несколько других способов выполнения резервного копирования кластеров HBase, например копирование папки HBase, копирование таблиц и моментальных снимков.
RPO и RTO для HBase
Экспорт HBase
- RPO: потери данных ограничиваются до последнего успешного инкрементного импорта дополнительным кластером из основного.
- RTO: время между отказом основного кластера и восстановлением операций ввода-вывода в дополнительном кластере.
Репликация HBase
- RPO: потери данных ограничиваются до последней доставки WalEdit, полученной дополнительным кластером.
- RTO: время между отказом основного кластера и восстановлением операций ввода-вывода в дополнительном кластере.
Варианты архитектуры HBase
Репликацию HBase можно настроить в трех режимах: "ведущий-ведомый", "ведущий-ведущий" и "циклический".
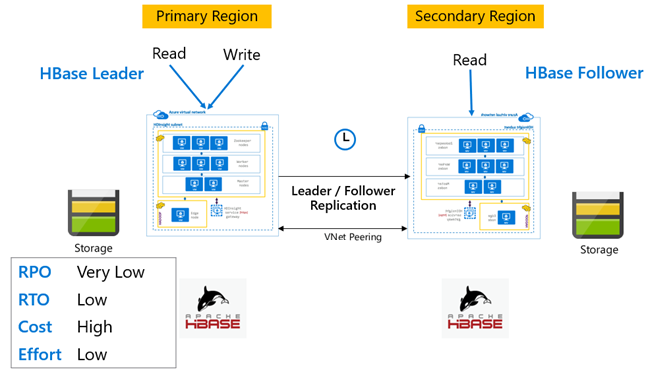
Репликация HBase. Модель «ведущий-ведомый»
В этой межрегиональной настройке репликация выполняется в одном направлении — из основного региона в дополнительный. Для однонаправленной репликации можно определить все таблицы или отдельные таблицы в основном кластере. При нормальном функционировании дополнительный кластер можно использовать для обслуживания запросов на чтение в собственном регионе.
Дополнительный кластер функционирует как обычный кластер HBase, который может размещать собственные таблицы и обслуживать операции чтения и записи из региональных приложений. Однако операции записи в реплицированных таблицах или таблицах, относящихся к дополнительному кластеру, не реплицируются в обратном направлении в основной кластер.
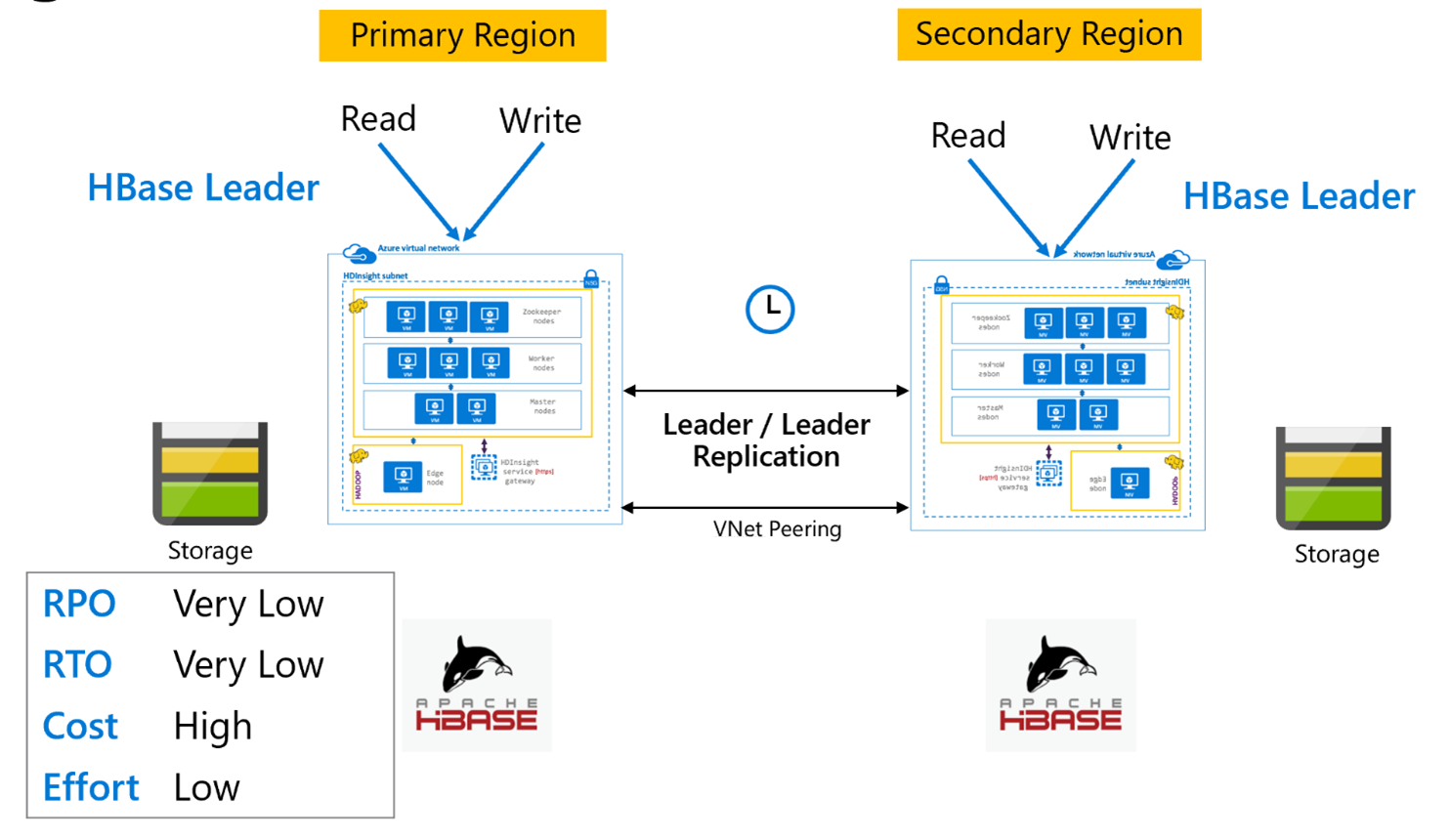
Репликация HBase. Модель «ведущий-ведущий»
Эта межрегиональная настройка очень похожа на однонаправленную, за исключением того, что репликация между основным и дополнительным регионом выполняется в обоих направлениях. Приложения могут использовать оба кластера в режиме чтения и записи, а обмен обновлений между ними выполняется асинхронно.
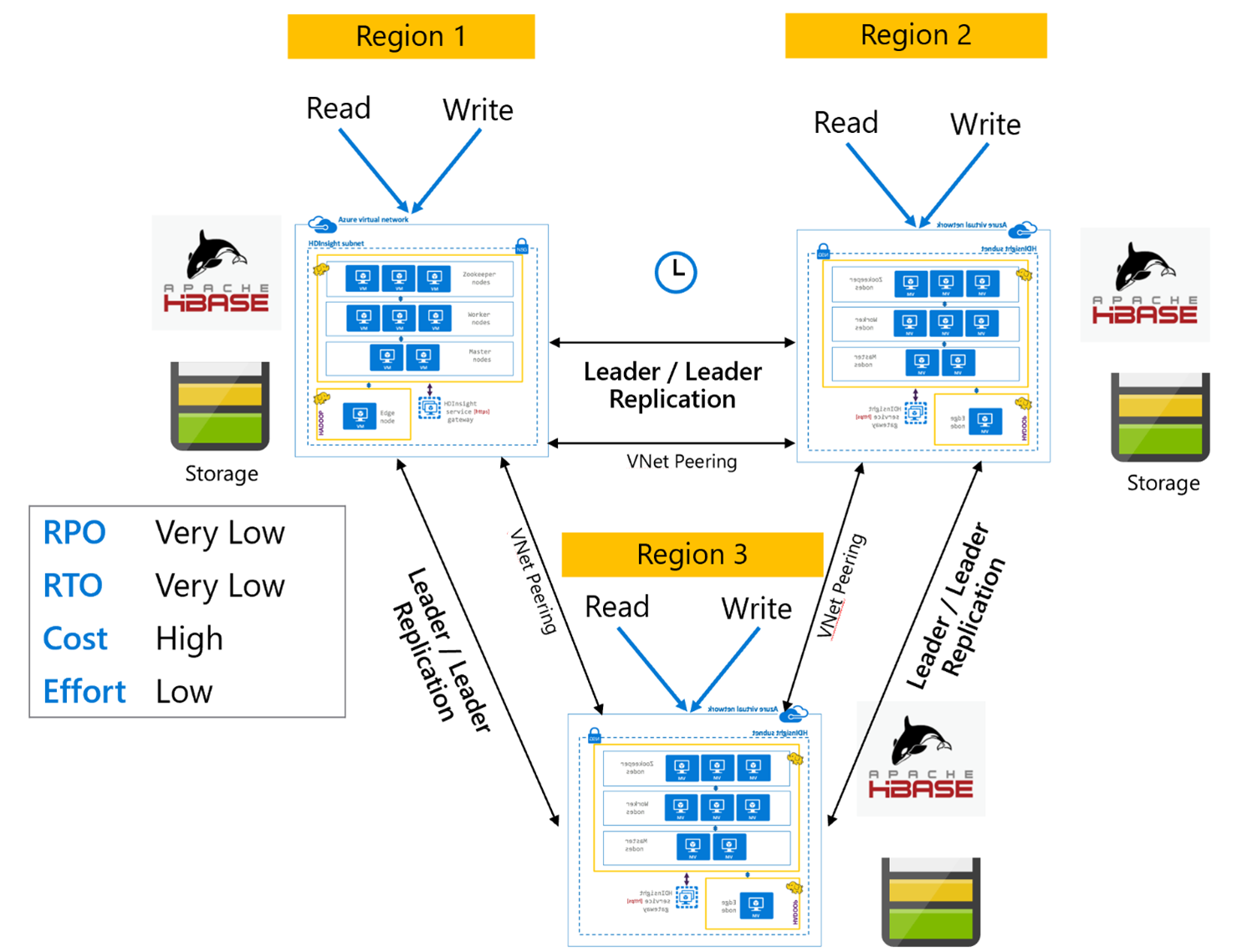
Репликация HBase. Модель многорегиональной или циклической репликации
Модель многорегиональной или циклической репликации представляет собой расширение репликации HBase и может использоваться для создания глобально избыточной архитектуры HBase с несколькими приложениями, которые считывают и записывают данные в отдельные кластеры HBase, относящиеся к регионам. Кластеры можно настроить в разных сочетаниях: "ведущий-ведущий" или "ведущий-ведомый" — в зависимости от бизнес-требований.
Apache Kafka
Для обеспечения межрегиональной доступности HDInsight 4.0 поддерживает служебную программу MirrorMaker из Apache Kafka, которую можно использовать для поддержки вторичной реплики основного кластера Kafka в другом регионе. MirrorMaker действует как пара "получатель-производитель" высокого уровня, принимает из определенного раздела в основном кластере и производит передачу в раздел с тем же именем в дополнительном кластере. При межкластерной репликации для аварийного восстановления высокого уровня доступности с помощью MirrorMaker предполагается, что производители и получатели должны выполнить отработку отказа в кластере реплики. Дополнительные сведения см. в статье Репликация разделов Apache Kafka с помощью Kafka в HDInsight и MirrorMaker.
Репликация с помощью MirrorMaker может привести к разным смещениям между разделами источника и реплики, что зависит от времени существования раздела. Кластеры HDInsight Kafka также поддерживают репликацию секций разделов, которая представляет собой функцию высокого уровня доступности на уровне отдельного кластера.
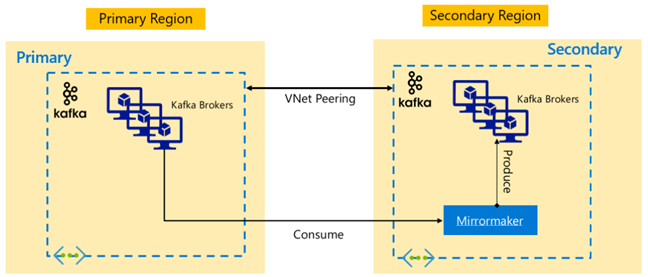
Варианты архитектуры Apache Kafka
Репликация Kafka: модель "активный-пассивный"
Настройка "активный-пассивный" позволяет выполнять асинхронное однонаправленное зеркальное отображение из активного кластера в пассивный. Производителям и получателям следует знать о существовании активного и пассивного кластера, и они должны быть готовы к отработке отказа в пассивном кластере в случае сбоя активного. Ниже приведены некоторые преимущества и недостатки настройки "активный-пассивный".
Преимущества.
- Задержка в сети между кластерами не влияет на производительность активного кластера.
- Простота однонаправленной репликации.
Недостатки.
- Пассивный кластер может оказаться недостаточно загруженным.
- Сложность разработки при реализации осведомленности производителей и получателей об отработке отказа в приложении.
- Возможная потеря данных при отказе активного кластера.
- Необязательная согласованность между разделами активных и пассивных кластеров.
- Восстановление размещения в основной кластер может привести к несогласованности сообщений в разделах.
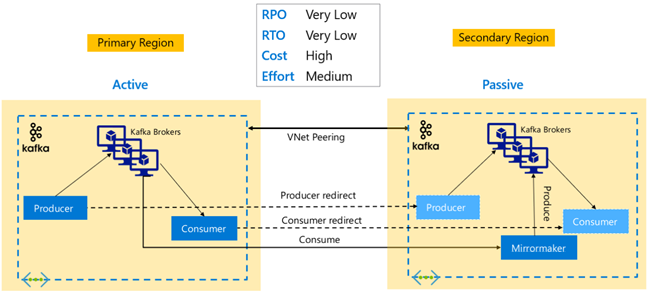
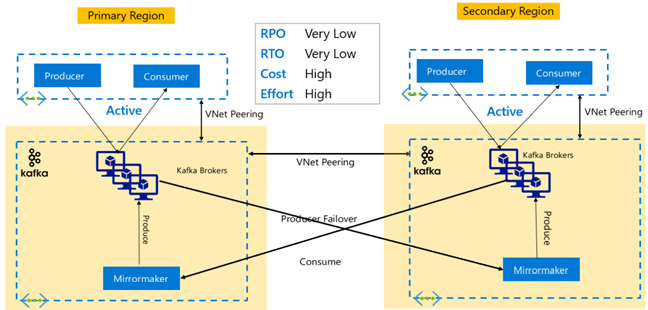
Репликация Kafka: модель "активный-активный"
Настройка "активный-активный" включает два разделенных по регионам одноранговых кластера HDInsight Kafka виртуальной сети с поддержкой двунаправленной асинхронной репликации с помощью MirrorMaker. В этой структуре сообщения, используемые получателями в основном кластере, становятся доступными для получателей в дополнительном, и наоборот. Ниже приведены некоторые преимущества и недостатки настройки "активный-активный".
Преимущества.
- Благодаря дублированию состояния, проще выполнять отработку отказа и восстановление размещения.
Недостатки.
- Настройка, управление и мониторинг сложнее, чем для модели "активный-пассивный".
- Необходимо решить проблему, связанную с циклической репликацией.
- Двунаправленная репликация приводит к более высокой стоимости регионального исходящего трафика.
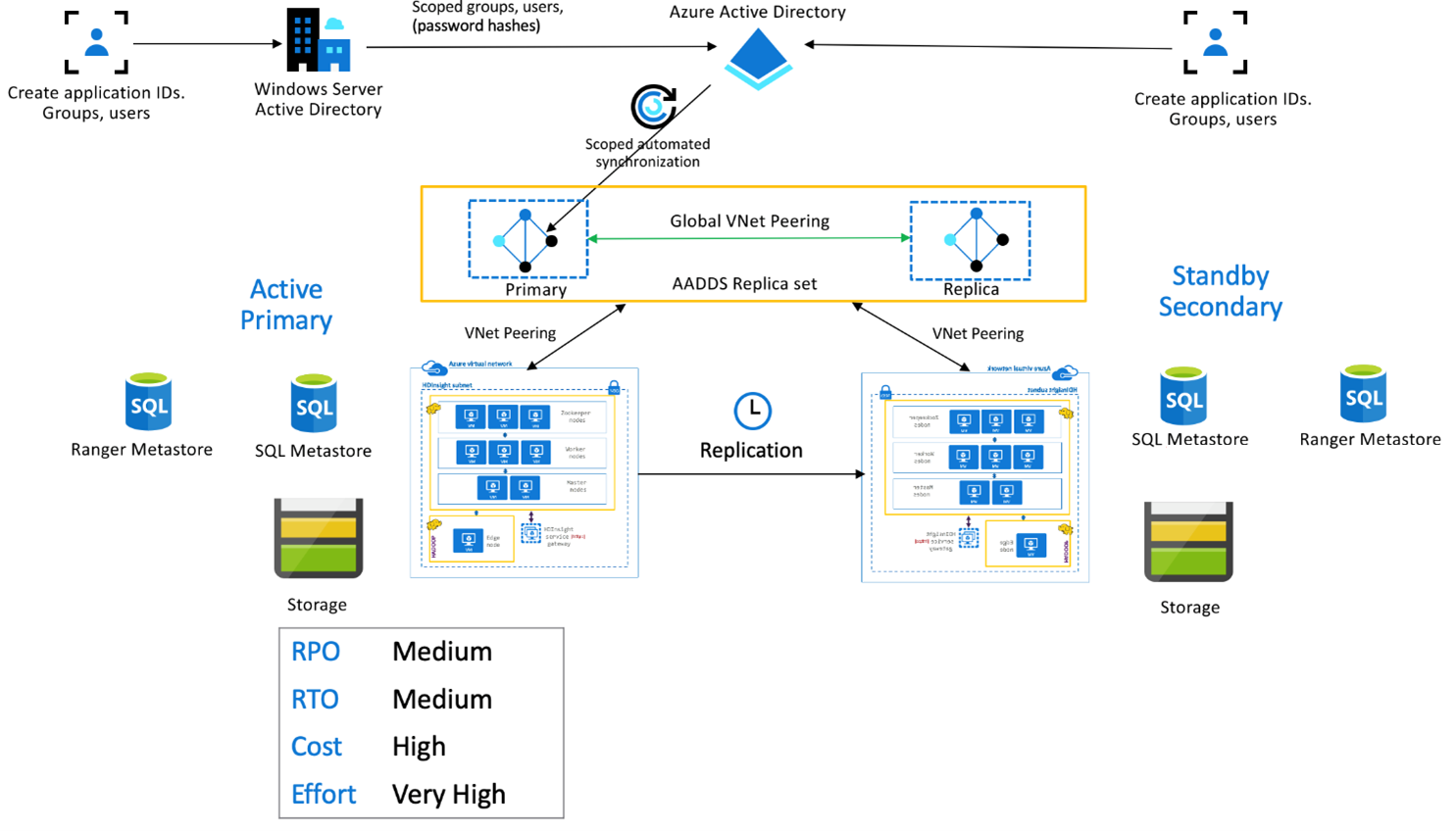
Корпоративный пакет безопасности в Azure HDInsight
Эта настройка используется для включения функциональных возможностей нескольких пользователей как в основном, так и в дополнительном, а также в доменных службах Майкрософт реплика наборов, чтобы обеспечить аутентификацию пользователей в обоих кластерах. При нормальном функционировании политики Ranger необходимо настроить в дополнительном кластере, чтобы пользователи могли выполнять только операции чтения. В приведенном ниже варианте архитектуры показано, как может выглядеть модель "активный основной-резервный дополнительный" в Hive с поддержкой ESP.
Репликация хранилища метаданных Ranger
Хранилище метаданных Ranger используется для постоянного хранения и обслуживания политик Ranger по управлению авторизацией данных. Рекомендуется поддерживать независимые политики Ranger в основном и дополнительном кластерах, и обслуживать дополнительный как реплику для чтения.
Если необходимо сохранять синхронизацию политик Ranger между основным и дополнительным кластерами, используйте операции импорта и экспорта Ranger для периодического резервного копирования и импорта политик Ranger из основного кластера в дополнительный.
Репликация политик Ranger между основным и дополнительным кластерами может привести к тому, что дополнительный кластер будет доступен для записи, в результате чего возможны непреднамеренное выполнение операций записи в дополнительном кластере и несогласованность данных.
Следующие шаги
Дополнительные сведения по темам, обсуждавшимся в этой статье, см. в следующих разделах:
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по