Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Механизмы репликации Azure HDInsight можно интегрировать с архитектурой высокодоступного решения. В этой статье вымышленный пример решения Contoso Retail используется для пояснения возможных подходов к аварийному восстановлению с высоким уровнем доступности, различных расходов и соответствующих им структур.
Рекомендации по аварийному восстановлению с высоким уровнем доступности могут обусловить много перестановок и комбинаций. Эти решения должны быть приняты после тщательного взвешивания преимуществ и недостатков каждого из вариантов. В этой статье рассматривается только одно возможное решение.
Архитектура клиента
На следующем рисунке показана основная архитектура Contoso Retail. Она состоит из потоковой рабочей нагрузки, пакетной рабочей нагрузки, уровня обслуживания, уровня потребления, уровня хранилища и системы управления версиями.
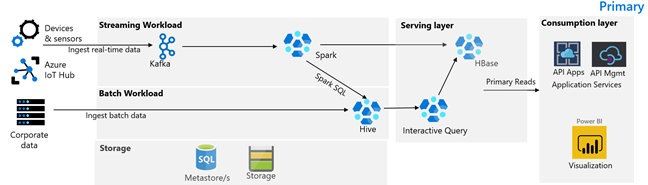
Потоковая рабочая нагрузка
Устройства и датчики создают данные в HDInsight Kafka, что формирует платформу обмена сообщениями. Клиент HDInsight Spark считывает данные из разделов Kafka. Spark преобразовывает входящие сообщения и записывает их в кластер HDInsight HBase на уровне обслуживания.
Пакетная рабочая нагрузка
Кластер HDInsight Hadoop, в котором выполняются Hive и MapReduce, принимает данные из локальных транзакционных систем. Необработанные данные, преобразованные Hive и MapReduce, хранятся в таблицах Hive в логической секции озера данных на основе Azure Data Lake Storage 2-го поколения. Данные, хранящиеся в таблицах Hive, также доступны для Spark SQL, что позволяет выполнить их пакетное преобразование перед сохранением курированных данных в HBase для обслуживания.
Служебный слой
Кластер HDInsight HBase с Apache Phoenix используется для обслуживания данных для веб-приложений и панелей мониторинга визуализации. Кластер HDInsight LLAP используется для выполнения требований к внутренним отчетам.
Уровень потребления
Приложения API Azure и уровень управления API обеспечивают общедоступную веб-страницу. Требования к внутренним отчетам выполняет Power BI.
Уровень хранения
Логически секционированное хранилище Azure Data Lake Storage 2-го поколения используется в качестве корпоративного озера данных. Метахранилища HDInsight работают на основе Базы данных SQL Azure.
Система управления версиями
Система управления версиями интегрирована в Azure Pipelines и размещена за пределами Azure.
Требования к непрерывности бизнес-процессов клиентов
Важно определить, какие минимальные бизнес-функции вам понадобятся в случае аварии.
Требования к непрерывности бизнес-процессов Contoso Retail
- Необходимо защититься от региональных сбоев и нарушений работоспособности служб на уровне региона.
- Мои пользователи никогда не должны видеть ошибку 404. Общедоступное содержимое всегда должно предоставляться. (RTO = 0)
- Большую часть года мы можем отображать общедоступное содержимое, которое устарело на 5 часов. (RPO = 5 ч)
- Во время праздников наше общедоступное содержимое всегда должно быть актуальным. (RPO = 0)
- Мои требования к внутренним отчетам не считаются критически важными для непрерывности бизнес-процессов.
- Оптимизируйте затраты на обеспечение непрерывности бизнес-процессов.
Предлагаемое решение
На следующем рисунке показана архитектура аварийного восстановления с высоким уровнем доступности Contoso Retail.
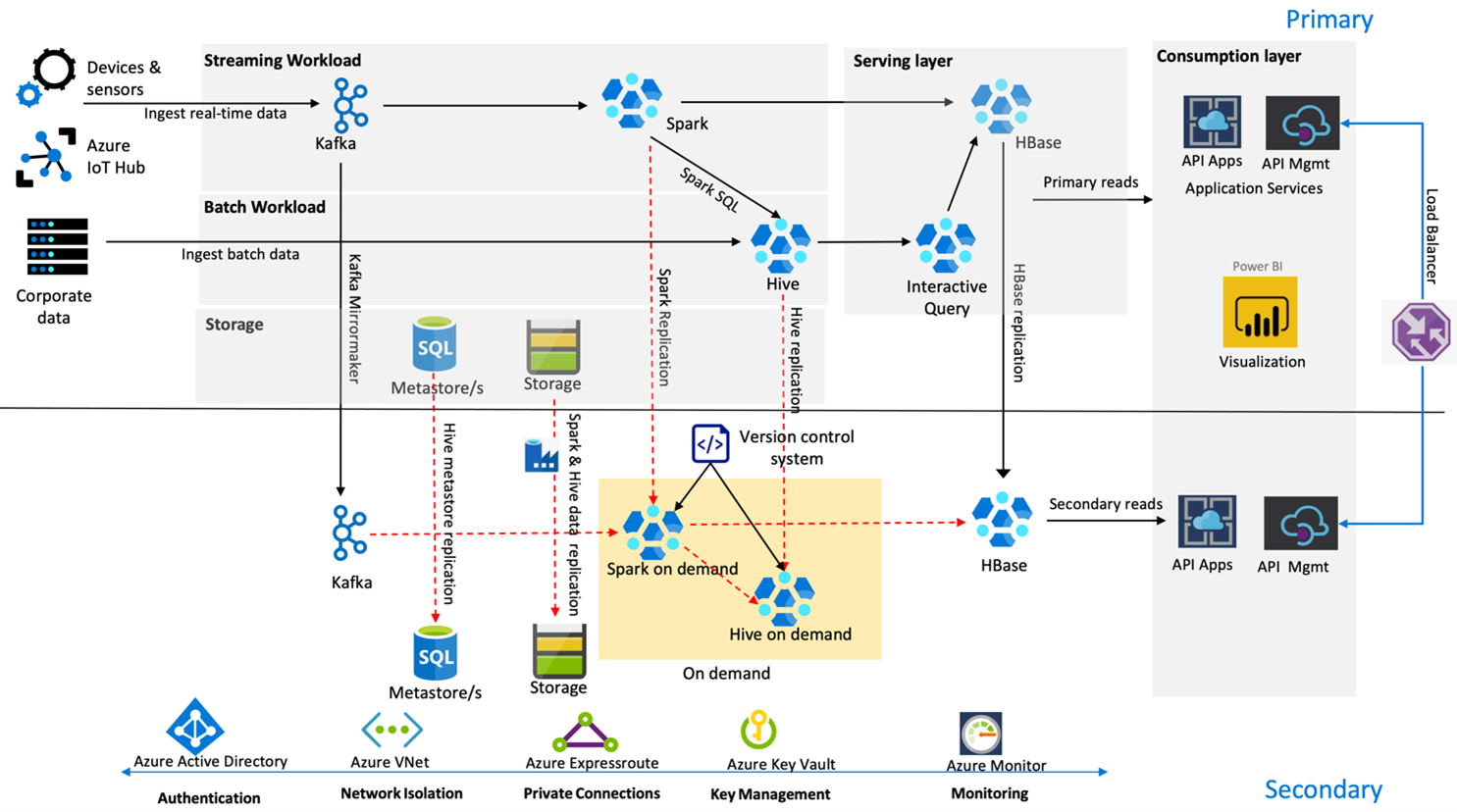
Kafka использует режим репликации активный — пассивный для отражения разделов Kafka из основного региона в дополнительный регион. В качестве альтернативы репликации Kafka можно создать службу Kafka в обоих регионах.
В обычных условиях Hive и Spark используют модели репликации активный основной — дополнительный по запросу. Процесс репликации Hive выполняется периодически и сопровождается репликацией учетной записи хранения Hive и хранилища метаданных Hive в Azure SQL. Учетная запись хранения Spark периодически реплицируется с помощью ADF DistCP. Временный характер этих кластеров помогает оптимизировать затраты. Репликация выполняется каждые 4 часа для соблюдения RPO, что хорошо подходит для требуемых 5 часов.
В обычных условиях репликация HBase использует модель лидер — подписчик, чтобы гарантировать, что данные всегда предоставляются независимо от региона, а значение RPO очень низкое.
Если в основном регионе произошел региональный сбой, веб-страница и содержимое серверной части обслуживаются из дополнительного региона в течение 5 часов с некоторой степенью устаревания. Если панель мониторинга работоспособности служб Azure не указывает восстановление в течение 5 часов, Contoso Retail создаст слой преобразования Hive и Spark в дополнительном регионе, а затем нацелит все вышестоящее источники данных на дополнительный регион. Предоставление доступа для записи в дополнительный регион приведет к восстановлению размещения, что включает в себя репликацию в основной регион.
Во время пиков покупательской активности весь дополнительный конвейер всегда активен и работает. Производители Kafka создают данные в обоих регионах, и служба репликации HBase сменит модель "лидер — подписчик" на модель "лидер — лидер", чтобы обеспечить постоянное обновление общедоступного содержимого.
Не требуется проектировать решение для отработки отказа для внутренних отчетов, так как они не являются критически важными для непрерывности бизнес-процессов.
Следующие шаги
Дополнительные сведения по темам, обсуждавшимся в этой статье, см. в следующих разделах: