Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Сведения об основных проблемах и способах их решения при работе с распределенной файловой системой Hadoop Distributed File System (HDFS). Полный список команд см. в Руководстве по командам HDFS и в Руководстве по оболочке файловой системы.
Как получить доступ к локальной системе HDFS в пределах кластера?
Проблема
Вместо хранилища BLOB-объектов Azure или Azure Data Lake Storage для доступа к локальной системе HDFS в пределах кластера HDInsight используется командная строка и код приложения.
Способы устранения
Вставьте в командную строку
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...без изменений, как в следующей команде:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userВставьте в исходный код универсальный код ресурса (URI)
hdfs://mycluster/без изменений, как показано в примере приложения.import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }Запустите скомпилированный JAR-файл (например, файл с именем
java-unit-tests-1.0.jar) в кластере HDInsight с помощью следующей команды:hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Исключение хранилища для записи в большой двоичный объект
Проблема
Если при использовании команд hadoop или hdfs dfs в кластер HBase записываются файлы размером более 12 ГБ, может возникнуть следующая ошибка:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
Причина
В HBase в кластерах HDInsight размер блока по умолчанию при записи в службу хранилища Azure равен 256 КБ. Несмотря на то что это подходит при использовании API HBase или REST API, применение служебных программ командной строки hadoop или hdfs dfs вызовет ошибку.
Разрешение
Задайте больший размер блока с помощью свойства fs.azure.write.request.size. Его можно указывать для каждого отдельного случая, используя параметр -D. Далее приведен пример использования параметра с командой hadoop:
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
Можно также глобально увеличить значение fs.azure.write.request.size с помощью Apache Ambari. Чтобы изменить значение в веб-интерфейсе Ambari, сделайте следующее:
В браузере перейдите к веб-интерфейсу Ambari для кластера Перейдите на страницу
https://CLUSTERNAME.azurehdinsight.net, гдеCLUSTERNAME— это имя вашего кластера. При появлении запроса введите имя и пароль администратора для кластера.В левой части экрана выберите HDFS, а затем перейдите на вкладку Configs (Конфигурации).
В поле Фильтр... введите
fs.azure.write.request.size.Измените значение с 262 144 (256 КБ) на новое. Например, 4 194 304 (4 MB).
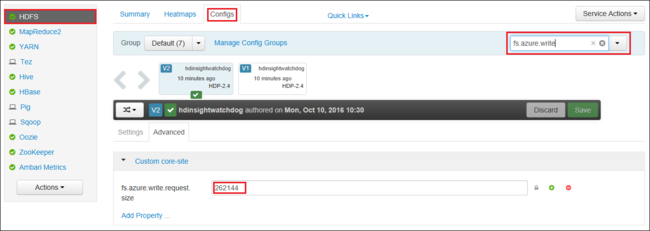
Подробные сведения об использовании Ambari см. в статье Управление кластерами HDInsight с помощью веб-интерфейса Ambari.
du
Команда -du отображает размеры файлов и каталогов, содержащихся в заданном каталоге, или длину файла, если это просто файл.
Параметр -s создает сводку по длине файлов.
Параметр -h форматирует размеры файлов.
Пример:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
rm
Команда -RM удаляет файлы, указанные в качестве аргументов.
Пример:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
Следующие шаги
Если вы не видите своего варианта проблемы или вам не удается ее устранить, дополнительные сведения можно получить, посетив один из следующих каналов.
Получите ответы специалистов Azure на сайте поддержки сообщества пользователей Azure.
Подпишитесь на @AzureSupport — официальный канал Microsoft Azure для улучшения качества взаимодействия с клиентами. Вступайте в сообщество Azure для получения нужных ресурсов: ответов, поддержки и советов экспертов.
Если вам нужна дополнительная помощь, отправьте запрос в службу поддержки на портале Azure. Выберите Поддержка в строке меню или откройте центр Справка и поддержка. Дополнительные сведения см. в статье Создание запроса на поддержку Azure. Доступ к управлению подписками и поддержкой выставления счетов уже включен в вашу подписку Microsoft Azure, а техническая поддержка предоставляется в рамках одного из планов Службы поддержки Azure.